







简 介
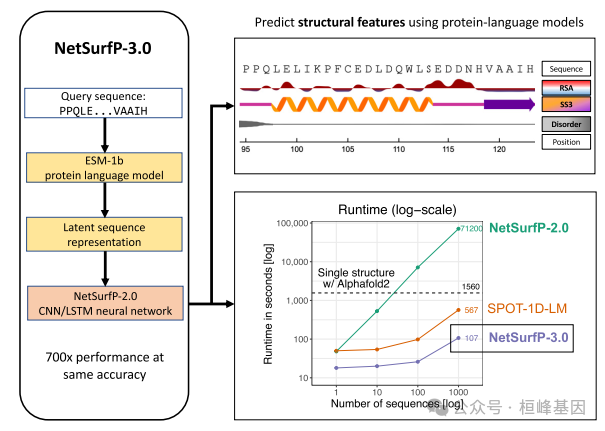
机器学习和自然语言处理的最新进展使我们能够深刻地提高准确预测蛋白质结构及其功能的能力。虽然这些改进对生物学和生物技术领域产生了重大影响,但这些方法在计算能力和运行时间方面有很高的要求,阻碍了它们对大型数据集的适用性。在这里,我们介绍NetSurfP-3.0,预测溶剂可及性的工具,二级结构,结构无序和主干二面角的氨基酸序列的每个残基。这次NetSurfP更新利用了预训练蛋白质语言模型的最新进展,在其前身的运行时间上大幅提高了两个数量级,同时显示出类似的预测性能。在几个独立的测试数据集上评估了NetSurfP-3.0的准确性,并发现始终如一地为其每个输出特征生成最先进的预测,运行时比执行相同任务的最常用的方法快600倍。该工具作为web服务器免费提供,具有用户友好的界面来导航结果,以及一个独立的可下载包。

NetSurfP3.0 在线分析工作流程:
文件准备
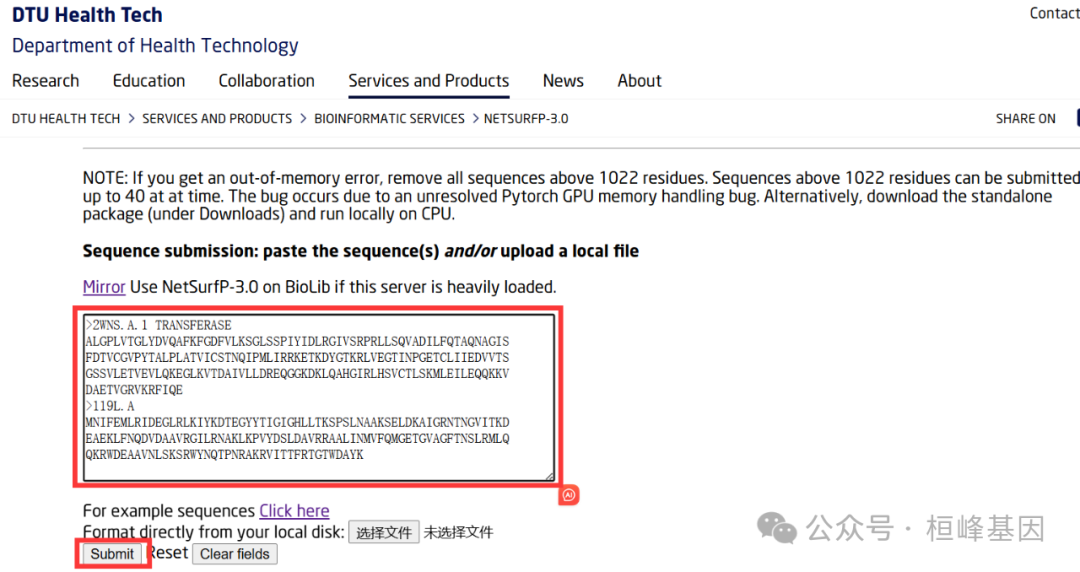
这个输入文件只有一个文件可以是蛋白序列文件,例如:
>2WNS.A.1 TRANSFERASE
ALGPLVTGLYDVQAFKFGDFVLKSGLSSPIYIDLRGIVSRPRLLSQVADILFQTAQNAGIS
