







 超级会员免费看
超级会员免费看
 本文详细解析了LLAVA模型的权重文件,包括pytorch_model-*.bin、mm_projector.bin、adapter_model.bin和non_lora_trainables.bin等,通过对比llava-v1.5-7b与llava-v1.5-13b的权重,展示了LORA训练的权重结构,并介绍了lora训练权重文件的保存和使用。
本文详细解析了LLAVA模型的权重文件,包括pytorch_model-*.bin、mm_projector.bin、adapter_model.bin和non_lora_trainables.bin等,通过对比llava-v1.5-7b与llava-v1.5-13b的权重,展示了LORA训练的权重结构,并介绍了lora训练权重文件的保存和使用。
文章目录
前言
为什么我单独用一节文章记录llava相关bin权重文件内容?原因很简单,它比较重要,我们可以通过查看权重相关变量间接感性认识llava模型结构,以便我们对模型权重含义理解。本篇文章将涉及lora权重与大语言LLM模型llama的权重,以及相应mm_project与vit图像编码权重。这样我们将从权重文件理解llava本身结构,并也给出自带lora训练权重相关内容,将对我们训练模型保存对应权重也是十分必要的,且也能帮助我们如何把lora权重更新原始权重。
一、权重bin文件读取方法
在查找了一些方法后,发现保存bin文件是使用torch完成,自然torch也可以直接读取bin文件,直接torch.load即可实现,代码如下:
