







2021-ICCV-Weakly-supervised Video Anomaly Detection with Robust Temporal Feature Magnitude Learning
具有鲁棒时间特征幅度学习的弱监督视频异常检测
摘要
带有弱监督视频级别标签的异常检测通常被表述为一个多实例学习(MIL)问题,其中我们的目标是识别包含异常事件的片段,每个视频表示为一包视频片段。目前的方法虽然具有有效的检测性能,但对于积极的实例,即异常视频中罕见的异常片段的识别,在很大程度上被占主导地位的消极实例所偏向,特别是当异常事件是与正常事件相比只有微小差异的细微异常时。在许多忽略重要视频时间依赖关系的方法中,这个问题更加严重。为了解决这一问题,我们引入了一种新颖且理论上合理的方法,称为鲁棒时间特征幅度学习(RTFM),该方法训练了一个特征幅度学习函数来有效地识别正实例,极大地提高了 MIL 方法对异常视频中负实例的鲁棒性。RTFM 还采用扩展卷积和自注意力机制来捕获长期和短期的时间依赖性,以更忠实地学习特征量级。大量实验表明,启用 RTFM 的 MIL 模型(i)在四个基准数据集(ShanghaiTech、UCF-Crime、XD-Violence 和 UCSD-Peds)上的性能大大优于几种最先进的方法,(ii)显著提高了细微异常的可识别性和样本效率。
1. 引言
视频异常检测由于其在自主监控系统中的应用潜力而得到了广泛的研究 [15、56、66、78]。视频异常检测的目标是识别异常事件发生的时间窗口——在监控环境下,异常的例子有欺凌、入店行窃、暴力等。虽然单类分类器(OCCs,也称为无监督异常检测)在这种情况下已经探索了专门使用正常视频训练的方法 [15、17、27、30、46、47、76],但性能最好的方法是使用带有正常或异常视频级标签注释的训练样本来探索弱监督设置 [56、66、78]。与 OCC 方法相比,这种弱监督设置以相对较小的人工注释工作为代价,实现了更好的异常分类精度。
弱监督异常检测的主要挑战之一是如何从标记为异常的整个视频中识别异常片段。这是由于两个原因,即:1)来自异常视频的大部分片段由正常事件组成,这会压倒(overwhelm)训练过程并对少数异常片段的拟合提出挑战;2)异常片段可能与正常片段没有足够的区别,这使得正常片段和异常片段之间的清晰区分具有挑战性。使用多实例学习(MIL)方法训练的异常检测 [56、66、74、80] 通过使用相同数量的异常和正常片段平衡训练集来缓解上述问题,其中正常片段是从正常视频中随机选择的异常片段是异常视频中异常得分最高的片段。虽然部分解决了上述问题,但 MIL 引入了四个问题:1)异常视频中的最高异常分数可能不是来自异常片段;2)从正常视频中随机选择的正常片段可能相对容易拟合,这对训练收敛性提出了挑战;3)如果视频有多个异常片段,我们就失去了在每个视频中包含更多异常片段的更有效的训练过程的机会;4)分类分数的使用提供了一个弱的训练信号,不一定能很好地区分正常和异常片段。在忽略重要时间依赖关系的方法中,这些问题甚至更加严重 [27、30、66、78]。
2. 相关工作
无监督异常检测。传统的异常检测方法仅假设正常训练数据的可用性,并使用手工制作的特征来处理单类分类问题 [2、32、64、75]。随着深度学习的出现,最近的方法使用了预训练深度神经网络的特征 [11、19、40、54、77]。其他人对正常流形的潜在空间施加约束以学习紧凑的常态表示 [1、3–5、8–10、13、28、31、33、41、43、49、52、57、59、63、79]。或者,一些方法依赖于使用生成模型的数据重建来通过(对抗性地)最小化重建误差来学习正常样本的表示 [6、14、18、18、27、34–36、41、48、51、52、61、67、81]。这些方法假设看不见的异常视频 / 图像通常无法很好地重建,并将重构误差高的样本视为异常。然而,由于缺乏异常的先验知识,这些方法可能会过度拟合训练数据并且无法区分异常事件和正常事件。读者可以参考 [38] 以全面回顾这些异常检测方法。
弱监督异常检测。利用一些标记的异常样本已经显示出比无监督方法显着提高的性能 [26、37、39、50、56、58、66、71-73]。然而,大规模的帧级标签注释太昂贵而无法获得。因此,目前的 SOTA 视频异常检测方法依赖于使用更便宜的视频级注释的弱监督训练。Sultani 等人 [56] 提出了使用视频级标签,并引入了大规模弱监督视频异常检测数据集 UCF-Crime。从那时起,这个方向就引起了研究界的关注 [62、66、74]。
弱监督视频异常检测方法主要基于 MIL 框架 [56]。然而,大多数基于 MIL 的方法 [56、74、80] 无法利用异常视频标签,因为它们可能会受到正包中标签噪声的影响,而正包中的标签噪声是由于正常片段被误选为异常视频中的顶级(top)异常事件而引起的。为了解决这个问题,Zhong 等人 [78] 将这个问题重新表述为噪声标签问题下的二元分类,并使用图卷积神经(GCN)网络来清除标签噪声。尽管本文显示的结果比 [56] 更准确,但 GCN 和 MIL 的训练计算量大,并且可能导致无约束的潜在空间(即正常和异常特征可以位于特征空间的任何位置),这可能导致性能不稳定。相比之下,与原始 MIL 公式相比,我们的方法具有微不足道的计算开销。此外,我们的方法通过基于 ℓ 2 \ell_2 ℓ2 范数的时间特征排名损失将表示学习和异常评分学习统一起来,从而更好地分离正常和异常特征表示,与以前的 MIL 方法相比改进了对弱标签的探索 [56、62、66、74、78、80]。
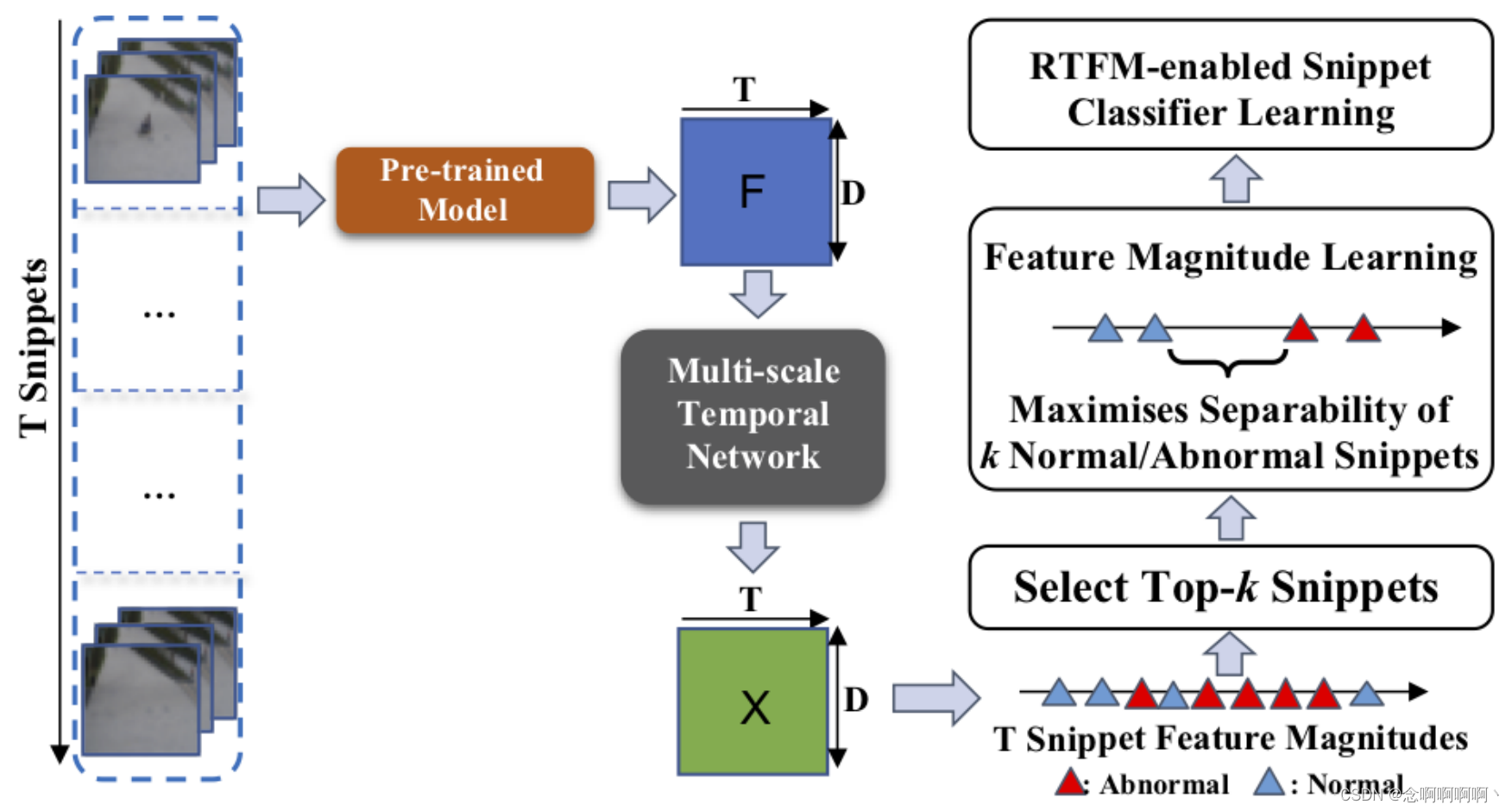
3. 提出的方法:RTFM
我们提出的鲁棒时间特征幅度(RTFM)方法旨在使用弱标记视频进行训练来区分异常和正常片段。给定一组弱标记的训练视频
D
=
{
(
F
i
,
y
i
)
}
i
=
1
∣
D
∣
