






点击下方卡片,关注“小白玩转Python”公众号

介绍
YOLO长期以来一直是目标检测任务的首选模型之一。它既快速又准确。此外,其API简洁易用。运行训练或推断作业所需的代码行数有限。在2023年下半年,YOLOv8在框架中引入了姿态估计后,该框架现在支持最多四个任务,包括分类、目标检测、实例分割和姿态估计。

在本文中,我们将详细介绍YOLOv8中使用的五个损失函数。请注意,我们将仅讨论YOLOv8仓库中配置的默认损失函数。此外,我们还将仅关注代表性参数,跳过一些标量和常数以进行归一化或缩放,以便更好地理解。YOLOv8中对应的任务和损失函数可见于图1。接下来我们将分别对每一个进行讨论。
IoU损失
cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU当考虑评估边界框准确度的方式时,交并比(IoU)指标可能是大多数人首先想到的一个指标。IoU度量了预测的边界框与实际边界框之间的重叠程度。它也可以作为一个损失函数,只需将IoU转换为1-IoU。
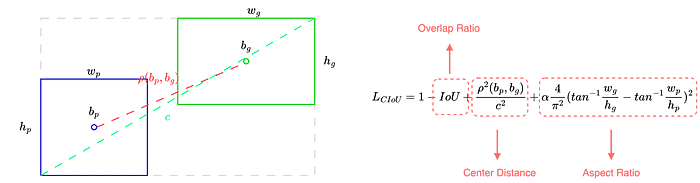
在YOLOv8中,修订后的版本,完全IoU(CIoU)¹被应用于衡量预测边界框与实际边界框之间的差异。CIoU是一个综合性指标,它考虑了边界框之间的三个属性:
重叠比
中心点之间的距离
长宽比
CIoU的方程可在图2右侧找到。重叠比、中心点距离和长宽比这三个因素分别由方程中的各项表示。方程中涉及的关键参数在左侧的图中进行了说明,其中p和g表示预测和实际情况,b、w和h分别是相应边界框的中心、宽度和高度。参数c是包围边界框的对角线(灰色虚线矩形)而ρ是欧氏距离。除了分类任务外,IoU损失在YOLOv8中的所有其他任务中都会应用。
分布焦点损失(DFL)
def _df_loss(pred_dist, target):
"""Return sum of left and right DFL losses."""
# Distribution Focal Loss (DFL) proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391
tl = target.long() # target left
tr = tl + 1 # target right
wl = tr - target # weight left
wr = 1 - wl # weight right
return (F.cross_entropy(pred_dist, tl.view(-1), reduction='none').view(tl.shape) * wl +
F.cross_entropy(pred_dist, tr.view(-1), reduction='none').view(tl.shape) * wr).mean(-1, keepdim=True)另一个与边界框相关的损失函数是分布焦点损失(DFL)²。DFL关注的是边界框回归的分布差异。YOLOv8中的网络不是直接预测边界框,而是预测边界框的概率分布。它旨在解决边界模糊或部分遮挡的挑战性对象。
关键点损失

loss[1] += self.keypoint_loss(pred_kpt, gt_kpt, kpt_mask, area)
area:bounding box area
class KeypointLoss(nn.Module):
def forward(self, pred_kpts, gt_kpts, kpt_mask, area):
"""Calculates keypoint loss factor and Euclidean distance loss for predicted and actual keypoints."""
d = (pred_kpts[..., 0] - gt_kpts[..., 0]) ** 2 + (pred_kpts[..., 1] - gt_kpts[..., 1]) ** 2
kpt_loss_factor = (torch.sum(kpt_mask != 0) + torch.sum(kpt_mask == 0)) / (torch.sum(kpt_mask != 0) + 1e-9)
# e = d / (2 * (area * self.sigmas) ** 2 + 1e-9) # from formula
e = d / (2 * self.sigmas) ** 2 / (area + 1e-9) / 2 # from cocoeval
return kpt_loss_factor * ((1 - torch.exp(-e)) * kpt_mask).mean()在YOLOv8中,首次将姿态估计任务纳入到框架中。姿态由一组关键点的坐标和顺序定义。关键点损失监控了预测和实际关键点之间的相似性。两个对应关键点之间的欧几里得距离是关键点损失的主要组成部分。此外,每个关键点都带有一个权重σ,定义了关键点的重要性,默认值为1/关键点数。例如,如果姿态有四个关键点,则所有关键点的权重为1/4 = 0.25。
关键点目标损失

import torch.nn as nn
loss[2] = nn.BCEWithLogitsLoss(pred_kpt[..., 2], kpt_mask.float())在大多数姿态估计训练中,我们可以定义每个关键点的可见性。Python脚本中的参数kpt_mask携带了我们在标签中定义的可见性(1/0)。关键点目标损失计算关键点存在的距离。在YOLOv8中,距离由预测值和实际值的二元交叉熵(BCE)测量。
分类损失和掩码损失
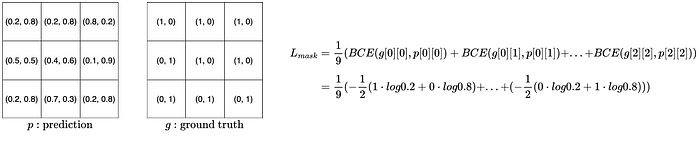
import torch.nn as nn
loss[3] = nn.BCEWithLogitLoss(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE分类损失是涉及到所有任务的唯一损失函数。无论我们是在进行分类、目标检测、分割还是姿态估计,图像或特定对象的类别(例如猫、狗、人等)的推断结果之间的距离都是通过二元交叉熵(BCE)计算的。
它还适用于实例分割中的掩码损失。掩码损失将每个像素视为一个对象,并计算相关的BCE值。在图5中计算了一个3x3的预测掩码和相应的掩码损失。
总损失
# yolo/cfg/default.yaml
...
box: 7.5 # box loss gain
cls: 0.5 # cls loss gain (scale with pixels)
dfl: 1.5 # dfl loss gain
pose: 12.0 # pose loss gain
kobj: 1.0 # keypoint obj loss gain
...好了,以上我们已经介绍了所有六个损失。在网络应用反向传播并更新其参数之前,将损失与相应的权重相加。权重在配置文件default.yaml中定义,如上所示。如果您想在训练阶段动态调整权重,您可以考虑直接在存储库中使用下面提供的代码片段。
loss[0] *= self.hyp.box # box gain
loss[1] *= self.hyp.pose / batch_size # pose gain
loss[2] *= self.hyp.kobj / batch_size # kobj gain
loss[3] *= self.hyp.cls # cls gain
loss[4] *= self.hyp.dfl # dfl gain
return loss.sum() * batch_size, loss.detach()总结
YOLO是一个为目标检测任务而知名的框架。除了在效率和准确性方面的表现之外,它还在不断更新最新的研究成果。这是一个让计算机视觉从业者跟踪和学习入选技术的好框架。损失函数在模型训练中起着重要作用,并决定了最终的准确性。
· END ·
🌟 想要变身计算机视觉小能手?快来「小白玩转Python」公众号!
回复“Python视觉实战项目”,解锁31个超有趣的视觉项目大礼包!🎁

本文仅供学习交流使用,如有侵权请联系作者删除

















 2937
2937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









