









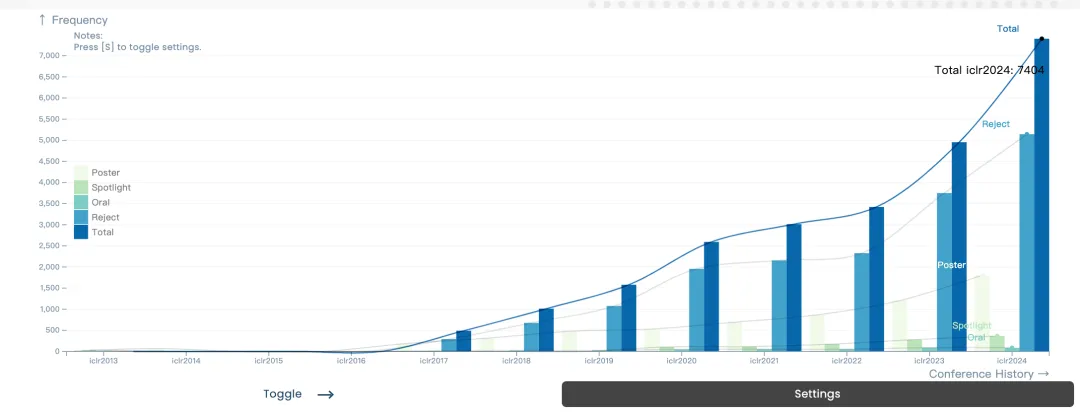
朋友们,ICLR 2024开奖了!5月7日至11日,今年的大会在奥地利维也纳展览会议中心举行。

ICLR(国际表征学习大会)是公认的深度学习领域国际顶级会议之一,属于CCF A类,主要专注于深度学习和强化学习等相关技术的研究与发展。
据统计,本届ICLR 2024共收到了7262篇论文,整体接收率约为31%,与去年(31.8%)基本持平。其中Spotlight论文比例为5%,Oral论文比例为1.2%。

但无论是参会人数还是论文提交量,相比往年都有极大提升!
近日,大会公布了 5 篇杰出论文奖和 11 篇荣誉提名奖,以及2篇时间检验奖。非常值得一提的是,其中有两篇国内论文获荣誉提名,分别来自北京大学和香港城市大学。
我这次帮大家整理了这些ICLR 2024所有的获奖论文,其中杰出论文可参考的创新点做了简单提炼。另外,为帮助想发论文的同学获取灵感,我也整理了25篇热门的ICLR高分录用论文,原文以及开源代码一并附上。
全部获奖+高分论文+开源代码需要的同学看文末
5篇杰出论文
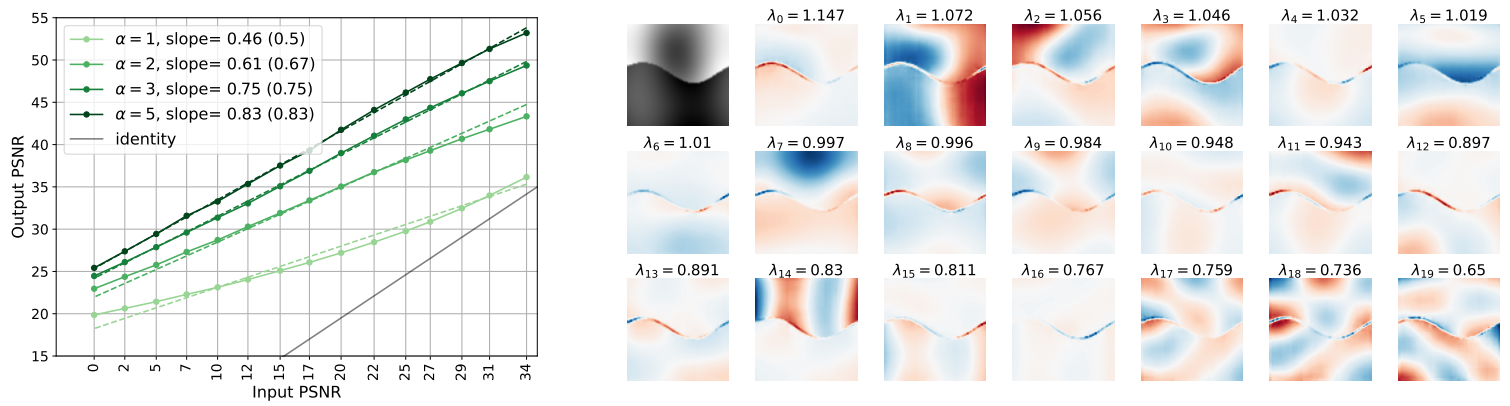
Generalization in diffusion models arises from geometry-adaptive harmonic representations
方法:论文研究了深度神经网络在图像去噪中的归纳偏差,发现网络倾向于学习适应图像几何结构的谐波基,这种偏差使网络在大数据集上能够达到较优的去噪性能,并生成高质量的样本。
