








- 作者: Lingfeng Zhang 1 , 2 ^{1,2} 1,2, Xiaoshuai Hao 2 ^{2} 2, Qinwen Xu 2 , 5 ^{2,5} 2,5, Qiang Zhang 1 , 3 ^{1,3} 1,3, Xinyao Zhang 1 ^{1} 1,Pengwei Wang 2 ^{2} 2, Jing Zhang 4 ^{4} 4, Zhongyuan Wang 2 ^{2} 2, Shanghang Zhang 2 , 5 ^{2,5} 2,5,Renjing Xu 1 ^{1} 1
- 单位: 1 ^{1} 1香港科技大学, 2 ^{2} 2北京人工智能学院, 3 ^{3} 3北京人形机器人创新中心有限公司, 4 ^{4} 4武汉大学计算机科学学院, 5 ^{5} 5北京大学计算机科学学院多媒体信息处理国家重点实验室
- 论文标题:MapNav: A Novel Memory Representation via Annotated Semantic Maps for VLM-based Vision-and-Language Navigation
- 论文链接:https://arxiv.org/pdf/2502.13451
主要贡献
- 提出了基于VLM的端到端视觉语言导航模型MapNav,利用标注的语义地图(ASM)进行记忆表示,有效地替代了传统的历史帧。
- 引入了自上而下的标注语义地图(ASM),在每个时间步更新,允许精确的对象映射和结构化的导航信息,提供了清晰的导航线索。
- MapNav在模拟和现实环境中超越了SOTA方法,展示了其在视觉语言导航任务中的有效性。
研究背景
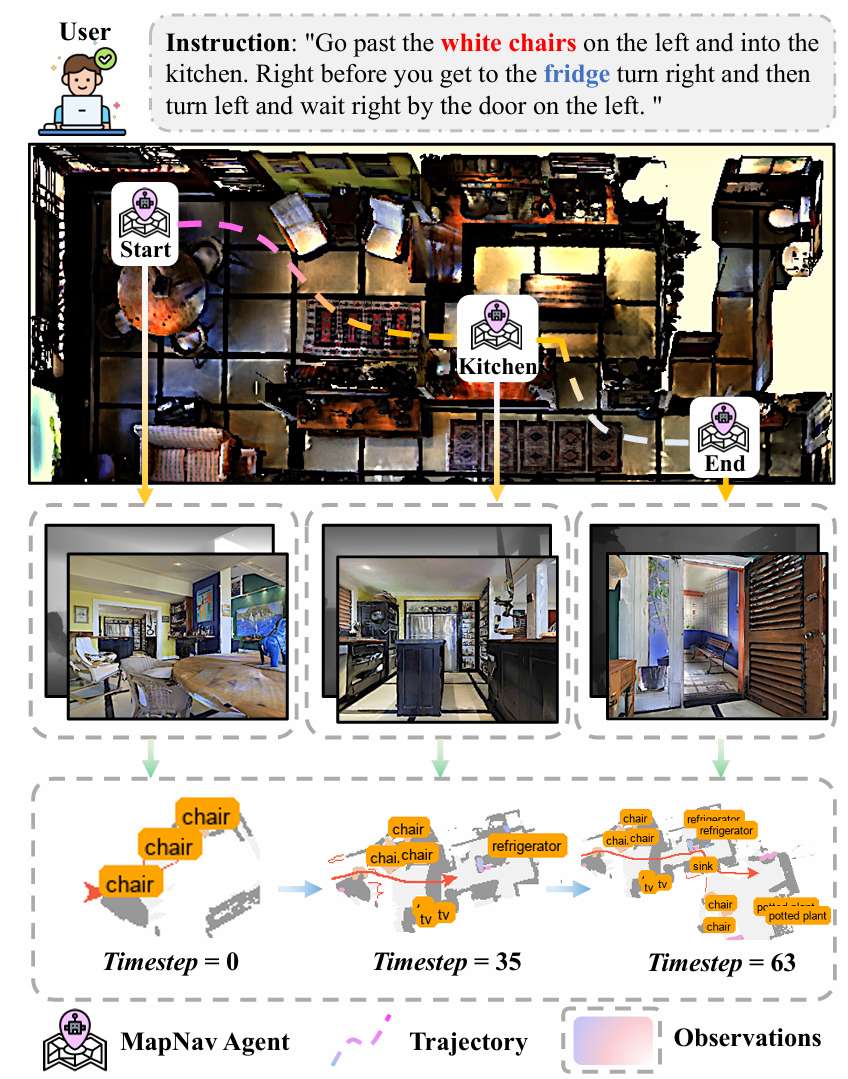