res = torch.load("/home/LLaVA/llava_v1.5_lora/llava-v1.5-7b/mm_projector.bin", map_location=torch.device("cpu"))
二、查看llava-v1.5-7b与llava-v1.5-13b文件权重
在知道权重查看方法后,我们将开始解读权重文件。首先,我将给出可以直接预测模型2个权重文件,这些文件可以直接在huggingface中下载得到,其链接如下。
https://huggingface.co/liuhaotian/llava-v1.5-7b
https://huggingface.co/liuhaotian/llava-v1.5-13b
1、llava-v1.5-7b
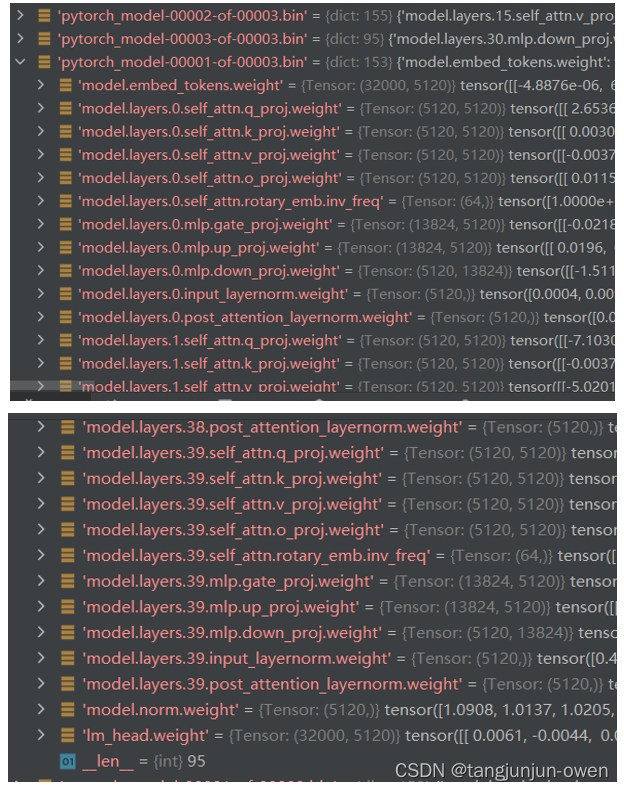
a、查看pytorch_model-*.bin权重
下图左边是pytorch_model-00001-of-00002.bin权重,右边是pytorch_model-00002-of-00002.bin权重,中间省略了,如下:
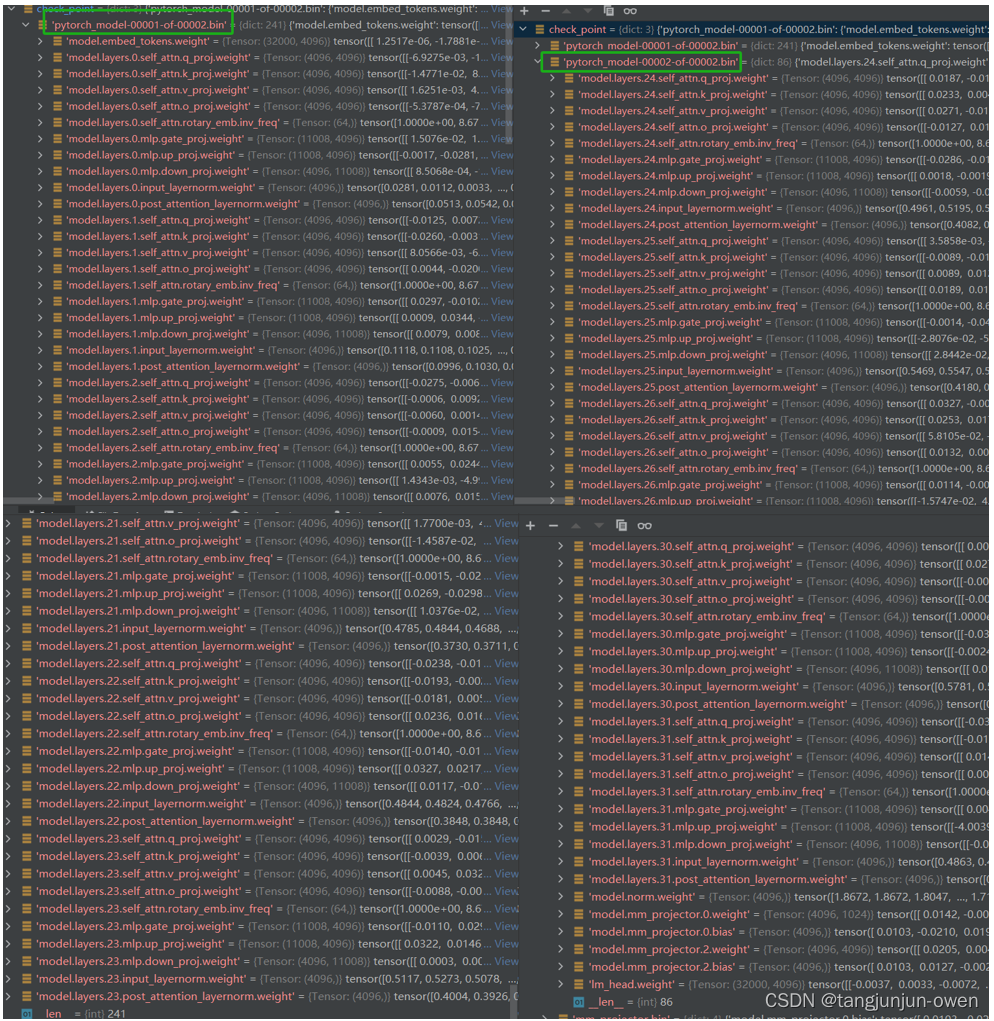
实际上面文件你可以发现,该文件实际就是大语言模型的权重,并没有视觉vit编码权重。
b、查看mm_projector.bin权重
我们可以发现该文件内容就是几层简单线性方法,这就是mm_projector的映射头。同时,我们也可发现该文件也是后续的non_lora_trainables.bin文件。
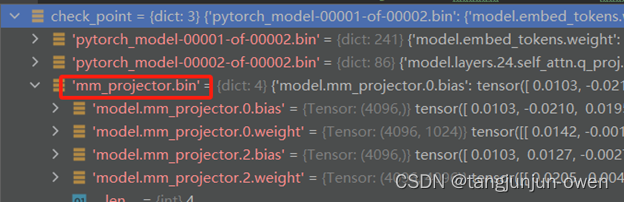