FDTVCGVPYTALPLATVICSTNQIPMLIRRKETKDYGTKRLVEGTINPGETCLIIEDVVTS
GSSVLETVEVLQKEGLKVTDAIVLLDREQGGKDKLQAHGIRLHSVCTLSKMLEILEQQKKV
DAETVGRVKRFIQE
>119L.A
MNIFEMLRIDEGLRLKIYKDTEGYYTIGIGHLLTKSPSLNAAKSELDKAIGRNTNGVITKD
EAEKLFNQDVDAAVRGILRNAKLKPVYDSLDAVRRAALINMVFQMGETGVAGFTNSLRMLQ
QKRWDEAAVNLSKSRWYNQTPNRAKRVITTFRTGTWDAYK在线分析
在线网址NetSurfP3,或者NetSurfP3在线使用还是非常简单,序列少可以优先选择在线操作。
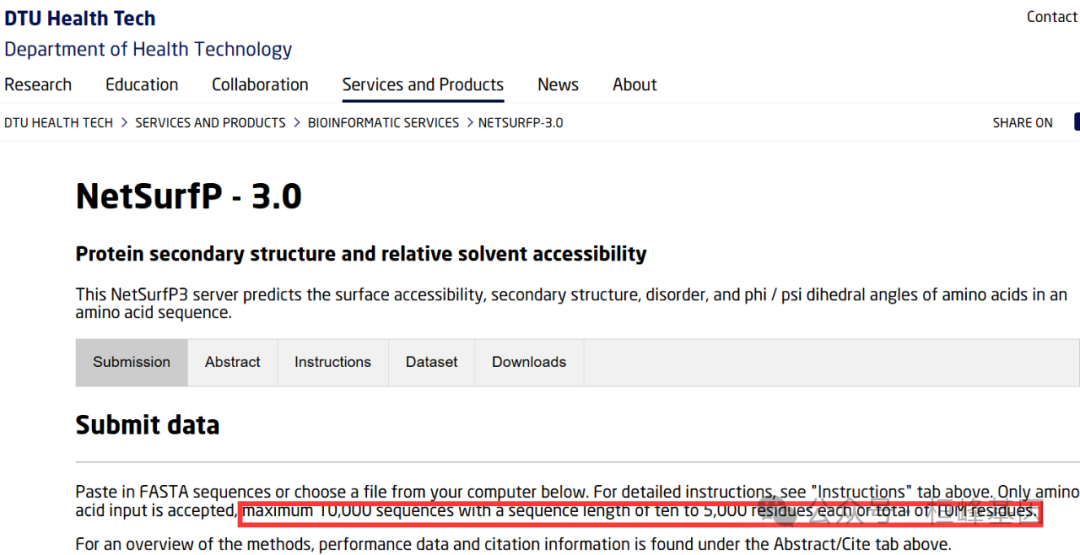
线上分析对数据量要求有一定局限性:
氨基酸序列最多10000个序列,每个序列长度为10到5000个残基,或者总共有10M个残基。如果出现内存不足错误,则删除所有超过1022个残基的序列。超过1022个残基的序列一次最多可提交40个。该错误是由于一个未解决的Pytorch GPU 内存处理错误引起的。或者下载独立包(在“下载”下)并在CPU上本地运行。
NetSurfP-3 测试结果:
运行完成之后会出现结果页面,右上角可以下载结果。