研究问题
论文主要解决的问题是如何在视觉和语言导航(VLN)任务中,通过标注语义地图(ASM)来替代传统的历史帧,从而减少存储和计算开销,同时提高导航性能。
研究难点
该问题的研究难点包括:
- 传统的VLN方法依赖于历史观测数据作为时空上下文,导致存储和计算开销巨大;
- 现有的连续环境导航方法虽然提高了模拟到现实的转移能力,但仍然依赖历史观测数据,增加了存储需求并缺乏对过去轨迹的结构化理解。
相关工作
该问题的研究相关工作有:
- 早期的VLN方法主要依赖于离散环境导航和预定义的路径点选择;
- Habitat模拟器和R2R-CE、RxR-CE基准测试推动了连续环境导航的研究;
- 最近的研究利用大规模预训练模型和VLN特定预训练来改进VLN性能,但这些方法仍然依赖于分层提示或历史帧,导致高内存需求和有限的历史数据理解。
研究方法
任务定义
- 目标:在连续的三维环境中,智能体需要根据自然语言指令进行导航。智能体的任务是沿着指令指定的路径移动,最终到达目标位置。
- 输入:
- 自然语言指令 I I I:指定所需的导航路径。
- 观察序列 X t X_t Xt:智能体在导航过程中收集的第一人称RGB观察。这些观察是智能体在每个时间步 t t t 获取的图像帧。
- 输出:
- 动作序列 a t + 1 a_{t+1} at+1:智能体在每个时间步 t t t 需要预测的下一个连续动作。动作定义了智能体的下一个移动方向或操作。
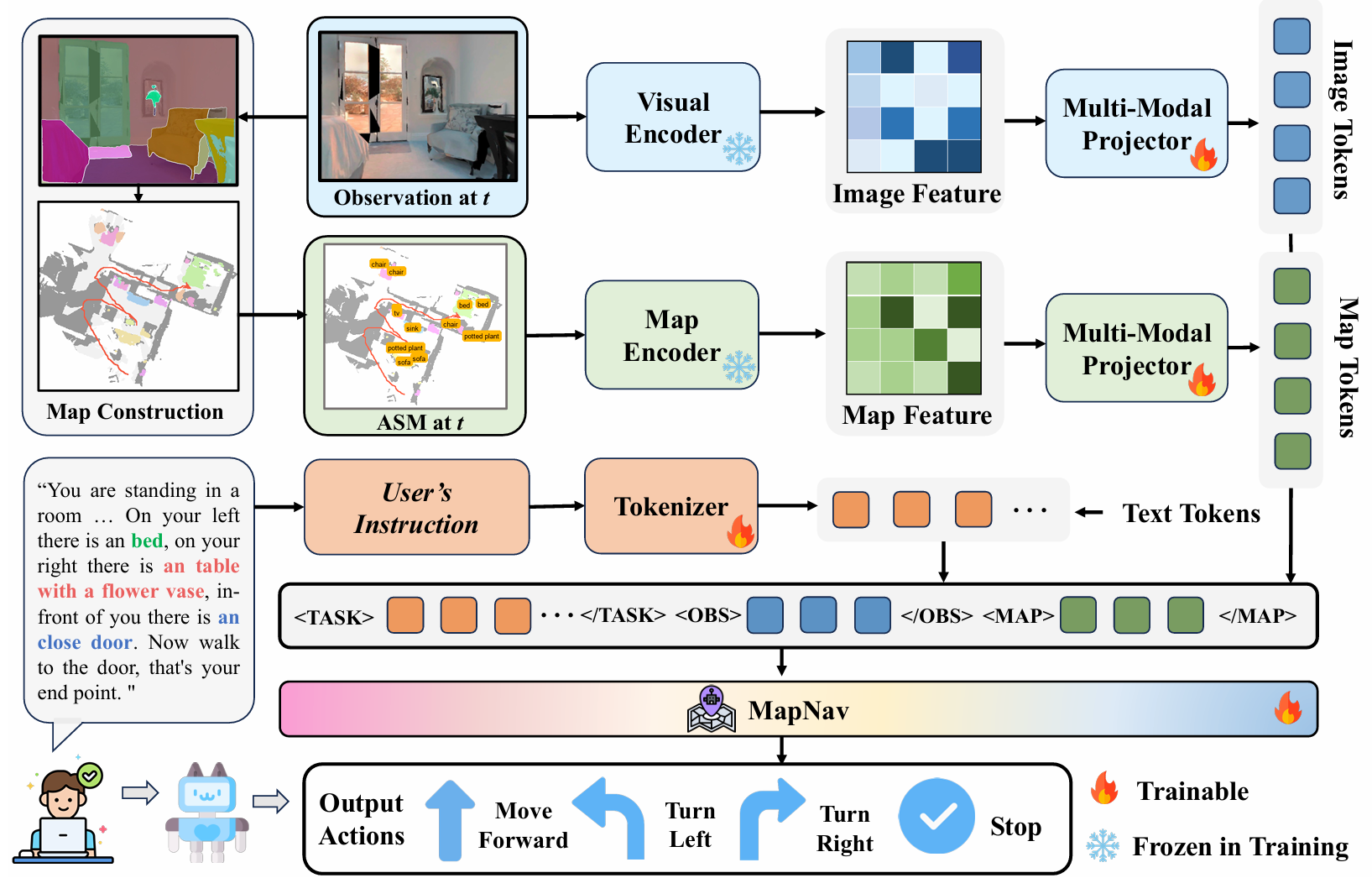
MapNav智能体
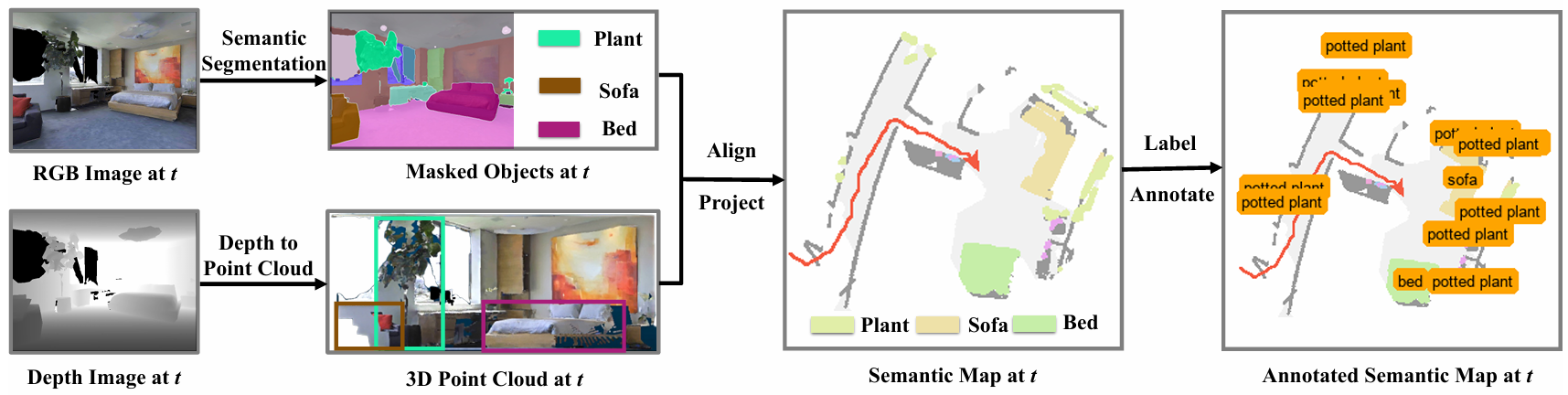
语义地图标注生成
-
初始化:
- 在每个导航任务的开始,ASM被初始化。智能体位于环境的中心位置(例如,坐标为 ( 1 2 , 1 2 ) (\frac{1}{2}, \frac{1}{2}) (21,21) )。
-
语义映射系统:
- ASM的生成依赖于一个语义映射系统,该系统使用一个多通道的张量 M M M 来表示环境。张量的维度为 C × W × H C \times W \times H C×W×H,其中 C = C n + 4 C = C_{n} + 4 C=Cn+4, n n n 表示不同的对象类别。
- 基础通道(前四个通道)用于编码导航信息,包括物理障碍物、已探索区域、智能体的当前位置和历史位置。
- 其余的 n n n 个通道用于存储特定于对象的语义信息。
-
点云转换:
- 智能体将RGB-D数据转换为点云表示,以便生成精确的俯视图。点云数据被投影到二维平面上,以创建自上而下的俯视语义地图。
-
语义分割对齐:
- 通过将语义分割掩码与点云数据对齐,智能体能够在每个通道中实现精确的对象映射。
-
文本标注:
- 为了增强ASM的可读性和导航能力,智能体在每个语义区域上添加明确的文本标注。具体来说,通过连通组件分析识别每个对象特定通道中的语义区域,并计算这些区域的几何质心来确定最佳的文本放置位置。
- 对于每个超过最小面积阈值 τ \tau τ 的语义区域,智能体计算其几何质心作为文本锚点,以确保文本标注的最佳位置和可读性,同时保持视觉清晰度。
-
生成ASM:
- 生成的ASM将抽象的语义表示转化为具有明确标签的空间信息(例如, “chair”, “plant”, “bed”)。这种显式的文本标注使得VLM能够利用其预训练的对象-语言关系知识,促进直观的空间推理和导航决策。

特征编码
- 使用两个编码器分别处理观察和ASM的特征。假设
