







SubtypeDrug包是一个系统性的生物学工具,用于选择特定癌症亚型的药物,下面我们就看看怎么来实现吧!
简 介
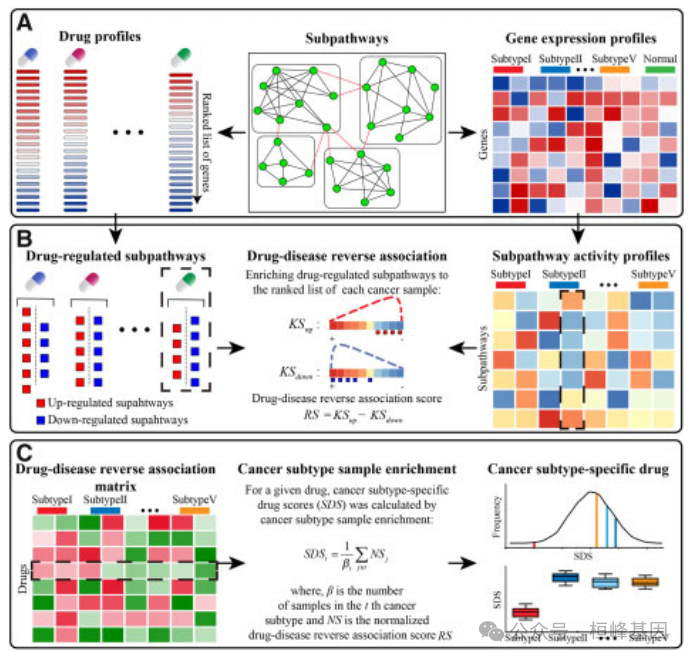
癌症可以根据其分子、组织学或临床特征分为不同的亚型。发现针对癌症亚型的药物是个体化医疗的关键一步。SubtypeDrug 是一个系统生物学基于R的软件包,可以根据癌症表达对亚型特异性药物进行优先排序来自许多亚型样本的数据。这提供了一种通过con考虑药物在亚通路水平调节的生物学功能来识别亚型特异性药物的新方法。操作模式包括提取 来自生物学途径的亚通路,鉴定由每种药物引起的失调亚通路,推断在样本特异性亚通路活性概况中,评估亚通路上的药物-疾病反向关联水平,通过亚型样本集富集分析鉴定癌症亚型特异性药物,并将结果可视化。它的功能使 SubtypeDrug 能够找到特定于亚型的药物,这将填补该领域的空白最近的工具只能识别针对特定癌症类型的药物。亚型药物可能有助于促进发展为癌症患者量身定制的治疗方案。
SubtypeDrug包是一个系统性的生物学工具,用于选择特定癌症亚型的药物。该工具的主要功能如下:
识别药物调控的亚通路。
推测特定患者的亚通路活性概况。
计算药物-疾病反向关联分数。
选择特定癌症亚型所对应的药物。
结果可视化。
软件包安装
chooseBioCmirror()
if(require(SubtypeDrug))
BiocManager::install("SubtypeDrug")
if(require(SubtypeDrugData))
devtools::install_github("hanjunwei-lab/SubtypeDrugData",force = TRUE)数据读取
这里药物相关的数据我们可以从 SubtypeDrugData 软件包里面下载,例子同样也来自这个数据包。
library(SubtypeDrug)
## Download SubtypeDrugData package from GitHub.
library(SubtypeDrugData)
## Get subpathway list data. If the gene expression profile contains gene
## Symbol.
data(SpwSymbolList)
## If the gene expression profile contains gene Entrezid.
data(SpwEntrezidList)
## Get drug subpathway association data.
data(DrugSpwData)实例操作
我们的方法不仅可以在具有多表型分类的数据集中识别癌症亚型特异性药物,还可以在具有癌症和正常样本的数据集中识别癌症相关药物。以模拟乳腺癌数据为例,乳腺癌相关及亚型特异性药物鉴定如下:
require(GSVA)
# > Loading required package: GSVA
require(parallel)