\mathcal{D}=\left\{\left(\mathbf{F}_i,\ y_i\right)\right\}_{i=1}^{\left|\mathcal{D}\right|}
D={(Fi, yi)}i=1∣D∣,其中
F
∈
F
⊂
R
T
×
D
\mathbf{F}\in\mathcal{F}\subset\mathbb{R}^{T\times D}
F∈F⊂RT×D 是来自
T
T
T 个视频片段的维度
D
D
D 的预计算特征(例如,I3D [7] 或 C3D [60]),
y
∈
Y
=
{
0
,
1
}
y\in\mathcal{Y}=\left\{0,\ 1\right\}
y∈Y={0, 1} 表示视频级注释(如果
F
i
\mathbf{F}_i
Fi 是正常视频则
y
i
=
0
y_i=0
yi=0,否则
y
i
=
1
y_i=1
yi=1)。RTFM 使用的模型表示为
r
θ
,
ϕ
(
F
)
=
f
ϕ
(
s
θ
(
F
)
)
r_{\theta,\ \phi}(\mathbf{F})\ =\ f_\phi\left(s_\theta\left(\mathbf{F}\right)\right)
rθ, ϕ(F) = fϕ(sθ(F)) 并返回
T
T
T 维特征
[
0
,
1
]
T
\left[0,\ 1\right]^T
[0, 1]T 表示将
T
T
T 个视频片段分类为异常或正常,其中参数
θ
,
ϕ
\theta,\ \phi
θ, ϕ 定义如下。该模型的训练包括端到端多尺度时间特征学习、特征幅度学习和启用 RTFM 的 MIL 分类器训练的联合优化,损失为
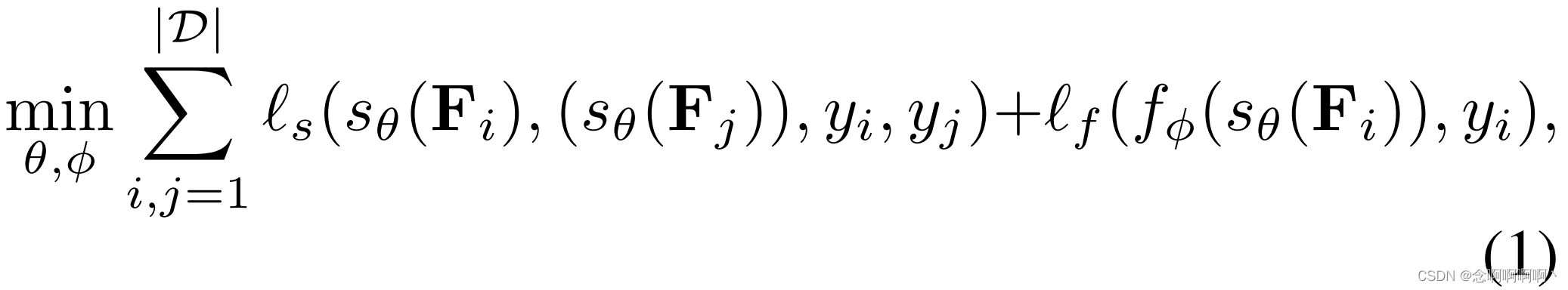
其中 s θ : F → X s_\theta : \mathcal{F}\rightarrow\mathcal{X} sθ:F→X 是时间特征提取器( X ⊂ R T × D \mathcal{X}\subset\mathbb{R}^{T\times D} X⊂RT×D), f ϕ : X → [ 0 , 1 ] T f_\phi : \mathcal{X}\rightarrow\left[0,\ 1\right]^T fϕ:X→[0, 1]T 是片段分类器, ℓ s ( . ) \ell_s\left(.\right) ℓs(.) 表示最大化特征之间可分离性的损失函数,来自正常和异常视频的 t o p − k top-k top−k 片段特征, ℓ f ( . ) \ell_f\left(.\right) ℓf(.) 是训练片段分类器 f ϕ ( . ) f_\phi\left(.\right) fϕ(.) 的损失函数,也使用来自正常和异常视频的 t o p − k top-k top−k 片段特征。接下来,我们讨论了我们提出的 RTFM 的理论动机,然后是对该方法的详细描述。
3.1. RTFM 的理论动机
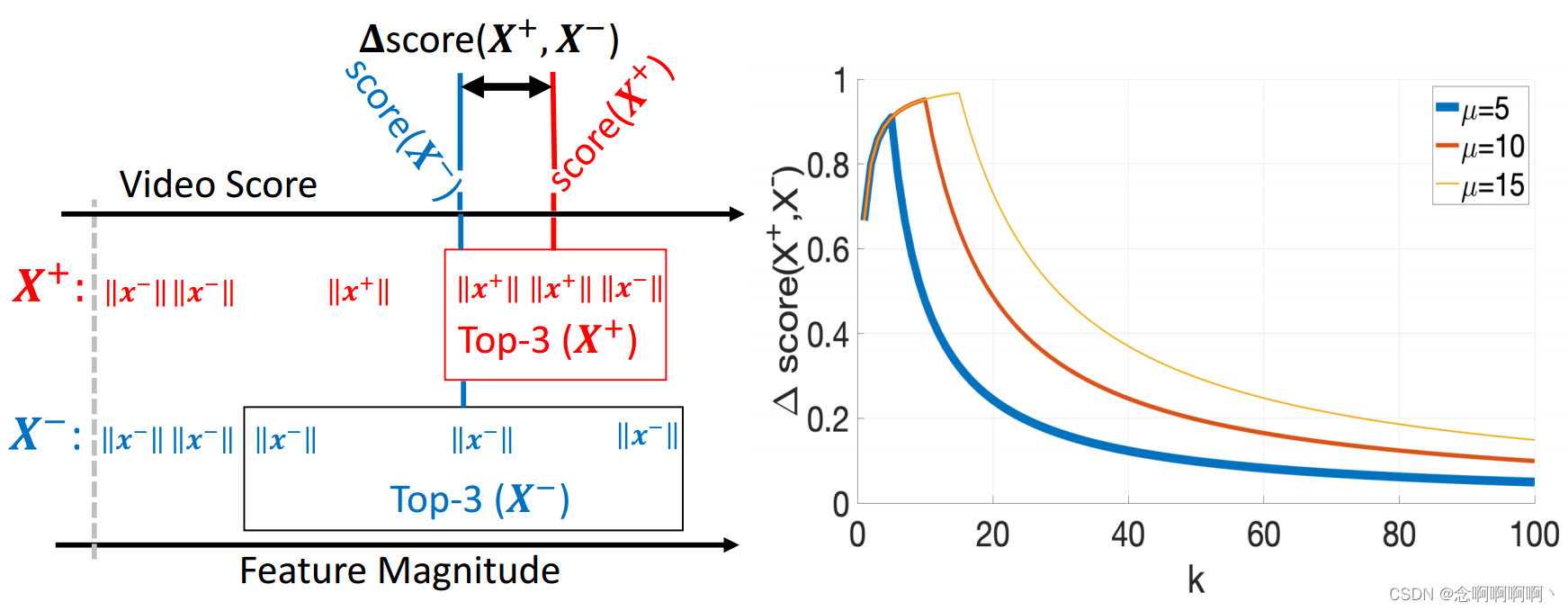
[24] 中的 t o p − k top-k top−k MIL 将 MIL 扩展到一个环境,其中正包中包含最少数量的正样本,负包也包含正样本,但程度较小,并且它假设分类器可以分离正样本和负样本。我们的问题不同,因为负包不包含正样本,我们不做分类可分离性假设。按照上面介绍的术语,从视频中提取的时间特征在(1)中表示为 X = s θ ( F ) \mathbf{X}=s_\theta\left(\mathbf{F}\right) X=sθ(F),其中片段特征由 X \mathbf{X} X 的行 x t \mathbf{x}_t xt 表示。异常片段表示为 x + ∼ P x + ( x ) \mathbf{x}^+\sim P_x^+\left(\mathbf{x}\right) x+∼Px+(x),和一个正常的片段, x − ∼ P x − ( x ) \mathbf{x}^-\sim P_x^-\left(\mathbf{x}\right) x−∼Px−(x)。异常视频 X + \mathbf{X}^+ X+ 包含从 P x + ( x ) P_x^+\left(\mathbf{x}\right) Px+(x) 抽取的 μ \mu μ 个片段和从 P x − ( x ) P_x^-\left(\mathbf{x}\right) Px−(x) 抽取的 ( T − μ ) (T-\mu) (T−μ) 个片段,而正常视频 X − \mathbf{X}^- X− 包含从 P x − ( x ) P_x^-\left(\mathbf{x}\right) Px−(x) 抽取的所有 T T T 个片段。
为了学习一个可以将视频和片段分类为正常或异常的函数,我们定义了一个函数,该函数使用片段的大小对片段进行分类(即,我们使用 ℓ 2 \ell_2 ℓ2 范数来计算特征大小),而不是假设正常和异常片段之间的分类可分离性(如 [24] 中假设的那样),我们做了一个更温和的假设 E [ ∣ ∣ x + ∣ ∣ 2 ] ≥ E [ ∣ ∣ x − ∣ ∣ 2 ] \mathbb{E}\left[||x^+||_2\right]≥\mathbb{E}\left[||x^-||_2\right] E[∣∣x+∣∣2]≥E[∣∣x−∣∣2]。这意味着通过从 s θ ( F ) s_\theta\left(\mathbf{F}\right) sθ(F) 中学习片段特征,使得正常片段的特征量级(feature magnitude)小于异常片段,我们可以满足这个假设。为了实现这种学习,我们依赖于基于视频 [24] 中 t o p − k top-k top−k 个片段的平均特征量级的优化,定义为
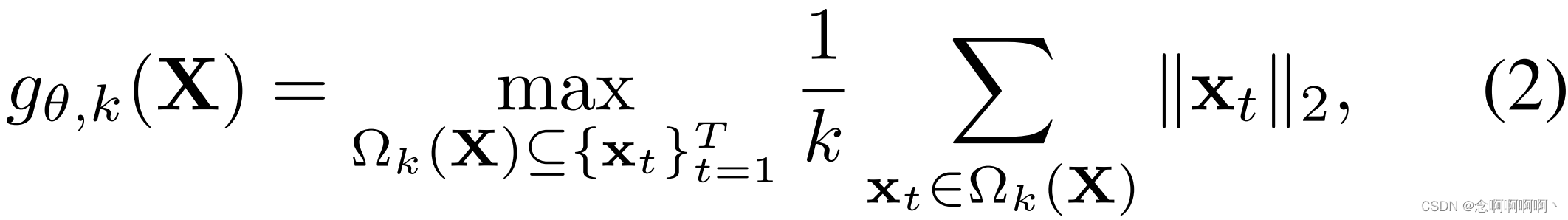
其中
g
θ
,
k
(
.
)
g_{\theta,k}\left(.\right)
gθ,k(.) 由
θ
\theta
θ 参数化以指示其依赖于
s
θ
(
.