F
t
F_t
Ft 和
F
t
M
F_t^M
FtM 分别是观察帧和ASM的特征表示,特征编码的过程可以表示为:
F t = Φ spatial ( X t , G ) F_t = \Phi_{\text{spatial}}(X_t, \mathcal{G}) Ft=Φspatial(Xt,G)
F t M = Φ spatial ( M t ASM , G ) F_t^M = \Phi_{\text{spatial}}(M_t^{\text{ASM}}, \mathcal{G}) FtM=Φspatial(MtASM,G) - 这里 Φ spatial \Phi_{\text{spatial}} Φspatial 是一个空间感知的补零块合并函数, G \mathcal{G} G 定义了特征提取的网格。
多模态投影
- 将观察和ASM的特征对齐到一个共享的嵌入空间中。假设
E
t
E_t
Et 和
E
t
M
E_t^M
EtM 是投影后的特征表示,多模态投影的过程可以表示为:
E t = P mlp obs ( F t ) E_t = P_{\text{mlp}}^{\text{obs}}(F_t) Et=Pmlpobs(Ft)
E t M = P mlp map ( F t M ) E_t^M = P_{\text{mlp}}^{\text{map}}(F_t^M) EtM=Pmlpmap(FtM) - 这里 P mlp obs P_{\text{mlp}}^{\text{obs}} Pmlpobs 和 P mlp map P_{\text{mlp}}^{\text{map}} Pmlpmap 是两层MLP。
指令处理
- 将指令标记与对齐后的特征连接起来,并输入到VLM中。假设
