







 本文介绍了PyTorch中的UtilityAPI,包括类型提升逻辑、确定性算法的启用与检查,以及矩阵乘法精度的设置。同时,重点讨论了vmap功能,它是用于向量化操作的强大工具,可用于批处理和高阶导数计算,简化模型创建和优化计算。
本文介绍了PyTorch中的UtilityAPI,包括类型提升逻辑、确定性算法的启用与检查,以及矩阵乘法精度的设置。同时,重点讨论了vmap功能,它是用于向量化操作的强大工具,可用于批处理和高阶导数计算,简化模型创建和优化计算。
小白学Pytorch系列–Torch API (12)

Utilities
compiled_with_cxx11_abi
返回PyTorch是否使用compiled_with_cxx11_abi=1构建
result_type
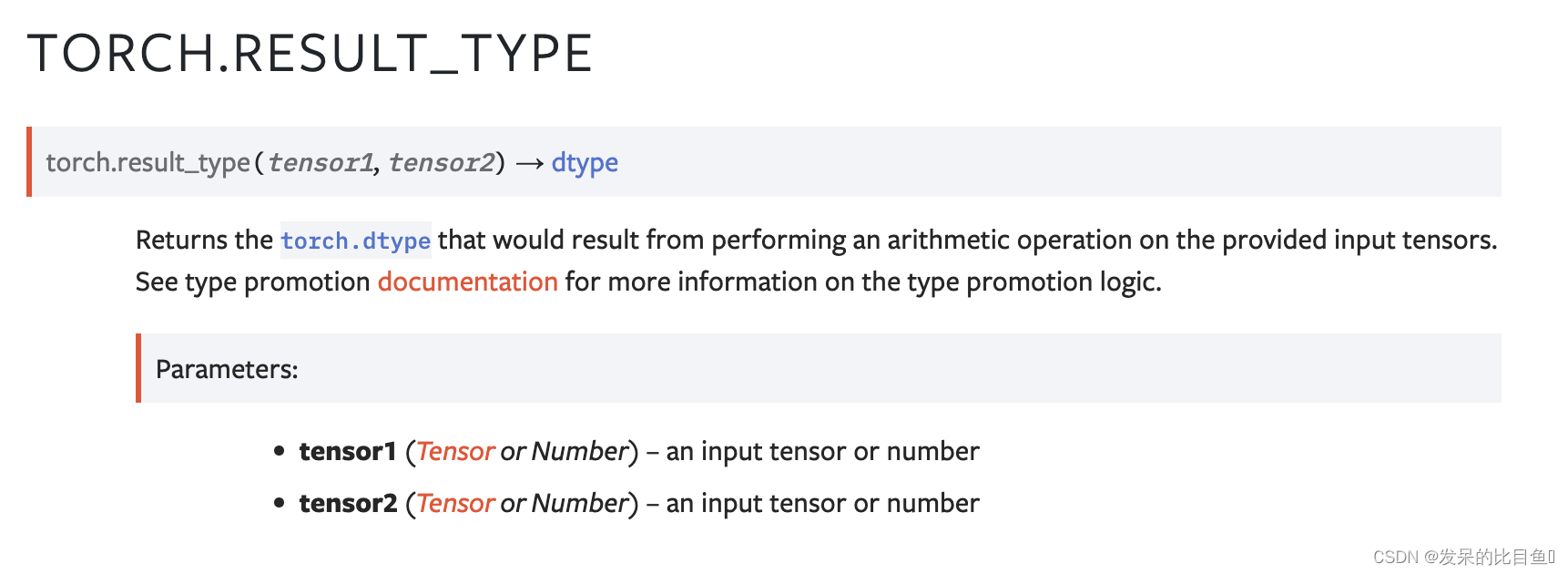
返回对提供的输入张量执行算术运算所产生的torch.dtype。有关类型提升逻辑的更多信息,请参阅类型提升文档。
>>> torch.result_type(torch.tensor([1, 2], dtype=torch.int), 1.0)
torch.float32
>>> torch.result_type(torch.tensor([1, 2], dtype=torch.uint8), torch.tensor(1))
torch.uint8
can_cast
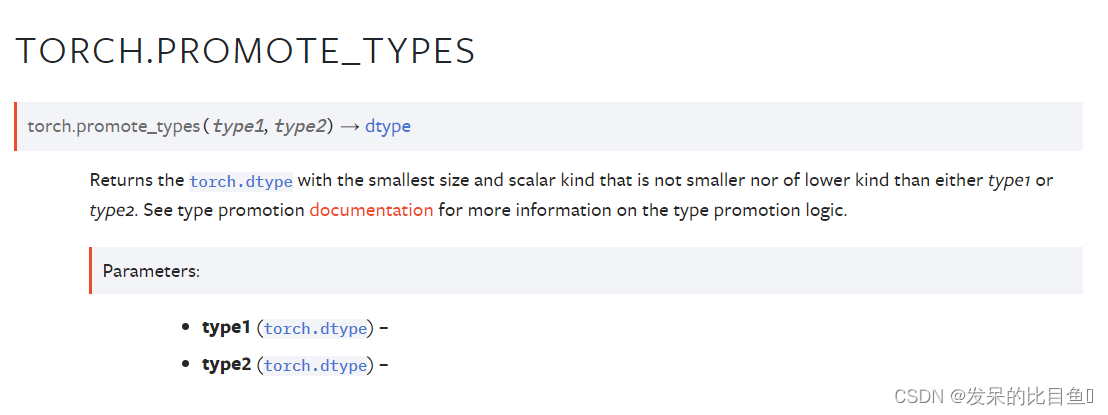
promote_types
返回具有最小大小和标量类型的torch.dtype,该类型既不小于type1也不低于type2。有关类型提升逻辑的更多信息,请参阅类型提升文档。
>>> torch.promote_types(torch.int32, torch.float32)
torch.float32
>>> torch.promote_types(torch.uint8, torch.long)
torch.long
use_deterministic_algorithms
设置PyTorch操作是否必须使用“确定性”算法。也就是说,在给定相同输入的情况下,当在相同的软件和硬件上运行时,算法总是产生相同的输出。启用后,操作将在可用时使用确定性算法,如果只有不确定性算法可用,则在调用时会抛出RuntimeError。

>>> torch.use_deterministic_algorithms(True)
# Forward mode nondeterministic error
>>> torch.randn(10, device='cuda').kthvalue(0)
...
RuntimeError: kthvalue CUDA does not have a deterministic implementation...
# Backward mode nondeterministic error
>>> torch.nn.AvgPool3d(1)(torch.randn(3, 4, 5, 6, requires_grad=True).cuda()).sum().backward()
...
RuntimeError: avg_pool3d_backward_cuda does not have a deterministic implementation...
