






大家好,今天给大分享一个OrangePi AIpro(20T)采用昇腾作为主控芯片的开发板,开箱以及对应功能的详细实现。
第一:板子基本介绍
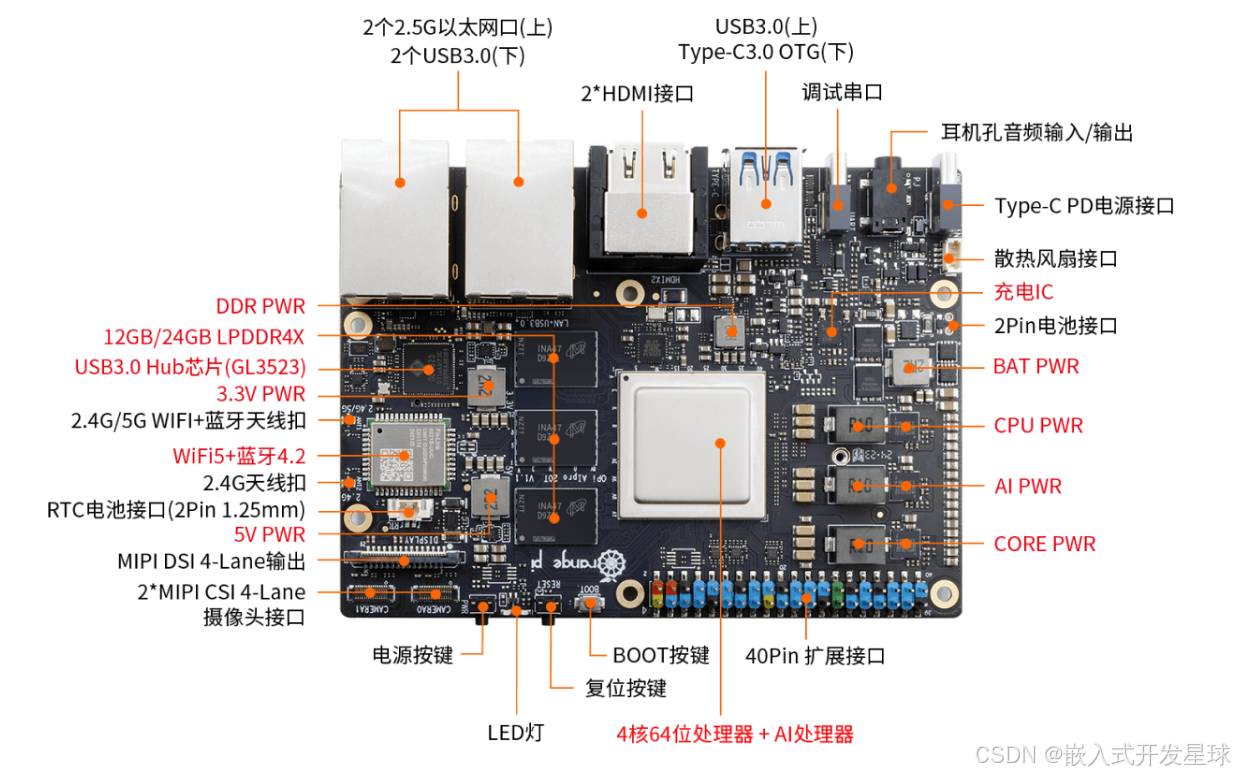
接通电源给对应的开发板上电,观察其中的现象,如下:
注意事项:开发板上有电源对应的Type-C接口,不要接错了。


1:控制启动设备3个拨码开关
开发板的linux系统下支持从TF卡、EMMC和SSD启动,具体从哪个设备启动是通过3个拨码开关进行选择的,启动之前要检查一下。 
从图上可以清晰的看出来对应系统的启动方式。
注意事项:切换拨码开关后必须重新拔插电源上电才能启动设备选择生效。通过开发板复位按键来复位系统是不会让拨码开关设置配置生效的。
2:开发利用调试串口的方法
开发板默认使用uart0做为调试串口。需要注意的是,uart0的tx和rx引脚同时接到了两个地方,所以有两种使用调试串口的方法:
第一种方法:
uart0 的 tx 和 rx 引脚接到了 40 pin 扩展接口中的 8 号和 10 号引脚,此种方式需要准备一个 3.3v 的 USB 转 TTL 模块和相应的杜邦线,然后才能正常使用开发板的调试串口功能。

