



前言
高通智能多媒体 SDK (IM SDK) 提供了构建 AI、多媒体和计算机视觉管道以构建应用程序所需的构建块。Qualcomm IM SDK 可用于构建本机应用程序和基于 docker/容器的 AI 工作流微服务。要构建 AI 工作流微服务,第一步是构建 Qualcomm IM SDK docker 容器镜像。这使您可以获得对源代码的完全访问权限,并自定义和构建自定义工作流。查看高通智能多媒体 SDK 了解更多信息。
准备工作
你已按照构建硬件加速的 Qualcomm IM SDK docker 容器中的步骤构建了 Qualcomm IM SDK docker 容器 或者已经下载了托管在此处的预构建 docker 映像
注意
若要开始使用预构建的泊坞窗,但它提供的自定义选项有限,请参阅入门:运行 AI 工作流示例和 构建硬件加速的 Qualcomm IM SDK docker 容器 。
构建 AI 工作流管道
从高层次上讲,AI 工作流管道分为三个部分。
- 输入:接收和解码输入数据
- AI 推理:预处理输入数据、运行 AI 推理、后处理
- 输出:流式传输 AI 元数据和合成的视频帧
以下示例演示了个人防护装备 (PPE) AI 工作流。相应的 GStreamer start 命令/管道可以在此处找到:qimsdk_ppe.sh
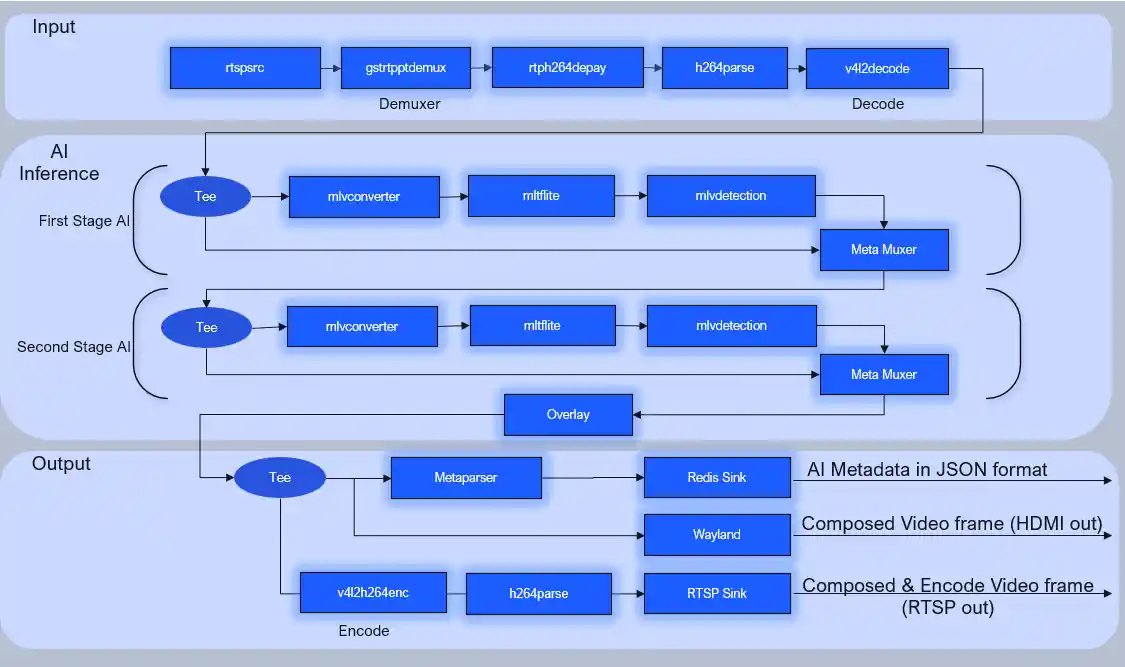
输入
在此 AI 工作流程中,RTSP 摄像机用作输入数据源,以下插件用于接收和解码传入的视频流。
rtspsrc:连接到远程 RTSP 相机,并接收 RTSP 数据rtpptdemux:基于数据包的有效负载类型的 RTP 数据包解复用器rtph264depay:从 RTP 数据包中提取 H264 视频数据包h264parse:解析 H264 流v4l2h264dec:将 H264 流解码为原始 YUV 帧
RTSP
rtspsrc location=<RTSP URL of Remote Camera> ! queue ! rtpptdemux ! rtph264depay ! h264parse ! v4l2h264dec capture-io-mode=5 output-io-mode=5 !