看一下CSV格式的结果:

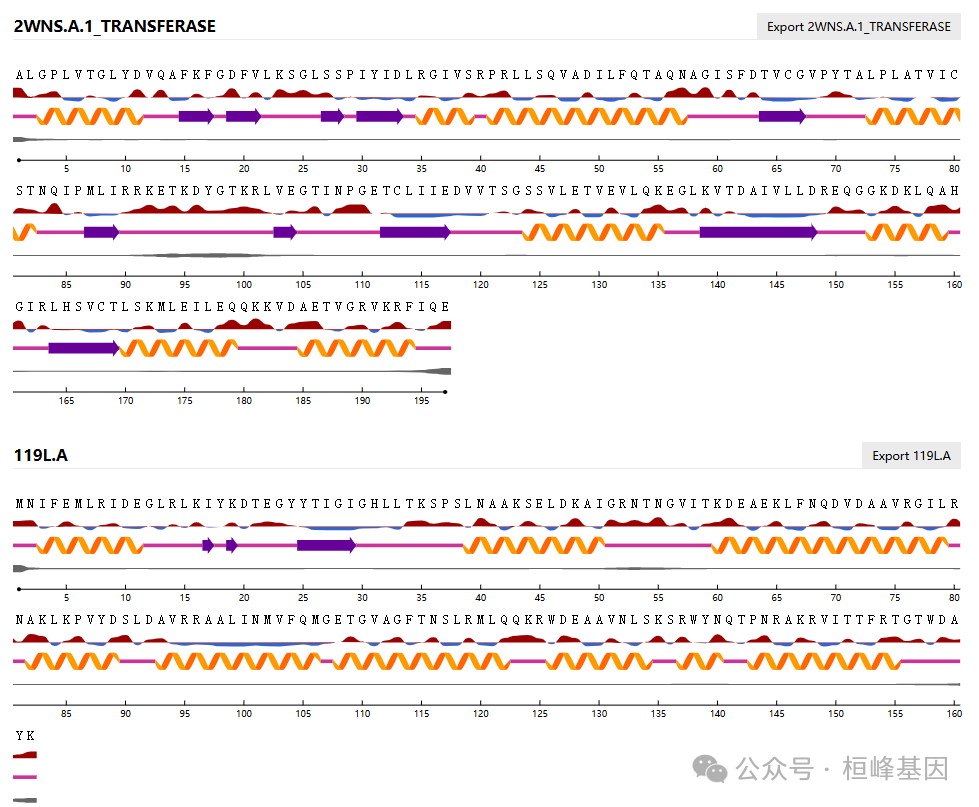
同时页面上也会出现每个基因蛋白质结构预测的结果:
本地分析
软件包安装
首先下载软件包,这个 NetSurfP3.0 软件包基于python3版本,下载的时候注意一下需要输入带有.edu类后缀的邮箱,否则也下载不了,安装操作都差不多哈。
pip3 install -U pybiolib
biolib run DTU/NetSurfP_3或者通过以下方法:
import biolib
nsp3 = biolib.load('DTU/nsp3')
nsp3_results = nsp3.cli(args='--input_data your_file.fasta')
nsp3_results.save_files("your_output_dir/")测试安装是否成功:
biolib run DTU/NetSurfP_3 -h
usage: main.py
[-h]
-i
I
-o
O
[-m M]
[-w W]
[-gpu GPU]
optional arguments:
-h, --help
show this
help
message and
exit
-i I
File input
path
-o O
File output
path
-m M
Model data
path
-w W
Worker id
-gpu GPU
Set to use
GPU实际操作
1. 参数说明
-i 输入蛋白序列文件;
-o 输出文件路径;
其他根据自己的运行环境设置。
2. 实际操作命令如下:
biolib run DTU/NetSurfP_3 -i test.fa结果解读
运行完成会发现生成 biolib_results/文件夹,里面涉及到所有的结果,每个序列都会生产一个文件夹,里面都有四个文件,如下:

然后根据每条序列的结果最后整理到results.netsurfp.txt里面。
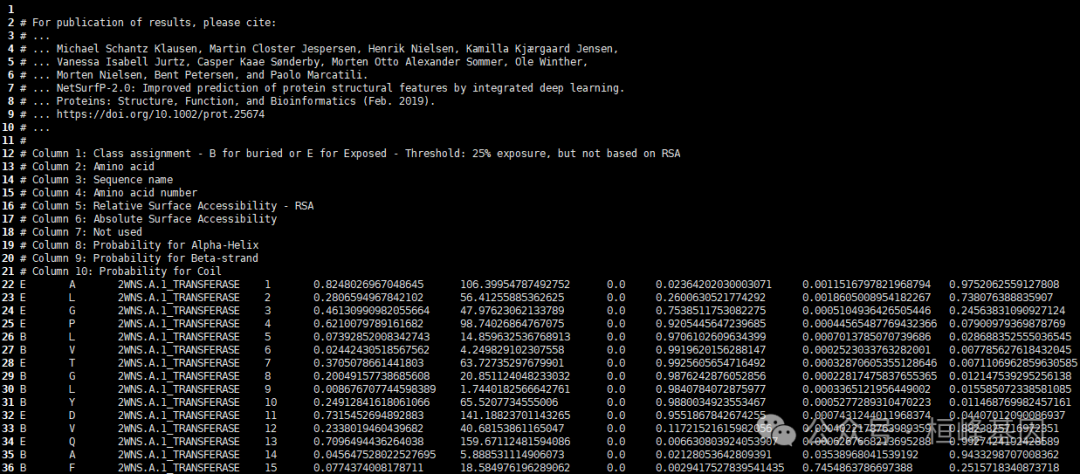
最主要的结果在biolib_results/results.netsurfp.txt 文件里面总结好了,每列的含有也显示在结果文件的title里面,这里不再赘述。
Reference
Magnus Haraldson Høie, et.al. NetSurfP-3.0: accurate and fast prediction of protein structural features by protein language models and deep learning, Nucleic Acids Research, Volume 50, Issue W1, 5 July 2022, Pages W510–W515, https://doi.org/10.1093/nar/gkac439
桓峰基因,铸造成功的您!
未来桓峰基因公众号将不间断的推出单细胞系列生信分析教程,
敬请期待!!
桓峰基因官网正式上线,请大家多多关注,还有很多不足之处,大家多多指正!http://www.kyohogene.com/
桓峰基因和投必得合作,文章润色优惠85折,需要文章润色的老师可以直接到网站输入领取桓峰基因专属优惠券码:KYOHOGENE,然后上传,付款时选择桓峰基因优惠券即可享受85折优惠哦!https://www.topeditsci.com/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









