







视频讲解:
YOLOv12 训练实战,train.py 常用参数介绍
前几期的视频介绍了数据标注、数据集准备以及yolov12的环境准备,今天开始训练
首先创建训练脚本,完整代码如下
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO(model=r'yolov12s.pt')
model.train(
# 指定数据集的配置文件路径,该文件包含了训练集、验证集的路径以及类别信息等
data=r'/home/dar/dev/yolo/dataset/gesture/num_gesture/data.yaml',
# 输入图像的尺寸大小,这里将所有输入图像调整为 640x640 像素
imgsz=640,
# 训练的总轮数,即整个数据集会被模型遍历 50 次
epochs=50,
# 每个批次中包含的图像数量,该值需要根据显存大小进行调整,避免显存溢出
batch=32,
# 用于数据加载的工作线程数量,设置为 0 表示使用主线程进行数据加载
workers=0,
# 指定用于训练的设备,0 表示使用第一块 GPU 进行训练,如果是多 GPU 系统,可通过修改该值选择不同的 GPU
device='0',
# 选择的优化器,这里使用随机梯度下降(SGD)优化器来更新模型的参数
optimizer='SGD',
# 在训练的最后 10 个 epoch 关闭 mosaic 数据增强方法,mosaic 是一种将多张图像拼接在一起进行训练的增强技术
close_mosaic=10,
# 是否从上次中断的位置继续训练,设置为 False 表示不继续,而是从头开始训练
resume=False,
# 训练结果(如模型权重、日志等)保存的项目目录
project='runs/train',
# 本次训练的名称,会作为项目目录下的子目录名,用于区分不同的训练实验
name='exp',
# 是否将所有类别视为一个单一类别进行训练,设置为 False 表示不使用单类别训练模式
single_cls=False,
# 是否开启数据缓存,开启后会将处理过的数据缓存起来,以加快后续训练的速度,但会占用一定的磁盘空间,设置为 False 表示不开启
cache=False,
)过滤warning
warnings.filterwarnings('ignore')指定data.yaml文件路径,前面视频创建的yaml文件
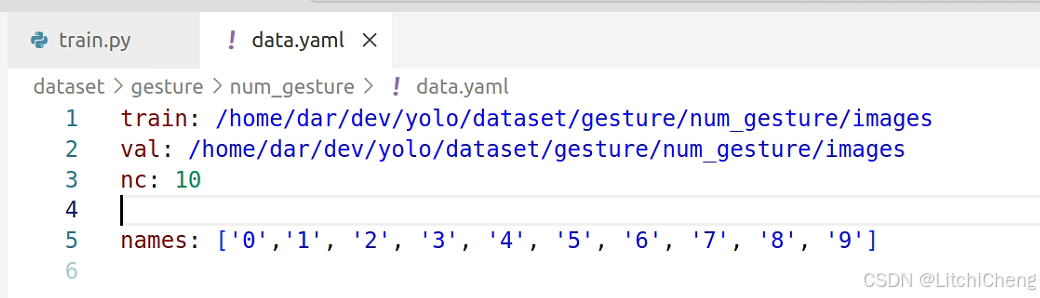
/home/dar/dev/yolo/dataset/gesture/num_gesture/data.yaml如果内存炸了,就把这个降低
batch=32,指定使用哪个gpu,也可以同时用多个,比如'0,1,2',就是用三块gpu
device='0',出现训练中断,如果想要继续,将resume改成True
model = YOLO(model=r'runs/train/exp/weight/last.pt')
resume=True训练开始

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