I
t
I_t
It 是指令的标记表示,最终的输入表示为:
V t = [ TASK ; E t ; OBS ; E t M ; MAP ] V_t = [\text{TASK}; E_t; \text{OBS}; E_t^M; \text{MAP}] Vt=[TASK;Et;OBS;EtM;MAP] - 这个过程将所有输入特征整合在一起,形成一个统一的表示。
动作预测
- 通过VLM直接解析导航意图为离散的动作。假设
A
(
t
)
\mathcal{A}(t)
A(t) 是动作预测的结果,动作预测的过程可以表示为:
A ( t ) = Ψ ( T ( t ) , P ) \mathcal{A}(t) = \Psi(\mathcal{T}(t), \mathcal{P}) A(t)=Ψ(T(t),P) - 这里 T ( t ) \mathcal{T}(t) T(t) 是模型的文本输出, P \mathcal{P} P 是模式匹配规则集, Ψ \Psi Ψ 是动作解析函数。
实验
实验设置
-
数据集:
- 论文构建了一个包含约1百万训练对的综合性数据集。
- 数据集通过混合收集策略构建,包括来自R2R和RxR数据集的真实轨迹(约30万对)、通过DAgger收集的数据(约20万对),以及专门的碰撞恢复样本(约2.5万对)。
- 这种策略确保了导航场景的多样性和覆盖范围。
- 为了公平比较,模型在R2R数据集上训练,并在RxR数据集上进行零样本评估。此外,还在RxR数据集上进行了单独的训练和评估。
-
模拟环境:
- 在模拟环境中,使用Habitat的VLN-CE基准进行评估。
- Habitat提供了一个连续的环境,用于在重建的逼真室内场景中进行导航。