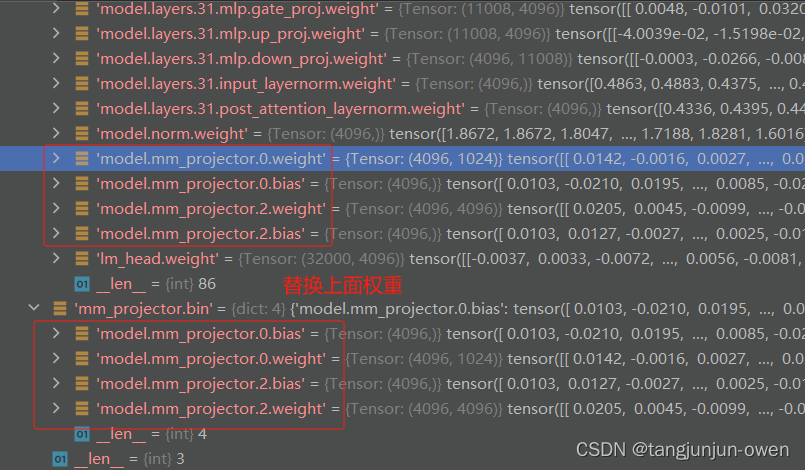
当然,为更好说明该文件内容,我们对比a中大语言模型最后几层内容与该文件内容是一致的。从下图可看出,该权重是上面最后一个权重有同样变量与名称的值,实际该文件权重也是lora训练需要保存的值。我将在后面内容讲解中说明。具体关系如下图显示。
2、llava-v1.5-13b
a、查看pytorch_model-*.bin权重
下图左边是pytorch_model-00001-of-00002.bin权重,右边是pytorch_model-00002-of-00002.bin权重,中间省略了,如下:
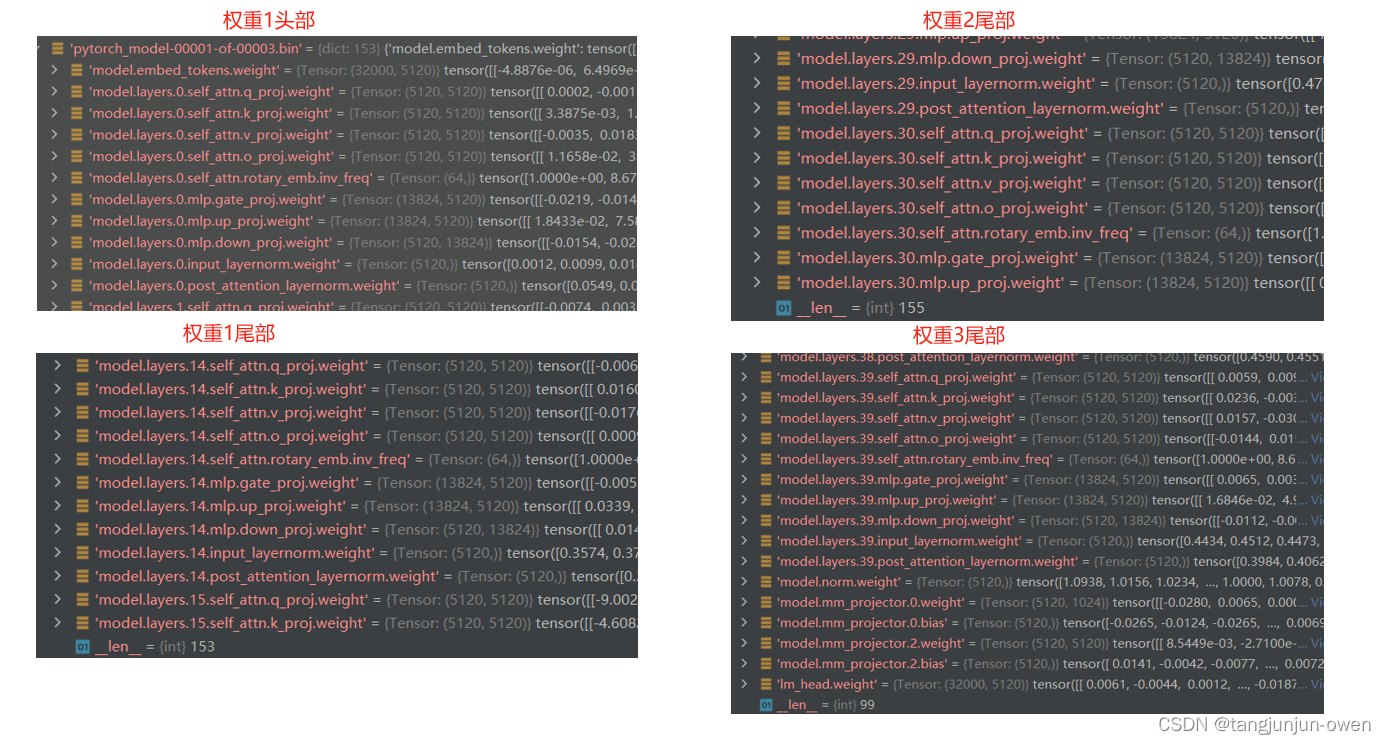
实际上面文件你可以发现,该文件实际就是大语言模型的权重,并没有视觉vit编码权重。
b、mm_projector.bin内容解释
该内容与上面7b一样,从下图可看出,该权重是上面最后一个权重有同样变量与名称的值,实际该文件权重也是lora训练需要保存的值。我将在后面内容讲解中说明。具体关系如下图显示。
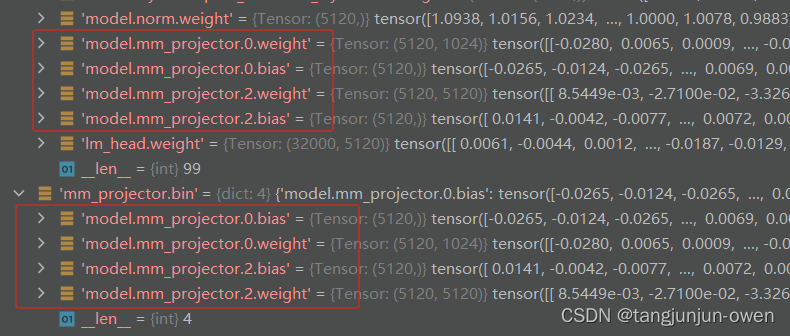
3、llava-v1.5-13b与llava-v1.5-7b对比
主要有以下几个点需要说明:
①、13b就是比7b多了几层,多了几个循环而已;
②、mm_projector.bin都是其一部分内容;
③、13b与7b最后输出分别为(32000,5120)与(32000,4096),其中32000表示llama的tokernizer词汇数。
4、vit视觉编码权重