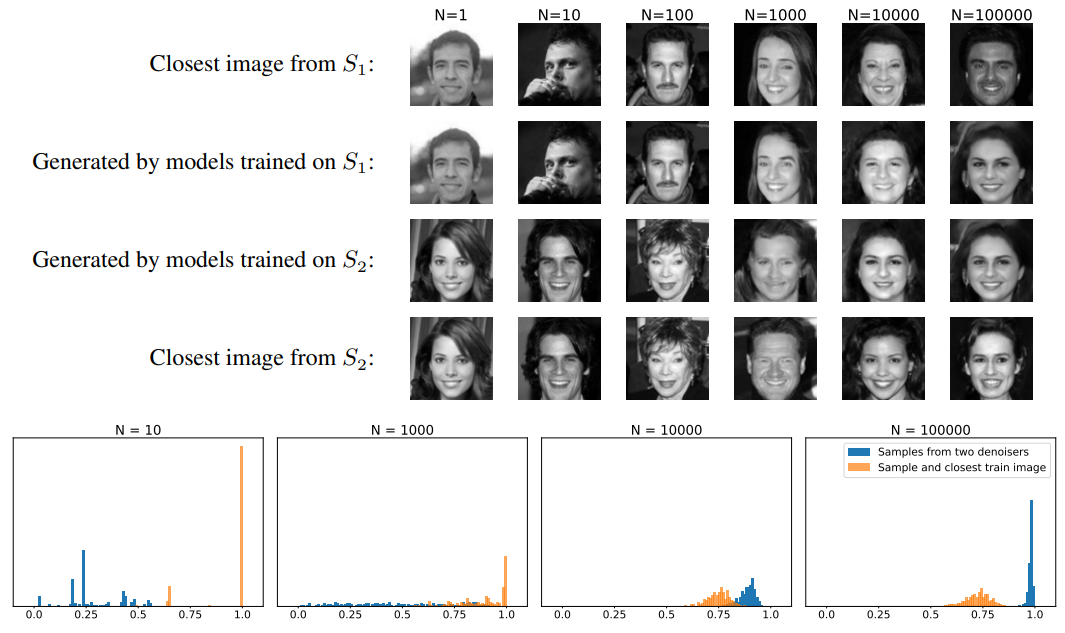
创新点:
-
提出了一种弱优化的方法,通过在噪声水平下降时对噪声抑制误差的渐近衰减进行匹配上下界的方式来找到基础(e k (y))1≤k≤d,以捕捉Figure1中PSNR曲线的渐近斜率。这种方法在噪声抑制中具有较好的性能。
-
提出了一种最佳自适应基础的方法,通过对噪声图像y进行自适应的基础(e k (y))1≤k≤d的选择,可以获得对未知清晰图像x的更稀疏的表示,从而获得更好的噪声抑制性能。
Learning Interactive Real-World Simulators
方法:论文介绍了一种建立通用模拟器(UniSim)的方法,该模拟器能够通过生成模型模拟真实世界的互动。通过精心组织不同的数据集,展示了UniSim如何将不同维度的信息整合在一起,从而模拟具有高水平指令和低水平控制的可视结果。

创新点:
-
综合不同维度的数据集,通过统一的生成模型建立了一个行为-视频的生成模型,实现了真实世界交互的通用模拟器(UniSim)。
-
将行为-视频生成模型转化为条件观测预测模型,并通过自回归的方式实现了一致且长时程的视频生成。
-
展示了模拟器在高层语言策略、低层控制策略和视频字幕模型的训练中的应用,并表明这些模型在纯模拟训练后能够在真实环境中进行泛化,从而弥合了模拟与真实之间的鸿沟。

Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors
方法:研究旨在探讨在长序列建模任务中,预训练对模型性能的影响,并研究了不同架构在预训练条件下的性能差异。相较于从零开始训练,预训练可以显著提高模型性能,并且使得简化的模型可以达到复杂架构的性能水平。
