









这篇文章第一作者是Johannes Graeter,发表在2018年的IROS会议上。
论文方法的源代码见:GitHub - johannes-graeter/limo: Lidar-Monocular Visual Odometry。
1. 简介
论文介绍了一种较为新颖视觉里程计,将激光雷达和视觉结合了起来。通过LIDAR提取深度,通过视觉提取特征进行跟踪,基于关键帧BA预测机器人运动。
论文介绍的方法在KITTI数据集上取得了top 15的成绩,图1为本论文方法和其他方法的对比。

图1 轨迹对比
本文开头介绍了BA算法的重要作用,随后介绍了双目方法的进展和主要难点。Lidar在测量深度信息方面具有相对于双目的优势,Lidar测量深度信息不仅精确,而且不依赖于精确标定的双目外参。
本文目的就是将Lidar的高精度测量深度的优势和相机提取特征的优势结合起来,需要做的一件事情就是要增加一个步骤,将特征跟踪和深度测量结合起来。本文介绍了一种新的为特征点通过Lidar提取深度的方法(Section III),作者通过局部平面假设去除外点,并且对地面点进行特殊处理以增加系统鲁棒性。同时,作者将Lidar提取的深度信息和视觉SLAM领域常用的结合到了一起(见图2)。

图2
2. 模块A和B:特征提取和预处理
A模块负责特征提取和跟踪,并采用了深度学习方法去除动态物体上的特征点。本文声称所采用的特征点描述子的提取和匹配速度是2000个点对30-40ms。
3. 模块S:尺度估计
为了得到单目的尺度信息,就要找到特征点和Lidar深度测量信息的对应关系。
文中给出了关联方法:
3.1 估计方法
首先激光点云被转到相机坐标系下,并投影到相机平面。对于每个图像上的特征点,采取如下步骤:
1. 在周围选取一组投影的Lidar点
,对于这一步,后续3.2有解释。
2. 对于,继续通过3.3中的方法进行筛选出前景的部分,作为新的集合
。
3. 通过3.4中的方法,将拟合一个平面
,如果
是地面点,那么将采用3.5中的方法。
4. 通过平面和点
对应的视线相交,得到其深度。
5. 对获得的深度进行测试。如果该深度结果能够被接受,必须满足条件:视线和平面法向量的夹角必须小于阈值。另外,如果预测的深度超过30m,也将丢弃该深度预测值。
3.2 点集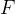 的选取
的选取
3.1中已经谈到要在特征点的周围选取一组激光雷达投影点的点集
。怎么选取呢?作者选取图像平面上围绕点
的矩形框内的点。矩形大小的选择必须要避免平面估计过程中的奇异性。如图3.

图3 矩形区域选取方法
如图3中绿色小点为特征提取过后的特征点,红色点为投影到相机平面的激光点。为了避免平面估计失败,应当选择不共线的红色点,如图3中间的那张小图。
3.3 前景分割(foreground segmentation)
我们知道,如果特征点正好处于建筑物的平坦表面(中间)时,平面假设会很好的被满足。并且可以通过点集
准确的预测平面。
然而,特征点常常是位于边边角角的位置的,而很少位于平坦平面的中间,因此预测深度经常出现如图4所示的歧义。

图4 (a)错误的深度估计,(b)只考虑前景的激光投影点,从而正确的估计深度
为了解决这个问题,文中将集合中的激光点插入到深度直方图当中,直方图的bin size为0.3m。如果存在前景和后景的差别,反应在直方图上就会是一个gap,由于特征点
是一个前景图中的边缘,通过选择直方图中的最近的显著bin区间对应的激光点,就可以实现对于前景图的分割工作。通过分割出来的对应点组成的
,就可以很好的预测特征点
周围的平面方程。
3.4 平面拟合
从中,选择三个点组成三角形
,并且要使得这个三角形的面积最大。如果三角形面积过小,就不进行深度预测了。
然后作者通过这个选取的三角形进行平面的估计,并进而进行深度的估计。
3.5 特殊情况
地面点无法采取上述方法预测深度,这是由于Lidar在垂直方向上的分辨率不够。如图5所示。

