







本文以论文小结的形式汇报近几年联邦学习安全方面的研究。
这里写目录标题
- 防御
Deep Leakage from Gradients (DLG) 梯度的数据泄露
1 Reconstruction Attack 重构攻击/模型反演攻击
1.1 CAFE: Catastrophic Data Leakage in Vertical Federated Learning
持有label的server为攻击者,利用 VFL 框架下 data index alignment,通过逐层的还原,实现了 VFL 阶段过程中 大批量训练数据 的还原。
见:https://blog.csdn.net/weixin_42468475/article/details/123174068
1.2 Beyond Inferring Class Representatives: User-Level Privacy Leakage From Federated Learning
curios server,利用多任务GAN 训练,恢复 client 级别的多种隐私,包括 数据所属的类别、真假、来自哪一个 client,最后还能实现 某位client 训练数据的恢复。 缺陷是要求batchsize=1时才能恢复。
2 Attribute Reconstruction Attack 属性重构攻击
不同于先前的 模型反演攻击(Model Inversion Attack,MIA),ARA是给定无关属性 X o t h e r s X_{others} Xothers和标签 Y Y Y,对某单一目标属性 X s X_{s} Xs进行推断,而MIA是在某一类大致相似的提前下,确定某一类的所有输入属性 X o t h e r s + X s X_{others}+X_{s} Xothers+Xs,假设场景不同。
见:A Novel Attribute Reconstruction Attack in Federated Learning
本文利用了受害者模型每轮更新的梯度,构建了一批虚拟样本并计算其对应的更新梯度,通过梯度上升优化得到 虚拟样本梯度和受害者模型上传的真实梯度的 cos 相似度的最大值:
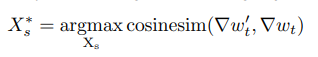
然后使用基于梯度的算法进行迭代更新。
3 Source Inference Attack 数据源推断攻击
在成员推断攻击的基础上进行改进,确立了某一数据来源于哪个参与方。
见:Source Inference Attacks in Federated Learning
4 Class Representative inference 类推断攻击
这个攻击和重构攻击(模型反演攻击)有点像,但是类推断攻击推断每一类别的大致样子,要求某一 client 单独持有某一类的数据。
用原文的话来说就是:attack could only infer class-wised representatives, which are generic samples characterizing class properties rather than the exact samples from the clients [Inference attacks against collaborative learning].
5 Membership Inference Attack成员推断攻击
5.1 GAN Enhanced Membership Inference: A Passive Local Attack in Federated Learning
在FL场景下,各 client 所持有的数据存在分布不一致的情况,而之前的 shadow model 的方法要求 攻击者拥有部分和 target model 训练集同分布的辅助数据集,才能进行攻击;所以之前的方法在 FL 场景下的效果会大打折扣,或者说需要辅助信息(和 target model 训练集同分布的数据集)。