are_deterministic_algorithms_enabled
如果全局确定性标志处于打开状态,则返回True。有关详细信息,请参阅torch.use_determistic_algorithms()文档。
is_deterministic_algorithms_warn_only_enabled
如果全局确定性标志设置为仅警告,则返回True。有关更多详细信息,请参阅torch.use_determistic_algorithms()文档。
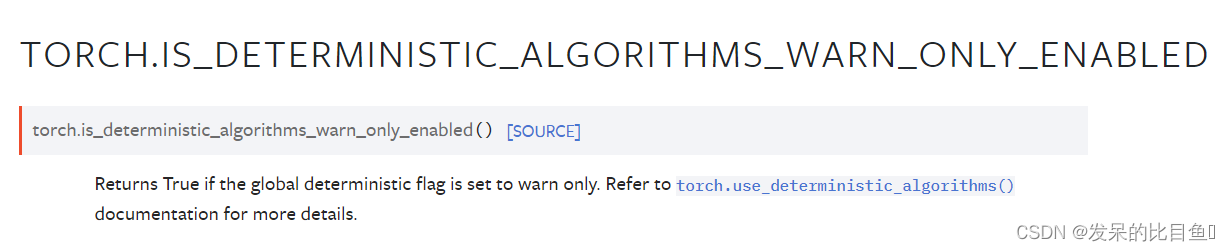
set_deterministic_debug_mode
为确定性操作设置调试模式。
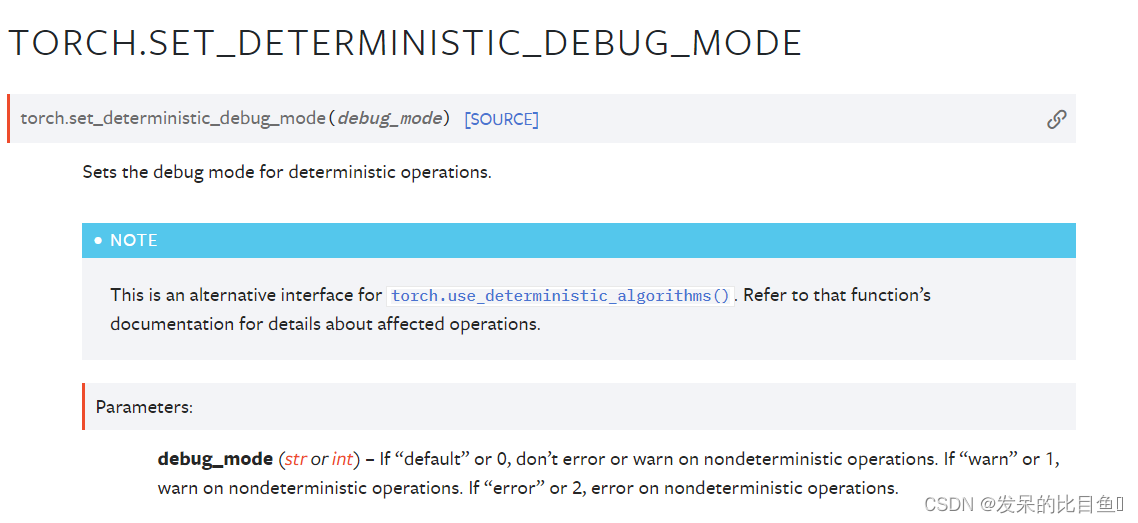
get_deterministic_debug_mode
返回确定性操作的调试模式的当前值。有关更多详细信息,请参阅torch.set_determistic_debug_mode()文档。
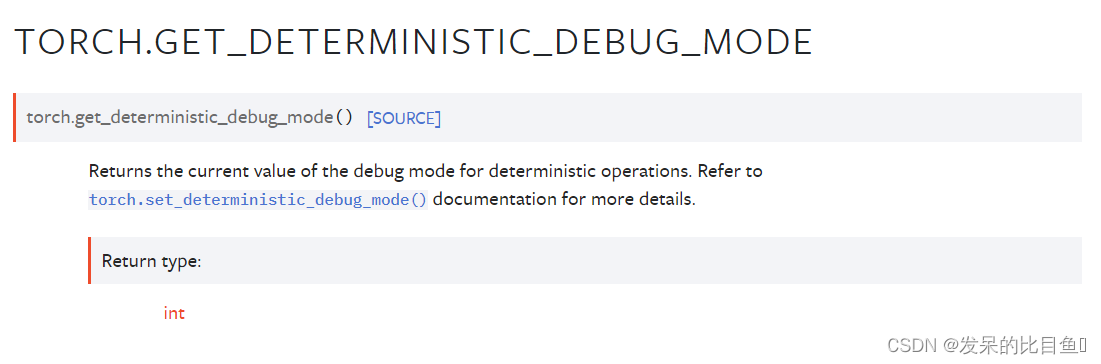
set_float32_matmul_precision
设置float32矩阵乘法运算的内部精度。
以较低的精度运行float32矩阵乘法可能会显著提高性能,在某些程序中,精度损失的影响可以忽略不计。


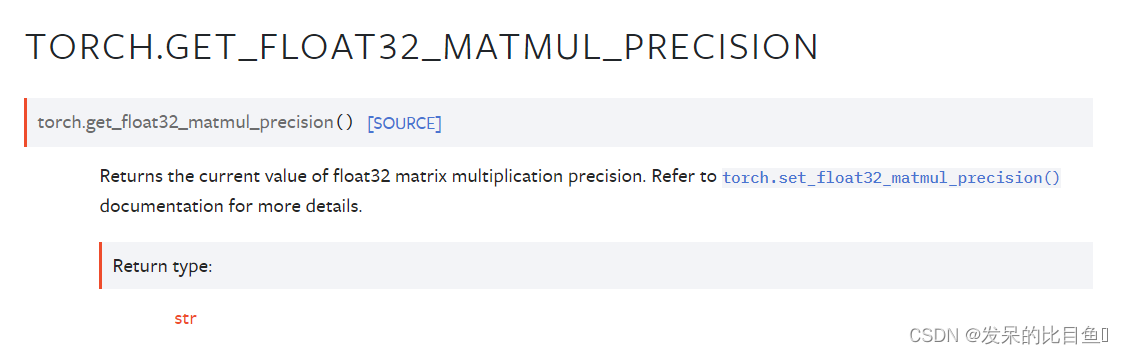
get_float32_matmul_precision
返回float32矩阵乘法精度的当前值。有关更多详细信息,请参阅torch.set_float32_matmul_precision()文档。
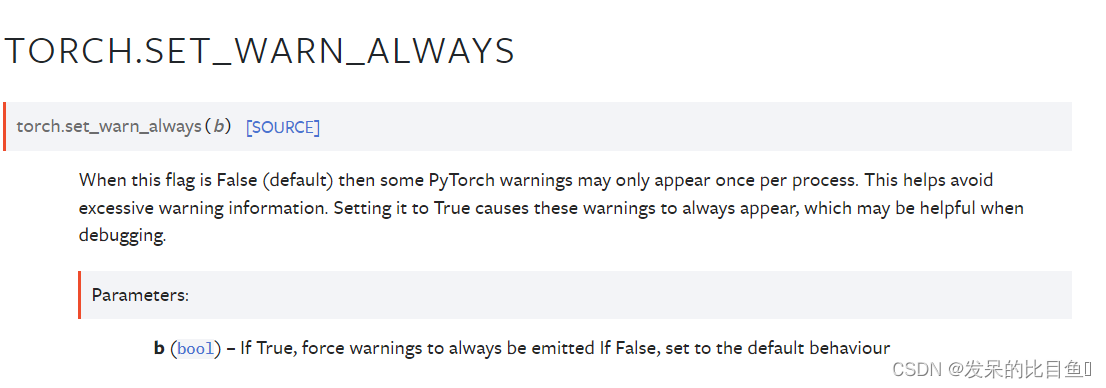
set_warn_always
当此标志为False(默认值)时,某些PyTorch警告可能在每个进程中只出现一次。这有助于避免过多的警告信息。将其设置为True会导致始终显示这些警告,这在调试时可能会有所帮助。
