






 本文深入解析了FPN网络,一种高效的目标检测与分割框架。它通过融合不同层级的特征图,提高了模型对不同尺度目标的检测能力,尤其在COCO数据集上表现出色。
本文深入解析了FPN网络,一种高效的目标检测与分割框架。它通过融合不同层级的特征图,提高了模型对不同尺度目标的检测能力,尤其在COCO数据集上表现出色。
FPN网络的目的
在目标检测和分割当中,大部分时候我们要检测的物体在图像中的尺寸是不固定的,在网络中一般有下采样的过程,在最后一层上进行检测对大物体的检测比较有效(感受野较大,压缩了更多的信息),在上层的特征图上进行检测对小物体的检测比较有效(因为包含更丰富的信息),那么,怎样融合让对大物体和小物体的检测都很鲁棒呢?
FPN的提出来自一篇论文:
Feature Pyramid Networks for Object Detection
链接:https://arxiv.org/abs/1612.03144
特征金字塔是识别系统中用于检测不同比例物体的基本组件。但是最近的深度学习对象检测器避免了金字塔表示,部分原因是它们需要大量计算和内存。该文章中作者提出了一种高效的特征金字塔,仅需要轻微的额外花销,在coco数据集上的表现胜于任何一个one-stage检测模型.
介绍
金字塔的主要目的在于检测不同尺度的目标,特征图的尺度越多,可检测的尺寸变化也就越多.特征金字塔在手工特征中非常常见也很重要.现如今,传统算法逐渐被深度学习(卷积网络)取代,单个特征图的输出也能很好地抗形变的变化.但是,特征金字塔仍然对于检测的精度有很重要的意义.其好处是在不同的尺度的特征图上进行检测.
但是这种做法会明显增加预测的耗时,所以Fast and Faster R-CNN 并没有使用这种方法.
适用于多尺度的方式不知特征金字塔,还有特征等级,但是作者任何高层的语义不应该掺杂底层的语义,简单的相加没有意义.
作者认为,FPN对于目标检测和分割的精度都有提升,每一层都体现了丰富的语义.
相关工作
手工特征
像sift和hog,都用了特征金字塔;
深度学习检测
大部分都是用单尺度的特征图,因为这样在性能和速度方面性价比很高.
也有很多使用了多尺度,比如FCN前后对应大小的层相加,还有一些网络是contate,还有一些是在不同的尺度上预测,还有一些是短接的方式将高层和低层融合.
我们的工作
我们的目的是融合高层和低层的特征图,输出具有丰富语义的特征图.
我们的FPN网络可以接在任意的backbone后面,输入大小任意,输出是成比例的,我们主干用的ResNet.
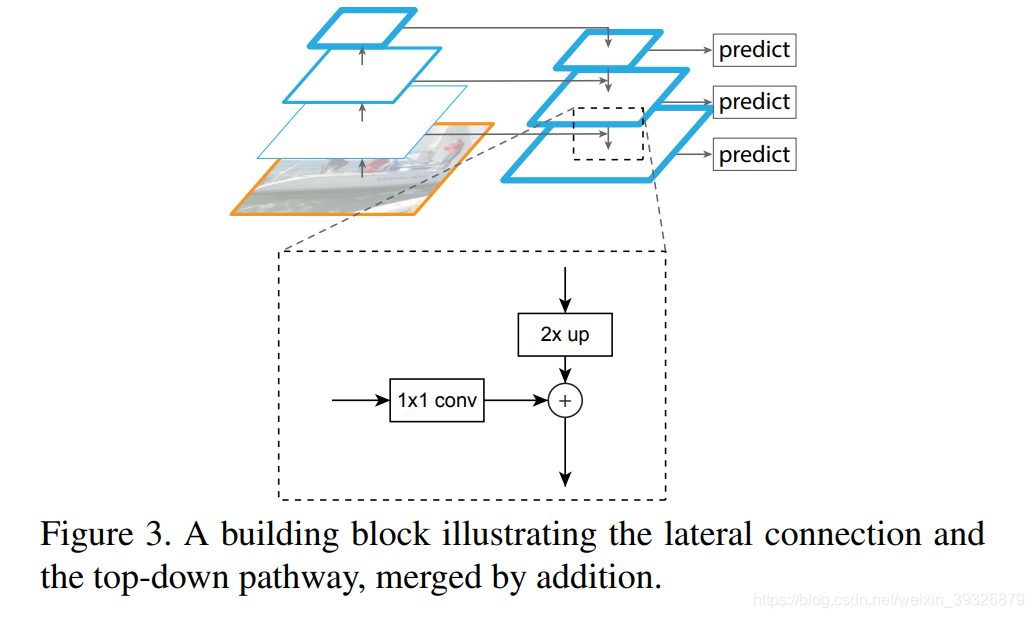
我们的FPN用了自上而下\自下而上以及侧向链接,如下图所示:
Bottom-up pathway
自下而上的方式,在网络中,每几层特征图大小相同我们称同一个level,我们取每一个level的最后一层组成我的金字塔(因为最后一层有最强的特征提取),前面的几个level不要,因为太大了.这样,在resNet中,我们可以取后四个Residual Block(s {C2, C3, C4, C5}),它们相对于原图的尺度倍数为 {4, 8, 16, 32}.