# > Loading required package: parallel Get simulated breast cancer gene
# expression profile data.
Geneexp <- get("Geneexp")
Geneexp[1:5, 1:5]
## TCGA-BH-A0BZ-11A TCGA-BH-A1FR-11B TCGA-A7-A0DB-11A TCGA-A7-A0CH-11A
## PMPCB 18.00481 18.07167 18.18495 18.16765
## WISP2 19.51181 18.44486 19.45742 19.00089
## IQCB1 17.23446 17.15936 16.67831 17.38432
## ARHGAP17 17.62721 17.21063 17.86861 17.45563
## BCL7C 17.01795 17.03588 17.40710 18.00261
## TCGA-E9-A1RD-11A
## PMPCB 18.20920
## WISP2 19.91755
## IQCB1 16.83018
## ARHGAP17 17.51310
## BCL7C 17.25346
## Obtain sample subtype data and calculate breast cancer subtype-specific
## drugs.
Subtype_labels <- system.file("extdata", "Subtype_labels.cls", package = "SubtypeDrug")# Identify breast subtype-specific drugs.
Subtype_drugs<-PrioSubtypeDrug(Geneexp,Subtype_labels,"Control",SpwSymbolList,
drug.spw.data=DrugSpwData,E_FDR=1,S_FDR=1)PrioSubtypeDrug()函数也只能在乳腺癌和正常两种类型的样本中识别乳腺癌相关药物。
## Results display.
Cancer_normal_labels <- system.file("extdata", "Cancer_normal_labels.cls", package = "SubtypeDrug")
Disease_drugs <- PrioSubtypeDrug(Geneexp, Cancer_normal_labels, "Control", SpwSymbolList,
drug.spw.data = DrugSpwData, E_FDR = 1, S_FDR = 1)PrioSubtypeDrug()函数也支持用户定义的数据。
## User-defined drug regulation data should resemble the structure below.
UserDS <- get("UserDS")
str(UserDS[1:5])
## List of 5
## $ 1,5-isoquinolinediol(1e-04M):List of 2
## ..$ Target_upregulation : chr [1:64] "00140_10" "00450_2" "00590_2" "00830_2" ...
## ..$ Target_downregulation: chr [1:76] "00030_2" "00071_1" "00100_2" "00100_5" ...
## $ 2-deoxy-D-glucose(0.01M) :List of 2
## ..$ Target_upregulation : chr [1:68] "00250_1" "01524_2" "03013_1" "03015_4" ...
## ..$ Target_downregulation: chr [1:43] "00051_1" "00100_6" "00230_1" "00240_8" ...
## $ NA : NULL
## $ NA : NULL
## $ NA : NULL
## Need to load gene set data consistent with drug regulation data.
UserGS <- get("UserGS")
str(UserGS[1:5])
## List of 5
## $ 00140_10: chr [1:49] "CYP11A1" "HSD3B1" "HSD3B2" "CYP17A1" ...
## $ 00250_1 : chr [1:17] "NIT2" "ASNS" "NAT8L" "IL4I1" ...
## $ 00030_2 : chr [1:28] "GPI" "DERA" "PRPS1L1" "PRPS1" ...
## $ 00071_1 : chr [1:17] "ACADSB" "ACADS" "EHHADH" "HADH" ...
## $ 00100_2 : chr [1:8] "EBP" "DHCR7" "SC5D" "DHCR24" ...
Drugs <- PrioSubtypeDrug(Geneexp, Subtype_labels, "Control", UserGS, spw.min.sz = 1,
drug.spw.data = UserDS, drug.spw.min.sz = 1, E_FDR = 1, S_FDR = 1)
## Estimating GSVA scores for 17 gene sets.
## Estimating ECDFs with Gaussian kernels
##
|
| | 0%
|
|==== | 6%
|
|======== | 12%
|
|============ | 18%
|
|================ | 24%
|
|===================== | 29%
|
|========================= | 35%
|
|============================= | 41%
|
|================================= | 47%
|
|===================================== | 53%
|
|========================================= | 59%
|
|============================================= | 65%
|
|================================================= | 71%
|
|====================================================== | 76%
|
|========================================================== | 82%
|
|============================================================== | 88%
|
|================================================================== | 94%
|
|======================================================================| 100%结果可视化
绘制癌症样本标准化药物-疾病反向关联评分的热图
require(pheatmap)