为此,本文介绍了一种利用 GAN 获取 整体参与者们 训练数据的分布,从而进行了更加精准的成员推断攻击。
https://blog.csdn.net/weixin_42468475/article/details/123771624
5.2 Efficient passive membership inference attack in federated learning
相较于之前基于更新量的成员推断攻击,本文提出一种黑盒的利用 连续次更新量(结合了 time series) 的 推断攻击,仅需 极小的计算量(虽然攻击准确率差不多)。
https://blog.csdn.net/weixin_42468475/article/details/123764570
防御
防御各类隐私攻击
1 Digestive neural networks: A novel defense strategy against inference attacks in federated learning
本文在联邦学习场景下,提出了一种 Digestive neural networks (后称DNN,区别于传统的DNN),类似于输入数据的特征工程,用于“抽取原始数据的有效特征,并修改原始数据使之不同”,本地模型经过处理后的数据进行训练,从而大大降低了 FL 中各类推断攻击的成功率(假设server是攻击者)。
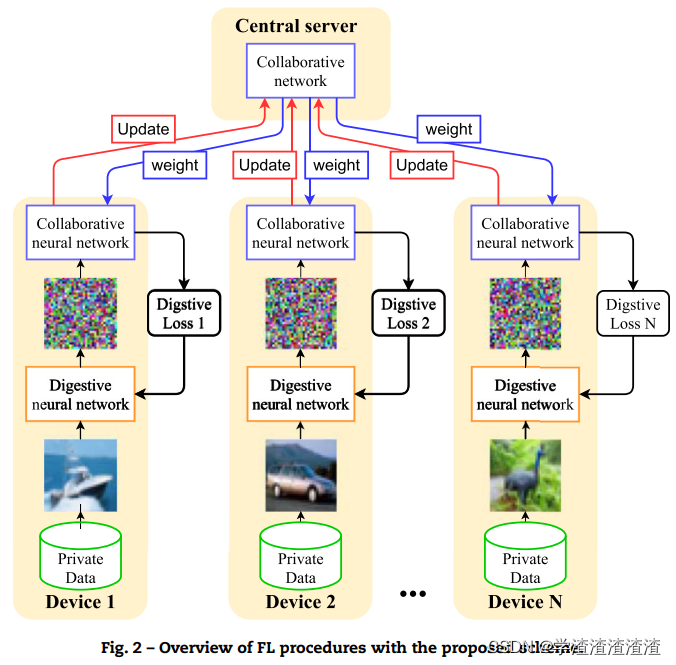
2 MixNN: Protection of Federated Learning Against Inference Attacks by Mixing Neural Network Layers
本文介绍了一种介于 client 和 server 中间的代理网络 MixNN proxy ,这样的代理网络有点类似同态加密(相当于利用神经网络进行加密),可以有效避免训练过程中的各类推断攻击。除此以外,本文还设计了一种利用 update 进行的 attribute 推断攻击,用于评估不同防御方法的防御效果。
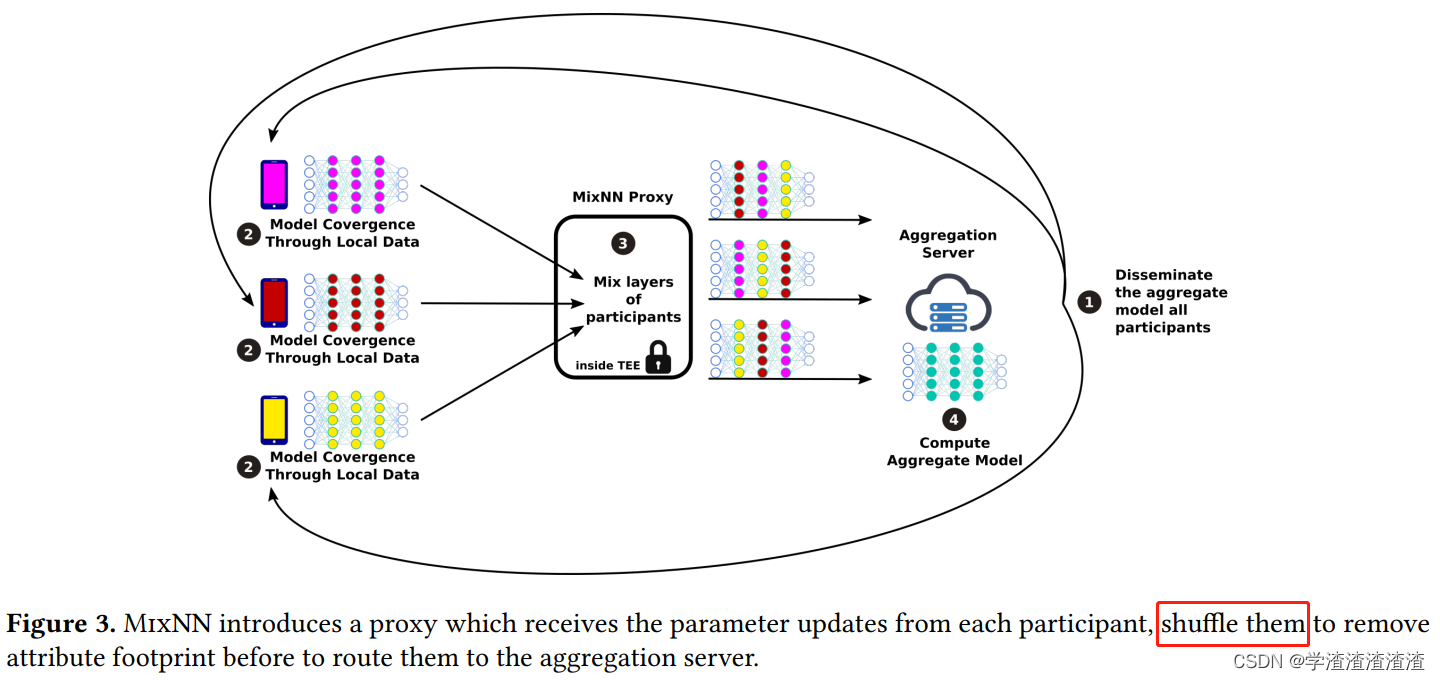
https://blog.csdn.net/weixin_42468475/article/details/124076585
2 差分隐私
2.1Local and Central Differential Privacy for Robustness and Privacy in Federated Learning
类似综述+实验论文,主要讲了在 FL 场景下 Local Differential Privacy (LDP)和 Central Differential Privacy (CDP)在遭受推断攻击(针对privacy ) 和 投毒攻击(针对robustness) 时的保护能力。
https://blog.csdn.net/weixin_42468475/article/details/123977753
3 全面的框架:
3.1 Efficient and Privacy-Enhanced Federated Learning for Industrial Artificial Intelligence
本文提出了一种包含同态加密、差分隐私、多方安全计算的FL隐私保护框架。
https://blog.csdn.net/weixin_42468475/article/details/123744231
===============================================================


















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











