








随着 Git 仓库的增长,新开发人员要克隆并开始工作就变得越来越难。Git 是一个分布式版本控制系统。这意味着你可以在自己的机器上工作,而不需要连接到控制你如何与版本库交互的中央服务器。只有在本地版本库中拥有所有可访问的数据时,这一点才能完全实现。
如果有更好的办法呢?你能在不下载整个 Git 历史中每个文件的每个版本的情况下开始在版本库中工作吗?Git 的部分克隆(partial clone)和浅克隆(shallow clone)功能可以帮到你,但它们也有各自的代价。每个选项都至少打破了 Git 正常分布式特性中的一个预期,而你可能并不愿意做出这样的取舍。
如果你正在处理的是一个超大规模的 monorepo,那么在这种规模下与 Git 交互时,这些权衡就更有可能是值得的,甚至是必要的!
快速摘要
有三种方法可以缩小 GitHub 托管仓库的克隆大小。
git clone --filter=blob:none <url>会创建一个无 blob 克隆。这些克隆会下载所有可访问的提交和树,同时按需获取 blob。这些克隆最适合开发人员和跨多个版本的构建环境。git clone --filter=tree:0 <url>会创建一个无树克隆。这些克隆会下载所有可访问的提交,同时按需获取树和 blob。这些克隆最适用于单次构建后版本库将被删除,但仍需要访问提交历史的构建环境。git clone --depth=1 <url>会创建一个浅克隆。这些克隆会截断提交历史,以减小克隆大小。这会产生一些意想不到的行为问题,限制了 Git 命令的执行。这些克隆也会给以后的获取带来不必要的压力,因此强烈不建议开发人员使用。在某些编译环境中,一次编译后仓库就会被删除,这时克隆就能派上用场了。
完整克隆
在讨论不同克隆类型时,我们将使用通用的 Git 对象表示法:
- 方框是 blob。它们代表文件内容。
- 三角形是树。代表目录。
- 圆圈代表提交。这些是时间快照。
我们用箭头来表示对象之间的关系。基本上,如果一个 OID B 出现在一个提交或树 A 中,那么对象 A 就有一个箭头指向对象 B。如果我们可以沿着一系列箭头从一个对象 A 到达另一个对象 C,那么我们就说 C 是可以从 A 到达的。沿着这些箭头行走的过程有时被称为 “行走物体”。
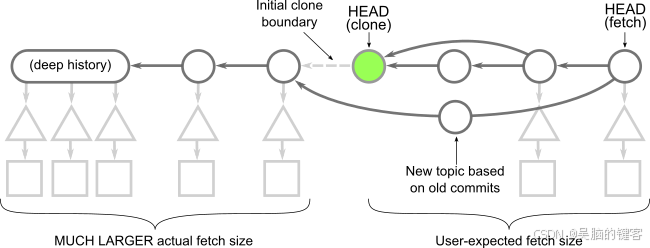
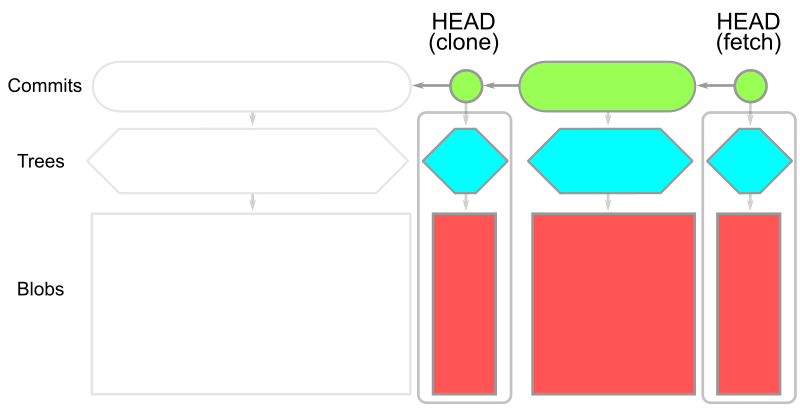
现在我们可以描述一下 git clone 命令下载的数据!客户端向服务器请求最新提交,然后服务器提供这些对象和其他所有可访问的对象。这包括整个提交历史中的每一棵树和每一个 blob!