)
s_\theta\left(.\right)
sθ(.) 来生成
x
t
\mathbf{x}_t
xt,
Ω
k
(
X
)
\Omega_k\left(\mathbf{X}\right)
Ωk(X) 包含来自
{
x
t
}
t
=
1
T
\left\{\mathbf{x}_t\right\}_{t=1}^T
{xt}t=1T 和
∣
Ω
k
(
X
)
∣
=
k
\left|\Omega_k\left(\mathbf{X}\right)\right|=k
∣Ωk(X)∣=k 的
k
k
k 个片段的子集。异常视频和正常视频之间的可分离性表示为
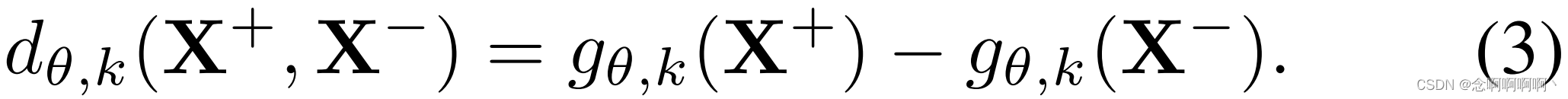
对于下面的定理,我们定义了 Ω k ( X + ) \Omega_k\left(\mathbf{X}^+\right) Ωk(X+) 中的片段异常的概率,其中 p k + ( X + ) = m i n ( μ , k ) k + ϵ , ϵ > 0 p_k^+\left(\mathbf{X}^+\right)=\frac{min\left(\mu,\ k\right)}{k+\epsilon}, \epsilon>0 pk+(X+)=k+ϵmin(μ, k),ϵ>0 ,而来自正常的 Ω k ( X − ) \Omega_k\left(\mathbf{X}^-\right) Ωk(X−), p k + ( X − ) = 0 p_k^+\left(\mathbf{X}^-\right)=0 pk+(X−)=0。这个定义意味着它很可能在 Ω k ( X + ) \Omega_k\left(\mathbf{X}^+\right) Ωk(X+) 的前 k k k 个片段中找到异常片段,只要 k ≤ μ k\le\mu k≤μ。
定理 3.1(异常视频和正常视频之间的预期可分离性)。假设 E [ ∣ ∣ x + ∣ ∣ 2 ] ≥ E [ ∣ ∣ x − ∣ ∣ 2 ] \mathbb{E}\left[||x^+||_2\right]≥\mathbb{E}\left[||x^-||_2\right] E[∣∣x+∣∣2]≥E[∣∣x−∣∣2],其中 X + \mathbf{X}^+ X+ 有 μ \mu μ 个异常样本和 ( T − μ ) (T-\mu) (T−μ) 个正常样本,其中 μ ∈ [ 1 , T ] \mu\in\left[1,\ T\right] μ∈[1, T], X − \mathbf{X}^- X− 有 T T T 个正常样本。令 D θ , k ( . ) D_{\theta,\ k}\left(.\right) Dθ, k(.) 为随机变量,从中得出(3)的可分离性分数 d θ , k ( . ) d_{\theta,\ k}\left(.\right) dθ, k(.) [24]。
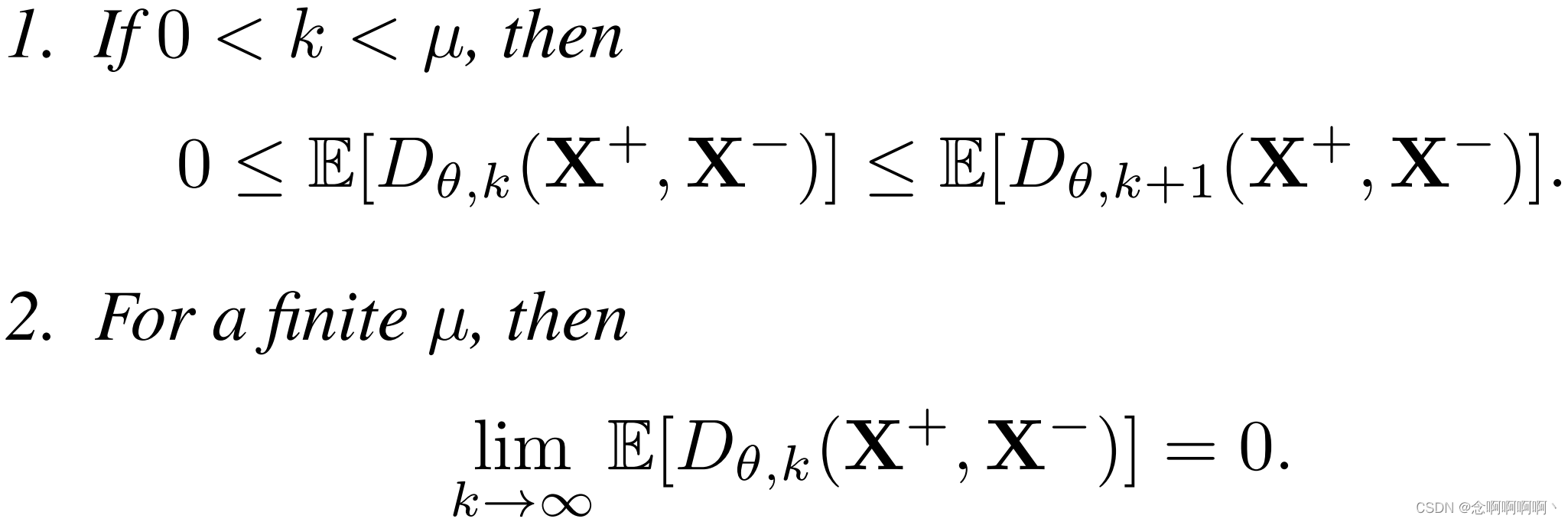
证明。请参阅补充材料中的证明。
因此,该定理的第一部分意味着,当我们在异常视频的 t o p − k top-k top−k 个片段中包含更多样本时,只要 k ≤ μ k\le\mu k≤μ,异常视频与正常视频之间的可分离性往往会增加(即使它包含一些正常样本)。定理的第二部分意味着当我们包含超过 μ \mu μ 个 t o p top top 实例时,异常和正常的视频分数变得难以区分,因为正负包中的负样本数量过多。两个点都显示在图 1 中,其中 s c o r e ( X ) = g θ , k ( X ) score\left(\mathbf{X}\right)=g_{\theta,\ k}\left(\mathbf{X}\right) score(X)=gθ, k(X), ∆ s c o r e ( X + , X − ) = d θ , k ( X + , X − ) ∆score\left(\mathbf{X}^+, \mathbf{X}^-\right)=d_{θ,k}\left(\mathbf{X}^+, \mathbf{X}^-\right) ∆score(X+,X−)=dθ,k(X+,X−),以及 ϵ = 0.4 \epsilon=0.4 ϵ=0.4 来计算 p k + ( X + ) p_k^+\left(\mathbf{X}^+\right) pk+(X+)。该定理表明,通过最大化异常视频和正常视频中前 k k k 个时间特征片段的可分离性(对于 k ≤ μ k\le\mu k≤μ),我们可以促进异常视频和片段的分类。它还表明,使用 t o p − k top-k top−k 特征来训练片段分类器可以进行更有效的训练,因为异常视频中的大多数 t o p − k top-k top−k 样本都是异常的,并且我们将使用 t o p − k top-k top−k 个最难的正常片段进行平衡训练。最后要考虑的是,因为我们只使用每个视频的 t o p − k top-k top−k 个样本,所以我们的方法可以用相对少量的训练样本进行有效优化。
3.2. 多尺度时间特征学习
受视频理解中使用的注意力技术的启发 [25、65],我们提出的多尺度时间网络(MTN)捕获视频片段之间的多分辨率局部时间依赖性和全局时间依赖性(我们在补充材料的图 1 中描述了 MTN)。MTN 在时域上使用扩张卷积金字塔来学习视频片段的多尺度表示。扩张卷积通常应用于空间域,目的是在不损失分辨率的情况下扩大感受野 [69]。在这里,我们建议在时间维度上使用扩张卷积,因为捕获相邻视频片段的多尺度时间依赖性对于异常检测非常重要。
MTN 从预先计算的特征 F = [ f d ] d = 1 D \mathbf{F}=\left[\mathbf{f}_d\right]_{d=1}^D F=[fd]d=1D 中学习多尺度时间特征。然后给定特征 f d ∈ R T \mathbf{f}_d\in\mathbb{R}^T fd∈RT,与内核 W k , d ( l ) ∈ R W \mathbf{W}_{k,\ d}^{\left(l\right)}\in\mathbb{R}^W Wk, d(l)∈RW 的一维扩张卷积运算,其中 k ∈ { 1 , . . . , D / 4 } k\in\left\{1,\ ...,\ D/4\right\} k∈{1, ..., D/4}, d ∈ { 1 , . . . , D } d\in\left\{1,\ ...,\ D\right\} d∈{1, ..., D}, l ∈ { P D C 1 , P D C 2 , P D C 3 } l\in\left\{{\rm PDC}_1,\ {\rm PDC}_2,\ {\rm PDC}_3\right\} l∈{PDC1, PDC2, PDC3}, W W W 表示滤波器尺寸,定义为
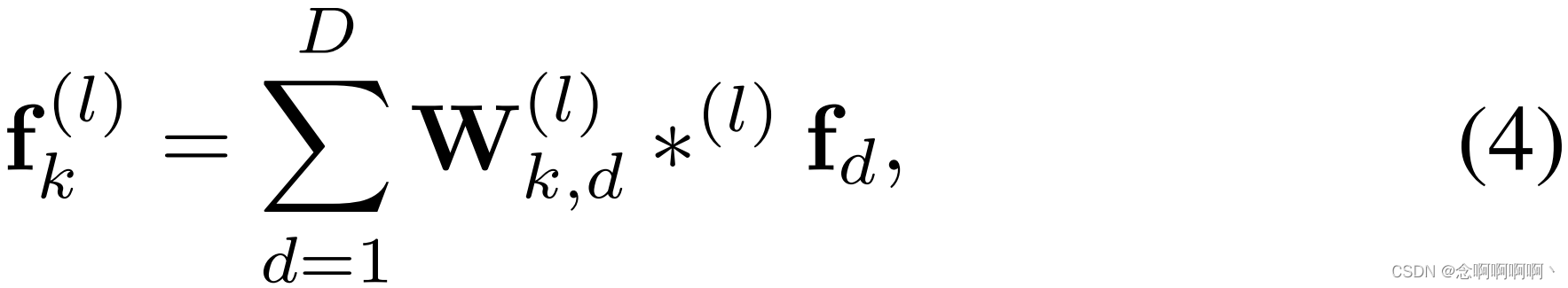
其中 ∗ ( l ) \ast^{\left(l\right)} ∗(l) 表示由 l l l 索引的扩张卷积算子, f k ( l ) ∈ R T \mathbf{f}_k^{\left(l\right)}\in\mathbb{R}^T fk(l)∈RT 表示在时间维度上应用扩张卷积后的输出特征。 { P D C 1 , P D C 2 , P D C 3 } \left\{{\rm PDC}_1,\ {\rm PDC}_2,\ {\rm PDC}_3\right\} {PDC1, PDC2, PDC3} 的膨胀因子分别为 { 1 , 2 , 4 } \left\{1,\ 2,\ 4\right\} {1, 2, 4}(这在补充材料的图 1 中显示)。
视频片段之间的全局时间依赖性是通过自注意力模块实现的,该模块在捕获视频理解 [65]、图像分类 [77] 和对象检测 [44] 的远程空间依赖性方面表现出了良好的性能。受之前使用 GCN 对全局时间信息建模的工作的启发 [66、78],我们重新制定了空间自我注意技术以处理时间维度并捕获全局时间上下文建模。详细来说,我们的目标是生成一个注意力图 M ∈ R T × T M\in\mathbb{R}^{T\times T} M∈RT×T 来估计片段之间的成对相关性。我们的时间自注意力(TSA)模块首先使用 1 × 1 1\times1 1×1 卷积将空间维度从 F ∈ R T × D \mathbf{F}\in\mathbb{R}^{T\times D} F∈RT×D 减少到 F ( c ) ∈ R T × D / 4 \mathbf{F}^{\left({c}\right)}\in\mathbb{R}^{T\times D/4} F(c)∈RT×D/4,其中 F ( c ) = C o n v 1 × 1 ( F ) \mathbf{F}^{\left({c}\right)}={Conv}_{1\times1}\left(\mathbf{F}\right) F(c)=Conv1×1(F)。然后,我们将三个单独的 1 × 1 1\times1 1×1 卷积层应用于 F ( c ) \mathbf{F}^{\left({c}\right)} F(c) 以生成 F ( c 1 ) , F ( c 2 ) , F ( c 3 ) ∈ R T × D / 4 \mathbf{F}^{\left({c1}\right)},\ \mathbf{F}^{\left({c2}\right)},\ \mathbf{F}^{\left({c3}\right)}\in\mathbb{R}^{T\times D/4} F(c1), F(c2), F(c3)∈RT×D/4,如 F ( c i ) = C o n v 1 × 1 ( F ( c ) ) 对于 i ∈ { 1 , 2 , 3 } \mathbf{F}^{\left({ci}\right)}={Conv}_{1\times1}\left(\mathbf{F}^{\left({c}\right)}\right) 对于 i\in\left\{1,\ 2,\ 3\right\} F(ci)=Conv1×1(F(c))对于i∈{1, 2, 3}。然后用 M = ( F ( c 1 ) ) ( F ( c 2 ) ) ⊺ \mathbf{M}=\left(\mathbf{F}^{\left({c1}\right)}\right)\left(\mathbf{F}^{\left({c2}\right)}\right)^\intercal M=(F(c1))(F(c2))⊺,产生 F ( c 4 ) = C o n v 1 × 1 ( M F ( c 3 ) ) \mathbf{F}^{\left({c4}\right)}={Conv}_{1\times1}\left(\boldsymbol{M}\mathbf{F}^{\left({c3}\right)}\right) F(c4)=Conv1×1(MF(c3))。
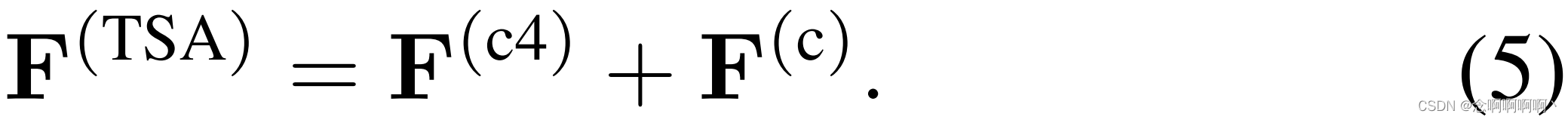
