







上次我发表了一篇题为《使用Ollama搭建自己的简单知识库》的文章,发现大家在使用过程中遇到了不少问题,我自己也遇到过类似的问题。特别是当我在MaxKB的知识库中导入一篇文章后,在应用中提问,得到的回答却答非所问,完全达不到我的要求。今天我就想分析一下这个问题以及如何改进。
一般来说,这种问题根源在于文章上传的分段不佳,由于分段不佳导致的命中率低,因此答非所问。下面我们来复现一下这个问题。
首先,导入一篇文档。
下一步采用推荐的智能分段方式进行分段:
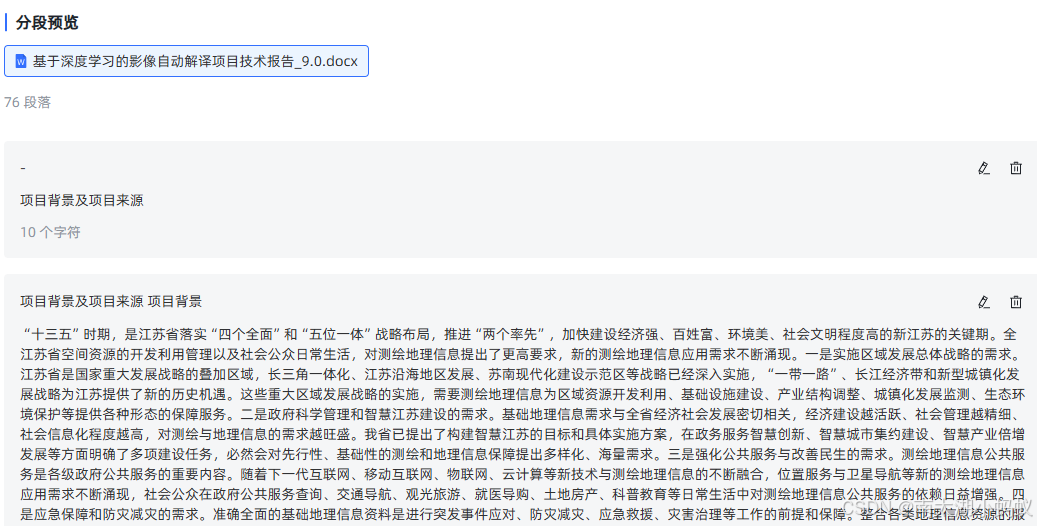
可以看到,分段结果很杂乱无章,甚至可以看到出现了乱码:


