






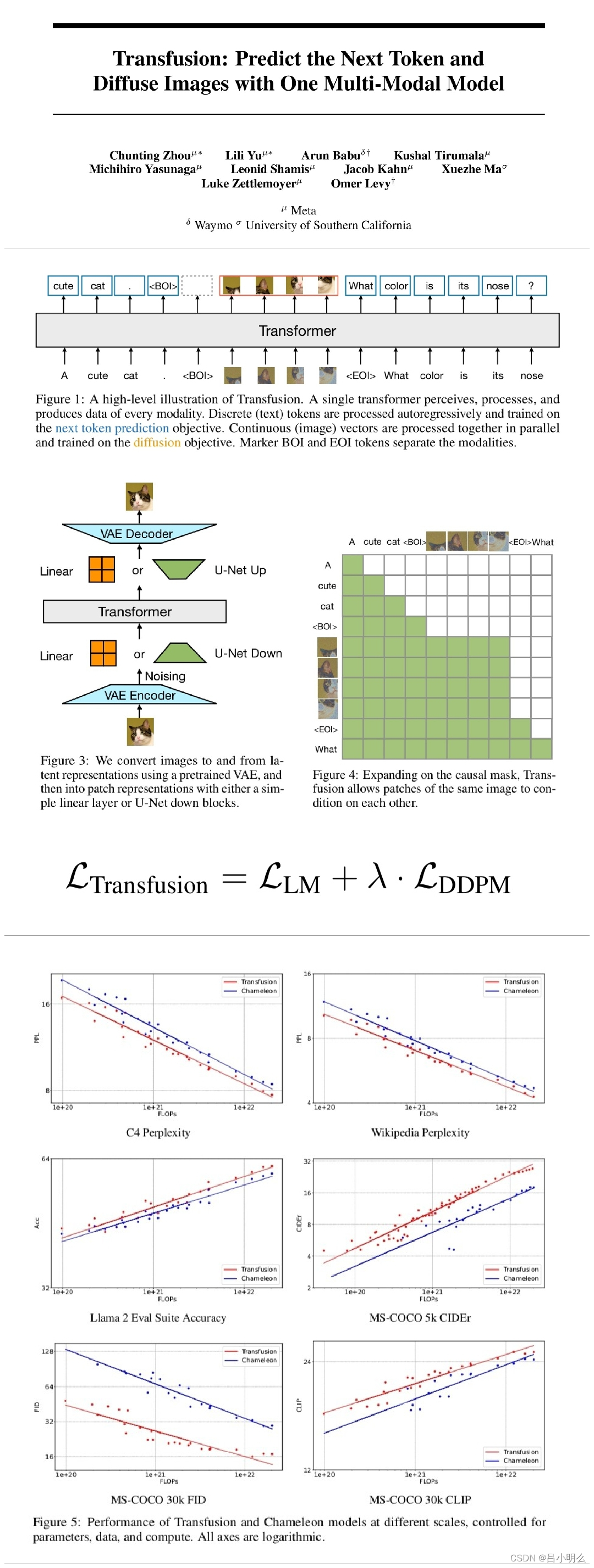
Meta:自回归与扩散的融合Transfusion
就在上周,Meta发布了Transfusion,构建了训练生成文本和图像的统一模型~至此,Transformer和Diffusion,似乎又有了一次某种形式或路线的融合尝试,也许在不久的将来,随着未来研究和探索的不断深入,在与先前的研究工作进一步结合,如AD(AR-Diffusion),以及不久前来自MIT CSAIL的“Diffusion Forcing等研究,语言(离散)和图像(连续)生成大一统的时代即将到来~
ps:关于AD(AR-Diffusion)思想和方法,以及不久前来自MIT CSAIL的“Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion”这篇论文,大家感兴趣的话可以爬下之前发的这一篇“高赞/高收藏”笔记「自回归(AR)与扩散(Diffusion)的邂逅」或参考「融合RL与LLM思想,探寻世界模型以迈向AGI」电子书中的部分章节论述。
而之所以说Meta的这篇是“某种形式或路线的融合尝试”,个人体会是其更多集中在模型架构和方法上的创新,如在模型结构上分别建立了针对离散文本数据分布与连续图像数据分布的目标与损失的集成与融合。
接下来针对这篇文章论文的核心方法做一些摘要,同时建议大家有时间去读下原论文,因论文直观且表达简练,可读性较强:
Ⅰ. 目标与损失的统一方面:为了训练模型,研究者将lm建模目标应用于文本token的预测,将扩散目标lddpm应用于图像块的预测。其中,lm损失是逐个token计算的,而扩散损失是逐个图像计算的。通过简单地将每种模态上计算出的损失与平衡系数λ结合,研究者合并了这两种损失,即将离散分布损失和连续分布损失结合,以优化于同一模型。
Ⅱ. 注意力统一方面:Transfusion通过对序列中的每个元素应用因果注意力,并在每个单独图像的元素内应用双向注意力,来结合这两种注意力模式。
Ⅲ. 模型架构统一方面:对于文本,每个输入整数转换为向量空间并将每个输出向量转换为词汇表上的离散分布;对于图像,尝试了两种方法(linear&u-net up/down)。
Ⅵ. 建立并评估了一系列单模态和跨模态缩放基准,并通过对比验证其更优的scaling law..















 4502
4502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