MTN 的输出由 PDC 和 MTN 模块的输出拼接而成 F ˉ = [ F ( l ) ] l ∈ L ∈ R T × D \bar{\mathbf{F}}=\left[\mathbf{F}^{\left(l\right)}\right]_{l\in\mathcal{L}}\in\mathbb{R}^{T\times D} Fˉ=[F(l)]l∈L∈RT×D,其中 L = { P D C 1 , P D C 2 , P D C 3 } \mathcal{L}=\left\{{\rm PDC}_1,\ {\rm PDC}_2,\ {\rm PDC}_3\right\} L={PDC1, PDC2, PDC3}。使用原始特征 F \mathbf{F} F 的跳跃连接产生最终的时间特征表示 X = s θ ( F ) = F ˉ + F \mathbf{X}=s_\theta\left(\mathbf{F}\right)=\bar{\mathbf{F}}+\mathbf{F} X=sθ(F)=Fˉ+F,其中参数 θ \theta θ 包含本节中描述的所有卷积的权重。
3.3. 特征量级学习
使用第 3.1 节中介绍的理论,我们提出了一个损失函数来模拟(1)中的 s θ ( F ) s_\theta\left(\mathbf{F}\right) sθ(F),其中来自正常视频的前 k k k 个最大片段特征量级被最小化并且来自异常视频的前 k k k 个最大片段特征量级被最大化。更具体地说,我们提出了(1)中的以下损失 ℓ s ( . ) \ell_s\left(.\right) ℓs(.),它最大化了正常视频和异常视频之间的可分离性:
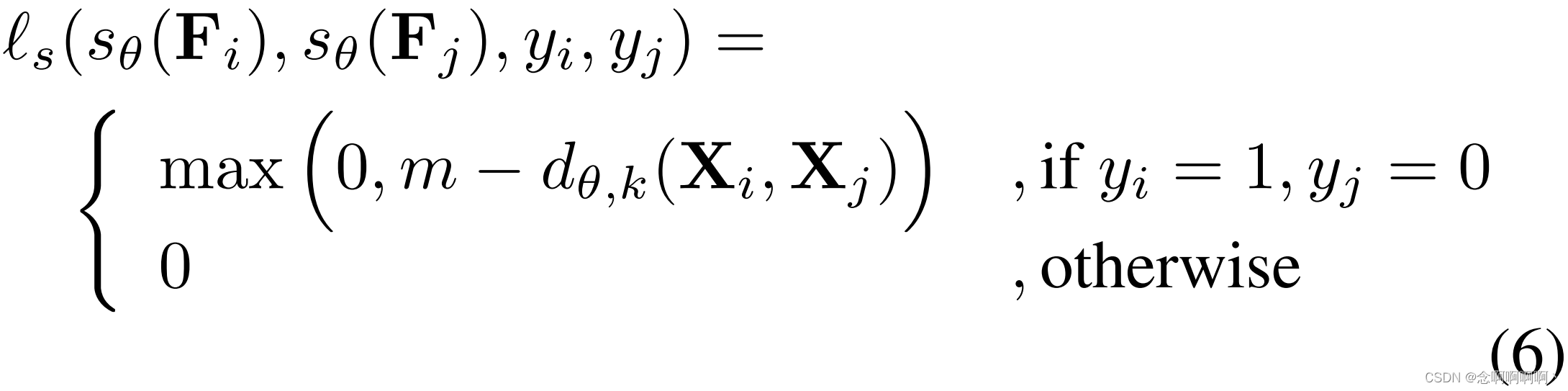
其中 m m m 是预定义的边距, X i = s θ ( F i ) \mathbf{X}_i=s_\theta\left(\mathbf{F}_i\right) Xi=sθ(Fi) 是异常视频特征(对于正常视频的 X j \mathbf{X}_j Xj 类似), d θ , k ( . ) d_{\theta,\ k}\left(.\right) dθ, k(.) 表示(3)中定义的可分离性函数,该函数从(2)中的 g θ , k ( . ) g_{\theta,\ k}\left(.\right) gθ, k(.) 计算异常和正常视频的前 k k k 个实例的得分之差,。
3.4. 支持 RTFM 的片段分类器学习
为了学习片段分类器,我们使用集 Ω k ( X ) \Omega_k\left(\mathbf{X}\right) Ωk(X) 训练一个基于二元交叉熵的分类损失函数,其中包含 k k k 个片段,这些片段具有来自(1)中的 s θ ( F ) s_\theta\left(\mathbf{F}\right) sθ(F) 的最大 ℓ 2 \ell_2 ℓ2 范数特征。特别是,(1)中的损失 ℓ f ( . ) \ell_f\left(.\right) ℓf(.) 定义为
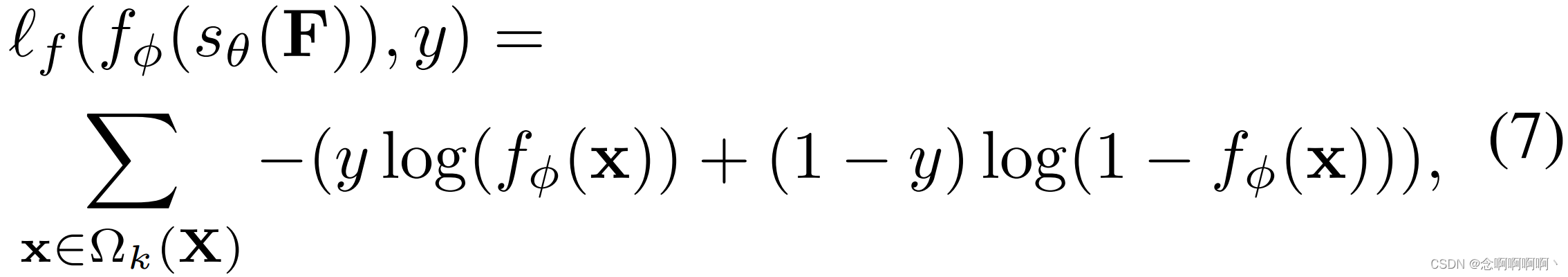
其中
x
=
s
θ
(
F
)
\mathbf{x}=s_\theta\left(\mathbf{F}\right)
x=sθ(F)。请注意,在 [56] 之后,
ℓ
f
(
.
)
\ell_f\left(.\right)
ℓf(.) 伴随着时间平滑度和稀疏性正则化,时间平滑度定义为
(
f
ϕ
(
s
θ
(
f
t
)
)
−
f
ϕ
(
s
θ
(
f
t
−
1
)
)
)
2
\left(f_\phi\left(s_\theta\left(\mathbf{f}_t\right)\right)-f_\phi\left(s_\theta\left(\mathbf{f}_{t-1}\right)\right)\right)^2
(fϕ(sθ(ft))−fϕ(sθ(ft−1)))2 以强制使相邻片段的异常得分相似,而稀疏性正则化定义为
∑
t
=
1
T
∣
f
ϕ
(
s
θ
(
f
t
)
)
∣
\sum_{t=1}^{T}\left|f_\phi\left(s_\theta\left(\mathbf{f}_t\right)\right)\right|
∑t=1T∣fϕ(sθ(ft))∣ 以施加一个先验,即每个异常视频中的异常事件很少见。
4. 实验
4.1. 数据集和评估措施
我们的模型在四个多场景基准数据集上进行评估,这些数据集是为弱监督视频异常检测任务创建的:ShanghaiTech [27]、UCF-Crime [56]、XDViolence [66] 和 UCSD-Peds [68]。
UCF-Crime 是一个大规模异常检测数据集 [56],其中包含来自真实世界街道和室内监控摄像头的 1900 个总时长为 128 小时的未修剪视频。与 ShanghaiTech 的静态背景不同,UCF-Crime 由复杂多样的背景组成。训练集和测试集都包含相同数量的正常和异常视频。该数据集涵盖了 1,610 个带有视频级标签的训练视频和 290 个带有帧级标签的测试视频中的 13 类异常。
XD-Violence 是最近提出的大规模多场景异常检测数据集,从现实生活中的电影、在线视频、体育流媒体、监控摄像头和闭路电视中收集 [66]。该数据集总时长超过 217 小时,包含 4754 个未裁剪的视频,训练集带有视频级标签,测试集带有帧级标签。它是目前最大的公开视频异常检测数据集。
ShanghaiTech 是一个来自固定角度街道视频监控的中等规模数据集。它有 13 个不同的背景场景和 437 个视频,包括 307 个正常视频和 130 个异常视频。原始数据集 [27] 是假设正常训练数据可用的异常检测任务的流行基准。Zhong 等人 [78] 通过选择异常测试视频的子集作为训练数据来重组数据集,构建弱监督训练集,使训练集和测试集都覆盖所有 13 个背景场景。我们使用与 [78] 中完全相同的程序将 ShanghaiTech 转换为弱监督设置。
UCSD-Peds 是一个由两个子数据集组合而成的小规模数据集——Ped1 有 70 个视频,Peds2 有 28 个视频。之前的工作 [16、78] 通过随机选择 6 个异常视频和 4 个正常视频到训练集中,其余的作为测试集,重新制定了用于弱监督异常检测的数据集。我们报告此过程 10 次以上的平均结果。
评估措施。与之前的论文 [14、27、56、62、74] 类似,我们使用 ROC 曲线下的帧级面积(AUC)作为所有数据集的评估指标。此外,在 [66] 之后,我们还使用平均精度(AP)作为 XD-Violence 数据集的评估指标。AUC 和 AP 值越大表示性能越好。最近的一些研究 [12、45] 建议使用基于区域的检测标准(RBDC)和基于轨道的检测标准(TBDC)来补充 AUC 度量,但这两种度量在弱监督环境中不适用。因此,我们专注于 AUC 和 AP 措施。
4.2. 实现细节
按照 [56],每个视频被分成 32 个视频片段,即 T = 32 T=32 T=32。对于所有实验,我们在(6)中设置边距 m = 100 m=100 m=100, k = 3 k=3 k=3。模型(第 3 节)中描述的三个 FC 层具有 512、128 和 1 个节点,其中每个 FC 层后跟一个 ReLU 激活函数和一个 dropout 函数,dropout 率为 0.7。2048D 和 4096D 特征分别从预训练的 I3D [21] 或 C3D [20] 网络的 “mix_5c” 和 “fc_6” 层中提取。在 MTN 中,我们将金字塔扩张率设置为 1、2 和 4,并且我们对每个扩张的卷积分支使用 3×1 Conv1D。对于自注意力块,我们使用 1×1 Conv1D。
我们的 RTFM 方法使用 Adam 优化器 [22] 以端到端的方式进行训练,权重衰减为 0.0005,批量大小为 64,持续 50 个时期。ShanghaiTech 和 UCF-Crime 的学习率设置为 0.001,XD-Violence 的学习率设置为 0.0001。每个小批量包含来自 32 个随机选择的正常和异常视频的样本。该方法是使用 PyTorch [42] 实现的。对于所有基线,我们使用与我们的主干相同的已发布结果。为了公平比较,我们使用与 [56、66、78] 中相同的基准设置。
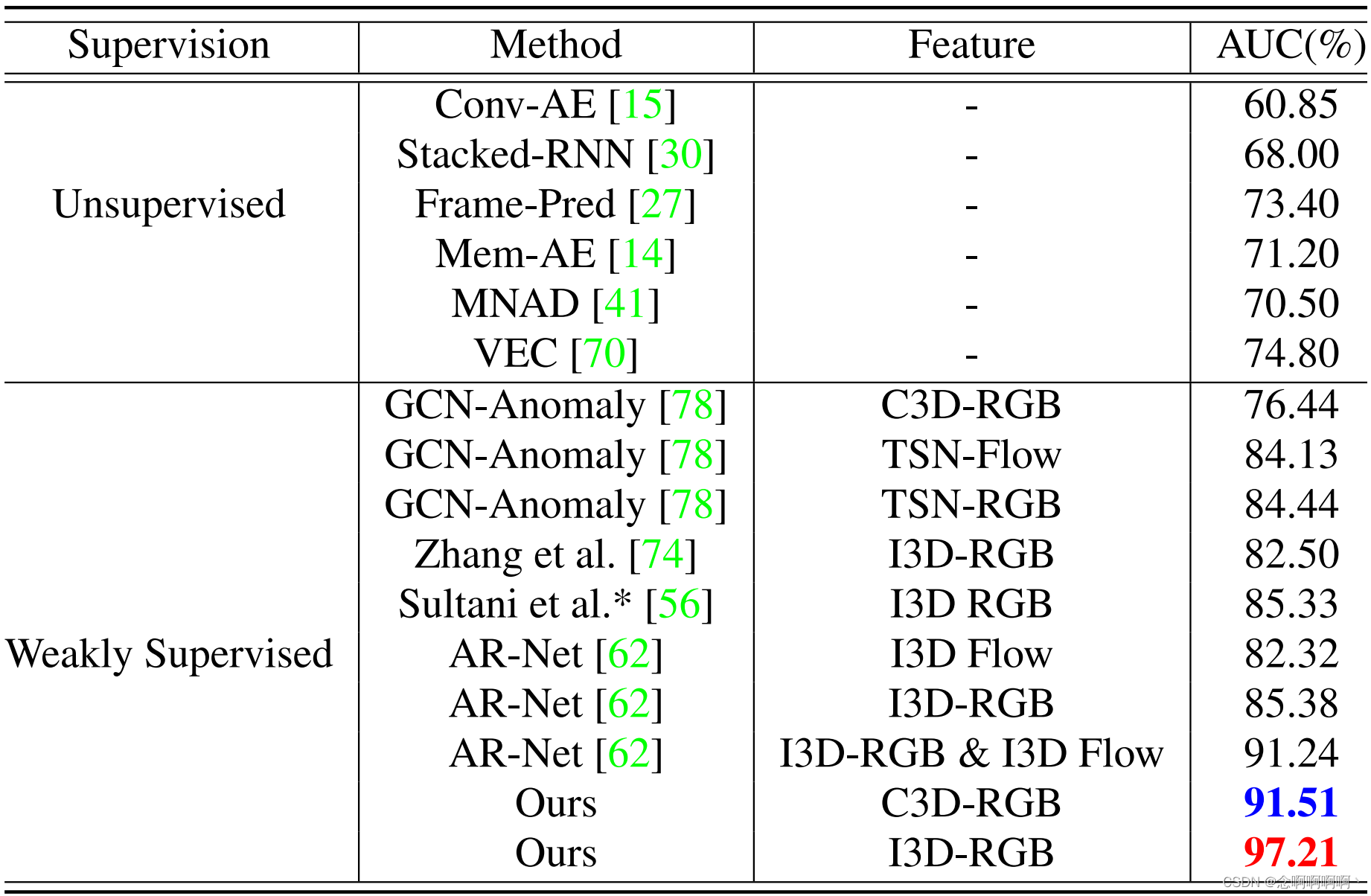
4.3. ShanghaiTech 的结果
ShanghaiTech 的帧级 AUC 结果如表 1 所示。与以前的 SOTA 无监督学习方法 [15、27、30、41、70] 和弱监督方法 [62、74、78] 相比,我们的方法 RTFM 实现了卓越的性能。借助 I3D-RGB 特征,我们的模型在此数据集上获得了最佳 AUC 结果:97.21%。使用相同的 I3D-RGB 功能,我们支持 RTFM 的 MIL 方法优于当前基于 SOTA MIL 的方法 [56、62、74] 10% 到 14%。我们的模型优于 [62] 超过 5%,即使它们依赖于更高级的特征提取器(即 I3D-RGB 和 I3D Flow)。这些结果证明了从我们提出的特征量级学习中获得的成果。
我们的方法也优于基于 GCN 的弱监督方法 [78] 11.7%,这表明我们的 MTN 模块在捕获时间依赖性方面比 GCN 更有效。此外,考虑到 C3D-RGB 特性,我们的模型实现了 91.51% 的 SOTA AUC,大大超过了之前使用 C3D-RGB 的方法。
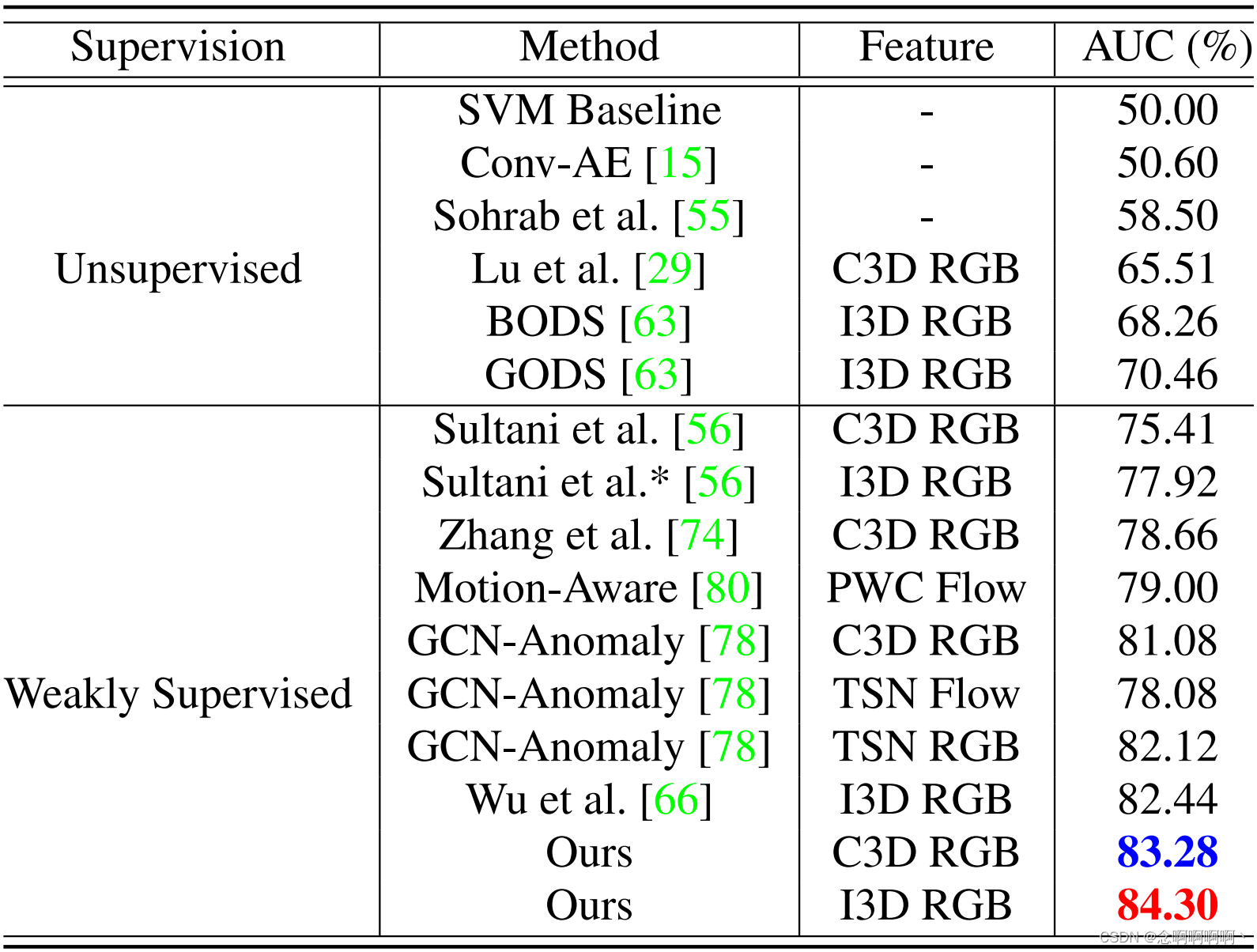
4.4. UCF-Crime 的结果
UCF-Crime 的 AUC 结果显示在表 2 中。我们的方法优于所有以前的无监督学习方法 [15、30、55、63]。值得注意的是,使用相同的 I3D-RGB 特征,我们的方法也优于当前基于 SOTA MIL 的方法,Sultani 等人 [56] 8.62%,Zhang 等人 [74] 5.37%,Zhu 等人 [80] 5.03% 和 Wu 等人 [66] 1.59%。Zhong 等人 [78] 使用计算成本高昂的交替训练方案来实现 82.12% 的 AUC,而我们的方法利用有效的端到端训练方案,比他们的方法高出 1.91%。我们的方法也超过了当前的 SOTA 无监督方法,BODS 和 GODS [63],至少 13%。考虑到 C3D 特征,我们的方法比以前的弱监督方法至少高出 2.95% 和最高 7.87%,表明我们的 RTFM 方法的有效性与骨干网络结构无关。
4.5. XD-Violence 的结果
XD-Violence 是最近发布的数据集,关于它的结果报告很少,如表 3 所示。我们的方法在 AP 中超过所有无监督学习方法至少 27.03%。与 SOTA 弱监督方法 [56、66] 相比,我们的方法使用相同的 I3D 特征比 Wu 等人 [66] 和 Sultani 等人 [56] 好 2.4% 和 2.13%。借助 C3D 功能,与 Sultani 等人 [56] 的 MIL 基线相比,我们的 RTFM 实现了最好的 75.89% AUC。我们方法的一贯优势增强了我们提出的特征幅度学习方法在实现基于 MIL 的异常分类方面的有效性。
