







有效跟踪(Eligibility traces)是强化学习的基本机制之一。例如,TD(λ)算法,λ引用了有效跟踪。
几乎任何的时间差分(TD)方法,如Q-learning或Sarsa,都可以与有效跟踪相结合,以获得更通用的方法,从而提高学习效率。
有效跟踪与TD和MC方法进行统一和概括。有效跟踪提供了一种在线实现蒙特卡罗方法的方法,以及在没有episodes的情况下实现连续问题的方法。还提供了一种简练的算法机制,具有显著的计算优势。该机制是一个短期记忆向量,有效跟踪 e t ∈ R n e _t \in \R^n et∈Rn,与长期的权向量 θ t ∈ R n \theta _t \in \R^n θt∈Rn 并存。
1、The λ-return
第7章中,定义了 n-step 版本的回报,即前n个奖励的总和加上n步中达到的状态的估计值,每一步都进行了适当的折现:

TD(λ)算法可以被理解为平均n-step备份的方式。这种平均包含所有n-step备份,每个权重成正比
λ
n
−
1
\lambda^{n-1}
λn−1,其中λ∈[0,1],和归一化因子为1−λ,确保权重之和为1(见下图)。

由此产生的备份形成回报,称为λ-return,定义为:
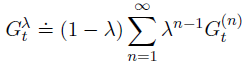
下图进一步说明了在 λ-return 中 n-step 回报序列下的权重。

到达一个终止状态后,所有 n-step 回报的都等于
G
t
G_t
Gt,我们可以把终止后的那项从总和里分离:
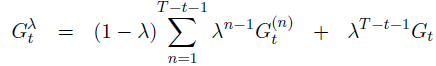
off-line λ-return algorithm:
作为一种离线算法,它在整个过程中不改变权向量。然后,在episode的最后,根据我们通常使用的半梯度规则,使用λ-return作为目标,进行了一系列离线更新:
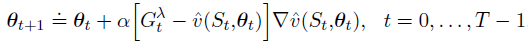
这是一种前向学习算法:通过展望未来的奖励和状态来决定如何更新每个状态。

2、TD(λ)
TD(λ)是第一个使用eligibility traces的算法,有三方面的优势:
- 它会在每一集的每一步更新权重向量,而不仅仅是在最后,因此它的估计可能会更好。
- 它的计算在时间上是均匀分布的,而不是在这一集的结尾。
- 它可以应用于 continuing 问题,而不仅仅是 episodic 问题。
在TD(λ)中,eligibility trace 向量开始时初始化为零,在每个时间步通过梯度值进行增加,然后通过
γ
λ
\gamma\lambda
γλ逐渐消退:
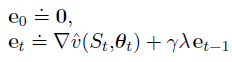
状态值预测的 TD error:

权重向量的更新:
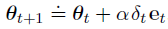

向后图:每个更新都依赖于当前 TD error 和过去的 eligibility traces。

3、An On-line Forward View
off-line λ-return algorithm 的主要缺点是 off-line:在这一集结束之前,它什么也学不到。这是由于它的前视图,它只在事件完成时定义一个目标。为了在整个过程中改变权重,只能使用当时的信息。
如何实现 online forward view algorithm?
答案是,使用 h-truncated λ-return。
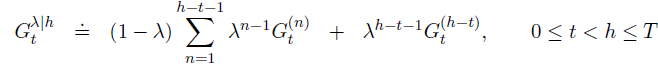
θ
t
h
\theta^h_t
θth 表示在范围 h 的序列中用于在时间 t 处生成值函数的权重。每个序列的第一个权重向量继承自上一个episode的权重。
前3次序列的更新:

一般形式(online λ-return algorithm):

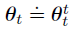
online λ-return algorithm 在每个episode期间每个时间步 t 上完全在线、确定一个新的权向量 θt ,并且仅使用在时间 t 的信息。主要缺点是计算复杂
4、True Online TD(λ)
线性函数近似中使用online λ-return 算法 —— True Online TD(λ)
通过 on-line λ-return 算法产生的权重向量的序列可以排成一个三角形:
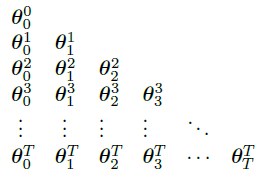
只有对角线上的权重向量
θ
t
t
\theta^t_t
θtt 需要由算法生成。第一个
θ
0
0
\theta^0_0
θ00 是输入,最后一个
θ
T
T
\theta^T_T
θTT 是输出,中间的每个权重向量
θ
t
t
\theta^t_t
θtt 在 n-step 回报的更新中起引导性作用。算法最后把对角线上的权重向量重命名为
θ
t
≐
θ
t
t
\theta_t \doteq \theta^t_t
θt≐θtt 。然后,策略是找到一种紧凑、高效的方法计算每个
θ
t
t
\theta^t_t
θtt 。
对于线性情况:
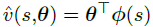
the true online TD(λ) algorithm:

其中,
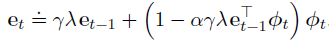
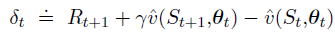
















 8176
8176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