is_warn_always_enabled
如果全局warn_always标志处于打开状态,则返回True。有关详细信息,请参阅torch.set_warn_always()文档。

vmap
vmap是矢量化映射;vmap(func)返回一个新函数,该函数将func映射到输入的某个维度上。从语义上讲,vmap将映射推入func调用的PyTorch操作,从而有效地向量化这些操作。
vmap对于处理批处理维度很有用:可以编写一个在示例上运行的函数func,然后将其提升为一个可以使用vmap(func)进行批处理示例的函数。当使用autograd组合时,vmap也可以用于计算分批梯度。
>>> torch.dot # [D], [D] -> []
>>> batched_dot = torch.func.vmap(torch.dot) # [N, D], [N, D] -> [N]
>>> x, y = torch.randn(2, 5), torch.randn(2, 5)
>>> batched_dot(x, y)
vmap()可以帮助隐藏批处理维度,从而获得更简单的模型创作体验。
>>> batch_size, feature_size = 3, 5
>>> weights = torch.randn(feature_size, requires_grad=True)
>>>
>>> def model(feature_vec):
>>> # Very simple linear model with activation
>>> return feature_vec.dot(weights).relu()
>>>
>>> examples = torch.randn(batch_size, feature_size)
>>> result = torch.vmap(model)(examples)
vmap()还可以帮助矢量化以前很难或不可能批量处理的计算。一个例子是高阶梯度计算。PyTorch autograd引擎计算vjps(向量雅可比乘积)。为某个函数
