







滑窗优化
在SLAM问题中,状态估计问题被建模为最大后验概率问题,在假设为高斯分布的情况下即为最小化损失函数的一个最小二乘问题,并通过泰勒展开转化为增量迭代求解问题:
x
^
=
arg
max
x
p
(
z
∣
x
)
=
arg
max
x
Π
p
(
z
i
j
∣
x
i
,
x
j
)
⇔
arg
min
x
1
2
Σ
∥
z
i
j
−
h
i
j
(
x
i
,
x
j
)
∥
Λ
i
j
2
⇒
δ
x
=
arg
min
δ
x
1
2
Σ
∥
z
i
j
−
h
i
j
(
x
i
^
(
k
)
,
x
j
^
(
k
)
)
−
J
i
j
(
k
)
δ
x
∥
Λ
i
j
2
\hat{x}=\mathop{\arg\max}_{x} \ p(z|x)=\mathop{\arg\max}_{x} \ \Pi{p(z_{ij}|x_i,x_j)} \\ \ \Leftrightarrow\mathop{\arg\min}_{x} \ \frac12 \Sigma\| z_{ij}-h_{ij}(x_i,x_j)\|_{\Lambda_{ij}}^2 \\ \Rightarrow \ \delta x=\mathop{\arg\min}_{\delta x} \frac12 \Sigma\|z_{ij}-h_{ij}(\hat{x_i}^{(k)},\hat{x_j}^{(k)})-J_{ij}^{(k)}\delta x\|_{\Lambda_{ij}}^2
x^=argmaxx p(z∣x)=argmaxx Πp(zij∣xi,xj) ⇔argminx 21Σ∥zij−hij(xi,xj)∥Λij2⇒ δx=argminδx21Σ∥zij−hij(xi^(k),xj^(k))−Jij(k)δx∥Λij2随着SLAM系统的运行,状态变量规模不断增大。使用滑窗优化是限制计算量的常用手段。
边缘化
对于滑窗外的状态,我们不去进行优化,但也不能直接丢掉,这样会破坏原有的约束关系,损失约束信息。采用边缘化的技巧,将约束信息转化为待优化变量的先验分布,实际上是一个从联合分布中获得变量子集概率分布的问题。
定义待边缘化变量
x
m
x_m
xm,和该变量有约束的待优化变量
x
b
x_b
xb,剩余待优化变量
x
r
x_r
xr,
x
m
x_m
xm和
x
b
x_b
xb间的约束为
z
m
z_{m}
zm,
x
b
x_b
xb间的约束为
z
b
z_{b}
zb,剩余约束为
z
r
z_{r}
zr,将优化问题拆解为两部分
x
^
=
arg
min
x
m
,
x
b
1
2
∑
(
i
,
j
)
∈
z
m
∥
z
i
j
−
h
i
j
(
x
i
,
x
j
)
∥
Λ
i
j
2
+
arg
min
x
b
,
x
r
1
2
∑
(
i
,
j
)
∈
z
b
,
z
r
∥
z
i
j
−
h
i
j
(
x
i
,
x
j
)
∥
Λ
i
j
2
\hat{x}=\mathop{\arg\min}_{x_m,x_b} \ \ \frac12 \sum_{(i,j)\in z_m} \| z_{ij}-h_{ij}(x_i,x_j)\|_{\Lambda_{ij}}^2 +\mathop{\arg\min}_{x_b,x_r} \ \ \frac12 \sum_{(i,j)\in z_b,z_r} \| z_{ij}-h_{ij}(x_i,x_j)\|_{\Lambda_{ij}}^2
x^=argminxm,xb 21(i,j)∈zm∑∥zij−hij(xi,xj)∥Λij2+argminxb,xr 21(i,j)∈zb,zr∑∥zij−hij(xi,xj)∥Λij2其中第一部分进行边缘化处理,将约束封装为
x
b
x_b
xb的先验
N
(
x
b
^
,
Λ
t
−
1
)
\mathcal{N}(\hat{x_b},\Lambda_t^{-1})
N(xb^,Λt−1),这样优化问题转为:
x
^
=
arg
min
x
1
2
∥
x
b
^
−
x
b
∥
Λ
t
2
+
1
2
∑
(
i
,
j
)
∈
z
b
,
z
r
∥
z
i
j
−
h
i
j
(
x
i
,
x
j
)
∥
Λ
i
j
2
\hat{x}=\mathop{\arg\min}_{x} \ \ \frac12 \| \hat{x_b}-x_b\|_{\Lambda_{t}}^2 + \frac12 \sum_{(i,j)\in z_b,z_r} \| z_{ij}-h_{ij}(x_i,x_j)\|_{\Lambda_{ij}}^2
x^=argminx 21∥xb^−xb∥Λt2+21(i,j)∈zb,zr∑∥zij−hij(xi,xj)∥Λij2边缘化采用的方式为舒尔补(schur complement)
证明
概率角度
状态变量满足高斯联合分布(区别于噪声的高斯分布,状态变量本身也是真值附近的高斯分布)
[
a
b
]
∼
N
(
μ
=
[
μ
a
μ
b
]
,
Σ
=
[
A
C
T
C
B
]
)
\left[ \begin{matrix} a\\ b \end{matrix} \right] \thicksim\mathcal{N}(\mu=\left[ \begin{matrix} \mu_a\\ \mu_b \end{matrix} \right] ,\Sigma=\left[ \begin{matrix} A &C^T\\ C& B \end{matrix} \right] )
[ab]∼N(μ=[μaμb],Σ=[ACCTB])
对a进行边缘化,将联合概率分布分解为条件概率和边缘概率,其中条件概率为:
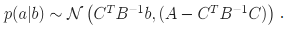
这样就去掉了a变量,得到了只含b变量的边际分布,其中a的信息固定,以概率为1的形式保留,不再影响b,对应b的信息矩阵进行了舒尔补(原本关于待边缘化变量条件独立的变量由于边缘化变量的固定而具有相关性,因子图两两之间建立约束,fill-in)。
使用不进行处理的变量表示待边缘化变量