第二种方法:
uart0 的 tx 和 rx 引脚还接到了开发板的 CH343P 芯片上,再通过 CH343P 芯片引出到 Type-C USB 接口上。此种方式只需要一根 Type-C USB 接口的数据线将开发板连接到电脑的 USB 接口就可以开始使用开发板的调试串口功能了,无需购买 USB 转 TTL 模块。这种方法是推荐的方法。

注意事项:上面的两种方式只能二选一,请不要同时使用。
第二:环境搭建与测试
1:Windows平台使用调试串口方法
1、直接安装对应的超级终端软件。
2、选择串口波特率为115200.

3、点击“OK”按钮后会进入下面的界面,此时启动开发板就能看到串口的输出信息了。
2:利用Windows PC将linux镜像烧写到TF卡的方法
1、要有一张大容量的TF卡,TF 卡的传输速度必须为 class10 级或 class10 级以上,建议使用闪迪等品牌的 TF 卡。
2、然后把 TF 卡插入读卡器,再把读卡器插入电脑。
3、下载想要烧录的 Linux 镜像压缩包。
4、下载用于烧录 Linux 镜像的软件——balenaEtcher,下载地址为:
https://www.balena.io/etcher/
5、进入 balenaEtcher 下载页面后,点击绿色的下载按钮会跳到软件下载的地方。
6、选择下载 Portable 版本的 balenaEtcher,Portable 版本无需安装,双击打

并进行双击打开。
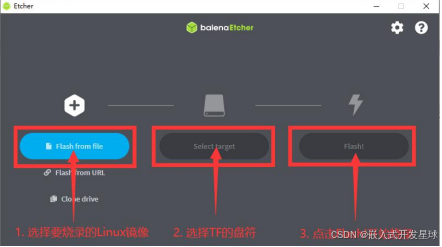
7、使用 balenaEtcher 烧录 Linux 镜像的具体步骤如下所示:
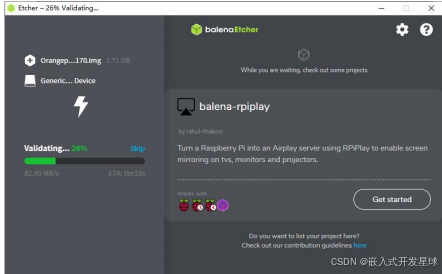
8、成功烧录完成后 balenaEtcher 的显示界面如下图所示,如果显示绿色的指示图
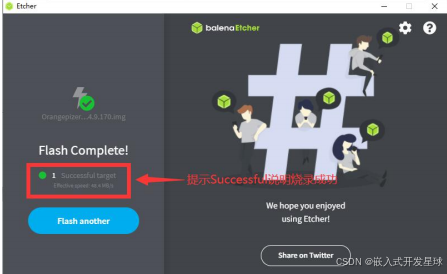
注意事项:启动系统前请确保拨码开发拨到了TF卡启动的位置了。拨码开关的使用请参考说明。
3:Ubuntu Xfce桌面系统使用
进入 Ubuntu 镜像的下载链接后可以看到下图所示的两个 ubuntu 镜像,他们的

Linux系统功能适配情况:
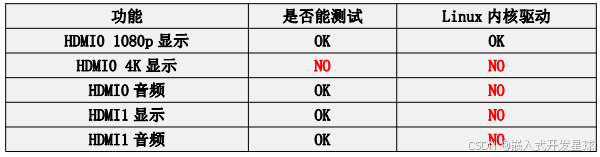
4:利用开发板无线连接
1、使用 nmcli dev wifi 命令扫描周围的 WIFI 热点。
命令:nmcli dev wifi
2、然后使用 nmcli 命令连接扫描到的 WIFI 热点,其中:
a. wifi_name 需要换成想连接的 WIFI 热点的名字。
b. wifi_passwd 需要换成想连接的 WIFI 热点的密码。
命令:sudo nmcli dev wifi connect wifi_name passwordwifi_passwd