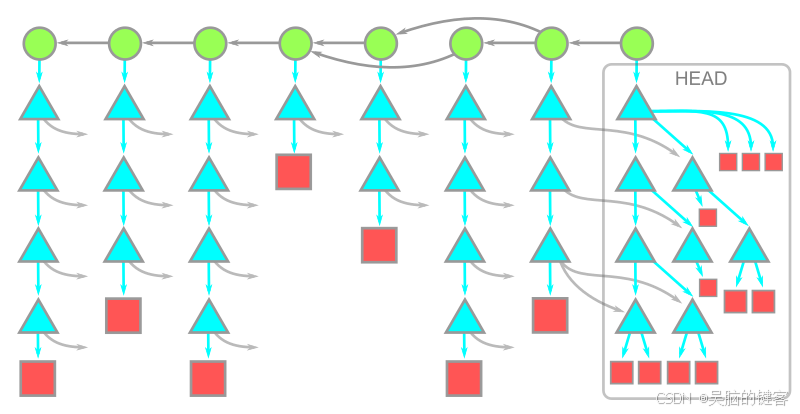
在此图中,时间从左到右移动。因此,提交与其父提交之间的箭头从右向左。每个提交都有一棵根树。位于 HEAD 提交处的根树在下方完全展开,而其余的树则有箭头指向这些对象。
此图故意简单化,但如果你的版本库非常大,历史中就会有很多提交、树和 Blob。历史数据很可能占了数据的大部分。您真的需要所有这些数据吗?
如今,许多开发人员在工作时总是可以使用网络连接,因此在必要时向服务器索取更多数据可能是一种可以接受的权衡。
这就是部分克隆带来的关键设计变化。
部分克隆
在 git clone 命令中指定 --filter 选项,就能启用 Git 的部分克隆功能。git rev-list 文档中有完整的过滤选项列表,你可以使用 git rev-list --filter= --all 查看仓库中哪些对象符合过滤条件。有几种可用的过滤器,但服务器可以选择拒绝你的过滤器,并恢复为完全克隆。
在 github.com 和 GitHub Enterprise Server 2.22+ 上,有两个选项可供选择:
- Blobless clones:
git clone --filter=blob:none <url> - Treeless clones:
git clone --filter=tree:0 <url>
Blobless clones
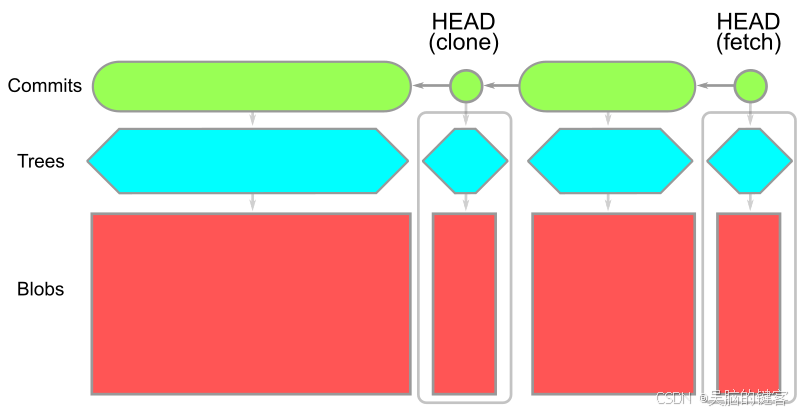
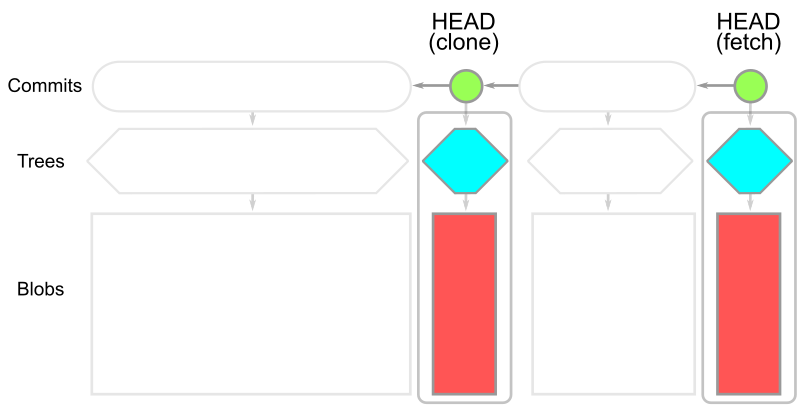
