







bitnet.cpp的核心优势在于其能够在标准CPU上实现超高效的模型推理。根据初步测试结果,这一框架在不同类型的CPU上表现出显著的加速效果,为ARM和x86架构的处理器提供了高达6.17倍的速度提升,同时能耗减少幅度可达82.2%。在当前对环保与效率双重追求的科技背景下,这样的性能显得尤为重要。
在技术创新上,bitnet.cpp利用了1-bit大语言模型的高效计算能力,包含多项优化内核,专门针对CPU推理性能进行设计。其灵活性使得该框架不仅可以在个人电脑上运行,未来还将扩展到NPU、GPU以及移动设备。这种技术的发展为研究人员、小型开发者和普通消费者铺平了道路,让他们能够更便捷地接触和使用高级AI应用。
传统大语言模型通常需要庞大的 GPU 基础设施和大量电力,导致部署和维护成本高昂,而小型企业和个人用户因缺乏先进硬件而难以接触这些技术,而 bitnet.cpp 框架通过降低硬件要求,吸引更多用户以更低的成本使用 AI 技术。
bitnet.cpp 支持 1-bit LLMs 的高效计算,包含优化内核以最大化 CPU 推理性能,且当前支持 ARM 和 x86 CPU,未来计划扩展至 NPU、GPU 和移动设备。
根据初步测试结果,在 ARM CPU 上加速比为 1.37x 至 5.07x,x86 CPU 上为 2.37x 至 6.17x,能耗减少 55.4% 至 82.2%。
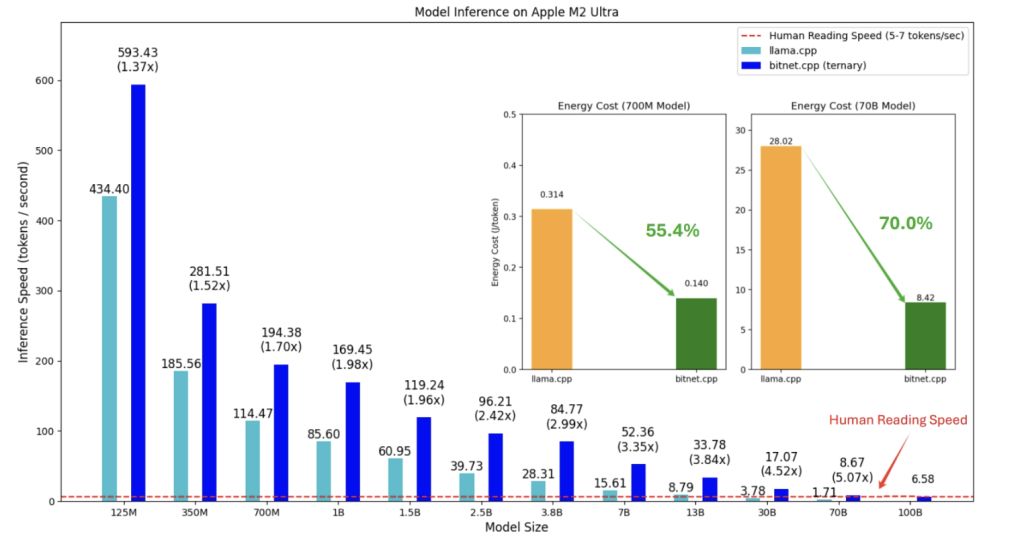
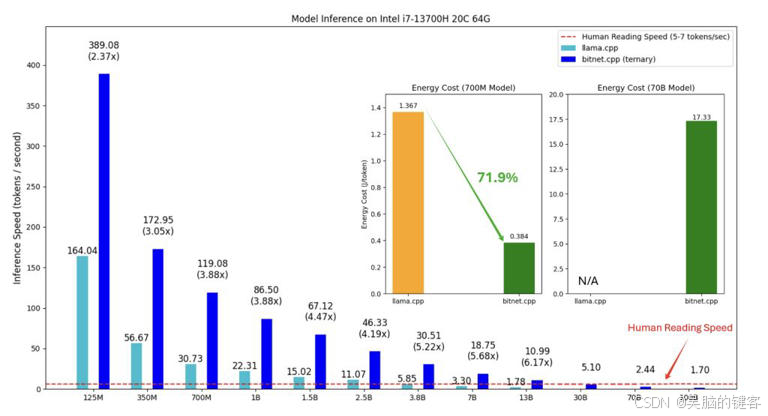
bitnet.cpp 的推出,可能重塑 LLMs 的计算范式,减少对硬件依赖,为本地 LLMs(LLLMs)铺平道路。
用户能够在本地运行模型,降低数据发送至外部服务器的需求,增强隐私保护。微软的“1-bit AI Infra”计划也在进一步推动这些模型的工业应用,bitnet.cpp 在这一进程中扮演着重要角色。
Github: https://github.com/microsoft/BitNet
教程
环境要求
要使用BitNet.cpp,需要配置以下环境:
- Python 3.9及以上版本
- CMake 3.22及以上版本
- Clang 18及以上版本
Windows用户还需安装Visual Studio 2022,并确保启用了C++开发相关组件。Debian/Ubuntu用户可通过自动化脚本安装LLVM工具链:
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
推荐使用Conda来管理虚拟环境,安装步骤如下:
-
克隆项目代码:
git clone --recursive https://github.com/microsoft/BitNet.git cd BitNet -
创建虚拟环境并安装依赖:
conda create -n bitnet-cpp python=3.9 conda activate bitnet-cpp pip install -r requirements.txt -
构建项目:
可以通过Hugging Face下载模型并将其转换为量化格式,或者手动下载模型后进行推理。python setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s
基本使用
BitNet.cpp提供了简单的命令行接口,便于用户进行推理。以下是一个运行推理的示例:
python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Where is Mary?" -n 6 -temp 0
在这个例子中,模型会根据给定的上下文生成6个token,输出答案为:“Mary is in the garden.”。
关键参数解释
-m:模型路径。-n:生成的token数量。-p:提示词,用于生成文本。-t:使用的线程数。-temp:控制生成文本的随机性,值越低,输出越确定。
性能基准测试
BitNet.cpp还提供了性能基准测试脚本,以评估模型在本地设备上的推理表现。例如:
python utils/e2e_benchmark.py -m /path/to/model -n 200 -p 256 -t 4
此命令会使用4个线程生成200个token,并对256个token的提示进行推理。用户还可以通过生成虚拟模型来进行自定义测试。
与现有框架的对比
BitNet.cpp与其他推理框架相比,最大的优势在于其高效的量化技术,能够在保持模型精度的前提下,极大提升推理速度并降低能耗。与常规16-bit或8-bit推理相比,1.58-bit模型的能效比明显更优,特别是在边缘设备或功耗敏感的环境中有着广阔的应用前景。
例如,与常见的LLM推理框架如Hugging Face Transformers或DeepSpeed相比,BitNet.cpp专注于低比特模型的推理,能够在仅使用CPU的情况下,达到其他框架需要GPU加速才能实现的性能。这使得BitNet.cpp非常适合在资源有限的设备上运行大规模模型。
感谢大家花时间阅读我的文章,你们的支持是我不断前进的动力。期望未来能为大家带来更多有价值的内容,请多多关注我的动态!


















 1181
1181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