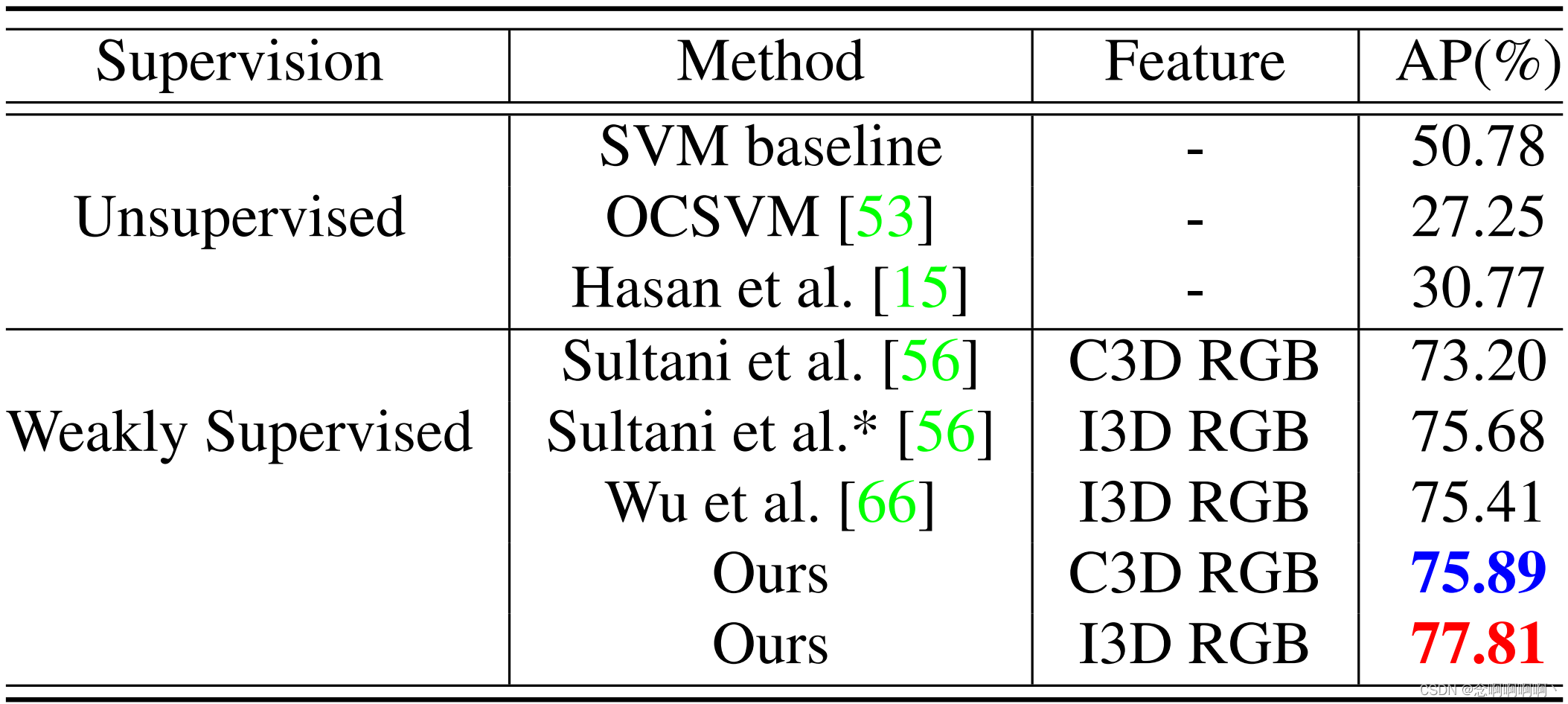
4.6. UCSD-Peds 的结果
我们在 UCSD-Ped2 上分别用 TSN-Gray 和 I3D-RGB 特征显示结果在表 4 中。我们的方法具有相同的 TSN-Gray 特征,比之前的 SOTA [78] 高出 3.2%。最后,我们使用相同的 I3D 功能实现了最好的 98.6% 平均 AUC,超过 Sultani 等人 [56] 6.3%。

4.7. 样本效率分析
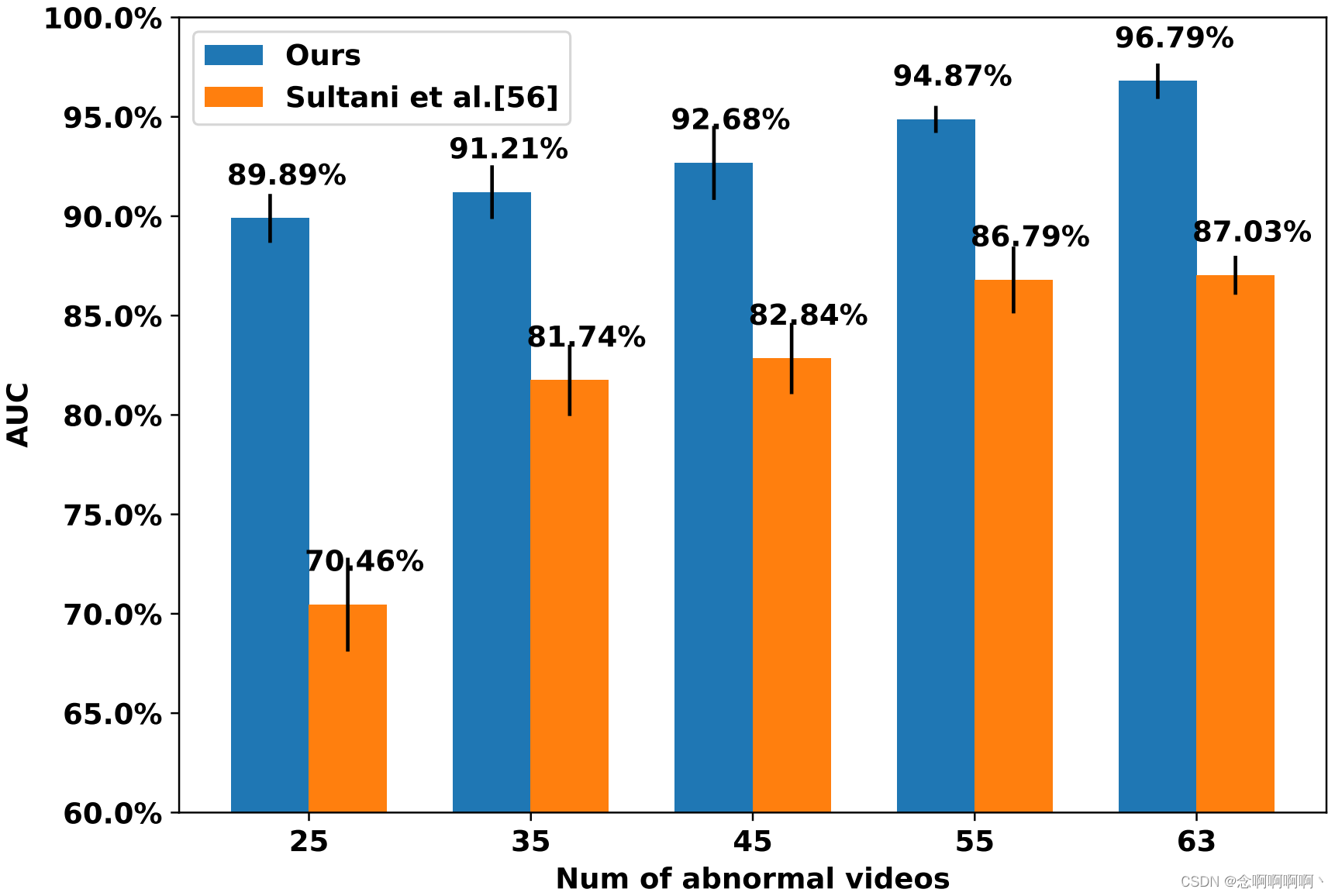
我们通过在 ShanghaiTech 上查看用于训练的异常视频的数量来考察该方法的样本效率 w . r . t w.r.t w.r.t。我们将异常训练视频的数量从原来的 63 个视频减少到 25 个视频,同时固定正常的训练视频和测试数据。[56] 中的 MIL 方法用作基线。为了公平比较,两种方法都使用相同的 I3D 特征,平均 AUC 结果(从使用不同随机种子的三个运行计算得出)如图 4 所示。正如预期的那样,我们的方法和 Sultani 等人的表现 [56] 随着异常训练视频数量的减少而减少,但我们模型的减少率小于 Sultani 等人 [56],表明我们的 RTFM 的鲁棒性。值得注意的是,我们的方法仅使用 25 个异常训练视频比 [56] 使用所有 63 个异常视频高出约 3%,也就是说,尽管我们的方法使用的标记异常训练视频减少了 60%,但它仍然优于 Sultani 等人 [56]。这是因为 RTFM 可以更好地识别异常视频中的正例,因此,它可以比基于 MIL 的方法更有效地利用相同的训练数据 [56]。请注意,我们使用相同的 I3D 特征重新训练 Sultani 等人的方法。
4.8. 细微异常可辨别性
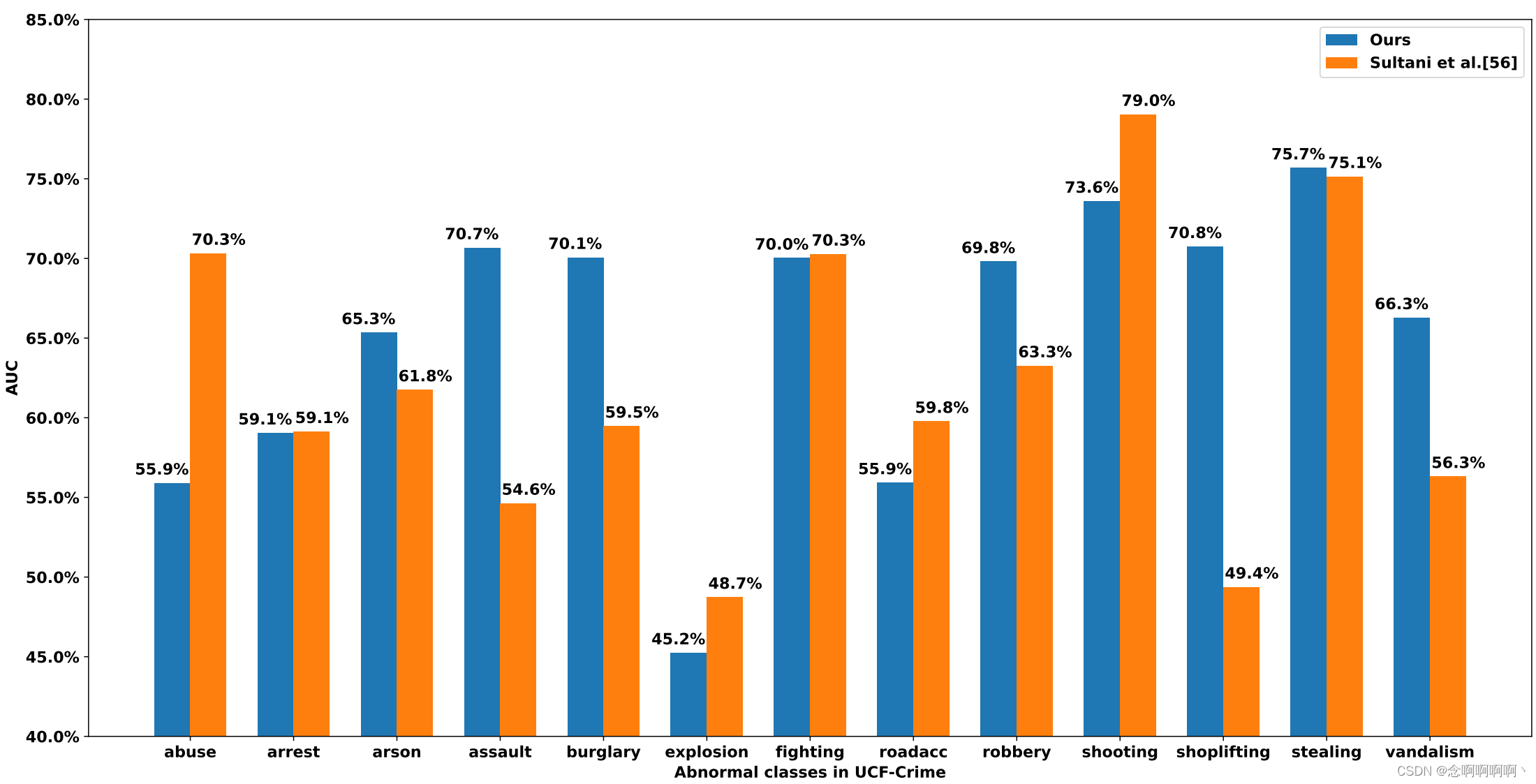
我们还通过研究每个异常类的 AUC 性能来检查我们的方法检测 UCF-Crime 数据集上细微异常事件的能力。这些模型是在完整的训练数据上训练的,我们使用 [56] 作为基线,结果如图 5 所示。我们的模型在以人为中心的异常事件上表现出色,即使异常非常微妙。特别是,我们的 RTFM 方法在 8 个以人为中心的异常类别(即纵火、袭击、入室盗窃、抢劫、枪击、入店行窃、偷窃、故意破坏)中优于 Sultani 等人 [56],显着提高了 AUC 性能 10% 到 15% 在微妙的异常类别中,例如入室盗窃,入店行窃,故意破坏。这种优势得到了 RTFM 的理论结果的支持,RTFM 保证了正例和负例的良好可分离性。对于逮捕、打架、交通事故和爆炸类,我们的方法显示出与 [56] 相比具有竞争力的性能。我们的模型在虐待类别中效果较差,因为该类别在训练数据中包含压倒性的以人为中心的虐待事件,但其测试视频仅包含动物虐待事件。
4.9. 消融研究
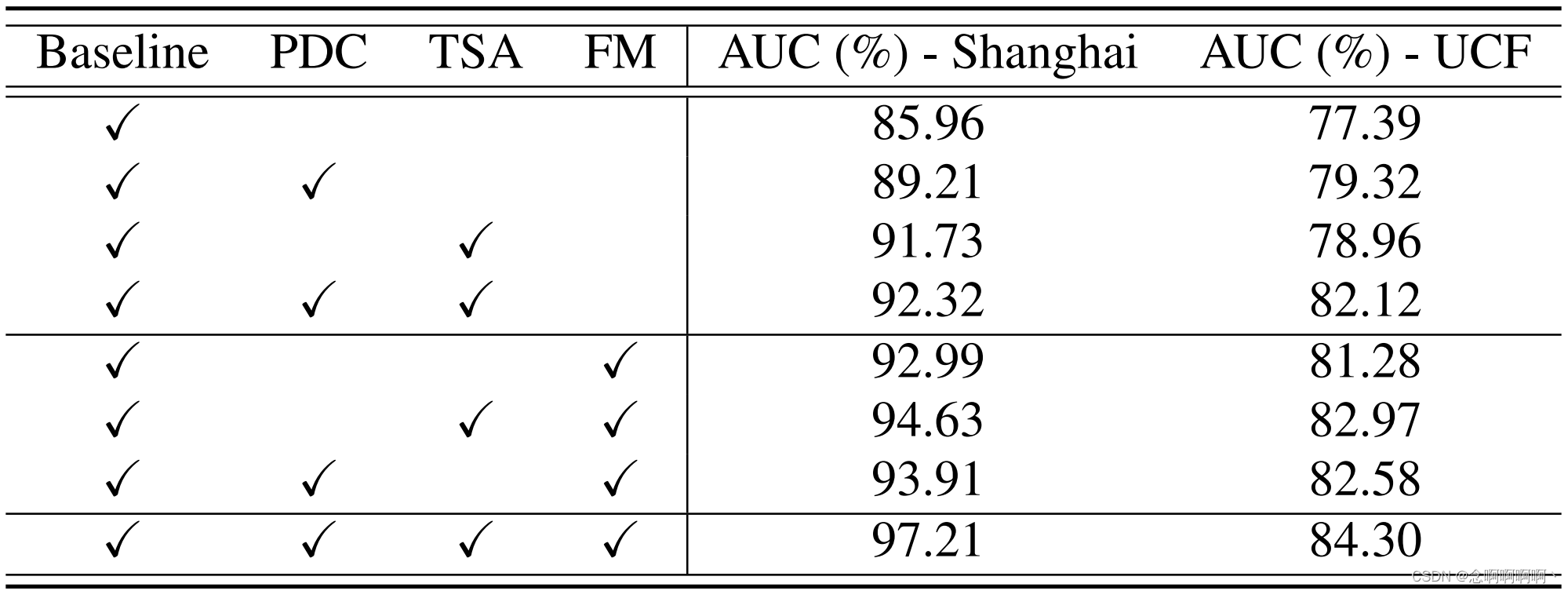
我们利用 I3D 特征对 ShanghaiTech 和 UCF Crime 进行消融研究,如表 5 所示,其中时间特征映射函数 s θ s_\theta sθ 被分解为 PDC 和 TSA,FM 表示从第 3.3 节学习的特征幅度。基线模型用 1×1 卷积层替换 PDC 和 TSA,并使用 [56] 中的原始 MIL 方法进行训练。由此产生的基线在 ShanghaiTech 上仅达到 85.96% AUC,在 UCF Crime 上达到 77.32% AUC(结果与 [56] 中的结果相似)。通过添加 PDC 或 TSA,ShanghaiTech 的 AUC 性能分别提升至 89.21% 和 91.73%,UCF 的 AUC 性能分别提升至 79.32% 和 78.96%。当同时添加 PDC 和 TSA 时,两个数据集的 AUC 结果分别增加到 92.32% 和 82.12%。这表明 PDC 和 TSA 对整体性能有贡献,并且它们在捕获长程和短程时间关系方面也相互补充。当仅将 FM 模块添加到基线时,ShanghaiTech 和 UCF-Crime 的 AUC 分别大幅增加了 7% 和 4% 以上,这表明我们的特征幅度学习比原始 MIL 方法有了很大改进,因为它可以更好地利用标记的异常视频数据。此外,将 PDC 或 TSA 与 FM 相结合有助于进一步提高性能。然后,全模型 RTFM 可以在两个数据集上达到 97.21% 和 84.30% 的最佳性能。RTFM 的理论动机假设是前 k k k 个异常特征片段的平均特征幅度大于正常片段的平均特征幅度。我们测量了 UCF-Crime 的测试视频,异常视频中前 k k k 个片段的平均幅度为 53.4,正常情况下为 7.7。这从经验上表明我们对定理 3.1 的假设是有效的,并且 RTFM 可以有效地最大化正常和异常视频片段之间的可分离性。异常片段的平均分类分数为 0.85,正常片段的平均分类分数为 0.13,进一步证明了这一点。
4.10. 定性分析
在图 3 中,我们显示了我们的 MIL 异常分类器为来自 UCF-Crime 和 ShanghaiTech 的各种测试视频生成的异常分数。使用了来自 UCF-Crime 的三个异常视频和一个正常视频(stealing079、shoplifting028、robbery050 和 normal876)。如 ℓ 2 \ell_2 ℓ2 范数曲线(即橙色曲线)所示,我们的 FM 模块可以有效地为正常片段产生小的特征量级,为异常片段产生大的特征量级。此外,我们的模型可以成功地确保正常和异常片段(即分别为空白和粉红色阴影区域)的异常分数之间有很大的余量。我们的模型还能够检测一个视频中的多个异常事件(例如,stealing079),这使得问题变得更加困难。此外,对于异常事件偷窃和入店行窃,异常是微妙的,几乎看不到视频,但我们的模型仍然可以检测到。我们还展示了我们的模型为 ShanghaiTech 01_0052 和 01_0053 生成的异常分数和特征量级(图 3 中的最后两个数字)。我们的模型可以有效地为这两个场景中车辆进入的异常事件产生较大的异常分数。

5. 结论
我们引入了一种名为 RTFM 的新方法,它支持使用 t o p − k top-k top−k MIL 方法进行弱监督视频异常检测。RTFM 学习时间特征幅度映射函数,该函数:1)从包含许多正常片段的异常视频中检测罕见的异常片段,以及 2)保证正常片段和异常片段之间有较大的间隙(margin)。这在两个主要方面改进了后续的基于 MIL 的异常分类:1)我们启用RTFM的模型学习了更多的判别特征,提高了它从难反例中区分复杂异常(例如,细微异常)的能力;2)它还使 MIL 分类器能够显着改进对异常数据的利用。与当前的 SOTA MIL 方法相比,这两种功能分别导致更好的细微异常可辨别性和采样效率。它们也是我们模型在所有三个大型基准测试中实现 SOTA 性能的两个主要驱动力。
参考文献
[1] Davide Abati, Angelo Porrello, Simone Calderara, and Rita Cucchiara. Latent space autoregression for novelty detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019. 2
[2] Arslan Basharat, Alexei Gritai, and Mubarak Shah. Learning object motion patterns for anomaly detection and improved object detection. In 2008 IEEE Conference on Computer Vision and Pattern Recognition, pages 1–8. IEEE, 2008. 2
[3] Liron Bergman and Yedid Hoshen. Classification-based anomaly detection for general data. arXiv preprint arXiv:2005.02359, 2020. 2
[4] Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Mvtec ad – a comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019. 2
[5] Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020. 2
[6] Philippe Burlina, Neil Joshi, and I-Jeng Wang. Where’s wally now? deep generative and discriminative embeddings for novelty detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019. 2
[7] Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017. 3
[8] Yuanhong Chen, Yu Tian, Guansong Pang, and Gustavo Carneiro. Unsupervised anomaly detection with multiscale interpolated gaussian descriptors. arXiv preprint arXiv:2101.10043, 2021. 2
[9] Kai-Wen Cheng, Yie-Tarng Chen, and Wen-Hsien Fang. Video anomaly detection and localization using hierarchical feature representation and gaussian process regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015. 2
[10] Allison Del Giorno, J Andrew Bagnell, and Martial Hebert. A discriminative framework for anomaly detection in large videos. In European Conference on Computer Vision, pages 334–349. Springer, 2016. 2
[11] Zhiwen Fang, Jiafei Liang, Joey Tianyi Zhou, Yang Xiao, and Feng Yang. Anomaly detection with bidirectional consistency in videos. IEEE Transactions on Neural Networks and Learning Systems, 2020. 2