Top-down pathway and lateral connections
关于流程,如上面的图所示:自上而下和侧接,
将小图做上采样,跟同样尺寸的Bottom-up直接做像素相加,要通过11的卷积使通道相同然后再相加.作者说这个过程可以迭代,最后在经过33的卷积得到最终的结果(这是为了减少上采样的错误影响),作者也有尝试残差的短接,结果有轻微的提升,但是本文不是研究如何链接,所以采用了简单的方式.
看代码可能比论文更直观,代码中并没有迭代的过程,就是上采样直接相加而已:
Skip to content
Search or jump to…
Pull requests
Issues
Marketplace
Explore
@Mazhengyu93
jwyang
/
fpn.pytorch
19
702170
Code
Issues
46
Pull requests
2
Actions
Projects
Wiki
Security
Insights
fpn.pytorch/lib/model/fpn/fpn.py /
Jianwei Yang minior change to fpn and anchor_scales
Latest commit 97fb94f on 14 Jan 2018
History
0 contributors
270 lines (235 sloc) 11.5 KB
import random
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable, gradcheck
from torch.autograd.gradcheck import gradgradcheck
import torchvision.models as models
from torch.autograd import Variable
import numpy as np
import torchvision.utils as vutils
from model.utils.config import cfg
from model.rpn.rpn_fpn import _RPN_FPN
from model.roi_pooling.modules.roi_pool import _RoIPooling
from model.roi_crop.modules.roi_crop import _RoICrop
from model.roi_align.modules.roi_align import RoIAlignAvg
from model.rpn.proposal_target_layer import _ProposalTargetLayer
from model.utils.net_utils import _smooth_l1_loss, _crop_pool_layer, _affine_grid_gen, _affine_theta
import time
import pdb
class _FPN(nn.Module):
""" FPN """
def __init__(self, classes, class_agnostic):
super(_FPN, self).__init__()
self.classes = classes
self.n_classes = len(classes)
self.class_agnostic = class_agnostic
# loss
self.RCNN_loss_cls = 0
self.RCNN_loss_bbox = 0
self.maxpool2d = nn.MaxPool2d(1, stride=2)
# define rpn
self.RCNN_rpn = _RPN_FPN(self.dout_base_model)
self.RCNN_proposal_target = _ProposalTargetLayer(self.n_classes)
# NOTE: the original paper used pool_size = 7 for cls branch, and 14 for mask branch, to save the
# computation time, we first use 14 as the pool_size, and then do stride=2 pooling for cls branch.
self.RCNN_roi_pool = _RoIPooling(cfg.POOLING_SIZE, cfg.POOLING_SIZE, 1.0/16.0)
self.RCNN_roi_align = RoIAlignAvg(cfg.POOLING_SIZE, cfg.POOLING_SIZE, 1.0/16.0)
self.grid_size = cfg.POOLING_SIZE * 2 if cfg.CROP_RESIZE_WITH_MAX_POOL else cfg.POOLING_SIZE
self.RCNN_roi_crop = _RoICrop()
def _init_weights(self):
def normal_init(m, mean, stddev, truncated=False):
"""
weight initalizer: truncated normal and random normal.
"""
# x is a parameter
if truncated:
m.weight.data.normal_().fmod_(2).mul_(stddev).add_(mean) # not a perfect approximation
else:
m.weight.data.normal_(mean, stddev)
m.bias.data.zero_()
# custom weights initialization called on netG and netD
def weights_init(m, mean, stddev, truncated=False):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
m.bias.data.fill_(0)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
normal_init(self.RCNN_toplayer, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_smooth1, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_smooth2, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_smooth3, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_latlayer1, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_latlayer2, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_latlayer3, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_rpn.RPN_Conv, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_rpn.RPN_cls_score, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_rpn.RPN_bbox_pred, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_cls_score, 0, 0.01, cfg.TRAIN.TRUNCATED)
normal_init(self.RCNN_bbox_pred, 0, 0.001, cfg.TRAIN.TRUNCATED)
weights_init(self.RCNN_top, 0, 0.01, cfg.TRAIN.TRUNCATED)
def create_architecture(self):
self._init_modules()
self._init_weights()
def _upsample_add(self, x, y):
'''Upsample and add two feature maps.
