






Emoji2Idiom:对多模态大型语言模型的神秘符号理解进行基准测试
hanscalZheng 大模型多模态论文解读 2025年02月07日 23:10 上海
文章提出了一种新任务——通过多模态大语言模型(MLLMs)将图像中的表情符号翻译为对应的文字(如成语、单词、或习语),以评估模型的视觉-语言理解能力。文章设计了一个高质量的基准数据集“Emoji2Idiom”,包括从网络和手动生成的数据集,用于支持这一任务。研究发现,现有的MLLMs在理解表情符号语义和推理文字含义方面存在显著不足。这项工作不仅提供了新的评测方法,还揭示了未来多模态模型需要改进的方向。
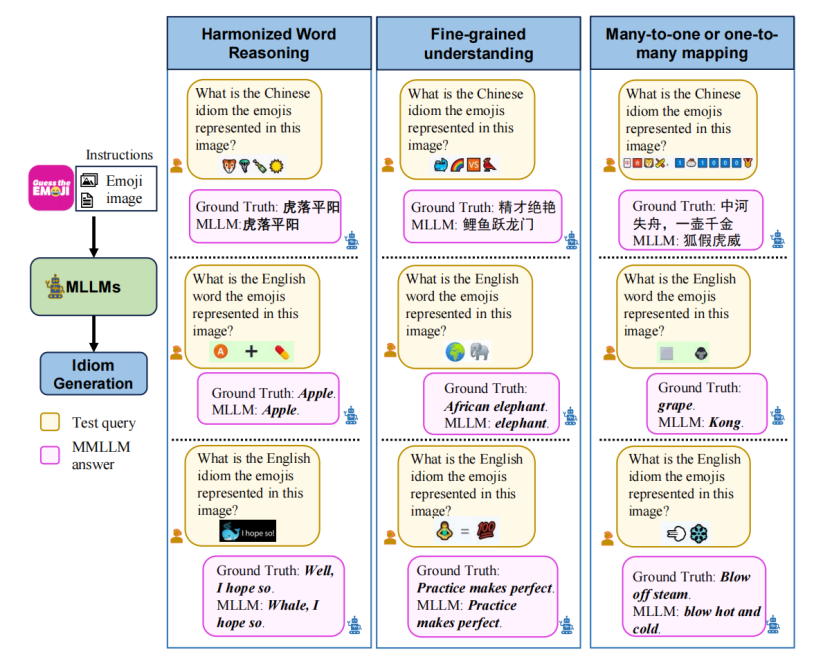
1 Emoji2Idiom书籍资料介绍
· 数据收集: 首先,从互联网和公开资源中获取与表情符号相关的原始数据,包括游戏截图、视频片段和网络数据库,同时通过文本生成相应的表情符号序列以扩充数据多样性。
· 自动数据清理: 利用算法进行初步数据过滤,删除重复、缺失或质量低下的样本,同时检测并剔除不符合伦理要求(如暴力、歧视性内容)的数据。
· 人工数据筛选: 由语言和图像专家进一步审核数据,确保表情符号与文本之间的语义关联清晰,并剔除语义模糊、不符合常规语言使用习惯或过于复杂的样本。
· 数据规范化: 对表情符号和文本配对进行标准化处理,避免过多重复映射,调整或替换频繁出现的谐音字符映射以提高数据多样性。
· 多语言覆盖: 设计任务包括表情符号到中文成语(四字成语与多字成语)、英文单词和英文习语的映射,涵盖不同语言和语义类型以增强数据的适用性。
· 挑战性设计: 引入多对一或一对多映射、谐音字符推理及表情符号的抽象语义理解等难点,提升任务复杂性,全面评估模型的视觉-语言推理能力。
· 伦理安全审查: 最终确保数据集中没有包含暴力、色情或歧视性内容,并涵盖多种文化和表达形式,以促进多样性和公平性。
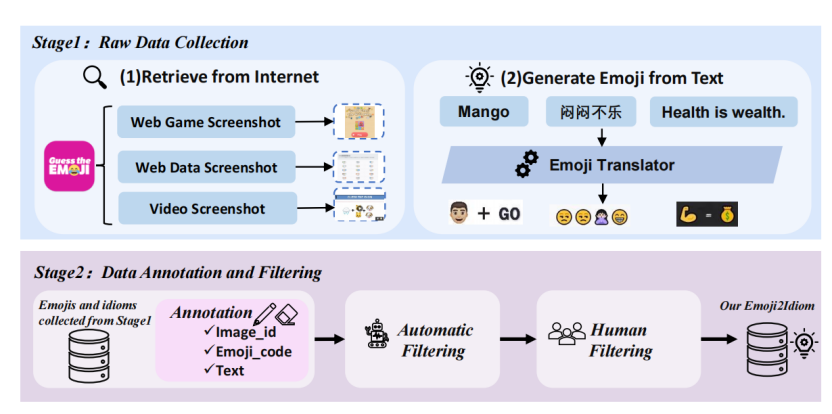
2 结语
文章提出了一个新的基准任务和数据集“Emoji2Idiom”,用于评估多模态智能体对图像中表情符号与语言关联的理解和推理能力。
论文题目: Emoji2Idiom: Benchmarking Cryptic Symbol Understanding of Multimodal Large Language Models
论文链接: https://openreview.net/forum?id=YxOG4FjZLd
PS: 欢迎大家扫码关注公众号^_^,我们一起在AI的世界中探索前行,期待共同进步!

















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