[12] Mariana-Iuliana Georgescu, Antonio Barbalau, Radu Tudor Ionescu, Fahad Shahbaz Khan, Marius Popescu, and Mubarak Shah. Anomaly detection in video via self-supervised and multi-task learning. arXiv preprint arXiv:2011.07491, 2020. 5
[13] Izhak Golan and Ran El-Yaniv. Deep anomaly detection using geometric transformations. In Advances in Neural Information Processing Systems, pages 9758–9769, 2018. 2
[14] Dong Gong, Lingqiao Liu, Vuong Le, Budhaditya Saha, Moussa Reda Mansour, Svetha Venkatesh, and Anton van den Hengel. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In Proceedings of the IEEE International Conference on Computer Vision, pages 1705–1714, 2019. 2, 5, 6
[15] Mahmudul Hasan, Jonghyun Choi, Jan Neumann, Amit K Roy-Chowdhury, and Larry S Davis. Learning temporal regularity in video sequences. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 733–742, 2016. 1, 6, 7
[16] Chengkun He, Jie Shao, and Jiayu Sun. An anomalyintroduced learning method for abnormal event detection. Multimedia Tools and Applications, 77(22):29573–29588, 2018. 5
[17] Ryota Hinami, Tao Mei, and Shin’ichi Satoh. Joint detection and recounting of abnormal events by learning deep generic knowledge. In Proceedings of the IEEE International Conference on Computer Vision, pages 3619–3627, 2017. 1
[18] Radu Tudor Ionescu, Fahad Shahbaz Khan, Mariana-Iuliana Georgescu, and Ling Shao. Object-centric auto-encoders and dummy anomalies for abnormal event detection in video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7842–7851, 2019. 2
[19] Radu Tudor Ionescu, Sorina Smeureanu, Bogdan Alexe, and Marius Popescu. Unmasking the abnormal events in video. In Proceedings of the IEEE International Conference on Computer Vision, pages 2895–2903, 2017. 2
[20] Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, 2014. 6
[21] Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al The kinetics human action video dataset. arXiv preprint arXiv:1705.06950, 2017. 6
[22] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. 6
[23] Weixin Li, Vijay Mahadevan, and Nuno Vasconcelos. Anomaly detection and localization in crowded scenes. IEEE transactions on pattern analysis and machine intelligence, 36(1):18–32, 2013. 2
[24] Weixin Li and Nuno Vasconcelos. Multiple instance learning for soft bags via top instances. In Proceedings of the ieee conference on computer vision and pattern recognition, pages 4277–4285, 2015. 2, 3
[25] C. Liu, X. Xu, and Y. Zhang. Temporal attention network for action proposal. In 2018 25th IEEE International Conference on Image Processing (ICIP), pages 2281–2285, 2018. 4
[26] Wen Liu, Weixin Luo, Zhengxin Li, Peilin Zhao, Shenghua Gao, et al Margin learning embedded prediction for video anomaly detection with a few anomalies. 2
[27] Wen Liu, Weixin Luo, Dongze Lian, and Shenghua Gao. Future frame prediction for anomaly detection–a new baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6536–6545, 2018. 1, 2, 5, 6
[28] Yuyuan Liu, Yu Tian, Gabriel Maicas, Leonardo Zorron Cheng Tao Pu, Rajvinder Singh, Johan W Verjans, and Gustavo Carneiro. Photoshopping colonoscopy video frames. In 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), pages 1–5. IEEE, 2020. 2
[29] Cewu Lu, Jianping Shi, and Jiaya Jia. Abnormal event detection at 150 fps in matlab. In Proceedings of the IEEE international conference on computer vision, pages 2720–2727, 2013. 6
[30] Weixin Luo, Wen Liu, and Shenghua Gao. A revisit of sparse coding based anomaly detection in stacked rnn framework. In Proceedings of the IEEE International Conference on Computer Vision, pages 341–349, 2017. 1, 2, 6
[31] Amir Markovitz, Gilad Sharir, Itamar Friedman, Lihi ZelnikManor, and Shai Avidan. Graph embedded pose clustering for anomaly detection. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020. 2
[32] Gerard Medioni, Isaac Cohen, Franc¸ois Br ´ emond, Somboon ´ Hongeng, and Ramakant Nevatia. Event detection and analysis from video streams. IEEE Transactions on pattern analysis and machine intelligence, 23(8):873–889, 2001. 2
[33] Romero Morais, Vuong Le, Truyen Tran, Budhaditya Saha, Moussa Mansour, and Svetha Venkatesh. Learning regularity in skeleton trajectories for anomaly detection in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019. 2
[34] Romero Morais, Vuong Le, Truyen Tran, Budhaditya Saha, Moussa Mansour, and Svetha Venkatesh. Learning regularity in skeleton trajectories for anomaly detection in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11996–12004, 2019. 2
[35] Duc Tam Nguyen, Zhongyu Lou, Michael Klar, and Thomas Brox. Anomaly detection with multiple-hypotheses predictions. In International Conference on Machine Learning, pages 4800–4809. PMLR, 2019. 2