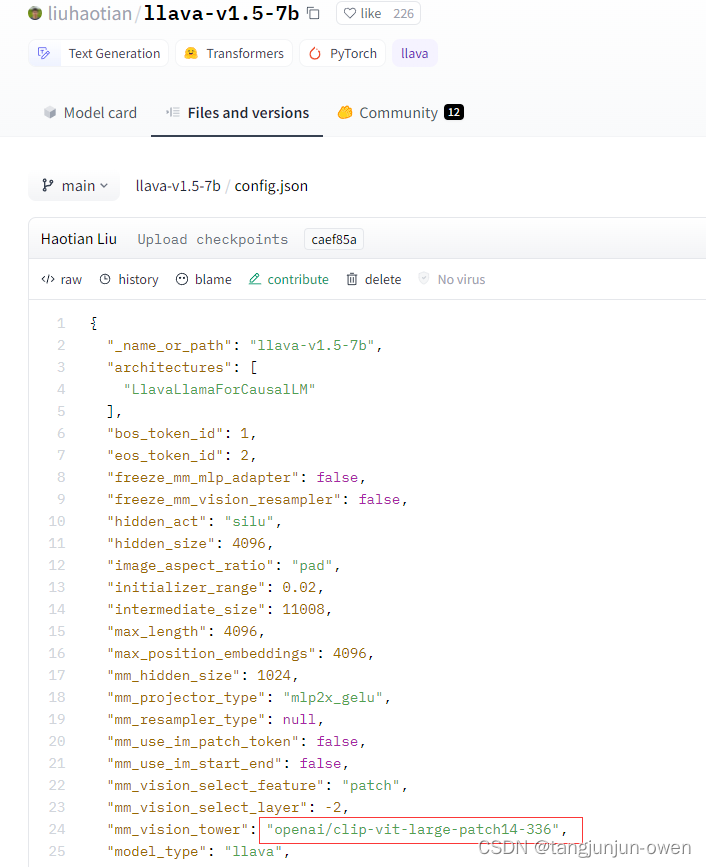
当然,你疑问上面既然只有语言模型和projector,那图像编码权重在哪呢?显然,7b与13b文件夹中的config.json文件中提供了vit编码权重路径,图像编码会根据路径去加载(如下图),我将在这里不在介绍,后期会解释。
三、查看llava-v1.5-13b-lora与llava-v1.5-7b-lora文件权重
可以直接使用权重文件内容我们看了,但大模型不是使用lora训练的嘛,我们如何加载lora权重呢?接下来,我们将介绍具有lora权重文件内容。这2个文件夹权重基本原理类似,我以13b作为介绍,该内容是lora训练,就是–model-path与–model-base结合可以推理,也是后期llava的lora训练会得到的权重文件。
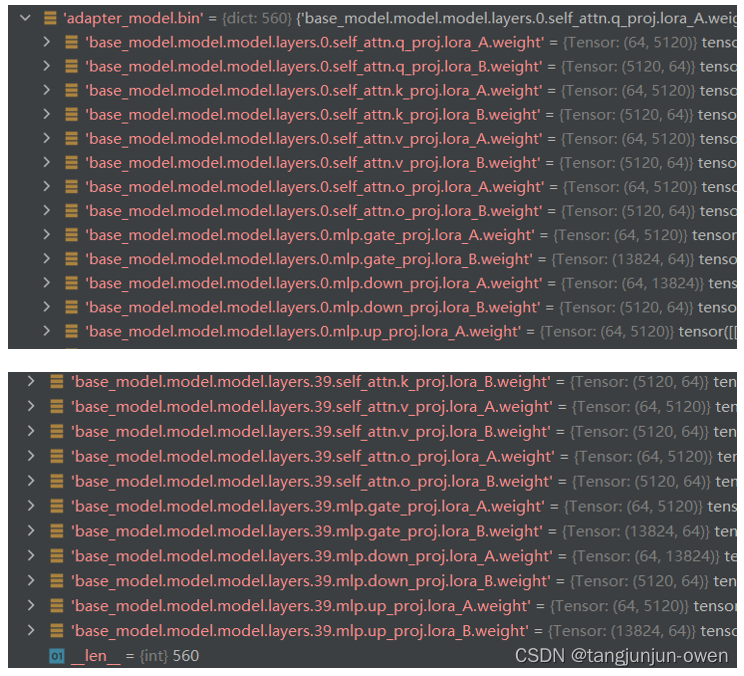
1、adapter_model.bin文件解读
adapter_model.bin文件实际就是保存lora权重的矩阵,而且是大语言模型的权浏览重。我查看模型lora训练基本是冻结图像编码模块,而llama2的权重也是冻结的,但是使用lora微调,则lora权重是会更新的,我给出该权重的头部与尾部内容,如下图:
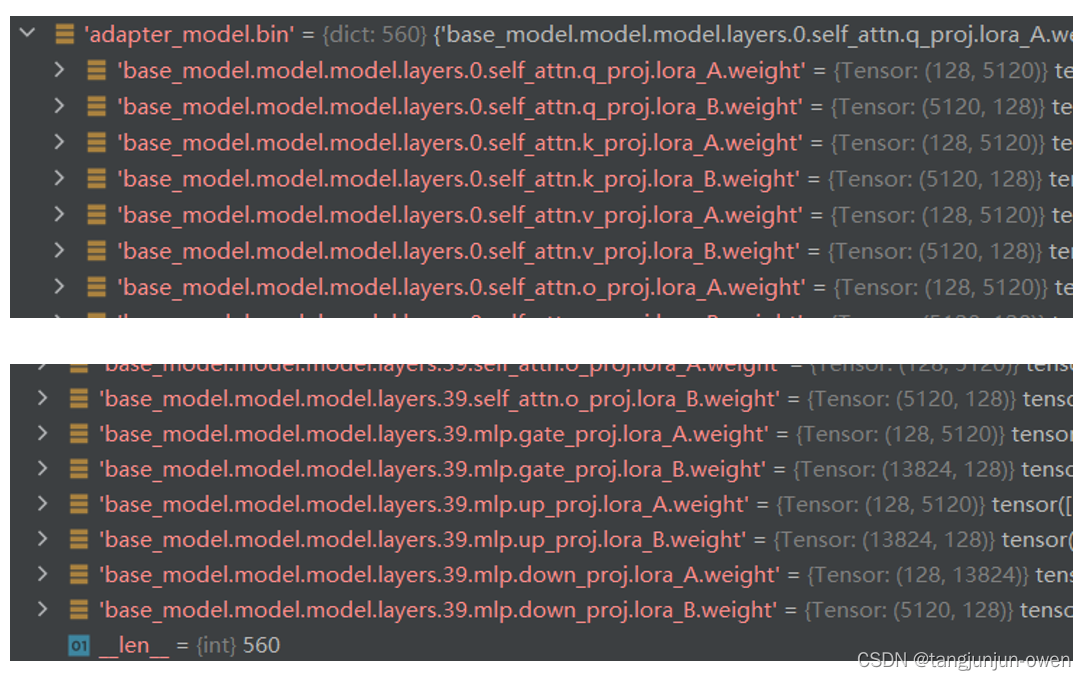
从上图可发现,lora训练刚好都是lora_A与lora_B矩阵,这样刚好实现参数更新,其方法如下图显示。

当然,你也发现了刚好没有第一个model.embed_tokens.weight参数与mm_projector.bin权重,实际是没进行lora训练而是完全微调方式,我想这样就可以添加新增token训练了,且参数也少。