而乱码部分的实际内容如下:

也就是说,这种知识库导入方式对于公式的解析其实并不完善。还是对于文本更加方便。
而且,同一篇文档,如果可以用word形式上传最好使用word,而不是PDF,因为PDF中可能文字是以图片形式存在的,而且可能会混进很多不同的格式符号,导致分段的错误。
可以看到,当我换成word之后,分段还是比较清晰的。
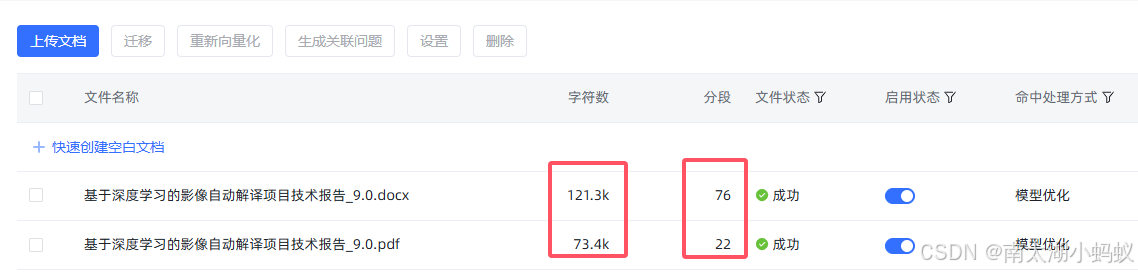
可以看到,同一篇文章,用word和PDF得到的分段数差距很大,字符数也有不小的差别,所以得到的分段是更清晰的。
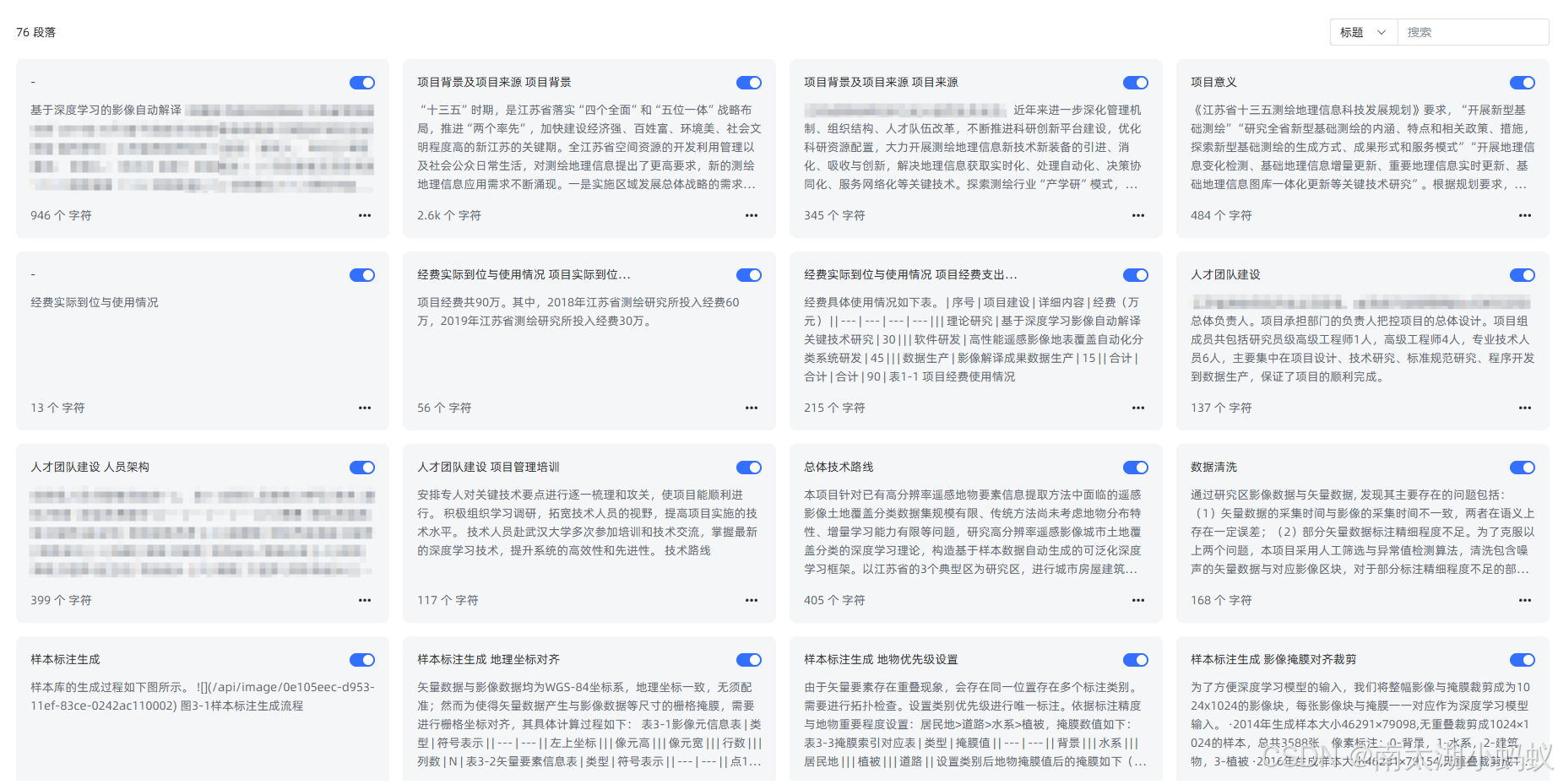
