







 文章详细介绍了torch_geometric库中用于图数据的几种池化操作,包括全局加法池化、全局平均池化、全局最大池化,以及TopKPooling、SAGPooling、EdgePooling、ASAPooling、PANPooling和MemPooling等高级池化方法。这些方法用于从图数据中提取高层特征,对图神经网络模型的性能有重要影响。
文章详细介绍了torch_geometric库中用于图数据的几种池化操作,包括全局加法池化、全局平均池化、全局最大池化,以及TopKPooling、SAGPooling、EdgePooling、ASAPooling、PANPooling和MemPooling等高级池化方法。这些方法用于从图数据中提取高层特征,对图神经网络模型的性能有重要影响。
torch_geometric – Pooling Layers
global_add_pool
通过在节点维度上添加节点特征来返回批量图级输出,因此对于单个图
它的输出由下式计算

from torch_geometric.nn import global_mean_pool, global_max_pool, global_add_pool
import torch as th
f = [[1,2,3,4,5], [6,7,8,9,10], [0,0,1,1,1],[2,2,2,0,0],[3,0,3,0,3]]
batch = [0, 0, 0, 1, 1]
f_t = th.tensor(f)
batch_t = th.tensor(batch)
result_add = global_add_pool(f_t, batch_t)
print(result_add)
-----------------------------------
tensor([[ 7, 9, 12, 14, 16],
[ 5, 2, 5, 0, 3]])
global_mean_pool
通过在节点维度上平均节点特征返回批量图级输出,因此对于单个图
它的输出由下式计算

from torch_geometric.nn import global_mean_pool, global_max_pool, global_add_pool
import torch as th
f = [[1,2,3,4,5], [6,7,8,9,10], [0,0,1,1,1],[2,2,2,0,0],[3,0,3,0,3]]
batch = [0, 0, 0, 1, 1]
f_t = th.tensor(f)
batch_t = th.tensor(batch)
result_mean = global_mean_pool(f_t, batch_t)
print(result_mean)
------------------------------
tensor([[2, 3, 4, 4, 5],
[2, 1, 2, 0, 1]])
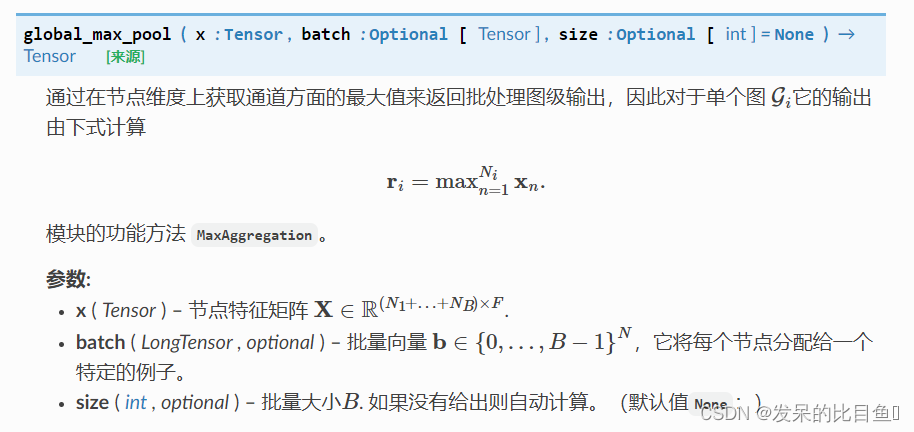
global_max_pool
通过在节点维度上获取通道方面的最大值来返回批处理图级输出,因此对于单个图
它的输出由下式计算
from torch_geometric.nn import global_mean_pool, global_max_pool, global_add_pool
import torch as th
f = [[1,2,3,4,5], [6,7,8,9,10], [0,0,1,1,1],[2,2,2,0,0],[3,0,3,0,3]]
batch = [0, 0, 0, 1, 1]
f_t = th.tensor(f)
batch_t = th.tensor(batch)
result_max = global_max_pool(f_t, batch_t)
print(result_max)
-------------------------------------------
tensor([[ 6, 7, 8, 9, 10],
[ 3, 2, 3, 0, 3]])
TopKPooling
来自“Graph U-Nets”、“Towards Sparse Hierarchical Graph Classifiers”和“Understanding Attention and Generalization in Graph Neural Networks”论文的 pooling operator