开发板中使用的交叉编译工具链如下:

第三:香橙派开发板AI实现
1、人工智能目标检测
SSD(Single Shot MultiBox Detector)是一种流行且高效的单阶段目标检测算法,它在处理速度和检测精度之间取得了良好的平衡。与传统的两阶段方法(如 R-CNN 系列)不同,SSD 在单个网络前向传递中直接预测目标的边界框和类别,无需先生成候选区域。这种方法不仅加快了目标检测速度,而且简化了检测流程。
将SSD人工智能算法(算法代码详见sample文件夹),放入欧拉实验平台,点击运行。
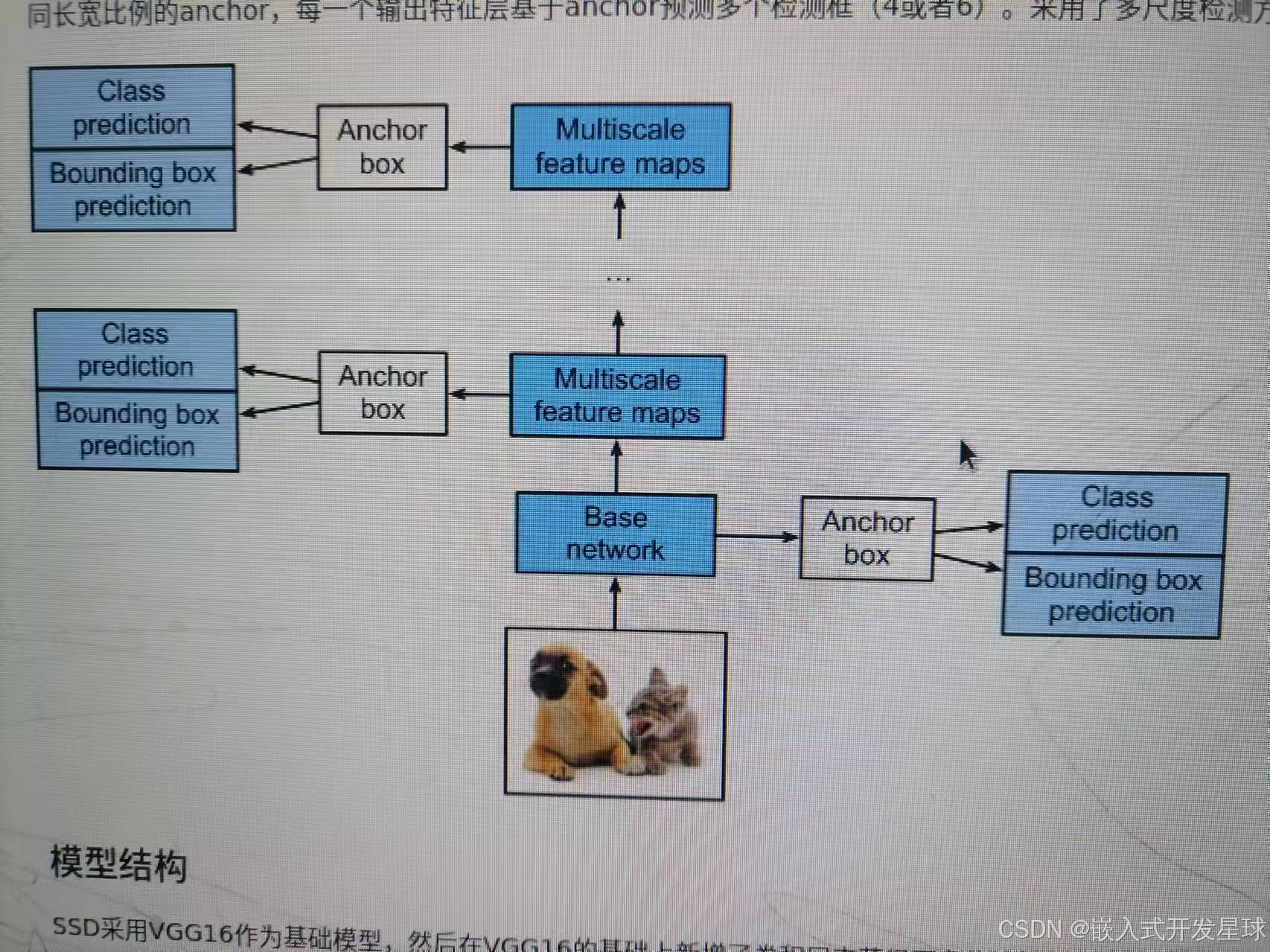