2、non_lora_trainables.bin文件解读
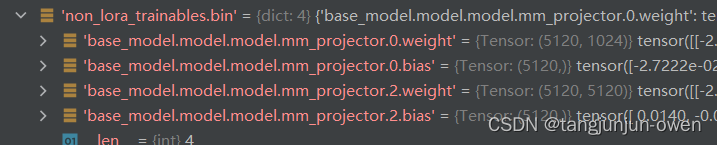
不想说了,实际该文件夹就是mm_projector.bin这个文件夹,是一个不进行微调的文件夹。
3、lora权重变成模型权重
浮出水面了,我们利用w=w+(lora_A*lora_B)*scaling,就可以实现lora微调方式了,而non_lora_trainables.bin对应的权重文件直接替换原有模型对应参数即可。
四、查看llava-v1-0719-336px-lora-vicuna-13b-v1.3文件权重
在上面,我们基本查看了llava可直接推理与使用lora推理权重文件,但我也想介绍一个依然使用lora推理的权重文件内容。这个和之前的lora权重文件类似,我将不在过多介绍,只是给读者呈现显示。
1、adapter_model.bin文件解读
我给出该权重的头部与尾部内容,如下图:
这个和之前说的是一样的。
2、non_lora_trainables.bin文件解读
不想说了,实际该文件夹就是mm_projector.bin这个文件夹,是一个不进行微调的文件夹。但是这个至于一层而已,只是参数问题,不必惊讶。

五、llama的vicuna-13b-v1.5权重文件解读
这个文件是大语言模型文件,该文件是要与lora文件内容共同使用,但以上lora训练的adapter_model.bin文件的lora与本文件llama很相似,实际就是语言llama的lora权重矩阵,这样我们就明白为何该文件需要和lora文件共同使用了。该文件权重内容如下:
同样需要管制下lm_head权重,我的理解应该是预测头权重。
六、lora训练权重文件
上面所有内容都是llava模型自带内容,但我们自己使用lora训练llava模型会保存哪些文件呢?实际答案很明显,一个语言模型的lora权重文件和一个无需lora训练全微调的projector文件,我将在下面说明。
1、保存权重代码修改
为了保存必要的权重文件,我修改了llava的权重文件,该代码内容在LLaVATrainer.py文件中,其修改内容如下:
def _save_checkpoint(self, model, trial, metrics=None):
if getattr(self.args, 'tune_mm_mlp_adapter', False):
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
checkpoint_folder = f"{PREFIX_CHECKPOINT_DIR}-{self.state.global_step}"
run_dir = self._get_output_dir(trial=trial)
output_dir = os.path.join(run_dir, checkpoint_folder)
# Only save Adapter
keys_to_match = ['mm_projector', 'vision_resampler']
if getattr(self.args, "use_im_start_end", False):
keys_to_match.extend(['embed_tokens', 'embed_in'])
weight_to_save = get_mm_adapter_state_maybe_zero_3(self.model.named_parameters(), keys_to_match)
self.model.config.save_pretrained(output_dir)
torch.save(weight_to_save, os.path.join(output_dir, f'non_lora_trainables.bin')) #实际也是'mm_projector.bin'
from llava.train.train import get_peft_state_maybe_zero_3
adapter_model_dict = get_peft_state_maybe_zero_3(model.named_parameters(),"none" ) # 获得adapter_model.bin文件
adapter_model_dict_all = get_mm_adapter_state_maybe_zero_3(model.named_parameters(),"none" )
torch.save(adapter_model_dict, os.path.join(output_dir, f'adapter_model.bin'))
torch.save(adapter_model_dict_all, os.path.join(output_dir, f'adapter_model_all.bin'))