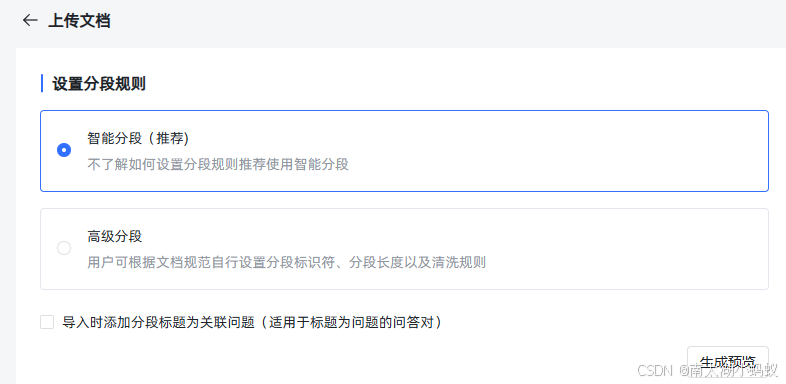
这种是“智能分段”模式,也可以使用“高级分段”模式,选择我们需要的分段标识符来进行分段。
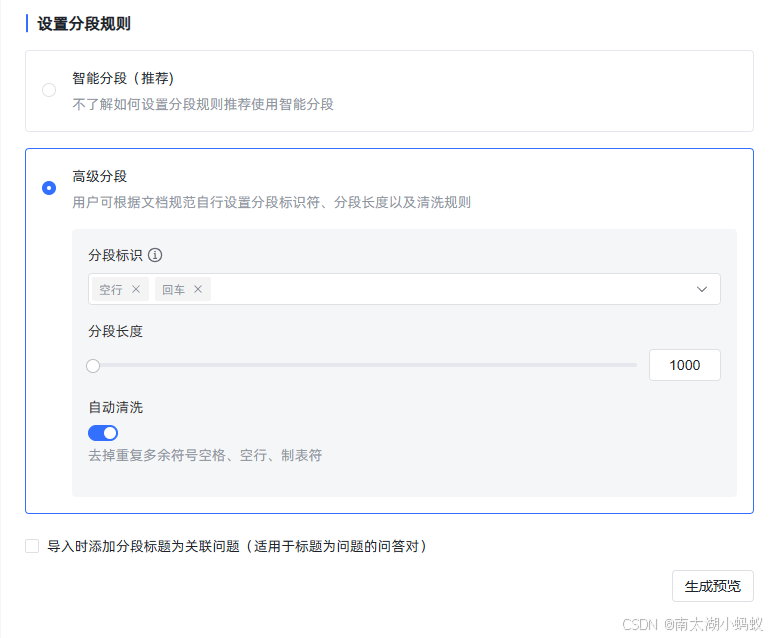
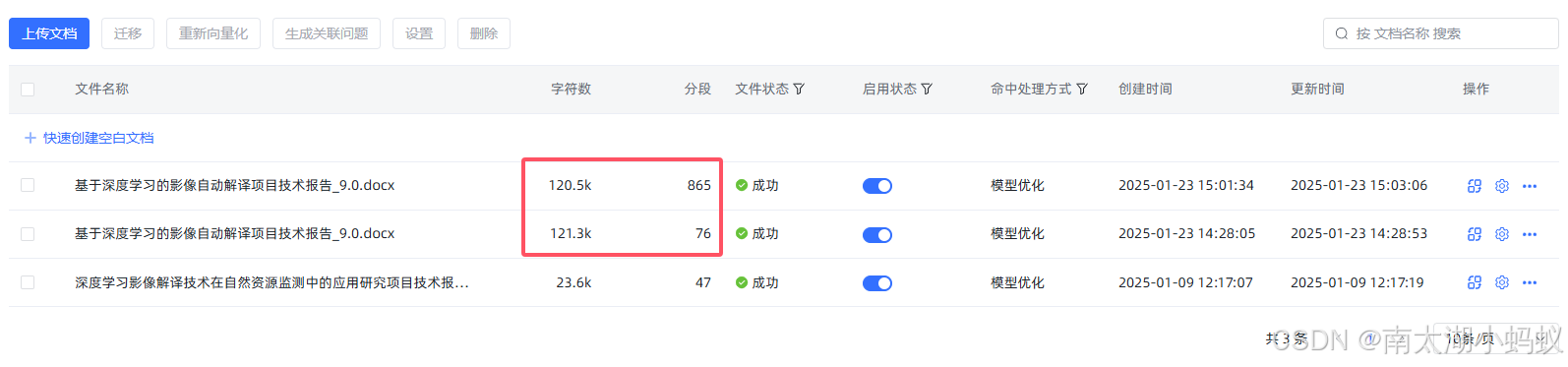
这个分段数就更多了。不过这种方式要慎用,最好自己提前处理一下,否则换行或者回车符并不一定是你想要的分段方式,容易造成一段完整的语义段落被切分成很多无意义的分段。
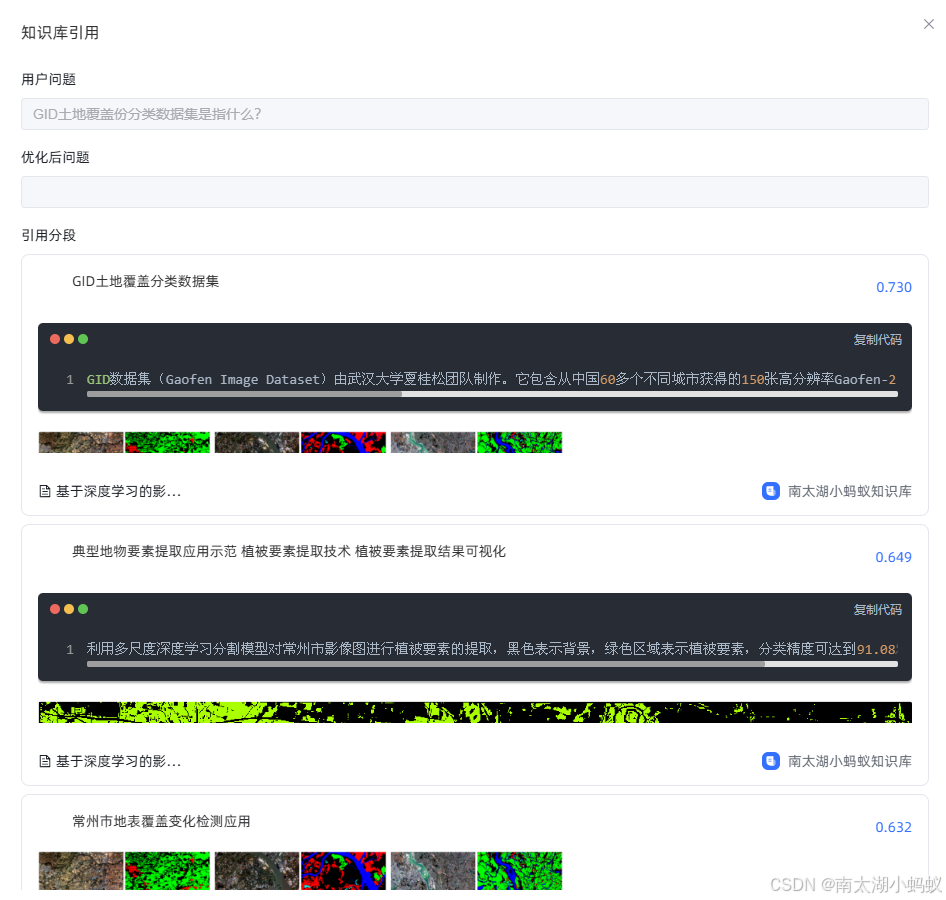