此外,研究还发现预训练的效果在数据规模较小时更为显著,同时展示了预训练对于不同数据模态的适用性。最后,研究还分析了通过预训练获得的先验与手动设计先验之间的关系,并提出了一种基于预训练的新的性能评估方法。
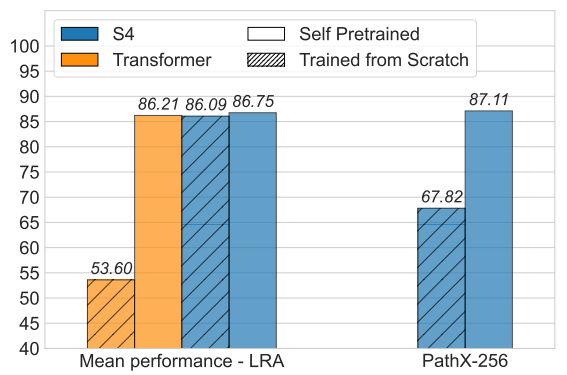
创新点:
-
通过标准去噪目标从任务数据中简单学习捕捉远程依赖关系的先验。作者发现,无需对模型进行干扰性改变,仅通过标准去噪目标就可以从任务数据中学习到捕捉远程依赖关系的有益先验。这一创新使得在数据相对稀缺的情况下,SPT的好处更加明显。
-
针对SSMs,通过分析通过SPT学习到的卷积核,揭示了捕捉长程依赖关系的学习先验。作者发现,根据模态的不同,快速衰减的卷积核可以比原始S4模型中使用的缓慢衰减的卷积核带来更好的性能,进一步凸显了从数据本身学习先验的效用。
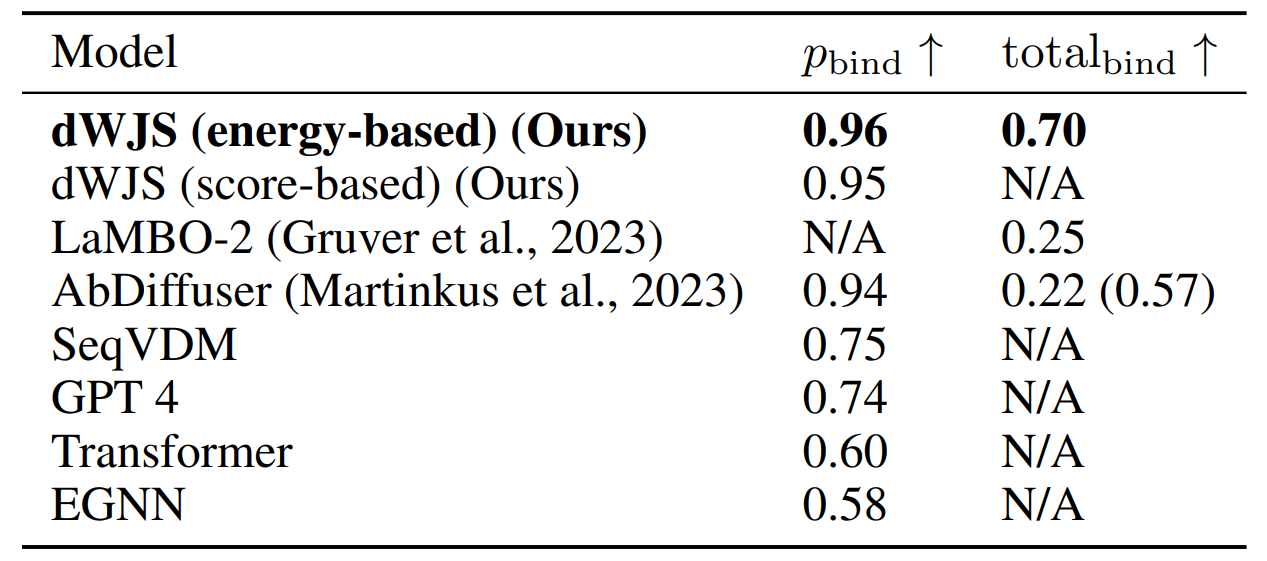
Protein Discovery with Discrete Walk-Jump Sampling
方法:作者开发一种用于离散数据的新型分离能量和评分建模方法,以改善训练和采样离散序列的困难。研究通过降低训练数据的能量(正样本)和增加从模型中采样的数据的能量(负样本)的期望值来达到这一目的。通过使用单步去噪回到离散值,该方法简化了离散数据的评分模型训练过程。
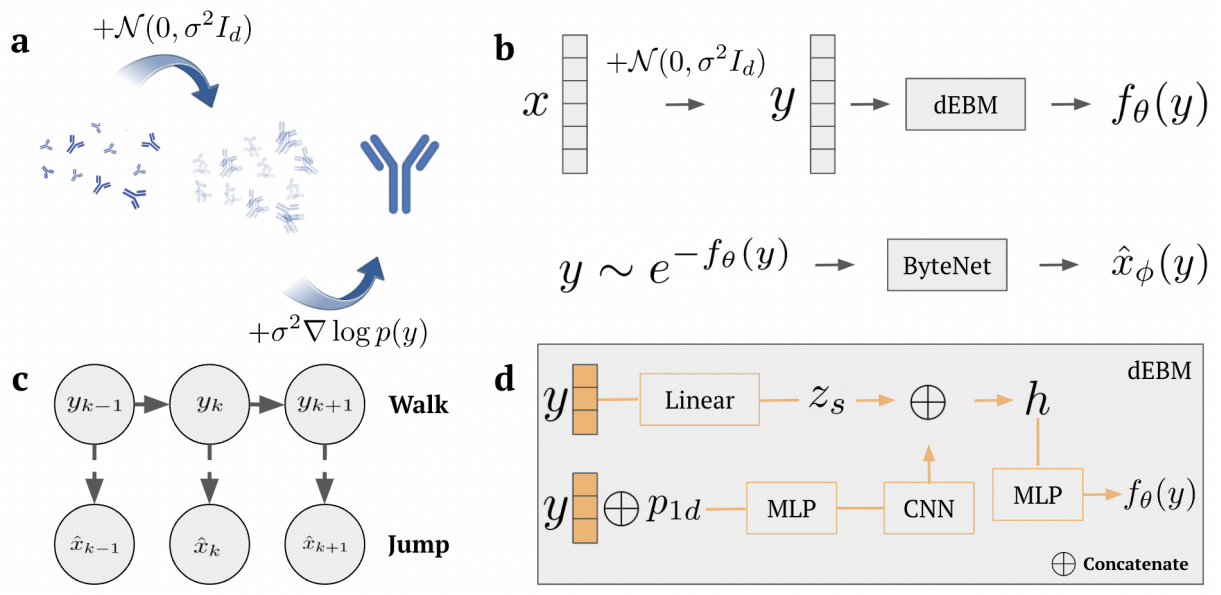
创新点:
-