[36] Trong-Nguyen Nguyen and Jean Meunier. Anomaly detection in video sequence with appearance-motion correspondence. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019. 2
[37] Guansong Pang, Longbing Cao, Ling Chen, and Huan Liu. Learning representations of ultrahigh-dimensional data for random distance-based outlier detection. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2041–2050, 2018. 2
[38] Guansong Pang, Chunhua Shen, Longbing Cao, and Anton Van Den Hengel. Deep learning for anomaly detection: A review. ACM Computing Surveys, 54(2):1–38, 2021. 2
[39] Guansong Pang, Chunhua Shen, and Anton van den Hengel. Deep anomaly detection with deviation networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 353– 362, 2019. 2
[40] Guansong Pang, Cheng Yan, Chunhua Shen, Anton van den Hengel, and Xiao Bai. Self-trained deep ordinal regression for end-to-end video anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12173–12182, 2020. 2
[41] Hyunjong Park, Jongyoun Noh, and Bumsub Ham. Learning memory-guided normality for anomaly detection. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020. 2, 6
[42] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d Alche-Buc, E. ´ Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc., 2019. 6
[43] Pramuditha Perera, Ramesh Nallapati, and Bing Xiang. Ocgan: One-class novelty detection using gans with constrained latent representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019. 2
[44] Hughes Perreault, Guillaume-Alexandre Bilodeau, Nicolas Saunier, and Maguelonne Heritier. Spotnet: Self-attention ´ multi-task network for object detection. In 2020 17th Conference on Computer and Robot Vision (CRV), pages 230– 237. IEEE, 2020. 4
[45] Bharathkumar Ramachandra, Michael Jones, and Ranga Raju Vatsavai. A survey of single-scene video anomaly detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020. 5
[46] Mahdyar Ravanbakhsh, Moin Nabi, Hossein Mousavi, Enver Sangineto, and Nicu Sebe. Plug-and-play cnn for crowd motion analysis: An application in abnormal event detection. In 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1689–1698. IEEE, 2018. 1
[47] Mahdyar Ravanbakhsh, Moin Nabi, Enver Sangineto, Lucio Marcenaro, Carlo Regazzoni, and Nicu Sebe. Abnormal event detection in videos using generative adversarial nets. In 2017 IEEE International Conference on Image Processing (ICIP), pages 1577–1581. IEEE, 2017. 1
[48] Huamin Ren, Weifeng Liu, Søren Ingvor Olsen, Sergio Escalera, and Thomas B Moeslund. Unsupervised behaviorspecific dictionary learning for abnormal event detection. In BMVC, pages 28–1, 2015. 2
[49] Lukas Ruff, Robert Vandermeulen, Nico Goernitz, Lucas Deecke, Shoaib Ahmed Siddiqui, Alexander Binder, Emmanuel Muller, and Marius Kloft. Deep one-class classifica- ¨ tion. In International conference on machine learning, pages 4393–4402, 2018. 2
[50] Lukas Ruff, Robert A Vandermeulen, Nico Gornitz, Alexan- ¨ der Binder, Emmanuel Muller, Klaus-Robert M ¨ uller, and ¨ Marius Kloft. Deep semi-supervised anomaly detection. arXiv preprint arXiv:1906.02694, 2019. 2
[51] Mohammad Sabokrou, Mohsen Fayyaz, Mahmood Fathy, and Reinhard Klette. Deep-cascade: Cascading 3d deep neural networks for fast anomaly detection and localization in crowded scenes. IEEE Transactions on Image Processing, 26(4):1992–2004, 2017. 2
[52] Mohammad Sabokrou, Mohammad Khalooei, Mahmood Fathy, and Ehsan Adeli. Adversarially learned one-class classifier for novelty detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018. 2
[53] Bernhard Scholkopf, Robert C Williamson, Alex J Smola, ¨ John Shawe-Taylor, and John C Platt. Support vector method for novelty detection. In Advances in neural information processing systems, pages 582–588, 2000. 7
[54] Sorina Smeureanu, Radu Tudor Ionescu, Marius Popescu, and Bogdan Alexe. Deep appearance features for abnormal behavior detection in video. In International Conference on Image Analysis and Processing, pages 779–789. Springer, 2017. 2
[55] Fahad Sohrab, Jenni Raitoharju, Moncef Gabbouj, and Alexandros Iosifidis. Subspace support vector data description. In 2018 24th International Conference on Pattern Recognition (ICPR), pages 722–727. IEEE, 2018. 6
[56] Waqas Sultani, Chen Chen, and Mubarak Shah. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6479–6488, 2018. 1, 2, 3, 5, 6, 7, 8
[57] Li Sun, Yanjun Chen, Wu Luo, Haiyan Wu, and Chongyang Zhang. Discriminative clip mining for video anomaly detection. In 2020 IEEE International Conference on Image Processing (ICIP), pages 2121–2125. IEEE, 2020. 2
[58] Yu Tian, Gabriel Maicas, Leonardo Zorron Cheng Tao Pu, Rajvinder Singh, Johan W Verjans, and Gustavo Carneiro. Few-shot anomaly detection for polyp frames from colonoscopy. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part VI 23, pages 274–284. Springer, 2020. 2