## Heat map of normalized disease-drug reverse association scores for all
## subtype-specific drugs.
plotDScoreHeatmap(data = Subtype_drugs, E_Pvalue.th = 0.05, E_FDR.th = 1, S_Pvalue.th = 0.05,
S_FDR.th = 1, show.colnames = FALSE)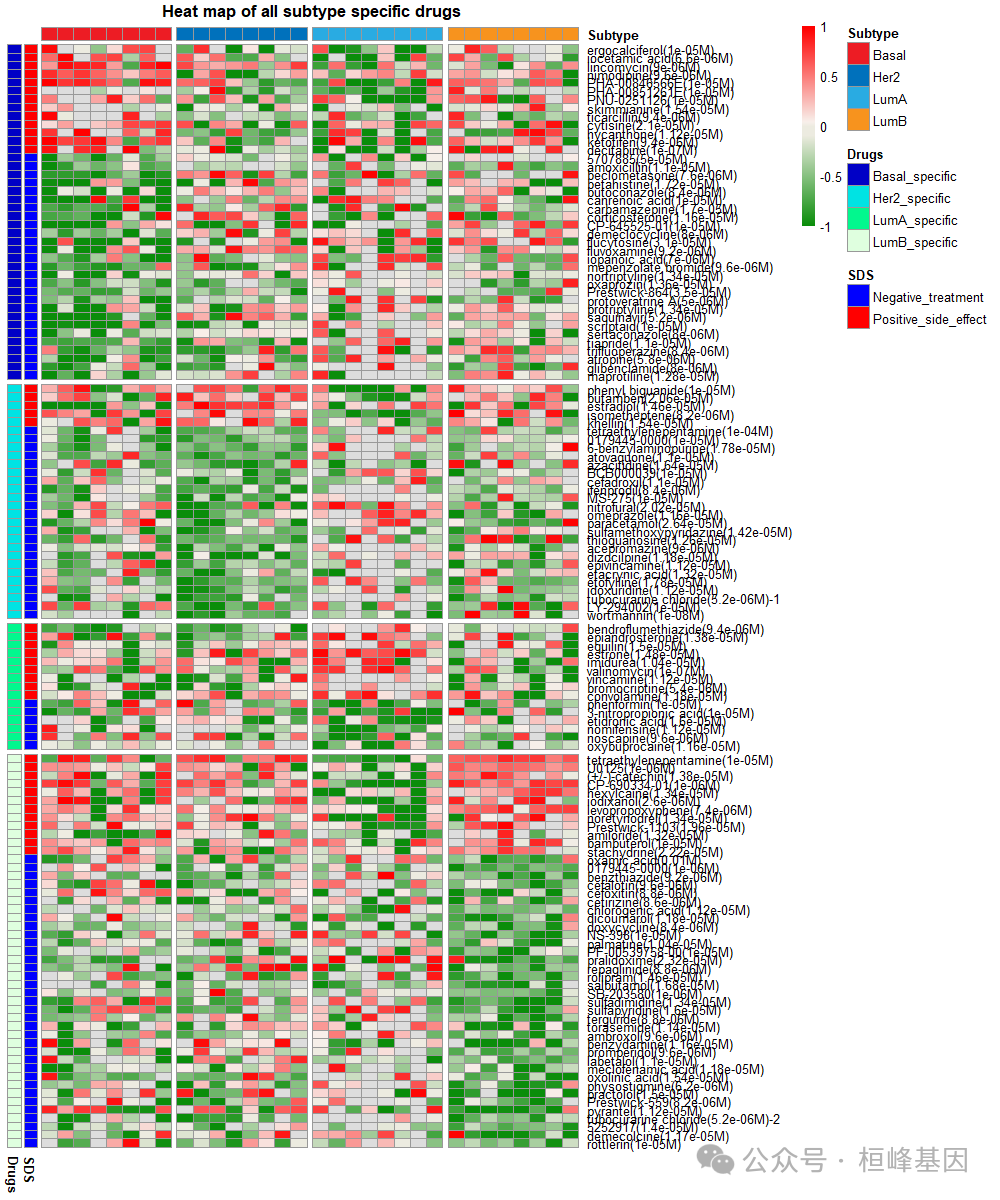
## Plot only Basal subtype-specific drugs.
plotDScoreHeatmap(Subtype_drugs, subtype.label = "Basal", SDS = "all", E_Pvalue.th = 0.05,
E_FDR.th = 1, S_Pvalue.th = 0.05, S_FDR.th = 1, show.colnames = FALSE)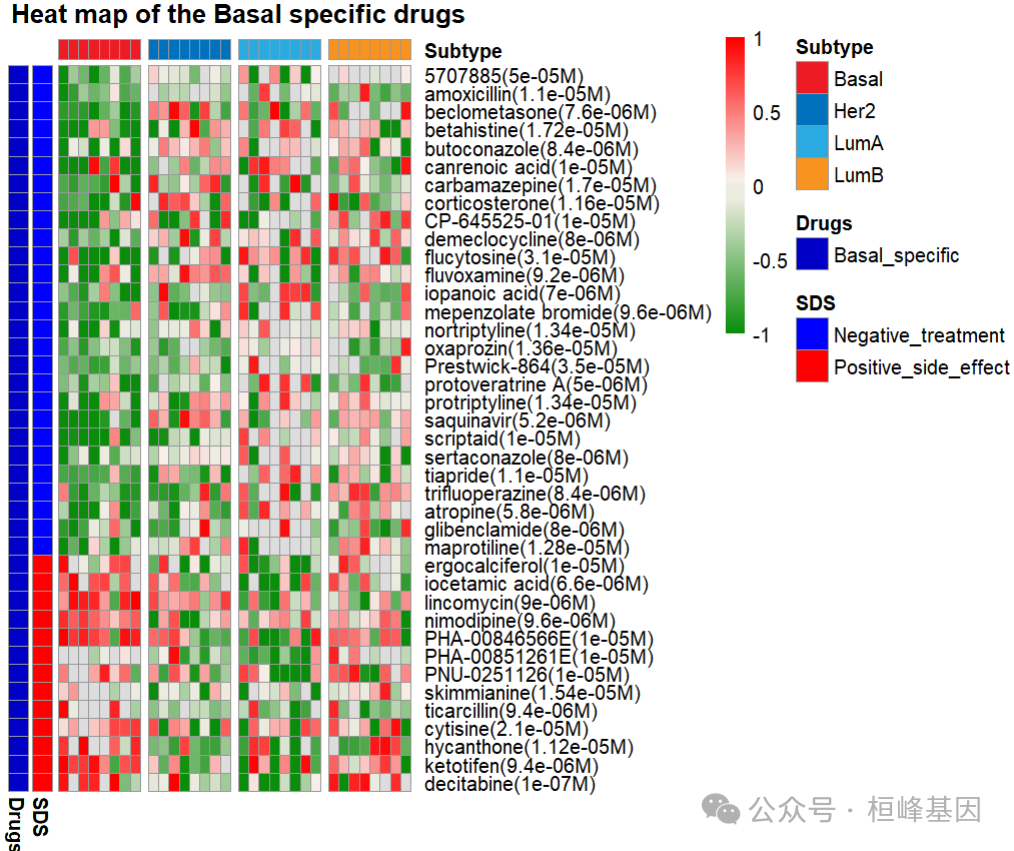