实现现象如下:

人工智能源码分析:
要使用这个文件进行模型评估,你需要使用与该文件兼容的框架和API。以下是一个使用 MindSpore 读取 .mindrecord 文件的基本示例:
-
安装 MindSpore: 确保你的环境中安装了 MindSpore。你可以访问 MindSpore 的官方网站获取安装指导。
-
读取文件: 使用 MindSpore 提供的 API 读取
.mindrecord文件,并将数据加载到模型中进行评估。
from mindspore import context
from mindspore.dataset import MindDataset
# 设置环境
context.set_context(mode=context.GRAPH_MODE, device_target="CPU")
# 创建数据集
dataset = MindDataset("path/to/ssd_eval.mindrecord0")
# 配置数据集,例如批处理大小等
dataset = dataset.batch(32)
# 使用数据集
for data in dataset.create_dict_iterator():
images = data["image"]
labels = data["label"]
# 这里可以加入模型评估的代码
分析数据
在使用这种文件时,你可能需要了解数据的具体结构,比如数据中包含的标签、图像尺寸等。你可以使用 MindSpore 的数据集查看工具来检查 .mindrecord 文件中的内容,以便更好地理解和使用数据。
2、人工智能实现文字识别
该人文字识别主要是将图像中的文字区域转化为字符信息,能够提取丰富的信息特征,采用ResNet算法模型,提取网络信息,其中包含转换后的om模型和测试图片,详细实现如下:
找到源码,存放在欧拉平台,双击点开。
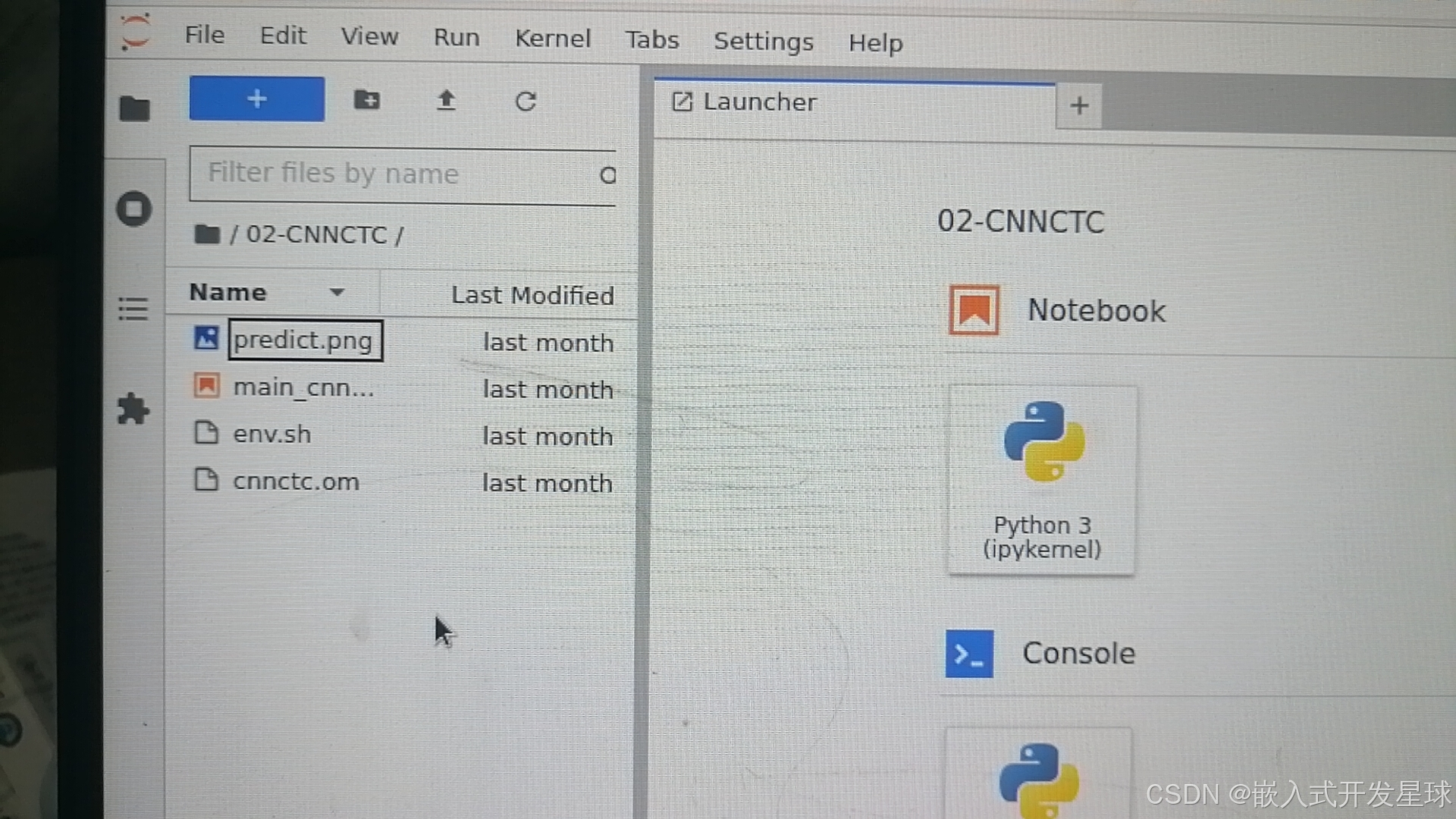
打开图片文字转化代码,利用CNN网络提取丰富的特征信息,进行识别。

