




在人工智能的快速发展进程中,推理模型始终占据着核心地位。近日,昆仑万维天工团队推出的全新升级 Skywork-OR1(Open Reasoner 1)系列模型,犹如一颗重磅炸弹,在业界引起了广泛关注。该系列模型在同等参数规模下实现了业界领先的推理性能,进一步突破了大模型在逻辑理解与复杂任务求解方面的能力瓶颈,同时秉持开源精神,以完全开源的形式回馈开发者社区。
一、Skywork-OR1 系列模型介绍
Skywork-OR1 系列模型涵盖了三款高性能模型,各有千秋,分别针对不同的应用场景和需求:
- Skywork-OR1-Math-7B:这是一款聚焦数学领域的专项模型,别看它参数规模为 7B,却在数学推理方面展现出惊人的实力。同时,它还具备较强的代码能力。在高阶数学推理任务中,其在 AIME24 数据集上取得了 69.8% 的准确率,在 AIME25 数据集上也有 52.3% 的准确率,远超当前主流 7B 级别模型,充分彰显了其在数学推理上的专业优势。
- Skywork-OR1-7B-Preview:该模型融合了数学与代码能力,是一款兼具通用性与专业性的通用模型。在 AIME24 与 AIME25 数据集上,它实现了同参数规模下的最优表现,展现出强大的数学推理能力。在 LiveCodeBench 数据集上,同样取得了同等参数规模下的最优性能,说明其在代码生成与问题求解方面也毫不逊色。
- Skywork-OR1-32B-Preview:作为面向更高复杂度任务、具备更强推理能力的旗舰版本,Skywork-OR1-32B-Preview 在所有 benchmark 上均实现了对 QwQ-32B 的超越。其代码生成与问题求解能力已接近参数规模高达 671B 的 DeepSeek-R1,在大幅压缩模型体量的同时实现了卓越的性价比,充分展现出天工团队训练策略的先进性。
二、技术原理与创新
- 基于 GRPO 强化学习框架:Skywork-OR1 系列基于 GRPO 强化学习框架构建,通过多阶段训练策略逐步扩展模型的上下文处理能力。这种训练方式使得模型能够像人类一样,在面对复杂问题时逐步思考,分阶段解决问题。
- 严格筛选的训练数据:其训练数据经过严格筛选,数学数据集涵盖了 11 万道高难度题目,这些题目来自 AIME、Olympiads 等高难度数学竞赛题库,通过数据蒸馏技术从 89.6 万题数学库中精心挑选而出。代码数据集则保留了 1.37 万条通过单元测试的问题,确保数据的高质量和有效性。在训练过程中,还采用了动态采样验证机制,保证每个训练样本都具有足够的挑战性,从而提升模型的泛化能力。
- 动态熵控制采样策略:在强化学习中,模型采用了 τ=1.0 高温采样的自适应熵控制策略,增强了模型的探索能力,使其能够在复杂的解空间中找到更优的解决方案。
混合验证机制:为了进一步提高训练数据的质量,昆仑万维团队结合了人工评审与 LLM 自动判题的混合验证机制,清理低质量训练样本,为模型的训练提供了坚实的数据基础。
三、性能和测试
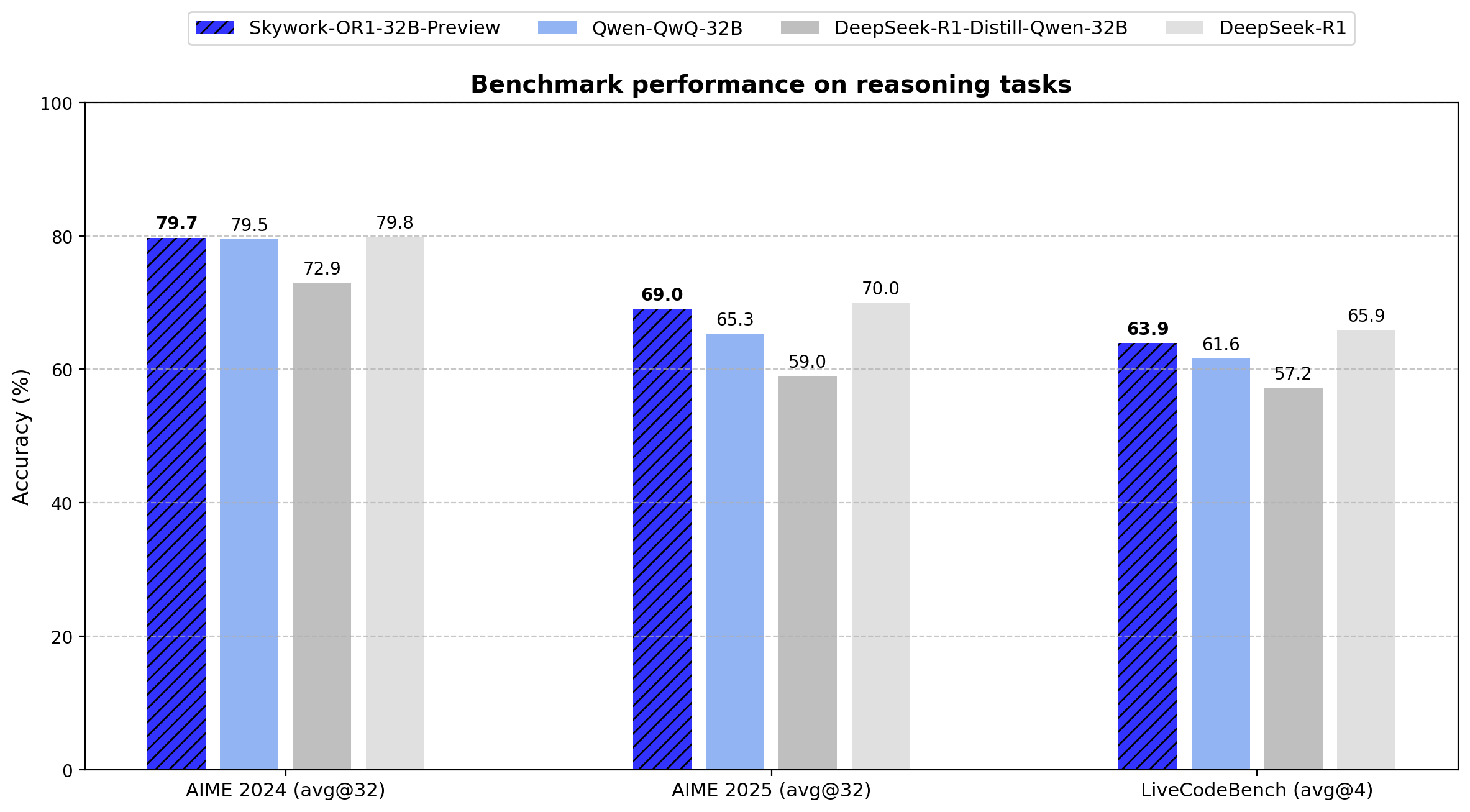