f
:
R
N
−
>
R
N
f:R^N->R^N
f:RN−>RN计算一个完整的雅可比矩阵通常需要N次对autograd.grad的调用,每个雅可比行一次。使用vmap(),我们可以对整个计算进行矢量化,在对autograd.grad的一次调用中计算雅可比。
>>> # Setup
>>> N = 5
>>> f = lambda x: x ** 2
>>> x = torch.randn(N, requires_grad=True)
>>> y = f(x)
>>> I_N = torch.eye(N)
>>>
>>> # Sequential approach
>>> jacobian_rows = [torch.autograd.grad(y, x, v, retain_graph=True)[0]
>>> for v in I_N.unbind()]
>>> jacobian = torch.stack(jacobian_rows)
>>>
>>> # vectorized gradient computation
>>> def get_vjp(v):
>>> return torch.autograd.grad(y, x, v)
>>> jacobian = torch.vmap(get_vjp)(I_N)
vmap()也可以嵌套,生成具有多个批处理维度的输出
>>> torch.dot # [D], [D] -> []
>>> batched_dot = torch.vmap(torch.vmap(torch.dot)) # [N1, N0, D], [N1, N0, D] -> [N1, N0]
>>> x, y = torch.randn(2, 3, 5), torch.randn(2, 3, 5)
>>> batched_dot(x, y) # tensor of size [2, 3]
如果输入没有沿着第一个维度进行批处理,in_dims将每个输入沿着的维度指定为