提示编译成功的效果,注意观察启动的现象。

最终成功输出的结果如下:

文字识别现象解析:
要使用 ResNet 模型进行图片预测,你需要以下几步:
-
环境准备:确保 Python 环境中已安装必需的库,如
torch,torchvision。 -
模型加载:加载预训练的 ResNet 模型。
torchvision提供了多种 ResNet 模型,如 ResNet-18, ResNet-50 等。 -
图片处理:将图片调整为模型所需的输入大小,并进行必要的预处理,比如标准化。
-
预测:将处理过的图片输入模型,获取预测结果
基础案例实现:
import torch
from torchvision import models, transforms
from PIL import Image
# 加载预训练的 ResNet50 模型
model = models.resnet50(pretrained=True)
model.eval() # 设置为评估模式
# 图片预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 加载图片
img = Image.open("predict.png") # 确保这里的路径与你的图片路径相对应
img_t = transform(img)
batch_t = torch.unsqueeze(img_t, 0)
# 进行预测
with torch.no_grad():
output = model(batch_t)
_, predicted = torch.max(output, 1)
# 获取类别标签
classes = [...] # 这里需要一个类别列表,你可以从 ImageNet 的类别中获取
print("Predicted class:", classes[predicted.item()])
3、人工智能大模型实现
经过两个晚上思考,做什么样的人工智能呢?,最终还是到开源网站上找一找,果然很多,最终选择了一款,基于人工智能的大模型实现。