图5 在高速场景下,地面特征点是非常重要的。由于第i-th射线的深度计算公式为(论文中应该是笔误)
首先从激光点云中提取出地面平面,并采用RANSAC方法进行优化。对于地面点,我们不去进行前景分割,并直接采用如前的估计方法,先选一个点集,然后选取比此前更大的
三角形。
4. 里程计
为了获得良好的BA初始化,帧间运动估计准确性很重要。
由于有了3D激光信息,PnP这里就能够派上用场。优化目标函数如下:
是当前帧的特征点,
是
对应的3D点,
是从上一帧到当前帧的线性变换,分别是3自由度的旋转和3自由度的平移,
是相机的投影矩阵,将3D点投影到相平面。
是通过前后帧的特征点
和
匹配以及预测的深度获得。
作者用到的是本质矩阵(fundamental matrix),所以这里的点的是归一化平面上的点。
此外,作者考虑特征不多的场景,比如低结构化和高速运动场景,可能获得3D信息的特征点的数量非常有限,作者加入了三角化的极线误差。
作者还在代价函数的基础上增加了损失函数:其中;
是外点阈值,并取为固定值。帧间运动的优化问题方程为:
5. 后端
这部分介绍了后端优化的四个主要部分:
1. 关键帧的选取
2. 地标的选取
3. 代价函数的选取
4. 鲁棒化的方法
A、B. 关键帧选取
为啥要选关键帧的原因是因为用到BA算法的话,当然是全局BA效果最好,但是计算量太大,时间太久,所以用一个窗口来选取部分帧来进行优化,但是这个窗口还是尽可能的大的好,选取关键帧就是这么一个折中的方法,通过选取关键帧,使得局部BA的范围更大,同时还保持着不那么大的计算复杂度,利用的历史信息更多更全面,从而更好的优化位姿。
对于关键点SLAM来说,frame是个很重要的实体对象,连续历史信息关联在frame上,关键帧(keyframe)就是选取用来进行在线优化的frame。
作者文中提到,转弯的地方,关键帧数量要多要密集,对于那种机器人静止的场景下,周围还有很多移动物体,那么如果判断结果发现平均光流小于一定数值,就不添加关键帧,其余所有即未被添加,也未被剔除的,那就每间隔0.3s添加一个关键帧。
另外一个关键问题就是滑动窗口大小的确定,通过判断当前关键帧和最新添加的关键帧之间的关联地图点的数量的多少,如果没有达到阈值,就将当前帧设定为窗口中的最后一帧。同时作者也制定了规则让这个滑动窗口不至于过短。
C. 地标选取
原则如下:
- 良好的观测性
- 规模小,减少计算复杂性
- 没有外点,误检测
- 3维空间和2d图像上都均匀的分布
作者在本文中,一开始不进行选取的工作,一开始先尽可能多的进行点的匹配,首先进行三角化的匹配,然后对匹配的点进行测试。然后作者选取了远、近、中三个距离范围的点,这种选取划分直接在度量空间(用人话说就是,直接看和车辆距离的远近,设置三个距离区域)完成,如图6。

图6
作者进一步采用体素对路标点进行滤波处理,使得路标点的分布更加的均匀。
通过语义信息的引入,路标点的权重得到了确定,分配了更多的权重给不容易移动的物体,而分配更少的权重给容易移动和变换位置的物体。
语义信息提取作者文中提到用的是Resnet38,作者做了微小的改动。
D. 路标深度insertion
为了将深度信息也放到BA中进行优化,增加一个cost functor ,惩罚路标深度和测量深度之间的差别:
是路标点,
是从世界坐标系到相机坐标系的投影,
就是在第3节尺度估计得到的深度,下标i和j只对能够提取到路标深度的点和位姿进行关联。
针对路标,作者又进一步添加了代价子函数:
(6)式之前,作者提到“The oldest motion in the optimization window is in general the most accurate one”,所以此处的分别是优化窗口中最老的两帧位姿,式6的残差就是优化之前和优化之后,这两帧位姿之间的translation要保持不变,
是优化之前的translation值。
E. 鲁棒性与问题表述
之前作者已经提到用语义信息对外点进行一个初步的去除,如C当中描述的。
最终,根据筛选得到的landmarks,keyframes,整个优化问题如下,采用了三个权重,此外还有,
为代价函数的损失函数:
问题的优化采用了trimmed-least-squares-like这种最小二乘优化方式。
作者最终在KITTI 视觉里程计 benchmark上对该算法进行了测试。
【微小的总结】^^
这篇文章进行激光雷达和视觉特征点数据关联的方式是进行反投影和平面拟合,并把地面上的点做了分开处理。采用的算法框架基本上还是稀疏特征点的BA优化框架,整个优化问题由三个代价子函数组成。
具体效果如何,作者在数据集上做了评估,也打算看看开源代码的实际效果,先不考虑算力、跨平台之类的因素,总体感觉这个方法还不成熟,在激光雷达和视觉特征点之间进行数据关联的方法还有待探索提升。

















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