- 评估集中在R2R和RxR数据集的val-unseen上,分别包含1,839和1,517个episode。
-
真实世界环境:
- 为了评估模型的sim-to-real性能,设计了在五个环境(办公室、会议室、演讲厅、茶室和客厅)中的多样化真实世界实验。
- 实验包括50个指令,分为简单指令和语义指令两类。
-
评估指标:
- 使用多种广泛使用的评估指标进行VLN任务评估,包括导航误差(NE)、Oracle成功率(OS)、成功率(SR)、路径长度加权成功率(SPL)和 nDTW。
- SPL是主要指标,因为它有效地反映了导航的准确性和效率。
-
实现细节:
- 模型在8个NVIDIA A100 GPU上进行训练,大约30小时,总计240 GPU小时。
- 使用LLaVA-Onevision架构,视觉编码器采用Google的SigLIP-so400M,语言模型采用Qwen2-7B-Instruct,语义分割使用Mask2Former。
与SOTA方法的比较
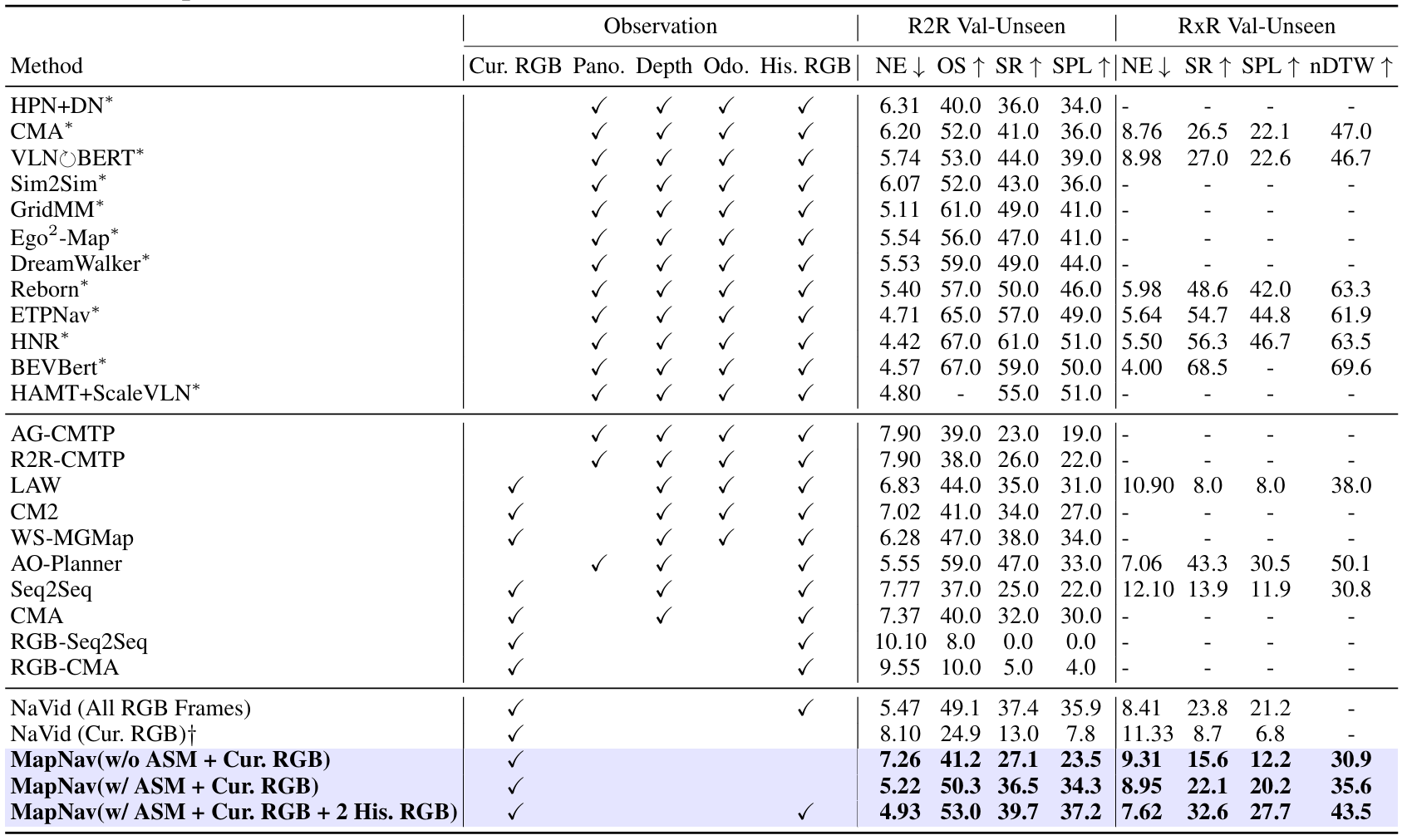
- 模拟环境结果:
- 在R2R数据集上,MapNav在零样本评估中表现出色,相比基线方法在成功率(SR)和SPL上分别提高了14.1%和15.7%。
- 在RxR数据集上,MapNav在SR和SPL上分别提高了6.9%和5.4%。
- 使用ASM后,MapNav在R2R数据集上的SR和SPL分别提高了23.5%和26.5%,显示出ASM在导航任务中的有效性。

- 真实世界环境结果:
- 在真实世界实验中,MapNav在简单指令和语义指令上都优于WS-MGMAP和Navid。
- 特别是在语义指令设置下,MapNav在演讲厅和客厅场景中表现出色,成功率(SR)分别提高了30%。
消融研究