使用 --filter=blob:none 选项时,初始 git clone 会下载所有可到达的提交和树,只在进行 git checkout 时下载提交的 Blob。这包括 git clone 操作中的第一次签出。生成的对象模型如图所示
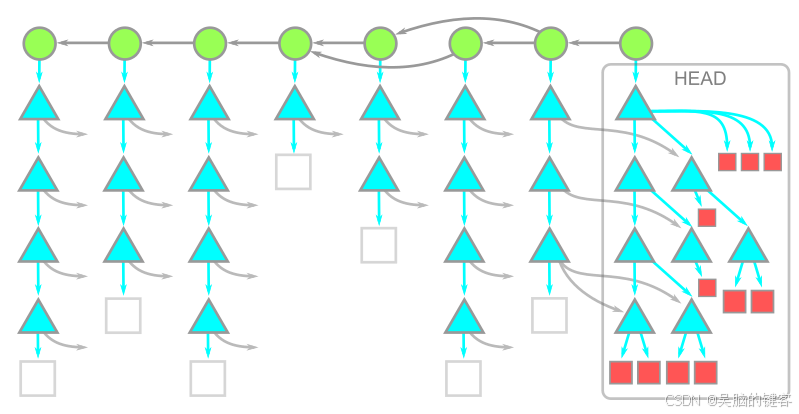
需要注意的是,我们在 HEAD 有每个 blob 的副本,但历史中的 blob 并不存在。如果您的版本库历史上有很多大的 blob,那么这个选项可以大大缩短您的 git clone 时间。提交和树数据仍然存在,因此任何后续的 git checkout 只需下载丢失的 blo即可。Git 客户端知道如何批量处理这些请求,只要求服务器下载缺失的 blobs。
此外,在无 blob 克隆中运行 git fetch 时,服务器只会发送新提交和树。只有在 git checkout 后才会下载新的 blob。需要注意的是,git pull 运行 git fetch 之后再运行 git merge,所以它会在 git merge 命令中下载必要的 blobs。
使用无 blob 克隆时,只要需要文件内容,就会触发 blob 下载,但如果只需要文件的 OID,则不需要下载。这意味着 git log 可以检测到哪些提交更改了指定路径,而无需下载额外的数据。
这意味着无 blob 克隆可以执行 git merge-base、git log 或甚至 git log -- <path> 等命令,其性能与完整克隆相同。
命令,如 git diff 或 git blame <path>;需要路径内容来计算差异,因此首次运行时会触发 blob 下载。不过,好消息是,在此之后,您的版本库中就会有这些 blob,无需再下载第二次。大多数开发人员只需要在少量文件上运行 git blame,因此 git blame 命令速度稍慢的折衷结果是值得的,因为克隆和获取时间更快了。