from torch_geometric.nn import TopKPooling
import torch as th
f = [[1,2,3,4,5], [6,7,8,9,10], [0,0,1,1,1], [2,2,2,0,0], [3,0,3,0,3]]
edge_index = [[0,1],[2,0],[3,4]]
batch = [0, 0, 0, 1, 1]
edge_index_t = th.tensor(edge_index)
f_t = th.tensor(f)
batch_t = th.tensor(batch)
topkp = TopKPooling(in_channels=5)
reslut = topkp(x = f_t, edge_index=edge_index_t, batch=batch_t)
print(reslut)
------------------------------------------------------------------
(tensor([[5.9999, 6.9998, 7.9998, 8.9998, 9.9998],
[0.9965, 1.9930, 2.9895, 3.9860, 4.9825],
[2.9566, 0.0000, 2.9566, 0.0000, 2.9566]], grad_fn=<MulBackward0>), tensor([[0],
[1]]), None, tensor([0, 0, 1]), tensor([1, 0, 4]), tensor([1.0000, 0.9965, 0.9855], grad_fn=<IndexBackward0>))
SAGPooling
来自“Self-Attention Graph Pooling”和“Understanding Attention and Generalization in Graph Neural Networks”论文的self-attention pooling算子

参数
- in_channels (int) – 每个输入样本的大小
- ratio (float or int) – 图池比率,用于计算k比率,或k本身的值,取决于比率的类型是float还是int。如果min score不是None,则忽略此值。(默认值:0.5)
- GNN (torch.nn.Module, optional) – 用于计算投影分数的图神经网络层(
convc.graphconv,convc.gcnconv,convc.gatconv或convc.sageconv之一)。(默认值:conv.GraphConv) - min_score (float, optional) – 最小节点分数 a ~ \tilde{a} a~用于计算池中节点 i = y i > a ~ i=y_i>\tilde{a} i=yi>a~的索引。当该值不为None时,将忽略ratio参数。(默认值:无)
- multiplier (float, optional) – 池化后特征相乘的系数。这对于大型图形和使用
min_score被使用。(默认值:1) - nonlinearity (str or callable, optional) – 要用到的非线性。(默认:“tanh”)
方法
- reset_parameters()
forward
- x(torch.Tensor) – 节点特征矩阵。
- edge_index (torch.Tensor) – 边索引
- edge_attr (torch.Tensor, optional) – 边缘特征。(默认值:None)
- batch (torch.Tensor, optional) – 批处理向量 b ∈ { 0 , . . . , B − 1 } N b \in \{0,...,B-1\}^N b∈{0,...,B−1}N,它将每个节点分配给一个特定的例子。(默认值:None)
- attn (torch.Tensor, optional) – 可选的节点级矩阵用于计算注意力得分,而不是使用节点特征矩阵 x x x。
class SAGPooling(torch.nn.Module):
def __init__(self, in_channels: int, ratio: Union[float, int] = 0.5,
GNN: Callable = GraphConv, min_score: Optional[float] = None,
multiplier: float = 1.0, nonlinearity: Callable = torch.tanh,
**kwargs):
super().__init__()
self.in_channels = in_channels
self.ratio = ratio
self.gnn = GNN(in_channels, 1, **kwargs)
self.min_score = min_score
self.multiplier = multiplier
self.nonlinearity = nonlinearity
def forward(self, x, edge_index, edge_attr=None, batch=None, attn=None):
""""""
if batch is None:
batch = edge_index.new_zeros(x.size(0))
attn = x if attn is None else attn
attn = attn.unsqueeze(-1) if attn.dim() == 1 else attn
score = self.gnn(attn, edge_index).view(-1)
if self.min_score is None:
score = self.nonlinearity(score)
else:
score = softmax(score, batch)
perm = topk(score, self.ratio, batch, self.min_score)
x = x[perm] * score[perm].view(-1, 1)
x = self.multiplier * x if self.multiplier != 1 else x
batch = batch[perm]
edge_index, edge_attr = filter_adj(edge_index, edge_attr, perm,
num_nodes=score.size(0))
return x, edge_index, edge_attr, batch, perm, score[perm]
from torch_geometric.nn import SAGPooling
import torch as th
f = [[1,2,3,4,5], [6,7,8,9,10], [0,0,1,1,1], [2,2,2,0,0], [3,0,3,0,3]]
edge_index = [[0,1],[2,0],[3,4]]
edge_index_change = [[0, 2, 3],[1, 0, 4]]
batch = [0, 0, 0, 1, 1]
edge_index_t = th.tensor(edge_index)
edge_index_change_t = th.tensor(edge_index_change, dtype=th.long)
f_t = th.tensor(f, dtype=th.float32)
batch_t = th.tensor(batch, dtype=th.long)
# 初始化输入 in_channel
model = SAGPooling(in_channels=5)
result = model(x=f_t, edge_index=edge_index_change_t, batch=batch_t)
print(result)
EdgePooling
“Towards Graph Pooling by Edge Contraction”和“Edge Contraction Pooling for Graph Neural Networks”论文中的边池运算符。
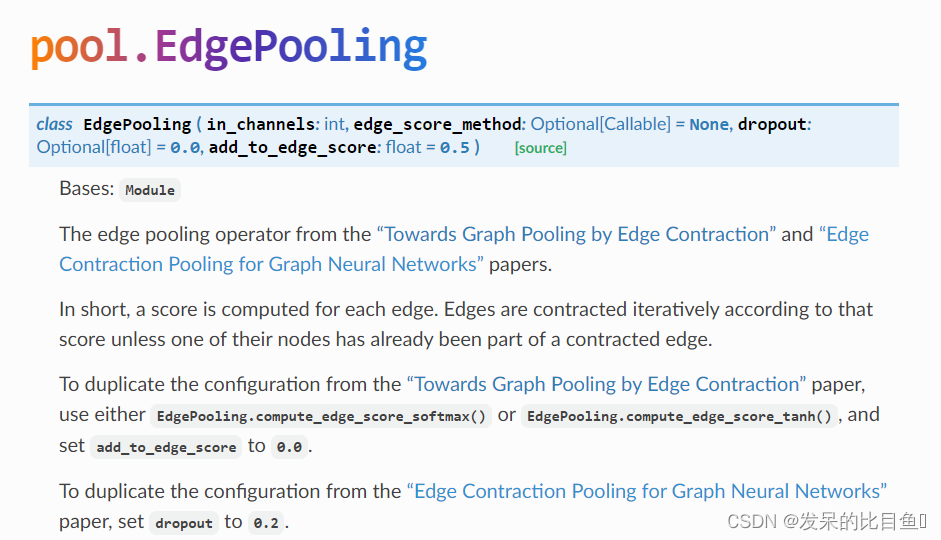
参数
- in_channels (int) – 每个输入样本的大小
- edge_score_method (callable, optional) – 应用于从原始边缘分数计算边缘分数的函数。默认情况下,这是每个节点所有入边的软最大值。这个函数接受一个形状为[num nodes]的原始边缘分数张量,一个边缘索引张量和节点数量为
num_nodes,并生成一个与原始边缘分数相同大小的新张量,用于描述标准化边缘分数。包含的函数有EdgePooling.compute edge score softmax()、EdgePooling.compute edge score tanh()和EdgePooling.compute edge score sigmoid()。(默认值:EdgePooling.compute edge score softmax()) - dropout (float, optional) – 训练期间降低边缘得分的概率。(默认:0.0)
- add_to_edge_score (float, optional) – 要添加到每个计算边缘分数的值。添加这一点极大地帮助了解池的稳定性。(默认值:0.5)
forward
- x (torch.Tensor) – 节点特性。
- edge_index (torch.Tensor) – 边索引
- batch (torch.Tensor, optional) – 批处理向量 b ∈ { 0 , . . . , B − 1 } N b \in \{0,...,B-1\}^N b∈{0,...,B−1}N,它将每个节点分配给一个特定的例子。(默认值:None)
from torch_geometric.nn import EdgePooling
import torch as th
f = [[1,2,3,4,5], [6,7,8,9,10], [0,0,1,1,1], [2,2,2,0,0], [3,0,3,0,3]]
edge_index = [[0,1],[2,0],[3,4]]
edge_index_change = [[0, 2, 3],[1, 0, 4]]
batch = [0, 0, 0, 1, 1]
edge_index_t = th.tensor(edge_index)
edge_index_change_t = th.tensor(edge_index_change, dtype=th.long)
f_t = th.tensor(f, dtype=th.float32)
batch_t = th.tensor(batch, dtype=th.long)
model = EdgePooling(in_channels=5)
x, edge_index, batch, unpool_info = model(x= f_t, edge_index=edge_index_change_t, batch=batch_t)
print(x)
ASAPooling
“ASAP:Adaptive Structure Aware Pooling for Learning Hierarchical Graph Representations”论文中的 Adaptive Structure Aware Pooling 运算符。