USB 摄像头
v4l2src io-mode=dmabuf-import device=<USB camera device node> !
文件源
filesrc location=<Video filename along with full path> ! qtdemux ! h264parse config-interval=1 ! v4l2h264dec capture-io-mode=5 output-io-mode=5 !
在管道的这一部分之后,通过网络的输入数据就可以用于 AI 处理了
AI 推理
PPE AI 管道预处理、运行菊花链 AI 推理和后处理输入数据
预处理将解码的视频帧转换为 AI 模型可以理解并用于运行推理的张量格式。它包括缩小、颜色转换、张量对齐、纵横比校正等
AI 推理以两阶段菊花链方式运行,其中两个阶段都利用检测模型。第一阶段在整个输入帧上运行并检测帧中的人数。第二阶段在检测到的框架 ROI 部分运行并检测 PPE。AI 推理管道是通用的,因为它接受张量输入并生成张量输出
后处理将输出张量作为输入并生成有意义的元数据,例如边界框坐标、关联的类/标签以及嵌入在输出张量中的其他输出信息。此 AI 元数据与原始帧多路复用,供下游插件使用,例如将 AI 元数据绘制在视频帧顶部的叠加层
AI 推理管道中使用了以下插件
qtimlvconverter:将解码的帧转换为张量、缩小、颜色转换(YUV Raw 到 RGB)、对齐张量并保留纵横比。所有预处理作都是 GPU 加速的qtimltflite(推理):使用 TFlite 运行时运行 AI 推理qtimlvdetection(后处理):将输出张量转换为 AI 元数据qtimetamux:将 AI 元数据附加到视频帧qtioverlay:使用 GLES 在视频帧顶部绘制和 AI 元数据tee:允许将相同的缓冲区共享到并行子管道以进行并行处理
您可以选择要使用的推理插件。Qualcomm IM SDK 支持的推理插件有:
qtimltflite:适用于 TensorFlow Lite 模型。它使用 TensorFlow 运行时qtimlspne:用于高通神经处理引擎 AI 模型qtimlqnn:用于 Qualcomm AI Engine Direct AI 模型
上述插件允许您选择是否要在 CPU、GPU 或 NPU 上运行 AI 模型。查看插件指南 了解更多详情
在此 AI 工作流程中,使用了 TensorFlow Lite 插件。有关更多详细信息,请参阅 qtimltflite 文档
AI 模型路径是推理插件的必填属性。您可以将其更新为自己的 AI 模型,并设置外部委托选项以在 NPU(用于加速 AI 工作负载的专用硬件)上加速它,如下所示:
qtimltflite name=stage_01_inference delegate=external external-delegate-path=libQnnTFLiteDelegate.so external-delegate-options="QNNExternalDelegate,backend_type=htp;" model=/etc/media/foot_track_net_quantized.tflite
AI 推理输出张量馈送到后处理阶段后,高通 IM SDK 提供了以下后处理插件
qtimlvclassification:用于视频/图像分类模型的后处理插件qtimlvdetection:视频/图像检测模型的后处理插件qtimlvpose:用于姿态估计模型的后处理插件qtimlvsegmentation:用于视频/图像分割模型的后处理插件qtimlvsuperresolution:用于视频/图像高档模型的后处理插件
每个后处理插件都有子模块。该插件封装了 模型类型,子模块封装了实际特定于模型的张量后处理。插件 获取张量(推理后的输出张量)并将它们解析为 AI 元数据。请参阅 插件指南 和插件源代码 了解更多详情
gst-inspect 实用程序可用于列出后处理插件支持的子模块
gst-inspect-1.0 qtimlvdetection
module 将用于处理张量的模块名称
(0): none - No module, default invalid mode
(1): east-textdt - ml-vdetection-east-textdt
(2): yolo-nas - ml-vdetection-yolo-nas
(3): qfd - ml-vdetection-qfd
(4): yolov8 - ml-vdetection-yolov8
(5): yolov5 - ml-vdetection-yolov5
(6): qpd - ml-vdetection-qpd
(7): ssd-mobilenet - ml-vdetection-ssd-mobilenet
(0): none - 无模块,默认无效模式
(1):东方文本 - ml-vdetection-east-textdt
(2):YOLO-NAS - ML-VDETECTION-YOLO-NAS
(3):QFD - ML-Vdetection-QFD
(4):YOLOV8 - ML-Vdetection-YOLOV8
(5):YOLOV5 - ML-Vdetection-YOLOV5
(6):qpd-ml-vdetection-qpd
(7):固态硬盘-移动网 - ml-vdetection-ssd-mobilenet