1、从开源网站上获取源码:
按照开源网站提供的网址进行操作。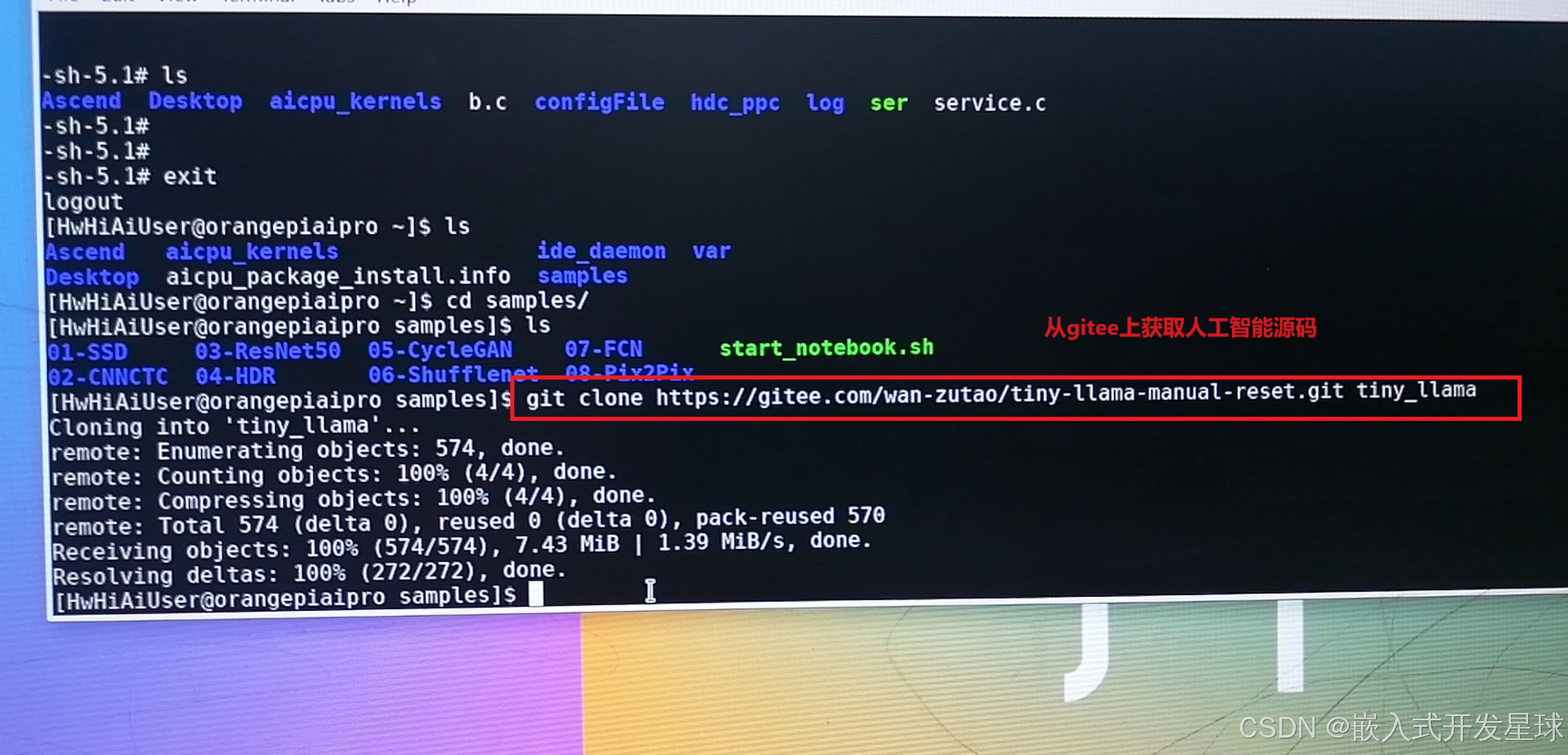
2、protoc的安装于使用
输入一下执行命令:
# 安装protoc==1.13.0, 找一空闲目录下载
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/wanzutao/tiny-llama/protobuf-all-3.13.0.tar.gz --no-check-certificate
tar -zxvf protobuf-all-3.13.0.tar.gz
cd protobuf-3.13.0
apt-get update
apt-get install autoconf automake libtool
./autogen.sh
./configure
make -j4
make install
sudo ldconfig
protoc --version # 查看版本号详细操作过程如下:


运行脚本文件现象分析:


使用make -j4进行编译,编译时间较长,需要耐性等待,最终编译生成的文件:

输入命令:sudo make install


3、算子编译部署
进行部署的时候,需要使用对应的安装命令
# 将./custom_op/matmul_integer_plugin.cc 拷贝到指定路径
cd tiny_llama
export ASCEND_PATH=/usr/local/Ascend/ascend-toolkit/latest
cp custom_op/matmul_integer_plugin.cc $ASCEND_PATH/tools/msopgen/template/custom_operator_sample/DSL/Onnx/framework/onnx_plugin/
cd $ASCEND_PATH/tools/msopgen/template/custom_operator_sample/DSL/Onnx 设置对应的环境变量命令:
export ASCEND_PATH=/usr/local/Ascend/ascend-toolkit/latest

