







 本文介绍了如何使用DSSP在Python环境中计算蛋白质的二级结构,并提供了详细的操作步骤,包括通过anaconda安装DSSP。此外,还讲解了如何解析氨基酸层面的DSSP信息,并给出了计算α螺旋个数的方法。
本文介绍了如何使用DSSP在Python环境中计算蛋白质的二级结构,并提供了详细的操作步骤,包括通过anaconda安装DSSP。此外,还讲解了如何解析氨基酸层面的DSSP信息,并给出了计算α螺旋个数的方法。
安装DSSP使用anaconda:
sudo apt-get install dssp
解析氨基酸层面的dssp信息:
from Bio.PDB.PDBParser import PDBParser
# 引入pdb文件分析function
from Bio.PDB import DSSP
# 引入dssp(需要注意的是biopython包里不自带dssp,需另外下载)
p = PDBParser()
pdb_path='/2rh3.pdb'
structure = p.get_structure('structure_name',pdb_path)
# 解析需要的pdb文件
model = structure[0]
# 指定pdb文件中的model
dssp = DSSP(model,pdb_path)
print(dssp)
官网说明:https://osgeo.cn/biopython/Bio.PDB.DSSP.html
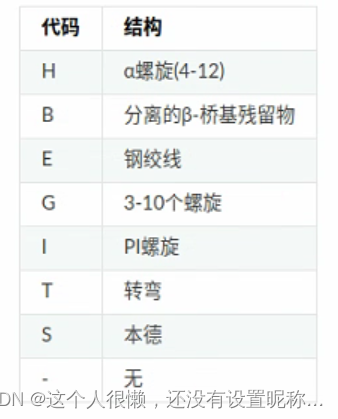
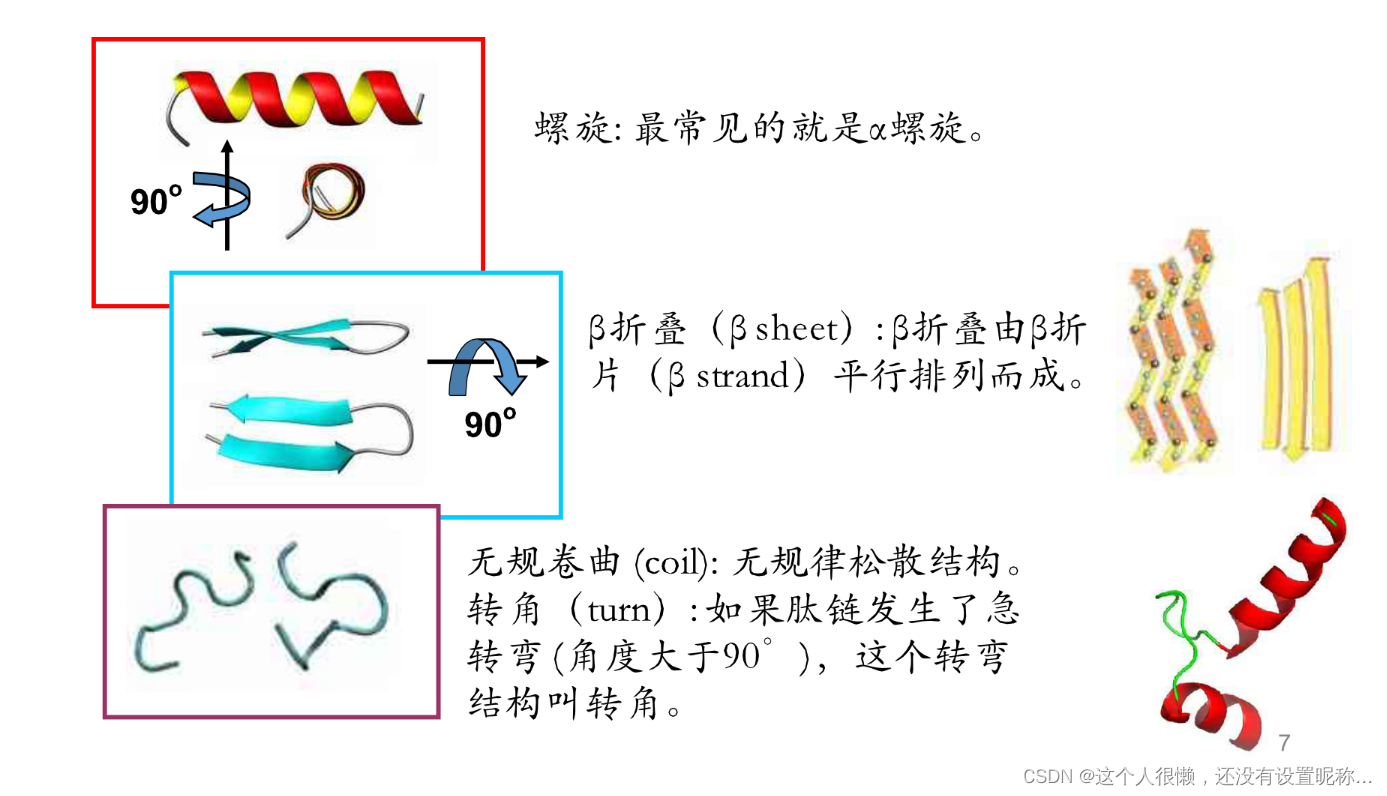
https://www.docin.com/p-1973044677.html(这是资料来源,写的很清楚,很不错了)
计算a-helix的个数:
from Bio.PDB.PDBParser import PDBParser
from Bio.PDB import DSSP
import os
import pandas as pd
df=pd.read_csv('log (7).csv',index_col=0)
file_list=list(df['sequence'])
file_list=[file_name+'_peptide.pdb' for file_name in file_list]
# file_list=os.listdir('peptide')
helix_num=2
helix_type='H'
rank_metrics1='SASA'
rank_metrics2='ratio_AKT'
top=10
col_num=0
for file_name in file_list:
file_path=os.path.join('peptide',file_name)
p = PDBParser()
structure = p.get_structure('structure_name',file_path)
model = structure[0]
dssp = DSSP(model,file_path)
property_list=dssp.property_list
flag=''
helix_num_temp=0
for h in property_list:
if h[0]==1:
flag=h[1]
continue
if h[1]!=flag and h[1]==helix_type:
helix_num_temp+=1
flag=h[1]
else:
flag=h[1]
if helix_num_temp==helix_num:
df_new = df[df['sequence'] == file_name[:-12]]
if col_num==0:
df_new.to_csv('helix.csv', mode='w', header=True)
else:
df_new.to_csv('helix.csv', mode='a', header=False)
col_num+=1
csv_file=pd.read_csv('helix.csv',index_col=0)
csv_file=csv_file.sort_values(by=rank_metrics1,ascending=False)[:top]
csv_file=csv_file.sort_values(by=rank_metrics2,ascending=False)
print(csv_file[['sequence',rank_metrics1,rank_metrics2]])
csv_file.to_csv('helix_top'+str(top)+'.csv')


















 1980
1980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