在参考 PPE AI 工作流程中,qtimlvdetection 用于两个阶段(人员检测和 PPE 检测)
您可以设置属性,例如特定于 AI 模型的检测阈值、子模块名称、量化系数和标签文件
第一阶段
qtimlvdetection name=stage_01_postproc threshold=90.0 stabilization=true results=10 module=qpd constants="qpd,q-offsets=<0.0,25.0,114.0,0.0>,q-scales=<0.0035636962857097387,1.2998489141464233,2.1744511127471924,0.00390625>;" labels=/opt/labels/ppe/foot_track_net.labels \
第二阶段
qtimlvdetection name=stage_02_postproc threshold=51.0 stabilization=true results=10 module=yolov5 constants="YoloV5,q-offsets=<180.0,178.0,170.0>,q-scales=<0.09695824235677719,0.08805476874113083,0.08215426653623581>;" labels=/opt/labels/ppe/gear_guard_net.labels \
输出
在参考 PPE AI 工作流中,支持以下类型的输出
- 通过 Redis 流的 AI 元数据流
- RTSP stream over network 通过网络的 RTSP 流
AI 元数据,AI 推理的输出被解析并转换为 JSON blob
使用 Redis 接收器插件将 blob 传输到 Redis 代理,该插件允许系统中运行的其他微服务侦听和使用 AI 元数据。
应用叠加层以启用实时可视化后,原始视频帧将传输到 Wayland 接收器插件进行实时渲染
您可以根据需要和输出类型决策修改管道的输出部分。以下插件用于输出。
qitmlmetaparse:将 AI 元数据转换为 JSON 格式qtiredissink:将 JSON 格式的 AI 元数据发布到 Redis 代理。与一个视频帧关联的 AI 元数据将作为一条 Redis 消息发送wayland:使用 Wayland 协议将原始视频帧渲染到 HDMI 显示器qtirtespbin:通过 RTSP 流式传输编码视频。RTSP 服务器作为插件的一部分实现
工作流微服务中的 AI 元数据通过 Redis 代理消息传递系统发布。您可以配置 Redis 通道名称、Redis Broker 主机 IP 和端口
对于视觉输出,使用 HDMI 显示和 RTSP 视频流
对于 HDMI 显示,如下所示配置显示管道。任何一个都可以渲染全屏视频并将其设置为特定的屏幕坐标
! waylandsink name=display sync=false async=false fullscreen=true
对于 RTSP 视频流,请配置流式处理管道,如下所示。可以选择 H264 或 H265 编码
! v4l2h264enc name=encoder capture-io-mode=5 output-io-mode=5 ! queue ! h264parse config-interval=1 ! queue ! qtirtspbin address=0.0.0.0 port=8900
如果不需要对管道进行上述更改,请继续将管道打包到 QIMSDK 容器中
如果上述流水线需要在 Qualcomm IM SDK 源中进行修改,或者您想在微服务中添加自定义 AI 模型,请确保以下内容:
- AI 模型与 支持推理运行时
- 该工作流处理自定义类的后处理。看 如何添加后处理
如果模型兼容且启用了后处理,请执行以下作以在 docker 容器环境中启用新插件
在 中 /iot-solutions/gst-plugins-qti-oss 添加 CMake 和源代码。请参阅检测示例 。
在 添加 BitBake 配方。 <workspace>/iot-solutions/meta-qti-gst 请参阅检测配方示例 <https://git.codelinaro.org/clo/le/meta-qti-gst/-/blob/imsdk.lnx.2.0.0.r2-rel/recipes-gst/gstreamer/qcom-gstreamer1.0-plugins-oss-mlvdetection.bb?ref_type=heads>
将新的插件类添加到 sdk-tools 构建脚本中。
https://git.codelinaro.org/clo/le/sdk-tools/-/blob/imsdk-tools.lnx.1.0/qimsdk/scripts/dev_image/build.sh?ref_type=heads#L399
从 Dockerfile 添加依赖项 (第 15 行) 以防存在任何 docker 构建时间依赖项
从 Dockerfile 添加依赖项 (第 235 行) 以防存在任何 docker 构建时间依赖项
继续打包新容器


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