参数
- in_channels (int) –
- ratio (float or int) –
- GNN (torch.nn.Module, optional) –
- dropout (float, optional) –
- negative_slope (float, optional) –
- add_self_loops (bool, optional) –
forward
- x (torch.Tensor) –
- edge_index (torch.Tensor) –
- edge_weight (torch.Tensor, optional) –
- batch (torch.Tensor, optional) –
from torch_geometric.nn import ASAPooling
from torch_geometric.nn import GCNConv
import torch as th
f = [[1,2,3,4,5], [6,7,8,9,10], [0,0,1,1,1], [2,2,2,0,0], [3,0,3,0,3]]
edge_index = [[0,1],[2,0],[3,4]]
edge_index_change = [[0, 2, 3],[1, 0, 4]]
batch = [0, 0, 0, 1, 1]
edge_index_t = th.tensor(edge_index)
edge_index_change_t = th.tensor(edge_index_change, dtype=th.long)
f_t = th.tensor(f, dtype=th.float32)
batch_t = th.tensor(batch, dtype=th.long)
model = ASAPooling(in_channels=5, GNN=GCNConv)
x, edge_index, edge_weight, batch, perm = model(x=f_t, edge_index=edge_index_change_t)
print(x)
PANPooling
“Path Integral Based Convolution and Pooling for Graph Neural Networks”论文中的基于路径积分的池化算子。
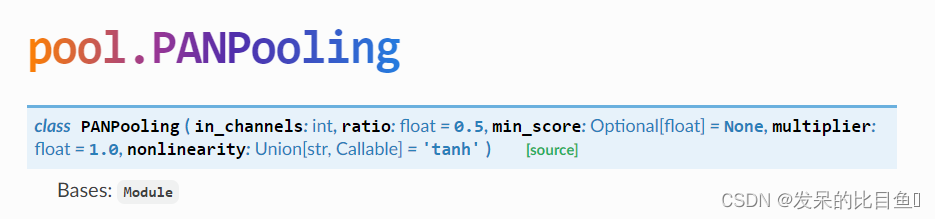
参数
- in_channels (int) –
- ratio (float) –
- min_score (float, optional) –
- multiplier (float, optional) – 池化后特征相乘的系数。这对于大型图表和使用
min_score非常有用。 - nonlinearity (str or callable, optional) –
forward
- x (torch.Tensor) –
- M (SparseTensor) – MET矩阵
- batch (torch.Tensor, optional) –
from torch_geometric.nn import PANPooling
import torch as th
from torch_sparse import SparseTensor
model = PANPooling(in_channels=5)
f = [[1,2,3,4,5], [6,7,8,9,10], [0,0,1,1,1], [2,2,2,0,0], [3,0,3,0,3]]
edge_index = [[0,1],[2,0],[3,4]]
edge_index_change = [[0, 2, 3],[1, 0, 4]]
batch = [0, 0, 0, 1, 1]
edge_index_t = th.tensor(edge_index)
edge_index_change_t = th.tensor(edge_index_change, dtype=th.long)
f_t = th.tensor(f, dtype=th.float32)
batch_t = th.tensor(batch, dtype=th.long)
edge_attr = th.tensor([1, 2, 3]) # 其实就是权重
M = SparseTensor.from_edge_index(edge_index=edge_index_change_t, edge_attr=edge_attr)
x, edge_index, edge_attr, batch, perm, score = model(f_t, M)
print(x)
MemPooling
来自“Memory-Based Graph Networks”论文的基于内存的池化层,它学习基于软聚类分配的粗化图表示
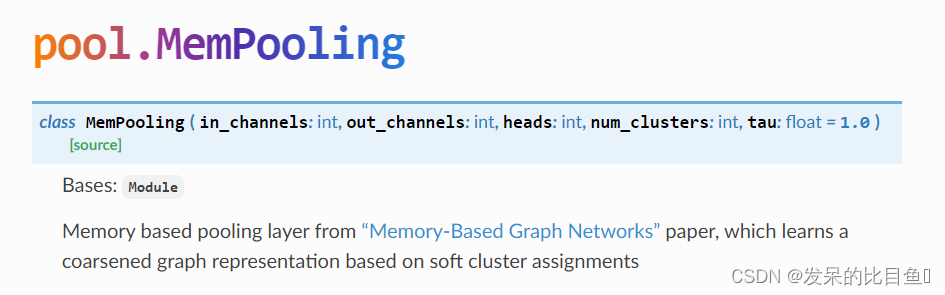
参数
- in_channels (int) –
- out_channels (int) –
- heads (int) – 头
- num_clusters (int) – 簇
- tau (int, optional) – 温度
forward
- x (torch.Tensor) –
- batch (torch.Tensor, optional) –
- mask (torch.Tensor, optional) –
from torch_geometric.nn import MemPooling
import torch as th
x = th.randn(5,6,6)
# batch = th.tensor([0, 0, 0, 1, 1])
model = MemPooling(in_channels=6, out_channels=3, heads=2, num_clusters=2, tau=0.5)
result = model(x)
print(result)
## -------------------------
x = th.randn(2,6,6)
batch = th.tensor([0, 0, 0, 1, 1])
result = model(x, batch=batch)
print(result)
max_pool
torch_geometric.data.Data根据 中定义的聚类,汇集并粗化对象给出的图cluster。