进入对应的目标文件:
cd $ASCEND_PATH/tools/msopgen/template/custom_operator_sample/DSL/Onnx
修改对应的环境变量:
打开build.sh,找到下面四个环境变量
export ASCEND_TENSOR_COMPILER_INCLUDE=/usr/local/Ascend/ascend-toolkit/latest/include
export TOOLCHAIN_DIR=/usr
export AICPU_KERNEL_TARGET=cust_aicpu_kernels
export AICPU_SOC_VERSION=Ascend310B4
配置完成之后,保存并退出。
编译并运行对应的人工智能:
./build.sh
cd build_out/
./custom_opp_ubuntu_aarch64.run
# 生成文件到customize到默认目录 $ASCEND_PATH/opp/vendors/,删除冗余文件
cd $ASCEND_PATH/opp/vendors/customize
rm -rf op_impl/ op_proto/对应的现象如下:

继续编译运行:

安装依赖:
cd tiny_llama/inference
pip install -r requirements.txt -i https://mirrors.huaweicloud.com/repository/pypi/simple

3、推理运行
1、下载tokenizer文件
cd tokenizer
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/wanzutao/tiny-llama/tokenizer.zip
unzip tokenizer.zip 
2、获取onnx模型文件
cd ../model
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/wanzutao/tiny-llama/tiny-llama.onnx
3、atc模型转换
atc --framework=5 --model="./tiny-llama.onnx" --output="tiny-llama" --input_format=ND --input_shape="input_ids:1,1;attention_mask:1,1025;position_ids:1,1;past_key_values:22,2,1,4,1024,64" --soc_version=Ascend310B4 --precision_mode=must_keep_origin_dtype
4、最终人工智能项目实现
终于接近尾声了,现在可以操作大模型了。
找打接口里面的main.py观察现象。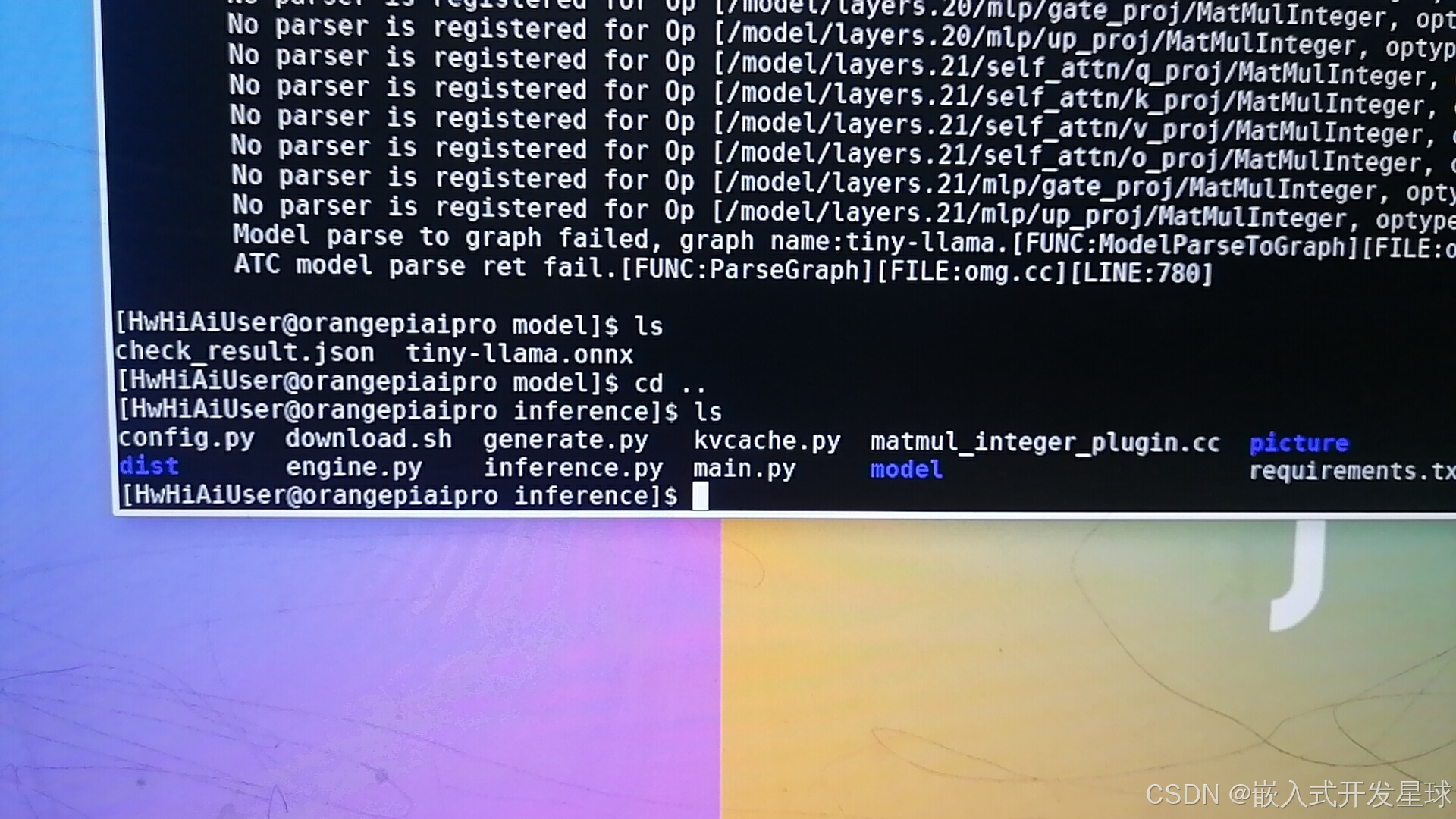
输入命令:python main.py,注意运行模型过程中会卡顿,多次启动即可。

