









近日,与网络高人学习,用Coze调用deepseek火山引擎版满血R1大模型,可以构建自己的业务级智能体,觉得还挺好玩的。又闻言,Dify、TensorFlow、PyTorch、Keras、Fastai、Hugging Face等工具可以微调诸如deepseek、chatgpt、doubao等大模型。
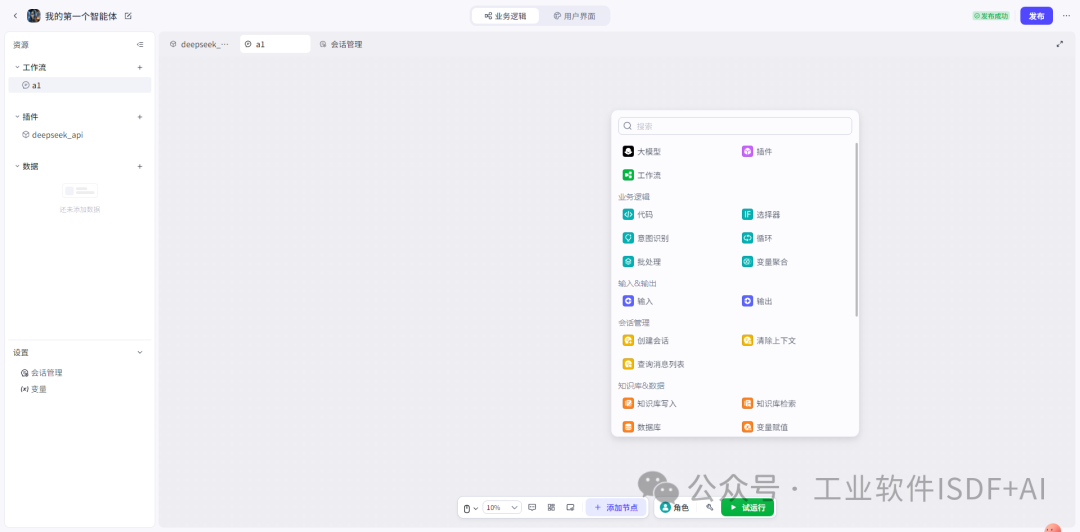
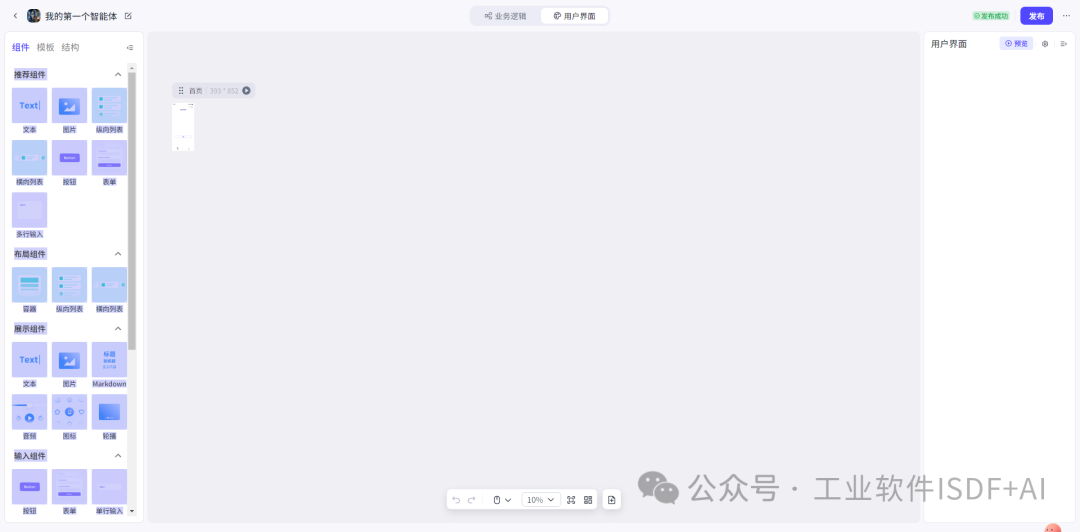
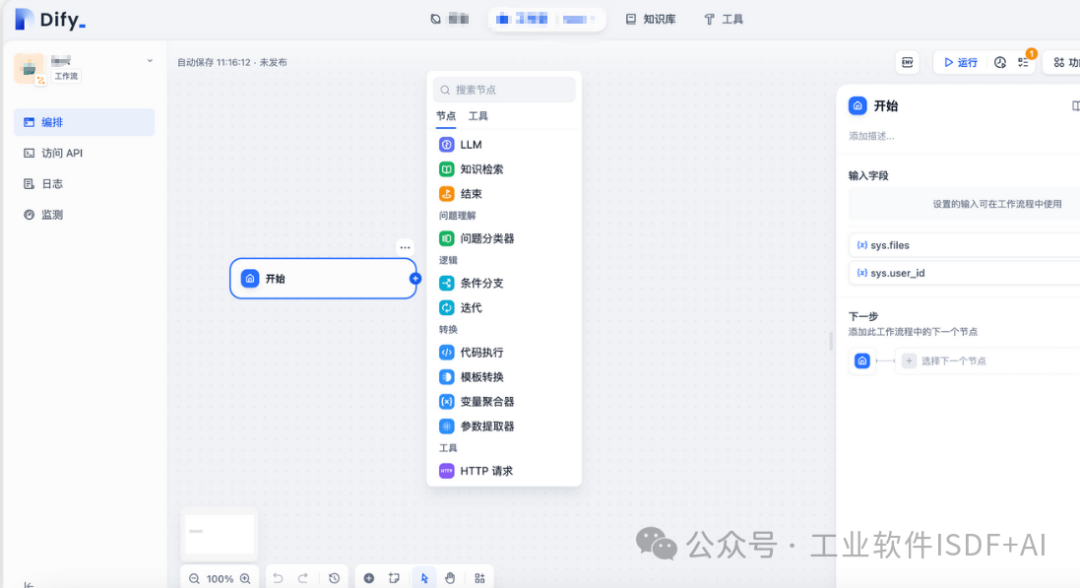
下面重点讲Dify和Coze在调用deepseek上的区别做一个简要分析,供个人认知扫盲。
1. 调用方式与底层逻辑
| 维度 | 扣子(Coze) | Dify |
| 技术路径 | 通过平台预置的模型接口选择 DeepSeek(需平台支持) | 通过 API 密钥手动配置或代码集成 DeepSeek 模型 |
| 依赖关系 | 依赖扣子平台是否开放 DeepSeek 的接入权限 | 依赖 DeepSeek 是否提供开放 API(如 HTTP API) |
| 代码需求 | 完全无代码,图形化界面操作 | 可能需要编写配置代码(如 YAML 文件或 Python 脚本) |
| 模型控制权 | 由扣子平台封装,用户无法直接干预模型底层参数 | 可自定义模型参数(如温度值、max_tokens 等) |
2. 灵活性与扩展
| 维度 | 扣子(Coze) | Dify |
| 功能扩展 | 仅能使用扣子平台支持的 DeepSeek 功能模块 | 可自由扩展功能(如结合 RAG、自定义数据处理逻辑) |
| 模型组合 | 通常单一模型调用,组合需依赖扣子的工作流功能 | 支持多模型协同(如 DeepSeek + GPT-4 混合调用) |