无 Blob 克隆是使用最广泛的部分克隆选项。我自己已经使用了几个月,没有任何问题。
无树克隆
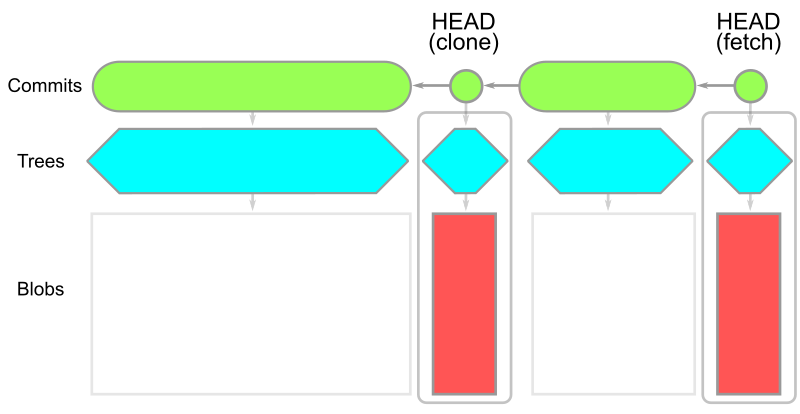
在某些版本库中,树数据可能是历史的重要组成部分。使用 --filter=tree:0 时,无树克隆会下载所有可到达的提交,然后按需下载树和 blobs。由此产生的对象模型如图所示:
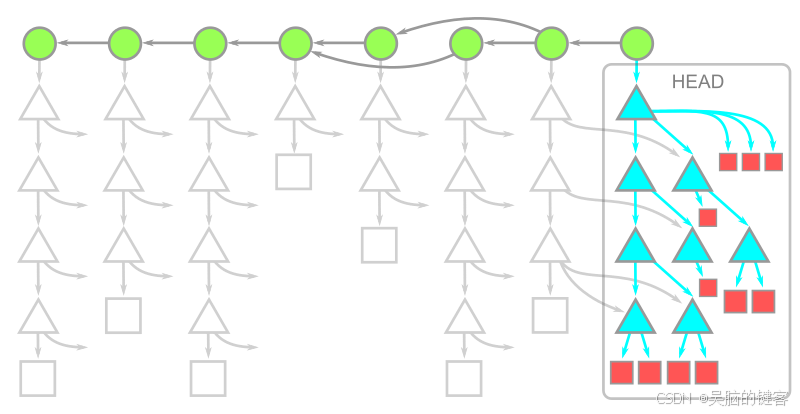
请注意,我们拥有 HEAD 的所有数据,除此之外只有提交数据。这意味着,无树克隆的初始克隆速度要比无块克隆或全克隆快得多。此外,我们还可以运行 git fetch 只下载最新的提交。不过,在无树克隆中工作比较困难,因为在需要时下载一个缺失的树会比较昂贵。
例如,git checkout 命令会修改 HEAD 提交,通常是修改到没有根树的提交。然后,Git 客户端会通过 OID 请求服务器提供根树,并请求提供该根树的所有可达树。目前,这个请求并不会告诉服务器客户端已经有了一些根树,所以服务器可能会发送很多客户端本地已经有的树。下载完树后,客户端可以检测出缺少哪些 blobs,并批量请求这些 blobs。
在无树克隆中工作不会触发过多的额外数据请求,但它比无树克隆的限制要多得多。
例如,git merge-base 或 git log(无额外选项)等历史操作只使用提交数据。这些操作不会触发额外的下载。
然而,如果你运行一个文件历史请求,比如 git log -- <path>,那么无树克隆就会开始下载历史中几乎所有提交的根树!