- cluster (torch.Tensor) – The cluster vector c ∈ { 0 , . . . , N − 1 } N c \in \{0,...,N-1\}^N c∈{0,...,N−1}N, which assigns each node to a specific cluster.
- data (Data) – Graph data object.
- transform (callable, optional) – A function/transform that takes in the coarsened and pooled Data object and returns a transformed version. (default: None)
avg_pool
torch_geometric.data.Data根据 中定义的聚类,汇集并粗化对象给出的图cluster。
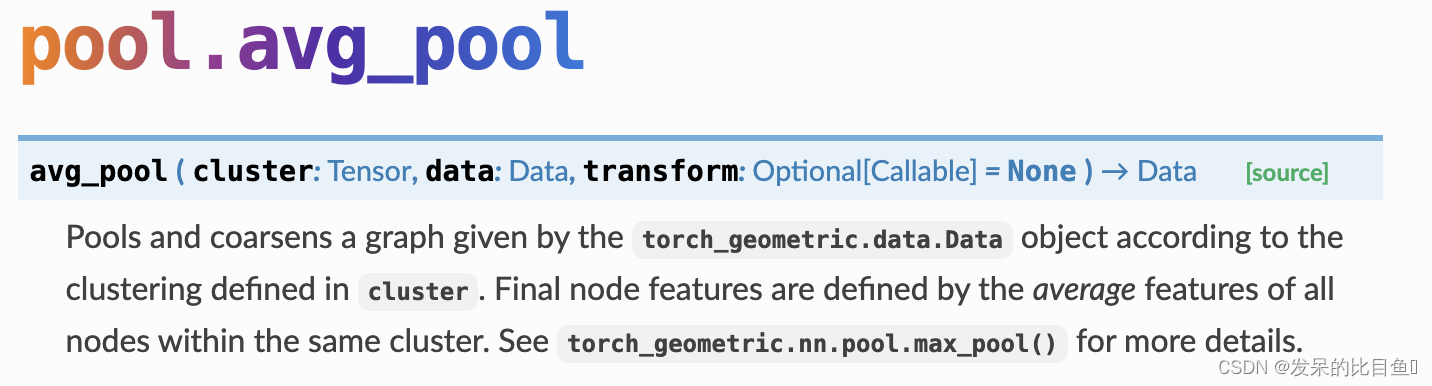
- cluster (torch.Tensor) – The cluster vector c ∈ { 0 , . . . , N − 1 } N c \in \{0,...,N-1\}^N c∈{0,...,N−1}N, which assigns each node to a specific cluster.
- data (Data) – Graph data object.
- transform (callable, optional) – A function/transform that takes in the coarsened and pooled Data object and returns a transformed version. (default: None)
max_pool_x
Max-Pools 节点特征根据中定义的聚类cluster。
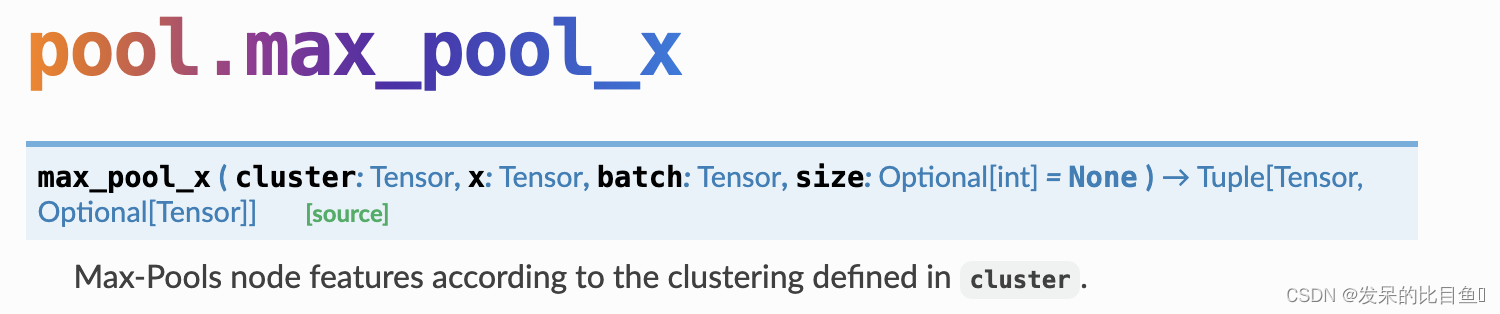
- cluster (torch.Tensor) – The cluster vector c ∈ { 0 , . . . , N − 1 } N c \in \{0,...,N-1\}^N c∈{0,...,N−1}N, which assigns each node to a specific cluster.
- x (Tensor) – The node feature matrix.
- batch (torch.Tensor) – The batch vector b ∈ { 0 , . . . , B − 1 } N b \in \{0,...,B-1\}^N b∈{0,...,B−1}N, which assigns each node to a specific example.
- size (int, optional) – The maximum number of clusters in a single example. This property is useful to obtain a batch-wise dense representation, e.g. for applying FC layers, but should only be used if the size of the maximum number of clusters per example is known in advance. (default: None)
max_pool_neighbor_x
最大池化相邻节点特征,其中每个特征data.x都被中心节点及其邻居中具有最大值的特征值替换。