| 数据流控制 | 数据输入/输出受限于扣子平台的设计 | 可完全自定义数据处理管道(如前置清洗、后置过滤) |
3. 权限与安全性
| 维度 | 扣子(Coze) | Dify |
| 密钥管理 | 平台自动托管密钥,用户无需直接接触 | 需自行管理 DeepSeek API 密钥(存在泄露风险) |
| 私有化部署 | 不支持,依赖扣子云端服务 | 支持私有化部署(模型和数据本地化运行) |
| 审计能力 | 仅限平台提供的日志 | 可自定义日志记录和监控体系 |
4. 典型场景对比
| 场景 | 扣子(Coze) | Dify |
| 快速验证需求 | 适合快速测试 DeepSeek 的基础能力(如生成文案) | 需配置开发环境,时间成本较高 |
| 企业级应用 | 功能受限,难以满足复杂需求 | 适合深度定制(如结合内部知识库的代码生成系统) |
| 成本控制 | 按扣子平台套餐计费,无需关心模型调用量 | 可精细控制 DeepSeek API 的调用频次和成本 |
5. 关键差异总结
| 对比项 | 扣子(Coze) | Dify |
| 本质差异 | 平台级封装(黑盒调用) | 开发者自主集成(白盒控制) |
| 优势 | 简单、快速、无需运维 | 灵活、可定制、支持私有化 |
| 劣势 | 功能受限、无法深度优化 | 需技术能力、部署成本较高 |
如何选择?
选扣子调用:
➤ 需求简单,追求“开箱即用”
➤ 无技术团队,且接受平台功能限制
选Dify调用:
➤ 需结合企业私有数据或定制复杂逻辑
➤ 希望完全掌控模型调用链路和安全性


















 5067
5067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