通过使用不被边缘化的状态代替待边缘化状态,可以求解出最小值时使用了舒尔补形式。
FEJ(First Estimiated Jacobian)
执行边缘化过程中,我们需要不断迭代计算H矩阵和残差b,而迭代过程中,状态变量会被不断更新,计算边缘化相关的雅克比时需要注意固定线性化点。也就是计算雅克比时求导变量的值要固定,而不是用每次迭代更新以后的x去求雅克比,这就是FEJ(First Estimate Jacobians)。也被称为系统的一致性问题。
解释一:



以上证明了使用舒尔补进行边缘化可以得到无信息损失的近似优化函数,同时,在使用一开始泰勒展开的线性化点计算的雅克比时(边缘化时的使用的线性化点),此时
g
t
g_t
gt项为0,最大似然估计才等价于上述我们假定条件概率符合高斯分布构造的最小二乘问题。否则就会引入了人为的伪造信息,系统慢慢破坏。
解释二:系统能观性

使用两个线性化点不确定性的东西变得确定了,专业的术语叫不可观的状态变量变得可观了,说明我们人为的引入了错误的信息。
能观性是系统的本身属性,不受估计方式而改变。如VIO的不可观维度为4。采用不同的线性化点,导致能观性矩阵零空间维度发生改变,给系统引入了虚假的能观信息,使得原本系统不可观的部分可观。导致优化的系统与实际的系统不一致。
如何理解SLAM中的FEJ 知乎
解释三:
被边缘化的点固定:边缘化的操作,把旧信息以先验的形式保留了下来,被边缘化的状态固定并且不再更新。因此其线性化点也就固定了以此来保证一致性。
fill-in
要marg那些不被其他帧观测到的特征点
(待补)















 5370
5370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