else:
super(LLaVATrainer, self)._save_checkpoint(model, trial, metrics)
2、lora训练权重文件
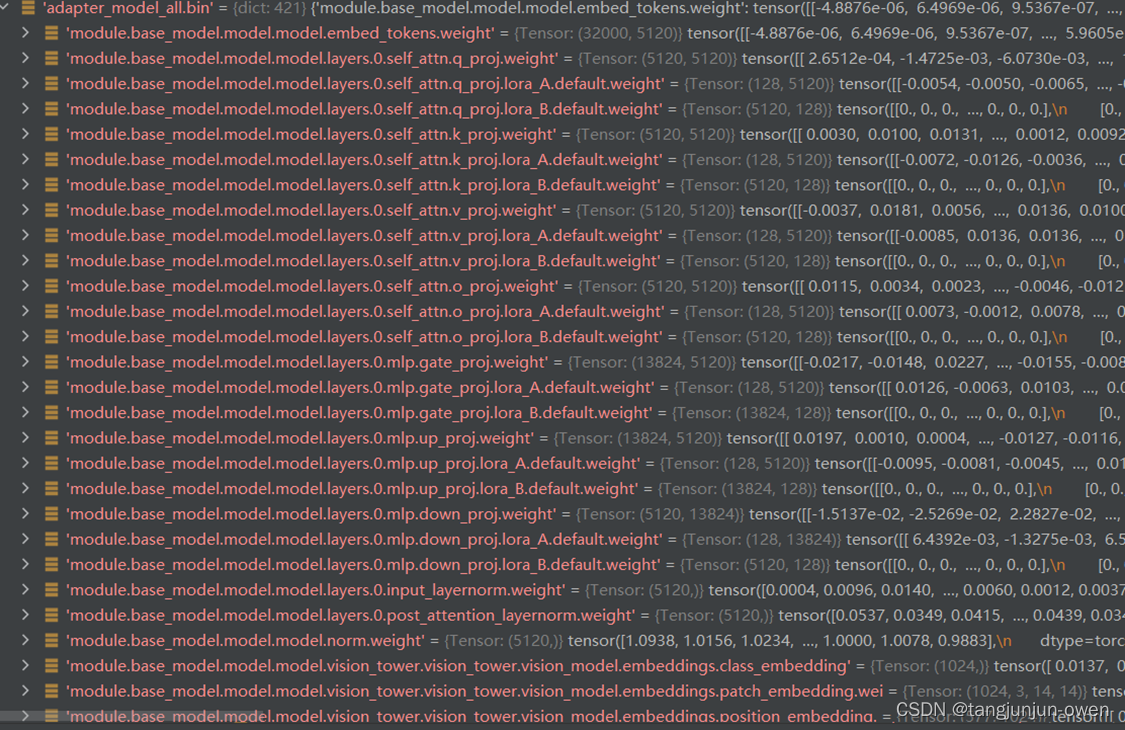
直接说重点,我修改后保存了三个权重文件,adapter_model.bin与non_lora_trainables.bin文件内容如下:
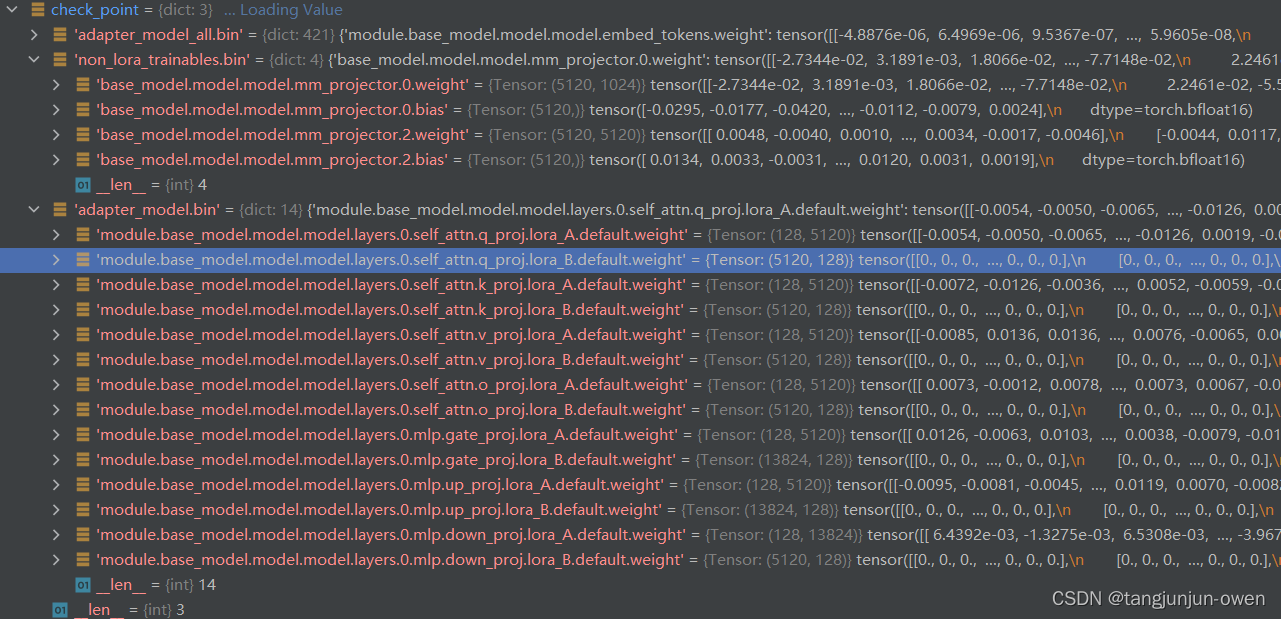
adapter_model_all.bin文件头部与尾部内容(这个文件可以不需要):
头部:
尾部:
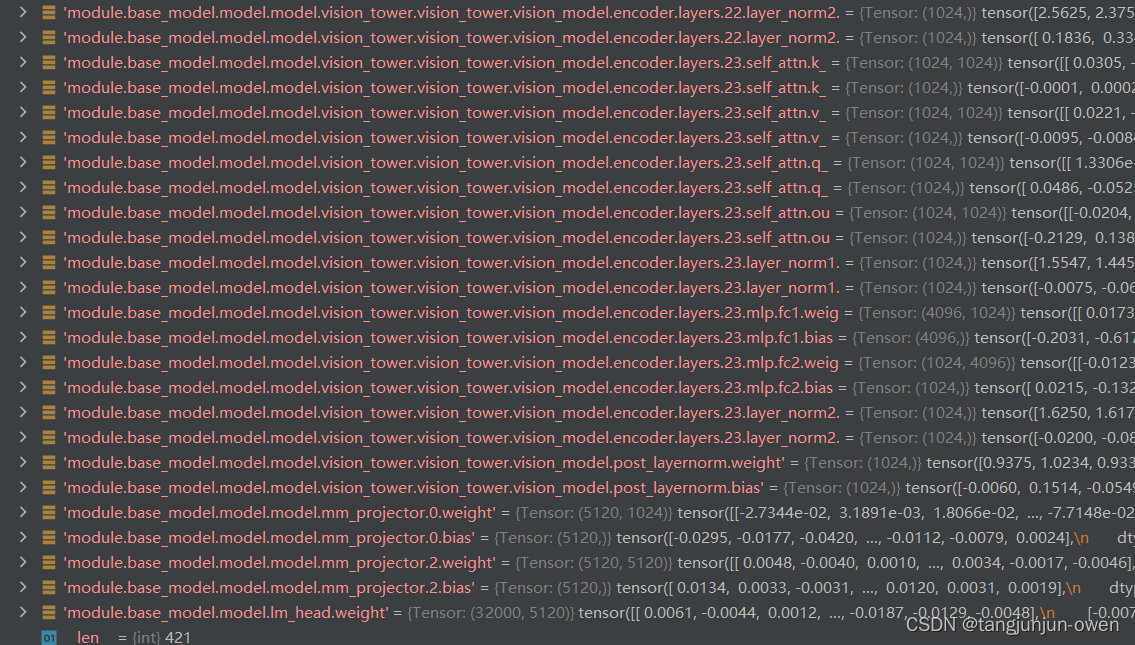
3、内容解读
adapter_model_all.bin保存为lora文件内容,是视觉内容与mlp映射的lora内容,而adapter_model.bin保存是映射层内容,是包含在adapter_model_all.bin文件中(下图已证明),non_lora_trainables.bin是语言模型权重内容,和上面lora说的non_lora_trainables.bin一致。
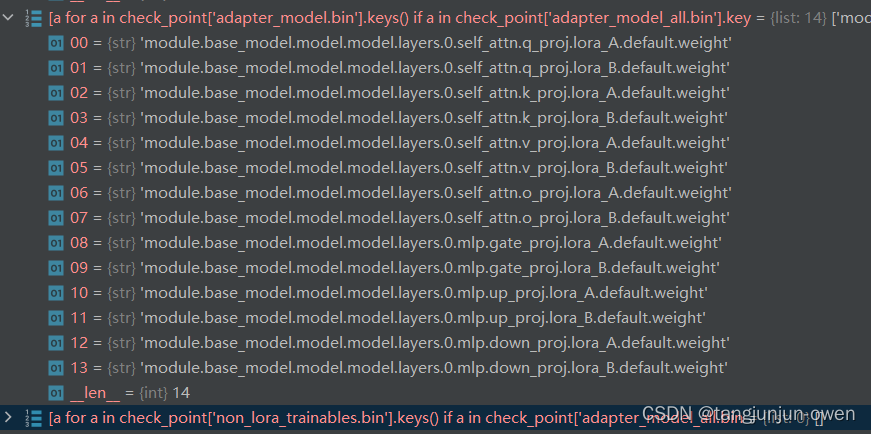
注:我们lora训练保存后的的模型是多了 module. 字符,这个需要注意!
总结
从权重中,你该明白了吧!


















 766
766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