avg_pool_x
平均池节点特征根据中定义的聚类cluster。

- cluster (torch.Tensor) – The cluster vector c ∈ { 0 , . . . , N − 1 } N c \in \{0,...,N-1\}^N c∈{0,...,N−1}N, which assigns each node to a specific cluster.
- x (Tensor) – The node feature matrix. batch (torch.Tensor) – The batch vector b ∈ { 0 , . . . , B − 1 } N b \in \{0,...,B-1\}^N b∈{0,...,B−1}N, which assigns each node to a specific example.
- size (int, optional) – The maximum number of clusters in a single example. (default: None)
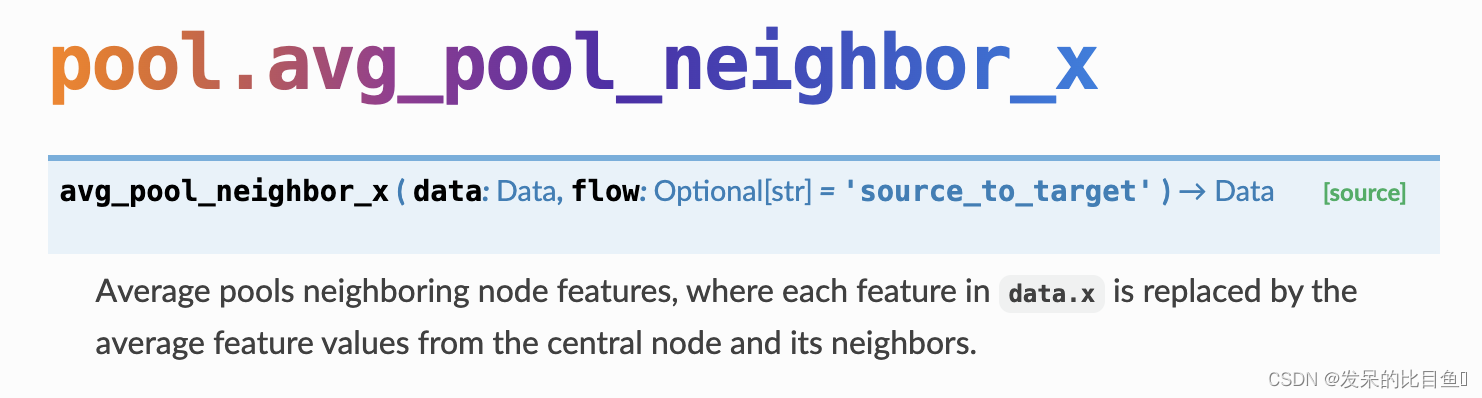
avg_pool_neighbor_x
平均汇集相邻节点特征,其中每个特征data.x都被中心节点及其邻居的平均特征值替换。
graclus
来自“没有特征向量的加权图切割:多级方法”论文中的一种贪婪聚类算法,该算法选择一个未标记的顶点并将其与其未标记的邻居之一匹配(最大化其边缘权重)。

- edge_index (torch.Tensor) – The edge indices.
- weight (torch.Tensor, optional) – One-dimensional edge weights. (default: None)
- num_nodes (int, optional) – The number of nodes, i.e. max_val + 1 of edge_index. (default: None)
voxel_grid
来自Graphs论文 Dynamic Edge-Conditioned Filters in Convolutional Networks on Graphs,它在点云上覆盖用户定义大小的规则网格,并将所有点聚集在同一体素内。

- pos (torch.Tensor) – Node position matrix X ∈ R { N 1 + . . . + N B } × N X \in R^{\{N_1+...+N_B\}\times N} X∈R{N1+...+NB}×N.
- size (float or [float] or Tensor) – Size of a voxel (in each dimension).
- batch (torch.Tensor, optional) – Batch vector b ∈ { 0 , . . , B − 1 } N b \in \{0,..,B-1\}^N b∈{0,..,B−1}N, which assigns each node to a specific example. (default: None)
- start (float or [float] or Tensor, optional) – Start coordinates of the grid (in each dimension). If set to None, will be set to the minimum coordinates found in pos. (default: None)
- end (float or [float] or Tensor, optional) – End coordinates of the grid (in each dimension). If set to None, will be set to the maximum coordinates found in pos. (default: None)
fps
“PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space”论文中的一种采样算法,该算法针对其余点迭代采样最远的点。