## Plot a heat map of the individualized activity aberrance scores of
## subpathway regulated by drug pirenperone(1.02e-05M). Basal-specific drugs
## pirenperone(1.02e-05M) regulated subpathways that show opposite activity
## from normal samples.
plotDSpwHeatmap(data = Subtype_drugs, drug.label = "pirenperone(1.02e-05M)", subtype.label = "Basal",
show.colnames = FALSE)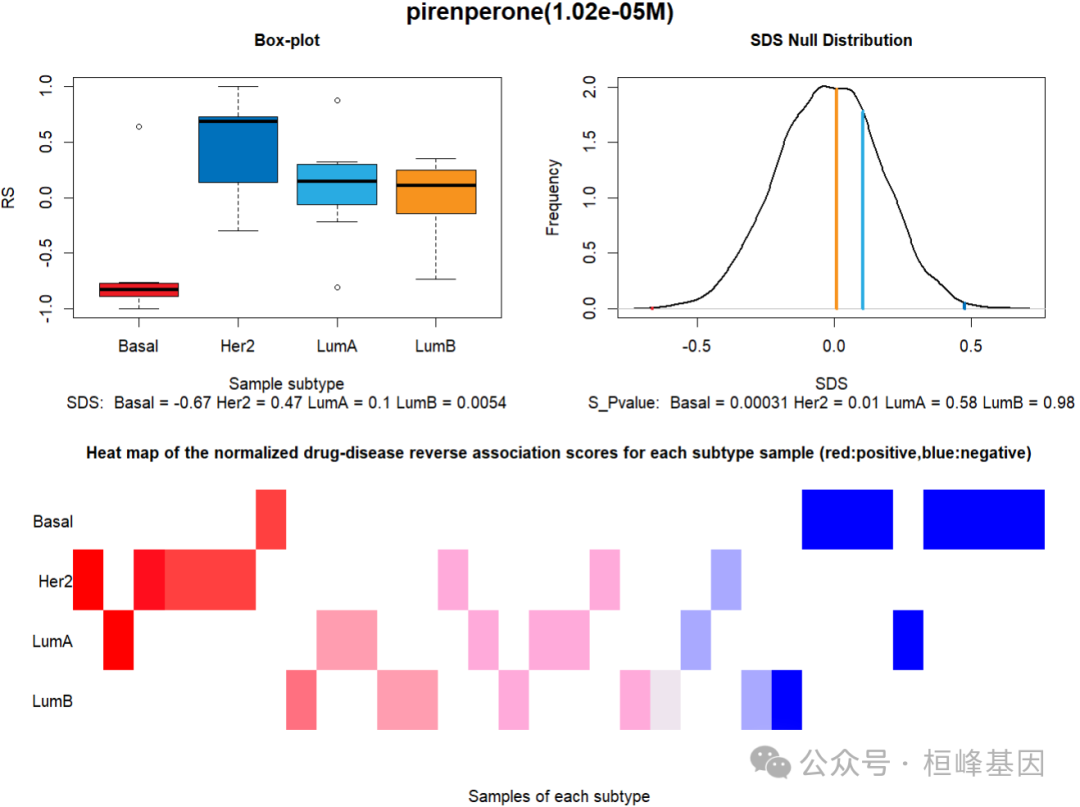