Args:
x: (Variable) top feature map to be upsampled.
y: (Variable) lateral feature map.
Returns:
(Variable) added feature map.
Note in PyTorch, when input size is odd, the upsampled feature map
with `F.upsample(..., scale_factor=2, mode='nearest')`
maybe not equal to the lateral feature map size.
e.g.
original input size: [N,_,15,15] ->
conv2d feature map size: [N,_,8,8] ->
upsampled feature map size: [N,_,16,16]
So we choose bilinear upsample which supports arbitrary output sizes.
'''
_,_,H,W = y.size()
return F.upsample(x, size=(H,W), mode='bilinear') + y
def _PyramidRoI_Feat(self, feat_maps, rois, im_info):
''' roi pool on pyramid feature maps'''
# do roi pooling based on predicted rois
img_area = im_info[0][0] * im_info[0][1]
h = rois.data[:, 4] - rois.data[:, 2] + 1
w = rois.data[:, 3] - rois.data[:, 1] + 1
roi_level = torch.log(torch.sqrt(h * w) / 224.0)
roi_level = torch.round(roi_level + 4)
roi_level[roi_level < 2] = 2
roi_level[roi_level > 5] = 5
# roi_level.fill_(5)
if cfg.POOLING_MODE == 'crop':
# pdb.set_trace()
# pooled_feat_anchor = _crop_pool_layer(base_feat, rois.view(-1, 5))
# NOTE: need to add pyrmaid
grid_xy = _affine_grid_gen(rois, base_feat.size()[2:], self.grid_size)
grid_yx = torch.stack([grid_xy.data[:,:,:,1], grid_xy.data[:,:,:,0]], 3).contiguous()
roi_pool_feat = self.RCNN_roi_crop(base_feat, Variable(grid_yx).detach())
if cfg.CROP_RESIZE_WITH_MAX_POOL:
roi_pool_feat = F.max_pool2d(roi_pool_feat, 2, 2)
elif cfg.POOLING_MODE == 'align':
roi_pool_feats = []
box_to_levels = []
for i, l in enumerate(range(2, 6)):
if (roi_level == l).sum() == 0:
continue
idx_l = (roi_level == l).nonzero().squeeze()
box_to_levels.append(idx_l)
scale = feat_maps[i].size(2) / im_info[0][0]
feat = self.RCNN_roi_align(feat_maps[i], rois[idx_l], scale)
roi_pool_feats.append(feat)
roi_pool_feat = torch.cat(roi_pool_feats, 0)
box_to_level = torch.cat(box_to_levels, 0)
idx_sorted, order = torch.sort(box_to_level)
roi_pool_feat = roi_pool_feat[order]
elif cfg.POOLING_MODE == 'pool':
roi_pool_feats = []
box_to_levels = []
for i, l in enumerate(range(2, 6)):
if (roi_level == l).sum() == 0:
continue
idx_l = (roi_level == l).nonzero().squeeze()
box_to_levels.append(idx_l)
scale = feat_maps[i].size(2) / im_info[0][0]
feat = self.RCNN_roi_pool(feat_maps[i], rois[idx_l], scale)
roi_pool_feats.append(feat)
roi_pool_feat = torch.cat(roi_pool_feats, 0)