[59] Yu Tian, Guansong Pang, Fengbei Liu, Seon Ho Shin, Johan W Verjans, Rajvinder Singh, Gustavo Carneiro, et al Constrained contrastive distribution learning for unsupervised anomaly detection and localisation in medical images. arXiv preprint arXiv:2103.03423, 2021. 2
[60] Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE international conference on computer vision, pages 4489–4497, 2015. 3
[61] Shashanka Venkataramanan, Kuan-Chuan Peng, Rajat Vikram Singh, and Abhijit Mahalanobis. Attention guided anomaly detection and localization in images. arXiv preprint arXiv:1911.08616, 2019. 2
[62] B. Wan, Y. Fang, X. Xia, and J. Mei. Weakly supervised video anomaly detection via center-guided discriminative learning. In 2020 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6, 2020. 3, 5, 6
[63] Jue Wang and Anoop Cherian. Gods: Generalized one-class discriminative subspaces for anomaly detection. In Proceedings of the IEEE International Conference on Computer Vision, pages 8201–8211, 2019. 2, 6
[64] Jiang Wang, Yang Song, Thomas Leung, Chuck Rosenberg, Jingbin Wang, James Philbin, Bo Chen, and Ying Wu. Learning fine-grained image similarity with deep ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1386–1393, 2014. 2
[65] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7794–7803, 2018. 2, 4
[66] Peng Wu, jing Liu, Yujia Shi, Yujia Sun, Fangtao Shao, Zhaoyang Wu, and Zhiwei Yang. Not only look, but also listen: Learning multimodal violence detection under weak supervision. In European Conference on Computer Vision (ECCV), 2020. 1, 2, 3, 4, 5, 6, 7
[67] Dan Xu, Elisa Ricci, Yan Yan, Jingkuan Song, and Nicu Sebe. Learning deep representations of appearance and motion for anomalous event detection. arXiv preprint arXiv:1510.01553, 2015. 2
[68] Dan Xu, Rui Song, Xinyu Wu, Nannan Li, Wei Feng, and Huihuan Qian. Video anomaly detection based on a hierarchical activity discovery within spatio-temporal contexts. Neurocomputing, 143:144–152, 2014. 5
[69] Fisher Yu and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122, 2015. 2, 4
[70] Guang Yu, Siqi Wang, Zhiping Cai, En Zhu, Chuanfu Xu, Jianping Yin, and Marius Kloft. Cloze test helps: Effective video anomaly detection via learning to complete video events. arXiv preprint arXiv:2008.11988, 2020. 6
[71] Muhammad Zaigham Zaheer, Jin-ha Lee, Marcella Astrid, Arif Mahmood, and Seung-Ik Lee. Cleaning label noise with clusters for minimally supervised anomaly detection. arXiv preprint arXiv:2104.14770, 2021. 2
[72] Muhammad Zaigham Zaheer, Arif Mahmood, Marcella Astrid, and Seung-Ik Lee. Claws: Clustering assisted weakly supervised learning with normalcy suppression for anomalous event detection. In European Conference on Computer Vision, pages 358–376. Springer, 2020. 2
[73] Muhammad Zaigham Zaheer, Arif Mahmood, Hochul Shin, and Seung-Ik Lee. A self-reasoning framework for anomaly detection using video-level labels. IEEE Signal Processing Letters, 27:1705–1709, 2020. 2
[74] J. Zhang, L. Qing, and J. Miao. Temporal convolutional network with complementary inner bag loss for weakly supervised anomaly detection. In 2019 IEEE International Conference on Image Processing (ICIP), pages 4030–4034, 2019. 2, 3, 5, 6
[75] Tianzhu Zhang, Hanqing Lu, and Stan Z Li. Learning semantic scene models by object classification and trajectory clustering. In 2009 IEEE conference on computer vision and pattern recognition, pages 1940–1947. IEEE, 2009. 2
[76] Ying Zhang, Huchuan Lu, Lihe Zhang, Xiang Ruan, and Shun Sakai. Video anomaly detection based on locality sensitive hashing filters. Pattern Recognition, 59:302–311, 2016. 1
[77] Hengshuang Zhao, Jiaya Jia, and Vladlen Koltun. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10076–10085, 2020. 2, 4
[78] Jia-Xing Zhong, Nannan Li, Weijie Kong, Shan Liu, Thomas H Li, and Ge Li. Graph convolutional label noise cleaner: Train a plug-and-play action classifier for anomaly detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1237–1246, 2019. 1, 2, 3, 4, 5, 6, 7
[79] Kang Zhou, Yuting Xiao, Jianlong Yang, Jun Cheng, Wen Liu, Weixin Luo, Zaiwang Gu, Jiang Liu, and Shenghua Gao. Encoding structure-texture relation with p-net for anomaly detection in retinal images. arXiv preprint arXiv:2008.03632, 2020. 2
[80] Yi Zhu and Shawn Newsam. Motion-aware feature for improved video anomaly detection. arXiv preprint arXiv:1907.10211, 2019. 2, 3, 6
[81] Bo Zong, Qi Song, Martin Renqiang Min, Wei Cheng, Cristian Lumezanu, Daeki Cho, and Haifeng Chen. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In International Conference on Learning Representations, 2018. 2


















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