- 效率分析:
- MapNav在内存消耗和推理时间上表现出显著优势。MapNav的语义地图方法保持恒定的内存占用(0.015MB),而NaviD的内存占用随轨迹长度线性增长,达到300步时的276MB。
- 在推理速度方面,MapNav的平均处理时间减少了79.5%,从每步1.22秒减少到0.25秒。
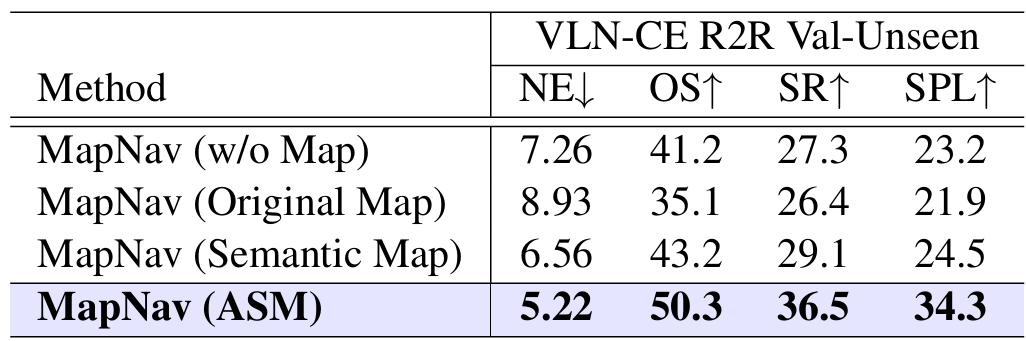
- ASM的影响:
- 通过比较不同的地图表示方法,验证了ASM在提升导航性能方面的有效性。
- ASM在所有评估指标上都优于原始地图和语义地图。
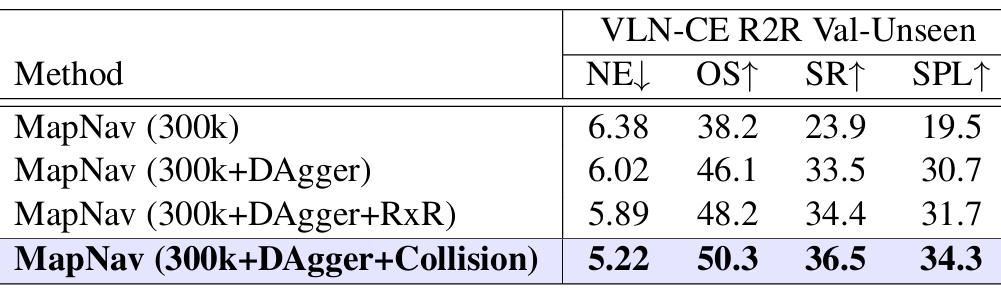
- 数据集组成的影响:
- 通过数据集消融研究,展示了数据多样性和交互学习对模型性能的提升作用。
- 特别是DAgger样本的引入显著提升了模型的泛化能力。
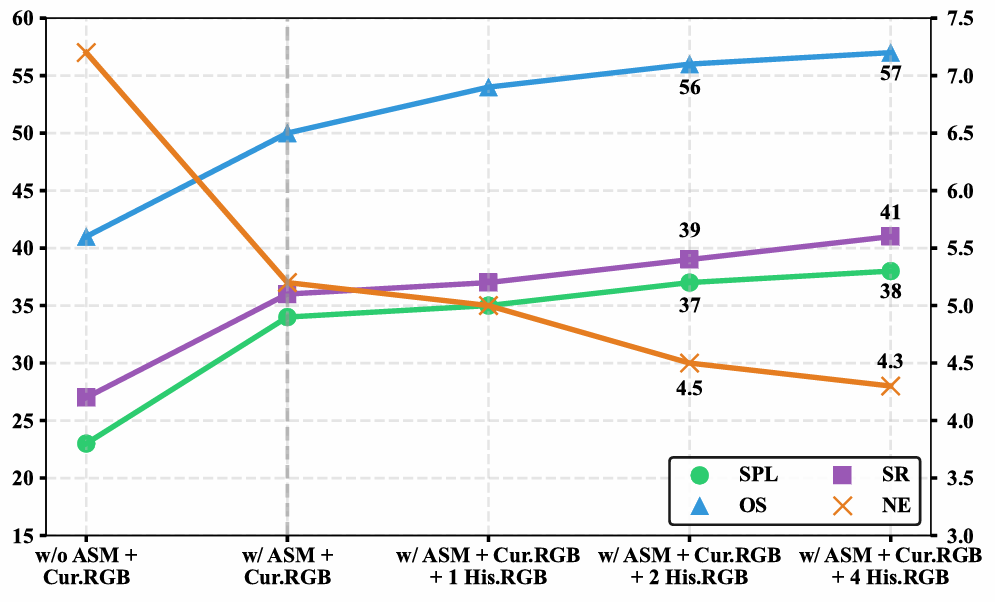
- 历史RGB帧的影响:
- 通过系统消融研究,评估了不同数量的历史RGB帧对性能的影响。
- 结果表明,ASM在单帧设置下效果最佳,而增加历史帧的收益相对较小。
总结
- 论文提出了MapNav,基于标注语义地图(ASM)的端到端VLN模型,通过替换传统的历史帧,显著减少了存储和计算开销,同时提高了导航性能。
- 实验结果表明,MapNav在模拟和真实世界环境中均达到了SOTA性能,验证了ASM在VLN任务中的有效性。
- 未来的研究方向包括探索更先进的语义理解方法和增强现实世界泛化能力。


















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