- x (torch.Tensor) – Node feature matrix X ∈ R N × F X \in R^{N \times F} X∈RN×F.
- batch (torch.Tensor, optional) – Batch vector b ∈ { 0 , b − 1 } N b \in \{0, b-1\}^N b∈{0,b−1}N, which assigns each node to a specific example. (default: None)
- ratio (float, optional) – Sampling ratio. (default: 0.5)
- random_start (bool, optional) – If set to False, use the first node in X X X as starting node. (default: obj:True)
import torch
from torch_geometric.nn import fps
x = torch.Tensor([[-1, -1], [-1, 1], [1, -1], [1, 1]])
batch = torch.tensor([0, 0, 0, 0])
index = fps(x, batch, ratio=0.5)
knn
求y中的每个元素在x中的k个最近点。
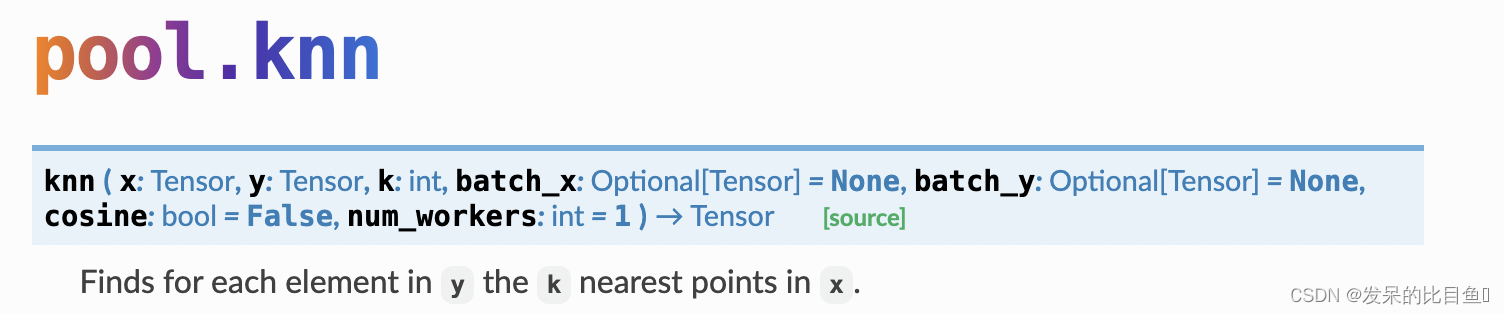
参数
- x (torch.Tensor) – Node feature matrix X ∈ R N × F X \in R^{N \times F} X∈RN×F.
- y (torch.Tensor) – Node feature matrix X ∈ R N × F X \in R^{N \times F} X∈RN×F.
- k (int) – The number of neighbors.
- batch_x (torch.Tensor, optional) – Batch vector b ∈ { 0 , . . . B − 1 } N b \in \{0,...B-1\}^N b∈{0,...B−1}N, which assigns each node to a specific example. (default: None)
- batch_y (torch.Tensor, optional) – Batch vector b ∈ { 0 , . . . B − 1 } N b \in \{0,...B-1\}^N b∈{0,...B−1}N, which assigns each node to a specific example. (default: None)
- cosine (bool, optional) – If True, will use the cosine distance instead of euclidean distance to find nearest neighbors. (default: False)
- num_workers (int, optional) – Number of workers to use for computation. Has no effect in case batch_x or batch_y is not None, or the input lies on the GPU. (default: 1)
import torch
from torch_geometric.nn import knn
x = torch.Tensor([[-1, -1], [-1, 1], [1, -1], [1, 1]])
batch_x = torch.tensor([0, 0, 0, 0])
y = torch.Tensor([[-1, 0], [1, 0]])
batch_y = torch.tensor([0, 0])
assign_index = knn(x, y, 2, batch_x, batch_y)
print(assign_index)
knn_graph
计算图边最近的k个点。

- x (torch.Tensor) – Node feature matrix X ∈ R N × F X \in R^{N \times F} X∈RN×F.
- k (int) – The number of neighbors.
- batch (torch.Tensor, optional) – Batch vector b ∈ { 0 , . . . B − 1 } N b \in \{0,...B-1\}^N b∈{0,...B−1}N, which assigns each node to a specific example. (default: None)
- loop (bool, optional) – If True, the graph will contain self-loops. (default: False)
- flow (str, optional) – The flow direction when using in combination with message passing (“source_to_target” or “target_to_source”). (default: “source_to_target”)
- cosine (bool, optional) – If True, will use the cosine distance instead of euclidean distance to find nearest neighbors. (default: False)
- num_workers (int, optional) – Number of workers to use for computation. Has no effect in case batch is not None, or the input lies on the GPU. (default: 1)
radius
求出y中的每个元素在距离r内x中的所有点。