box_to_level = torch.cat(box_to_levels, 0)
idx_sorted, order = torch.sort(box_to_level)
roi_pool_feat = roi_pool_feat[order]
return roi_pool_feat
def forward(self, im_data, im_info, gt_boxes, num_boxes):
batch_size = im_data.size(0)
im_info = im_info.data
gt_boxes = gt_boxes.data
num_boxes = num_boxes.data
# feed image data to base model to obtain base feature map
# Bottom-up
c1 = self.RCNN_layer0(im_data)
c2 = self.RCNN_layer1(c1)
c3 = self.RCNN_layer2(c2)
c4 = self.RCNN_layer3(c3)
c5 = self.RCNN_layer4(c4)
# Top-down
p5 = self.RCNN_toplayer(c5)
p4 = self._upsample_add(p5, self.RCNN_latlayer1(c4))
p4 = self.RCNN_smooth1(p4)
p3 = self._upsample_add(p4, self.RCNN_latlayer2(c3))
p3 = self.RCNN_smooth2(p3)
p2 = self._upsample_add(p3, self.RCNN_latlayer3(c2))
p2 = self.RCNN_smooth3(p2)
p6 = self.maxpool2d(p5)
rpn_feature_maps = [p2, p3, p4, p5, p6]
mrcnn_feature_maps = [p2, p3, p4, p5]
rois, rpn_loss_cls, rpn_loss_bbox = self.RCNN_rpn(rpn_feature_maps, im_info, gt_boxes, num_boxes)
# if it is training phrase, then use ground trubut bboxes for refining
if self.training:
roi_data = self.RCNN_proposal_target(rois, gt_boxes, num_boxes)
rois, rois_label, gt_assign, rois_target, rois_inside_ws, rois_outside_ws = roi_data
## NOTE: additionally, normalize proposals to range [0, 1],
# this is necessary so that the following roi pooling
# is correct on different feature maps
# rois[:, :, 1::2] /= im_info[0][1]
# rois[:, :, 2::2] /= im_info[0][0]
rois = rois.view(-1, 5)
rois_label = rois_label.view(-1).long()
gt_assign = gt_assign.view(-1).long()
pos_id = rois_label.nonzero().squeeze()
gt_assign_pos = gt_assign[pos_id]
rois_label_pos = rois_label[pos_id]
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
rois_label = Variable(rois_label)
rois_target = Variable(rois_target.view(-1, rois_target.size(2)))
rois_inside_ws = Variable(rois_inside_ws.view(-1, rois_inside_ws.size(2)))
rois_outside_ws = Variable(rois_outside_ws.view(-1, rois_outside_ws.size(2)))
else:
## NOTE: additionally, normalize proposals to range [0, 1],
# this is necessary so that the following roi pooling
# is correct on different feature maps
# rois[:, :, 1::2] /= im_info[0][1]
# rois[:, :, 2::2] /= im_info[0][0]
rois_label = None
gt_assign = None
rois_target = None
rois_inside_ws = None
rois_outside_ws = None
rpn_loss_cls = 0
rpn_loss_bbox = 0
rois = rois.view(-1, 5)