>>> torch.dot # [D], [D] -> []
>>> batched_dot = torch.vmap(torch.dot, in_dims=(0, None)) # [N, D], [D] -> [N]
>>> x, y = torch.randn(2, 5), torch.randn(5)
>>> batched_dot(x, y) # second arg doesn't have a batch dim because in_dim[1] was None
如果输入是Python结构,in_dims必须是包含与输入形状匹配的结构的元组:
>>> f = lambda dict: torch.dot(dict['x'], dict['y'])
>>> x, y = torch.randn(2, 5), torch.randn(5)
>>> input = {'x': x, 'y': y}
>>> batched_dot = torch.vmap(f, in_dims=({'x': 0, 'y': None},))
>>> batched_dot(input)
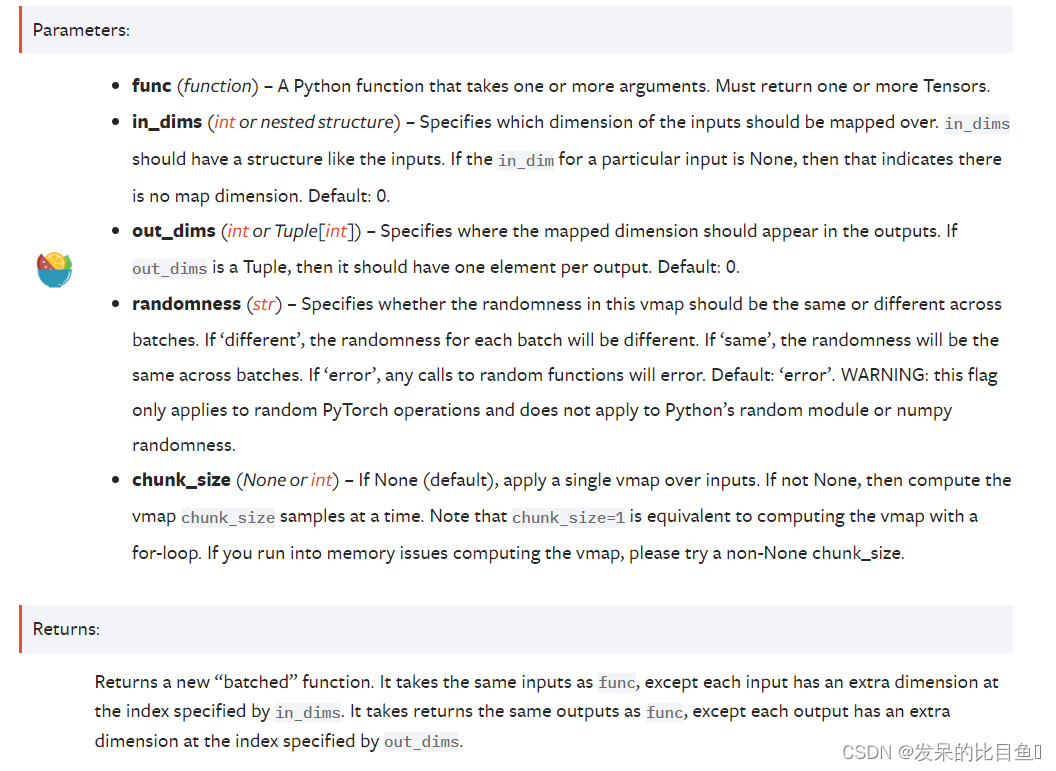
默认情况下,输出是沿着第一个维度进行批处理的。但是,可以使用out_dims沿任何维度进行批处理
>>> f = lambda x: x ** 2
>>> x = torch.randn(2, 5)
>>> batched_pow = torch.vmap(f, out_dims=1)
>>> batched_pow(x) # [5, 2]
对于任何使用kwargs的函数,返回的函数不会批处理kwargs,而是接受kwargs
>>> x = torch.randn([2, 5])
>>> def fn(x, scale=4.):
>>> return x * scale
>>>
>>> batched_pow = torch.vmap(fn)