- x (torch.Tensor) – Node feature matrix
- y (torch.Tensor) – Node feature matrix
- r (float) – The radius.
- batch_x (torch.Tensor, optional) – Batch vector , which assigns each node to a specific example. (default: None)
- batch_y (torch.Tensor, optional) – Batch vector, which assigns each node to a specific example. (default: None)
- max_num_neighbors (int, optional) – The maximum number of neighbors to return for each element in y. (default: 32)
- num_workers (int, optional) – Number of workers to use for computation. Has no effect in case batch_x or batch_y is not None, or the input lies on the GPU. (default: 1)
import torch
from torch_geometric.nn import radius
x = torch.Tensor([[-1, -1], [-1, 1], [1, -1], [1, 1]])
batch_x = torch.tensor([0, 0, 0, 0])
y = torch.Tensor([[-1, 0], [1, 0]])
batch_y = torch.tensor([0, 0])
assign_index = radius(x, y, 1.5, batch_x, batch_y)
print(assign_index)
radius_graph
计算给定距离内所有点的图边。

PARAMETERS
- x (torch.Tensor) – Node feature matrix .
- r (float) – The radius.
- batch (torch.Tensor, optional) – Batch vector , which assigns each node to a specific example. (default: None)
- loop (bool, optional) – If True, the graph will contain self-loops. (default: False)
- max_num_neighbors (int, optional) – The maximum number of neighbors to return for each element in y. (default: 32)
- flow (str, optional) – The flow direction when using in combination with message passing (“source_to_target” or “target_to_source”). (default: “source_to_target”)
- num_workers (int, optional) – Number of workers to use for computation. Has no effect in case batch is not None, or the input lies on the GPU. (default: 1)
import torch
from torch_geometric.nn import radius_graph
x = torch.Tensor([[-1, -1], [-1, 1], [1, -1], [1, 0]])
batch = torch.tensor([0, 0, 0, 0])
edge_index = radius_graph(x, r=1.5, batch=batch, loop=False)
print(edge_index)
nearest
在y中的每个元素找出在x中最近的k个点。
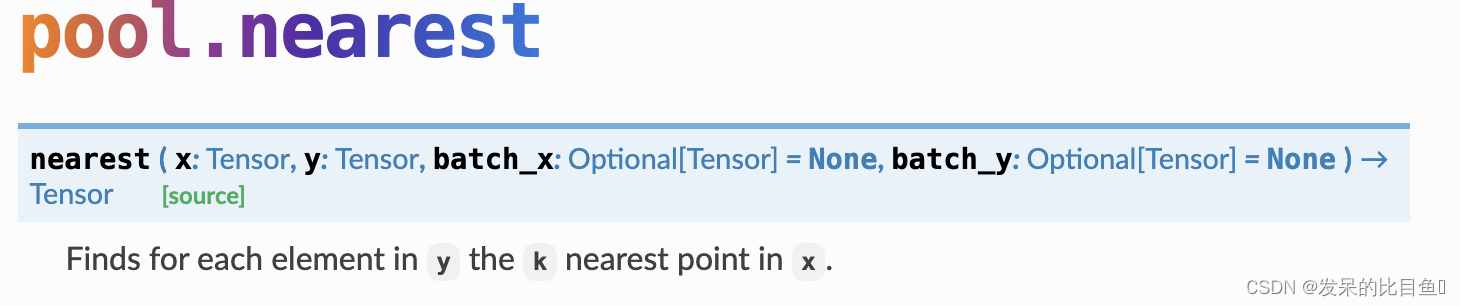
- x (torch.Tensor) – Node feature matrix
- y (torch.Tensor) – Node feature matrix
- batch_x (torch.Tensor, optional) – Batch vector, which assigns each node to a specific example. (default: None)
- batch_y (torch.Tensor, optional) – Batch vector , which assigns each node to a specific example. (default: None)
import torch
from torch_geometric.nn import nearest
x = torch.Tensor([[-1, -1], [-1, 1], [1, -1], [1, 1]])
batch_x = torch.tensor([0, 0, 0, 0])
y = torch.Tensor([[-1, 0], [1, 0]])
batch_y = torch.tensor([0, 0])
cluster = nearest(x, y, batch_x, batch_y)
print(cluster)


















 2195
2195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