现象分析:Tiny-Llama这个模型由于尺寸非常小,参数也只有1.1B。所以在我们部署Tiny-Llama这个大语言模型推理过程中,Ai Core的占用率只到70%左右,基本是一秒俩个词左右,速度上是肯定没问题的。
第四:性能分析
1、负载
能够使用20G左右的模型,进行编译,能够实时进行推理60FPS的视频,同时推理一张640*640的图像大约只要15-20ms,目前没有做量化设计,精度还是fioat16,做完In量化后,应该还可以进一步提升。
2、散热
Orange AlPro 在散热方面还是做的比较好的,配备了散热风扇,运行3个小时后,板子的温度还是处于一个较低的温度,个人觉得散热效果还是比较让人满意的。
3、噪音
这几天下来,只有在开机启动的时候大约有6~10s左右比较大的声音,但也在可接受范围内,平时运行各种AI模型都是静默的,几乎感受不到风扇的声音存在。
开发板Orange PiAPro 性能稳定,主打一个性价比!搭载的华为昇腾A!处理器,以 8TOPS 的INT8 算力和 4 TFLOPS FP16 的浮点运算能力,为复杂AI模型提供了强大的计算支撑。我在8G版本的 Orange PiAlPro上成功的运行了 MusicGen模型,其模型参数大小为 2.2G这对于 8G 版本的 Orange PiAIPro 来说,无疑是一个极大的挑战。板子在运行时内存使用超 90%,但是散热真的很好,风扇噪音较小,整块处理器的问题摸起来并不烫手,即使在满载的情况下运行半小时左右,处理器的温度略高于手指温度。
第五:产品评价
经过这两天操作香橙派开发板,感触颇深,硬件和系统的稳定性还是非常好的,基本上这块板子的所有外设和人工智能的实例都操作完了,还是非常容易上手的,开发文档比较齐全。
可以使用的操作系统也非常丰富,香橙派AiPro支持Ubuntu、openEuler等操作系统,这为用户提供了更多的选择空间,同时也方便了用户根据自己的需求进行开发和部署。
总体感受:香橙派开发板性能优越,易于上手,各种开发工具包齐全,非常适合新手,后期将继续分享优秀的人工智能项目,欢迎大家评论和相互交流学习。


















 2603
2603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