提出了在NEB形式中将离散数据视为在欧几里得空间中取连续值,并选择较大的噪声水平来平滑原始分布,使得采样更容易。此外,他们还使用单步去噪回到离散值。
-
提出了一种解耦能量和分数模型的新方法,用于训练和采样离散序列。他们还设计了一种名为“分布符合得分”(Distributional Conformity Score)的度量指标,用于评估蛋白质样本的质量。
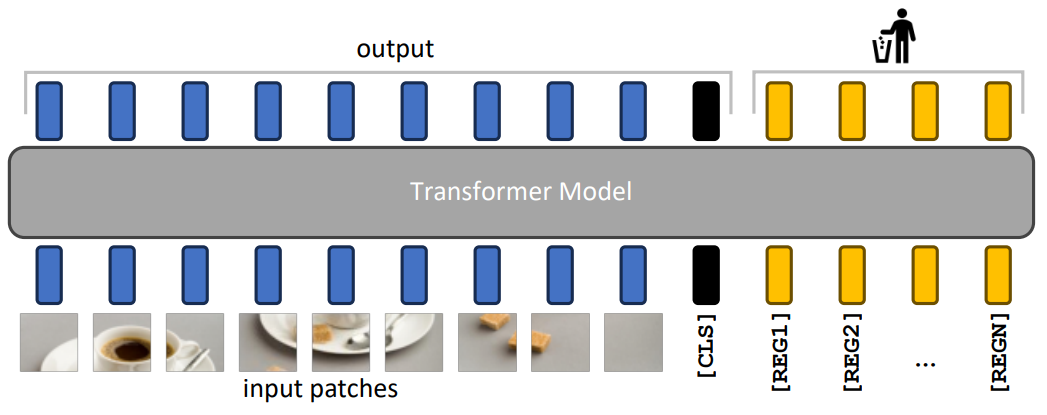
Vision Transformers Need Registers
方法:为解决现代视觉转换器中注意力图中的异常现象,作者提出了通过添加寄存器令牌来修复这一问题的简单而有效的解决方案,该解决方案不仅改善了模型性能和可解释性,而且在密集视觉预测任务中创造了自监督视觉模型的新纪录,还为使用更大模型的对象发现方法提供了可能性。
创新点:
-
提出了一种简单而有效的解决方案,通过向Vision Transformer的输入序列中添加额外的tokens来解决特征图中的异常问题。
-
研究者发现这些异常tokens通常出现在特征图的边缘区域,而不是中心区域。研究者认为这是因为基础模型倾向于在低信息区域中重用tokens作为寄存器,而这些区域通常对应于背景,其包含的信息较少。
-
通过在token序列中添加额外的寄存器tokens,这些异常tokens完全消失。这种修正技术提高了模型在密集预测任务中的性能,并且生成的特征图显著更平滑。

关注下方《学姐带你玩AI》🚀🚀🚀
回复“ICLR获奖”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