绘制药物的分布图
## Plot a global graph of the Basal-specific drug pirenperone(1.02e-05M).
plotGlobalGraph(data = Subtype_drugs, drug.label = "pirenperone(1.02e-05M)")绘制网络图
require(igraph)
# plot network graph of the subpathway 00020_4.
plotSpwNetGraph(spwid = "00020_4")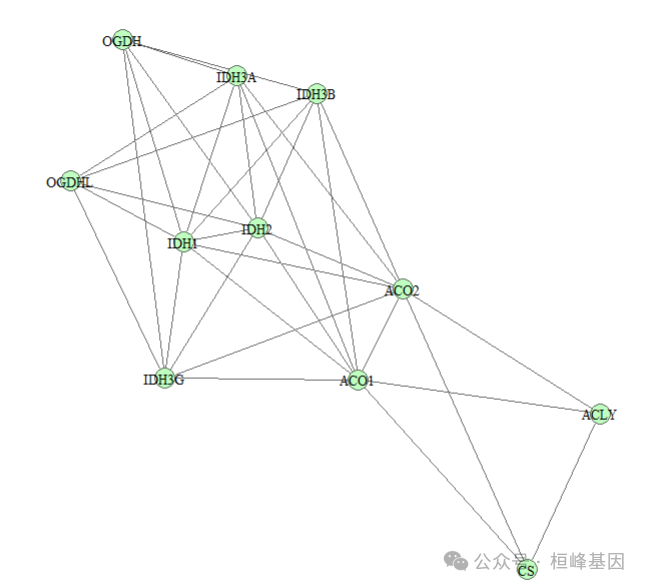
可视化药物的化学结构
require(ChemmineR)
require(rvest)
## Plot the chemical structure of drug pirenperone.
Chem_str <- getDrugStructure(drug.label = "pirenperone")