pos_id = torch.arange(0, rois.size(0)).long().type_as(rois).long()
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
# pooling features based on rois, output 14x14 map
roi_pool_feat = self._PyramidRoI_Feat(mrcnn_feature_maps, rois, im_info)
# feed pooled features to top model
pooled_feat = self._head_to_tail(roi_pool_feat)
# compute bbox offset
bbox_pred = self.RCNN_bbox_pred(pooled_feat)
if self.training and not self.class_agnostic:
# select the corresponding columns according to roi labels
bbox_pred_view = bbox_pred.view(bbox_pred.size(0), int(bbox_pred.size(1) / 4), 4)
bbox_pred_select = torch.gather(bbox_pred_view, 1, rois_label.long().view(rois_label.size(0), 1, 1).expand(rois_label.size(0), 1, 4))
bbox_pred = bbox_pred_select.squeeze(1)
# compute object classification probability
cls_score = self.RCNN_cls_score(pooled_feat)
cls_prob = F.softmax(cls_score)
RCNN_loss_cls = 0
RCNN_loss_bbox = 0
if self.training:
# loss (cross entropy) for object classification
RCNN_loss_cls = F.cross_entropy(cls_score, rois_label)
# loss (l1-norm) for bounding box regression
RCNN_loss_bbox = _smooth_l1_loss(bbox_pred, rois_target, rois_inside_ws, rois_outside_ws)
rois = rois.view(batch_size, -1, rois.size(1))
cls_prob = cls_prob.view(batch_size, -1, cls_prob.size(1))
bbox_pred = bbox_pred.view(batch_size, -1, bbox_pred.size(1))
if self.training:
rois_label = rois_label.view(batch_size, -1)
return rois, cls_prob, bbox_pred, rpn_loss_cls, rpn_loss_bbox, RCNN_loss_cls, RCNN_loss_bbox, rois_label
重点部分在于:
# feed image data to base model to obtain base feature map
# Bottom-up
c1 = self.RCNN_layer0(im_data)
c2 = self.RCNN_layer1(c1)
c3 = self.RCNN_layer2(c2)
c4 = self.RCNN_layer3(c3)
c5 = self.RCNN_layer4(c4)
# Top-down
p5 = self.RCNN_toplayer(c5)
p4 = self._upsample_add(p5, self.RCNN_latlayer1(c4))
p4 = self.RCNN_smooth1(p4)
p3 = self._upsample_add(p4, self.RCNN_latlayer2(c3))
p3 = self.RCNN_smooth2(p3)
p2 = self._upsample_add(p3, self.RCNN_latlayer3(c2))
p2 = self.RCNN_smooth3(p2)
p6 = self.maxpool2d(p5)
rpn_feature_maps = [p2, p3, p4, p5, p6]
mrcnn_feature_maps = [p2, p3, p4, p5]
特征融合的不同方式
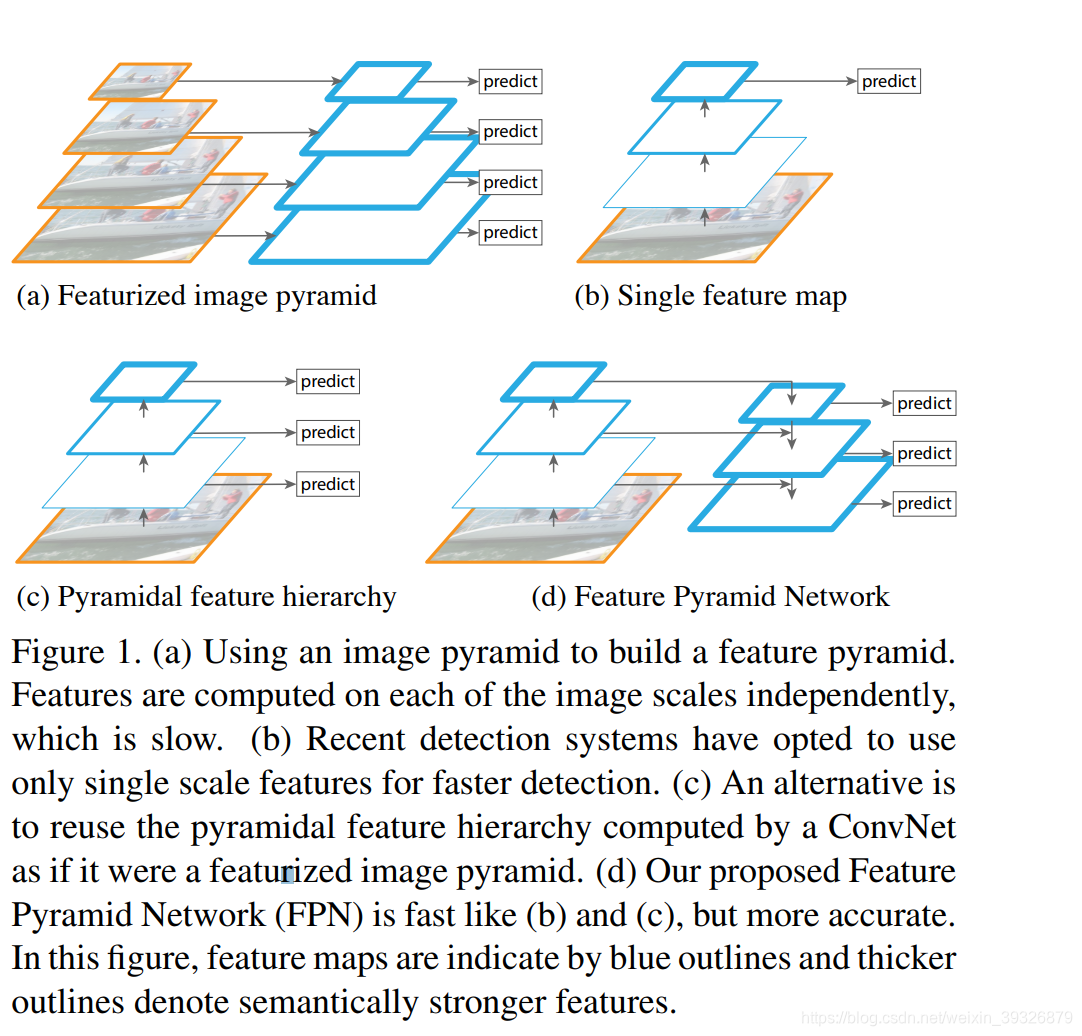
a.塑造图像金字塔,不大大小的图像放入网络进行预测,这样比较耗时;
b.大部分网络用这样单层的预测方式,这样比较快;
c.在不同的特征图上进行预测,SSD就是这样做的
d.FPN
具体的实验过程没有看了
总结
作者认为虽然深度学习已经有很不错的鲁棒性和抗形变,但是还是不如金字塔对于尺度变换的效果.

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