我们强烈建议开发人员在日常工作中不要使用无树克隆。无树克隆实际上只适用于自动构建,当你想快速克隆、编译一个项目,然后扔掉版本库的时候。在使用公共运行程序的 GitHub Actions 等环境中,你需要尽量减少克隆时间,以便把机器时间用于实际构建软件!无树克隆可能是这些环境的最佳选择。
⚠️警告: 在撰写本文时,我们对无树克隆进行了超出一般限制的测试。我们注意到,包含子模块的版本库在使用无树克隆时表现很差。具体来说,如果在无树克隆中运行 git fetch,那么 Git 中查找已更改子模块的逻辑就会为每次新提交触发一个树请求!在无树克隆中运行 git config fetch.recurseSubmodules false 可以避免这种情况。我们正在 Git 客户端中开发更强大的修复功能。
浅克隆
部分克隆是相对较新的 Git 功能,但有一个与无树克隆非常相似的老功能:浅克隆。浅克隆使用 git clone 中的 --depth=<N>参数来截断提交历史。通常,--depth=1 表示我们只关心最近的提交。浅克隆最好与 --single-branch --branch=<branch> 选项结合使用,以确保我们只下载计划立即使用的提交数据。
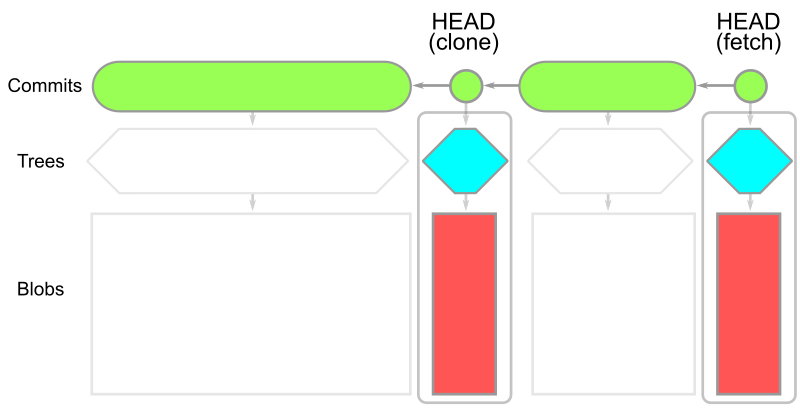
浅克隆的对象模型如图所示:
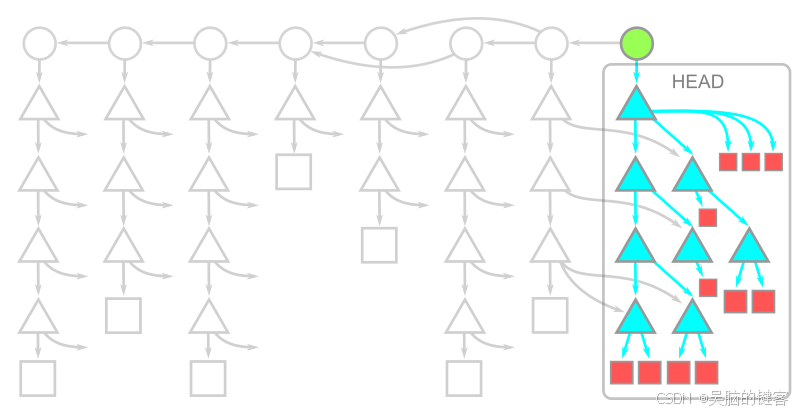
在这里,HEAD 处的提交仍然存在,但它与父提交和其他历史提交的联系被切断了。父提交被移除的提交称为浅层提交,它们共同构成了浅层边界。提交对象本身并没有改变,但客户端仓库中的一些元数据会指示 Git 客户端忽略这些父提交连接。所有提交树和 blob 都会被下载到客户端。
由于提交历史被截断,git merge-base 或 git log 等命令显示的结果与完全克隆时不同!一般来说,你不能指望它们按预期运行。回想一下,这些命令在部分克隆中也能按预期运行。即使在无 blob 的克隆中,像 git blame -- <path> 这样的命令也能正常运行,只是速度会比完全克隆慢一些。而浅克隆则根本不可能做到这一点!
另一个主要区别是 git fetch 在浅层克隆中的行为方式。在获取新提交时,服务器必须提供相对于浅层提交而言,这些提交的每一棵树和每一个 blob 都是 "新 "的。这种计算可能比典型的获取更昂贵,部分原因是维护良好的服务器可以使用可达性位图。根据其他人对远程仓库的贡献情况,在浅层克隆中执行 git fetch 操作最终可能会下载到几乎完整的提交历史!
下面描述了一些浅层克隆可能出现的问题,这些问题否定了所谓的价值。由于这些原因,我们不建议使用浅克隆,除非在构建后立即删除版本库。从浅克隆抓取可能弊大于利!