plot(Chem_str)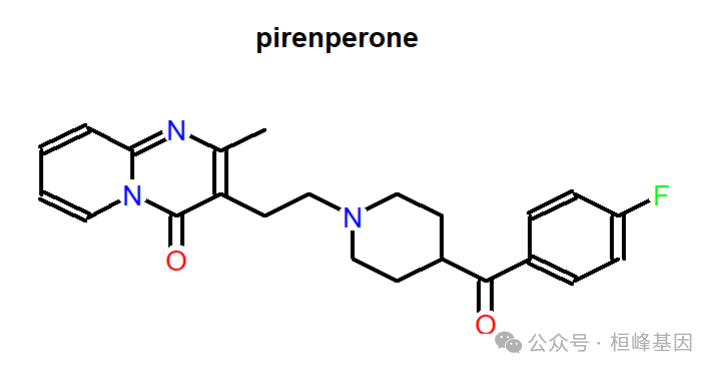
## $pirenperone
## An instance of "SDF"
##
## <<header>>
## Molecule_Name
## "4847"
## Source
## " -OEChem-01212420182D"
## Comment
## ""
## Counts_Line
## " 53 56 0 0 0 0 0 0 0999 V2000"
##
## <<atomblock>>
## C1 C2 C3 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 C15 C16
## F_1 14.1923 0.7327 0 0 0 0 0 0 0 0 0 0 0 0 0
## O_2 10.7282 -2.2673 0 0 0 0 0 0 0 0 0 0 0 0 0
## ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
## H_52 1.4643 0.3998 0 0 0 0 0 0 0 0 0 0 0 0 0
## H_53 1.4643 2.0656 0 0 0 0 0 0 0 0 0 0 0 0 0
##
## <<bondblock>>
## C1 C2 C3 C4 C5 C6 C7
## 1 1 26 1 0 0 0 0
## 2 2 13 2 0 0 0 0
## ... ... ... ... ... ... ... ...
## 55 28 52 1 0 0 0 0
## 56 29 53 1 0 0 0 0
##
## <<datablock>> (34 data items)
##
## "4847" "4847" "4847" "4847" "..."Reference
Han X, Kong Q, Liu C, Cheng L, Han J. SubtypeDrug: a software package for prioritization of candidate cancer subtype-specific drugs. Bioinformatics. 2021 Aug 25;37(16):2491-2493. doi: 10.1093/bioinformatics/btab011. PMID: 33459772.
号外号外,桓峰基因单细胞生信分析免费培训课程即将开始快来报名吧!
单细胞生信分析教程
桓峰基因公众号推出单细胞生信分析教程并配有视频在线教程,目前整理出来的相关教程目录如下:
SCS【4】单细胞转录组数据可视化分析 (Seurat 4.0)
SCS【6】单细胞转录组之细胞类型自动注释 (SingleR)
SCS【7】单细胞转录组之轨迹分析 (Monocle 3) 聚类、分类和计数细胞
SCS【8】单细胞转录组之筛选标记基因 (Monocle 3)
SCS【9】单细胞转录组之构建细胞轨迹 (Monocle 3)
SCS【10】单细胞转录组之差异表达分析 (Monocle 3)
SCS【11】单细胞ATAC-seq 可视化分析 (Cicero)
SCS【12】单细胞转录组之评估不同单细胞亚群的分化潜能 (Cytotrace)
SCS【13】单细胞转录组之识别细胞对“基因集”的响应 (AUCell)
SCS【15】细胞交互:受体-配体及其相互作用的细胞通讯数据库 (CellPhoneDB)
SCS【16】从肿瘤单细胞RNA-Seq数据中推断拷贝数变化 (inferCNV)
SCS【17】从单细胞转录组推断肿瘤的CNV和亚克隆 (copyKAT)
SCS【18】细胞交互:受体-配体及其相互作用的细胞通讯数据库 (iTALK)
SCS【21】单细胞空间转录组可视化 (Seurat V5)
SCS【22】单细胞转录组之 RNA 速度估计 (Velocyto.R)
SCS【24】单细胞数据量化代谢的计算方法 (scMetabolism)
SCS【25】单细胞细胞间通信第一部分细胞通讯可视化(CellChat)
SCS【26】单细胞细胞间通信第二部分通信网络的系统分析(CellChat)
SCS【28】单细胞转录组加权基因共表达网络分析(hdWGCNA)
SCS【29】单细胞基因富集分析 (singleseqgset)
SCS【30】单细胞空间转录组学数据库(STOmics DB)
SCS【31】减少障碍,加速单细胞研究数据库(Single Cell PORTAL)
SCS【32】基于scRNA-seq数据中推断单细胞的eQTLs (eQTLsingle)
SCS【33】单细胞转录之全自动超快速的细胞类型鉴定 (ScType)
SCS【34】单细胞/T细胞/抗体免疫库数据分析(immunarch)
SCS【35】单细胞转录组之去除双细胞 (DoubletFinder)
桓峰基因,铸造成功的您!
未来桓峰基因公众号将不间断的推出单细胞系列生信分析教程,
敬请期待!!
桓峰基因官网正式上线,请大家多多关注,还有很多不足之处,大家多多指正!http://www.kyohogene.com/
桓峰基因和投必得合作,文章润色优惠85折,需要文章润色的老师可以直接到网站输入领取桓峰基因专属优惠券码:KYOHOGENE,然后上传,付款时选择桓峰基因优惠券即可享受85折优惠哦!https://www.topeditsci.com/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