我们在 AIME24、AIME25 和 LiveCodeBench 上评估了我们的模型。我们没有使用以往工作中常见的 Pass@1,而是引入了 Avg@K 作为主要指标。该指标稳健地衡量了模型在 K 次独立尝试中的平均性能,减少了随机性的影响,提高了结果的可靠性。我们相信,Avg@K 能更好地反映模型的稳定性和推理的一致性。
详细结果见下表。
| Model | AIME24 (Avg@32) | AIME25 (Avg@32) | LiveCodeBench (8/1/24-2/1/25) (Avg@4) |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 39.2 | 37.6 |
| Light-R1-7B-DS | 59.1 | 44.3 | 39.5 |
| DeepSeek-R1-Distill-Qwen-32B | 72.9 | 59.0 | 57.2 |
| TinyR1-32B-Preview | 78.1 | 65.3 | 61.6 |
| QwQ-32B | 79.5 | 65.3 | 61.6 |
| DeepSeek-R1 | 79.8 | 70.0 | 65.9 |
| Skywork-OR1-Math-7B | 69.8 | 52.3 | 43.6 |
| Skywork-OR1-7B-Preview | 63.6 | 45.8 | 43.9 |
| Skywork-OR1-32B-Preview | 79.7 | 69.0 | 63.9 |


















 5181
5181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