>>> assert torch.allclose(batched_pow(x), x * 4)
>>> batched_pow(x, scale=x) # scale is not batched, output has shape [2, 2, 5]
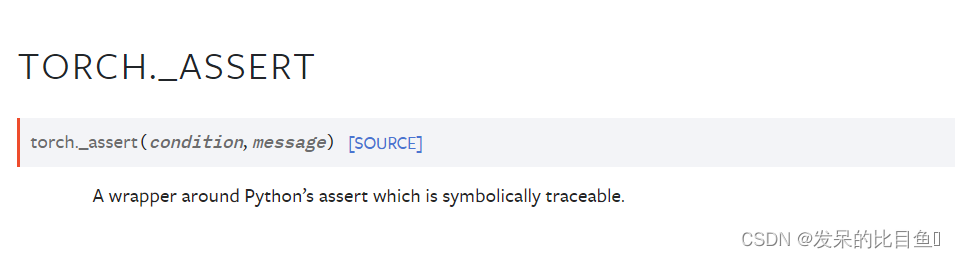
_assert
Python断言的包装器,该断言具有象征性可追溯性。
Symbolic Numbers
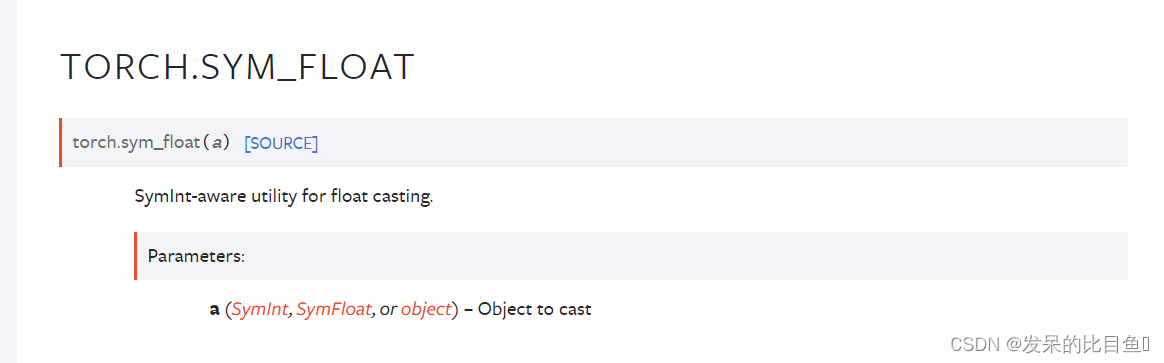
sym_float
SymInt-aware实用程序浮动铸造。
sym_int
用于int类型强制转换的symint感知实用程序。

sym_max
max()的symint感知实用程序。
sym_min
min()的symint感知实用程序。
sym_not
用于逻辑否定的symint感知实用程序

Optimizations
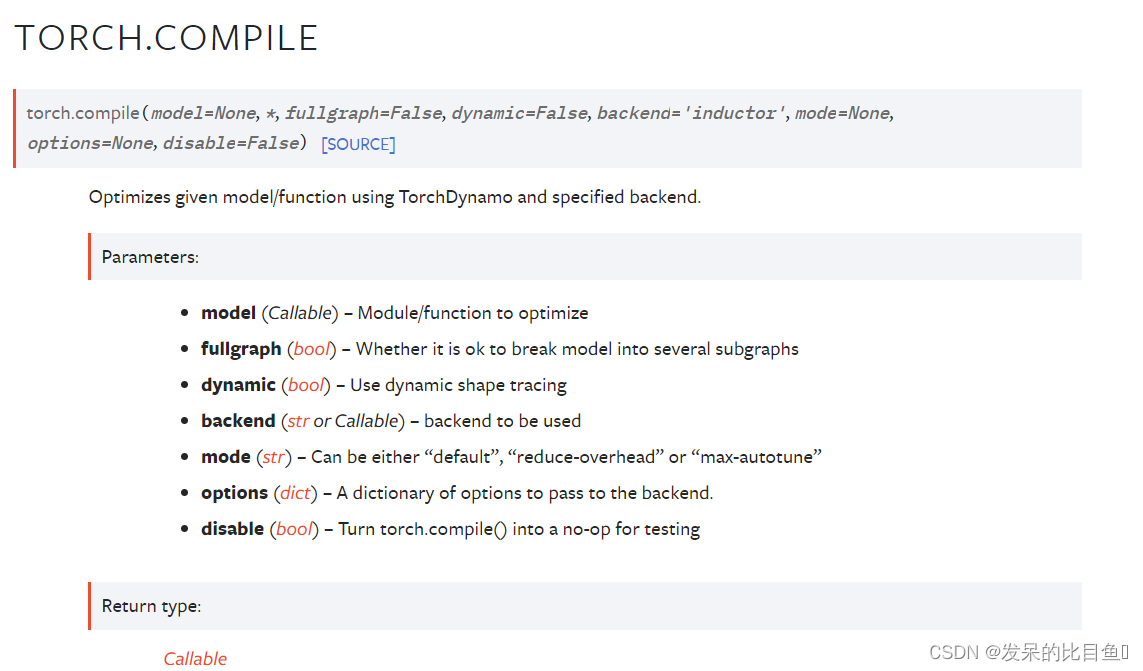
compile
使用TorchDynamo和指定的后端优化给定的模型/函数。
@torch.compile(options={"matmul-padding": True}, fullgraph=True)
def foo(x):
return torch.sin(x) + torch.cos(x)
Engine Configuration
set_multithreading_enabled
上下文管理器,用于向后打开或关闭多线程。
set_multitthreading_enabled将根据其参数模式启用或禁用多线程向后。它既可以用作上下文管理器,也可以用作函数。
这个上下文管理器是线程本地的;它不会影响其他线程中的计算。



















 1207
1207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











