







阿里云通义千问开源了全新的视觉模型Qwen2.5-VL,并推出了3B、7B和72B三个尺寸版本。
其中,旗舰版Qwen2.5-VL-72B在13项权威评测中夺得视觉理解冠军,超越了GPT-4o与Claude3.5。阿里云官方介绍称,新的Qwen2.5-VL能够更准确地解析图像内容,并突破性地支持超过1小时的视频理解。该模型可以在视频中搜索具体事件,并对视频的不同时间段进行要点总结,从而快速、高效地帮助用户提取视频中的关键信息。
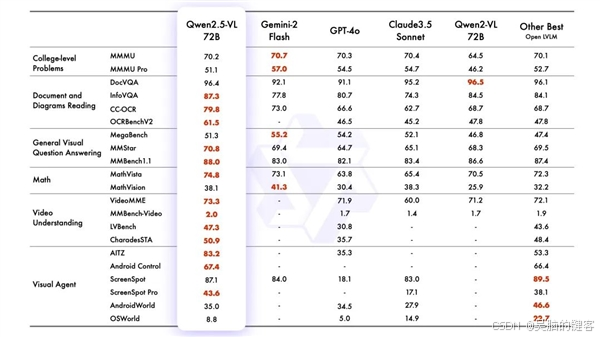
此外,Qwen2.5-VL无需微调即可变身为一个能操控手机和电脑的AI视觉智能体(Visual Agents),实现多步骤复杂操作,如给指定朋友发送祝福、电脑修图、手机订票等。Qwen2.5-VL不仅擅长识别常见物体,如花、鸟、鱼和昆虫,还能够分析图像中的文本、图表、图标、图形和布局。阿里云还提升了Qwen2.5-VL的OCR识别能力,增强了多场景、多语言和多方向的文本识别和文本定位能力。

同时,在信息抽取能力上进行了大幅度增强,以满足日益增长的资质审核、金融商务等数字化、智能化需求。
快速上手
安装依赖
pip install git+https://github.com/huggingface/transformers accelerate
pip install qwen-vl-utils[decord]==0.0.8
使用 🤗 Transformers 聊天
使用默认会爆24GB显存的,建议用Qwen官方FA2运行
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-7B-Instruct", torch_dtype="auto", device_map="auto"
#)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto",
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
# The default range for the number of visual tokens per image in the model is 4-16384.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
多图像推理
# Messages containing multiple images and a text query
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "Identify the similarities between these images."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
视频推理
# Messages containing a images list as a video and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": [
"file:///path/to/frame1.jpg",
"file:///path/to/frame2.jpg",
"file:///path/to/frame3.jpg",
"file:///path/to/frame4.jpg",
],
},
{"type": "text", "text": "Describe this video."},
],
}
]
# Messages containing a local video path and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "file:///path/to/video1.mp4",
"max_pixels": 360 * 420,
"fps": 1.0,
},
{"type": "text", "text": "Describe this video."},
],
}
]
# Messages containing a video url and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-VL/space_woaudio.mp4",
},
{"type": "text", "text": "Describe this video."},
],
}
]
#In Qwen 2.5 VL, frame rate information is also input into the model to align with absolute time.
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs, video_kwargs = process_vision_info(messages, return_video_kwargs=True)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
fps=fps,
padding=True,
return_tensors="pt",
**video_kwargs,
)
inputs = inputs.to("cuda")
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
视频 URL 的兼容性主要取决于第三方库的版本。 如果不想使用默认后端,可通过 FORCE_QWENVL_VIDEO_READER=torchvision 或 FORCE_QWENVL_VIDEO_READER=decord 更改后端。
批推理
# Sample messages for batch inference
messages1 = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "What are the common elements in these pictures?"},
],
}
]
messages2 = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who are you?"},
]
# Combine messages for batch processing
messages = [messages1, messages2]
# Preparation for batch inference
texts = [
processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True)
for msg in messages
]
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=texts,
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Batch Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_texts = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_texts)


















 2735
2735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