还记得前面提到的 "浅边界 "吗?客户端在执行 git fetch 命令时会向服务器发送该边界,告诉服务器它并没有该边界后的所有可访问提交。然后,客户端会请求最新的提交,以及从这些提交到边界中的浅层提交的所有可到达提交。如果另一个用户在该边界下启动了一个特性分支,然后浅层客户端获取了该特性(或者更糟糕的是,该特性被合并到了默认分支中),那么服务器就需要遍历全部历史,并为客户端提供几乎等同于完整克隆的服务!此外,服务器还需要计算这些数据,而无法利用可达性位图等性能特性的优势。
比较克隆选项
让我们回顾一下每个克隆选项。与其从纯粹的对象层面来审视它们,不如让我们来探究每一类对象。下图对每种存储库类型下载的数据进行了分组。除了克隆时下载的数据外,我们还可以考虑这样一种情况:一段时间过去后,客户端运行 git fetch,然后再运行 git checkout,转到新的提交。对于每一个选项,会下载多少数据。
完全克隆会下载所有可到达的对象。通常情况下,blobs 负责大部分数据。
在部分克隆中,有些数据不会立即提供,而是延迟到客户端需要时才提供。无数据块克隆会跳过数据块,但检出时所需的数据块除外。无树克隆会跳过历史记录中的所有树,而下载每次签出所需树的完整副本。
| Blobless clone | Treeless clone |
|---|---|
 |  |
git clone --depth=1,git fetch | git clone --depth=1,git fetch --depth=1 |
|---|---|
 |  |
数据说明了什么?
GitHub 工程师 @solmazabbaspour 设计并运行了一个实验,在各种开源软件源上比较这些不同的克隆选项。她将在明天发布一篇博文,介绍实验的全部细节和数据,但我将在此分享实验的执行摘要。以下是我们发现的一些共同主题,可以帮助你选择适合自己使用的方案:
除了默认的完全克隆,还有许多不同类型的克隆。如果你确实需要一个分布式工作流程,并希望所有数据都在本地版本库中,那么你应该继续使用完全克隆。如果你是专注于单个版本库的开发人员,而且你的版本库大小适中,那么最好的方法就是进行完全克隆。
如果你的版本库因为有很多大 Blob 而非常庞大,你可以改用无 blob 的部分克隆,因为克隆可以帮助你更快上手。这样做的代价是,某些命令(如 git checkout 或 git blame)需要在必要时下载新的 blob 数据。
一般来说,计算浅层提取比完全提取的计算成本更高。无论是完全克隆还是浅层克隆的版本库,都应始终使用完全取回而不是浅层取回。
在 CI 构建等工作流中,如果需要进行单次克隆并立即删除版本库,浅层克隆是一个不错的选择。浅层克隆是获取工作目录副本的最快方法,但从这些版本库中获取副本的成本要高得多,因此我们不建议开发人员使用浅层克隆。如果你在构建过程中需要提交历史,那么无树部分克隆可能比完全克隆更适合你。
总之,因人而异。现在,你已经掌握了这些不同的选项及其背后的对象模型,可以开始使用这些类型的克隆了。同时,你也应该注意这些非完全克隆选项的一些缺陷:
- 浅克隆会跳过提交历史。这使得
git log或git merge-base等命令无法使用。永远不要从浅克隆中获取! - 无树克隆包含提交历史,但下载缺失的树代价很高。因此,可以使用
git log(不带路径)和git merge-base,但git log -- <path>和git blame等命令速度极慢,不建议在这些克隆中使用。 - 无 Blob 克隆包含所有可访问的提交和树,因此 Git 在需要访问文件内容时会下载 Blob。这意味着可以使用
git log -- <path>等命令,但第一次运行git blame等命令时速度会慢一些。不过,这也是一个很好的方法,可以让你开始处理一个拥有大量旧的大型 blob 的超大版本库。 - 完全克隆的效果与预期一样。唯一的缺点是下载所有数据需要时间,而且还要为所有这些文件占用额外的磁盘空间。

















 1396
1396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