现在再来提问,效果比之前更好:


同时,在调试窗口我们也可以更加直观的看到问答的结果,以及引用的分段:
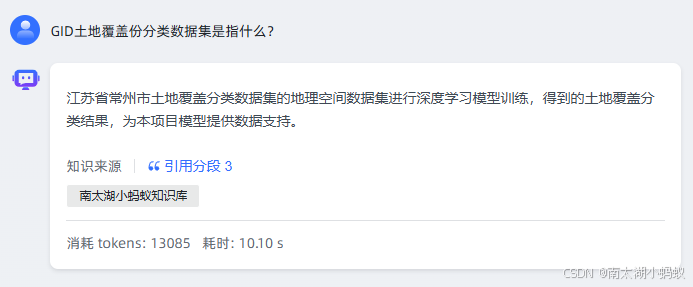
用本地未加入知识库的原始ollama大模型试试:
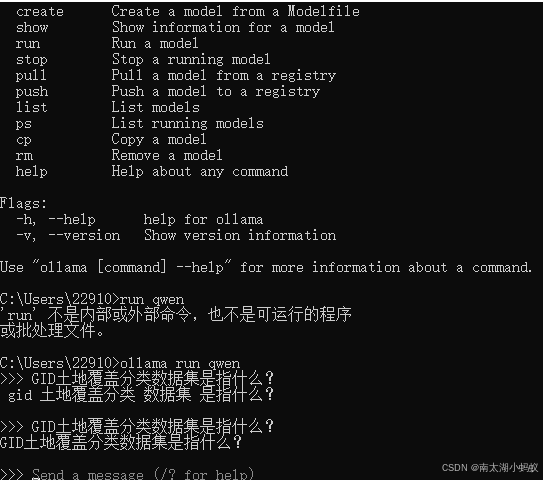
发现回答的非常搞笑,它完全不知道我在说什么,仅仅是把我的问题复述了一遍,说明采用我们分段后的知识库还是有效果的。


















 4887
4887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









