







文章目录
LUT-GEMM: Quantized Matrix Multiplication based on LUTs for Efficient Inference in Large-Scale Generative Language Models
LUT-GEMM:基于lut的量化矩阵乘法在大规模生成语言模型中的高效推理
欢迎关注微信公众号InfiniReach,这里有更多AI大模型的前沿算法与工程优化方法分享

abstract
为了减小模型大小,我们采用仅权重量化策略,同时保留激活的全部精度。因此,我们通过非均匀或均匀量化技术实现了每个权值的亚4位sub-4-bit量化。
我们提出的核,称为LUT-GEMM,然后加速量化矩阵乘法,在压缩比和精度之间提供灵活的平衡。
与早期仅支持权重量化的矩阵乘法核不同,LUT-GEMM有效地消除了均匀和非均匀量化方法所需的资源去量化过程。通过减少单个gpu的延迟和大规模语言模型的整体推理过程,LUT- GEMM在推理方面提供了显着的性能改进。通过低比特量化和高效的基于lut的操作实现高压缩比,减少了所需gpu的数量,从而促进了LUT-GEMM的影响。对于3位量化的OPT-175B模型,我们表明,与需要昂贵的去量化的OPTQ相比,lutt - gemm将生成每个to- ken的延迟加快了2.1倍。因此,LUT-GEMM可以在单个GPU上对OPT-175B模型进行推理,而不会在交流精度或性能上出现明显的下降,而非量化的OPT-175B模型至少需要8个GPU
introduction
为了缓解与模型并行性相关的挑战,参数量化[10,33,54]提出了最小化模型大小的实用解决方案,从而减少了推理所需的gpu数量,如图1所示。
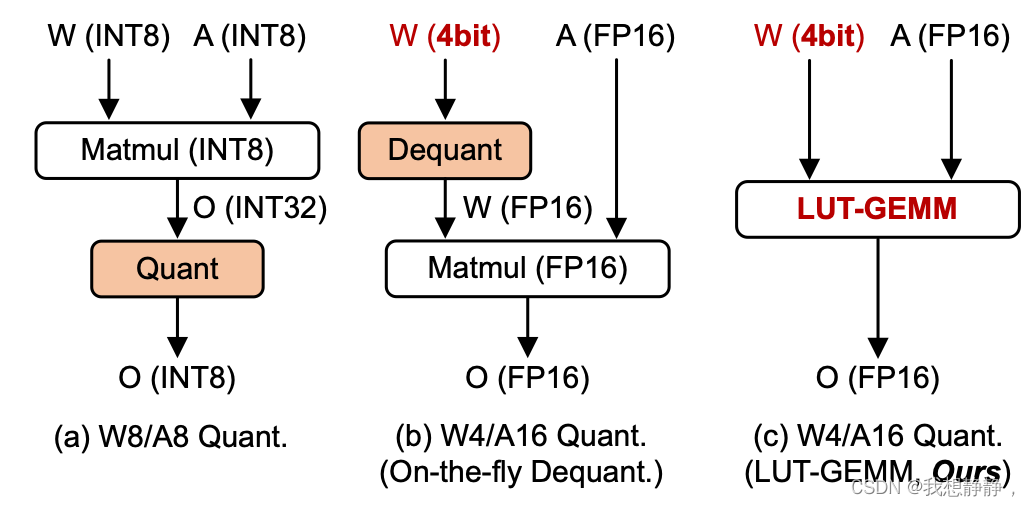
在各种量化方案中,均匀量化是利用基于整数的算术单位的首选方案[24,31,52,60]。尽管如此,均匀量化实际上仅限于8位,非线性操作(例如softmax和归一化)可能会产生不精确的结果[5,28]。此外,为了充分利用整数算术单位,必须实现动态激活量化和去量化,以及对激活分布的准确估计[14,56]。
最近的研究提出了4-bit weight-only作为内存压缩的一种方法[18,58],这涉及到动态转换到全精度。虽然这牺牲了使用整数算法的计算优势,但大型语言模型(LMs)中的weight-only表明对于给定的目标精度,与同时量化权重和激活时相比,weight-only可实现的权重压缩比明显更高[18,58]。人们还提出了各种采用非均匀格式的权重量化方法来提高压缩比[25,29]。
在本文中,我们引入了一个核函数LUT-GEMM,它被设计用于在保持全精度激活的同时,使用均匀或非均匀方法对权重进行全量化时,便于量化矩阵乘法。如图2所示,LUT-GEMM有效地解决了以前量化方法中普遍存在的两个问题:
- 由于全量化激活而不可避免地导致精度下降;
- 需要额外的去量化实施。
LUT-GEMM支持仅量化权重和全精度激活,使推理过程的加速,同时保持所需的精度水平。
具体来说,LUT-GEMM采用二进制编码量化(BCQ)格式[45]来利用简单的算术运算。值得注意的是,BCQ最初是为了支持非均匀量化而提出的,它依赖于自定义的硬件来进行位级操作。在本文中,我们证明了先前的均匀量化可以以BCQ的形式重新表述,从而允许LUT-GEMM同时支持非均匀和均匀量化格式。因此,LUT-GEMM能够对矩阵乘法执行广泛的weight-only方案,实现低推理延迟并消除对激活量化的需要。
我们在这项工作中的主要贡献包括:
- 验证了BCQ能够表示均匀和非均匀权量化。
- 对于BCQ格式,LUT-GEMM可以在压缩比和延迟之间提供广泛的搜索空间(基于gpu特定的高效硬件利用方法来实现各种BCQ配置)。
- 对于大型lm,我们证明了LUT-GEMM可以显着加速小量化位的矩阵乘法,同时通过减少gpu数量节省了大量功耗。因此,LUT-GEMM导致低能耗。
- 假设OPT-175B的权重为3位BCQ格式,由单个GPU提供,我们的实验结果表明,与OPTQ[18]结果相比,LUT-GEMM可以将生成每个token的延迟加快2.1倍。
背景
量化
提高吞吐量的操作包括量化[12,24,37,45,54],修剪[17,19,21,62],知识蒸馏[22,41]和低秩近似[7,16,36]。其中,量化是研究最广泛的领域,它涉及到使用更快、更高效的计算单元和减少内存消耗。使用INT8算子的统一量化在各种量化格式中得到了特别好的研究,目前正在llm中得到积极应用[14,53,56]。
INT8算术单元,提供更低的延迟(由于其低面积和功耗要求),并且与FP16相比减少了高达50%的内存使用。因此,目前的NVIDIA gpu采用支持INT8运算的tensor core来加速计算[32]。然而,INT8的使用要求激活量化,这可能会给使用INT8单元实现压缩和加速模型带来重大挑战。
例如,当scaling factors离线确定时,激活量化可能会导致模型精度的显著降低,因为离群值是近似的。为了避免准确性的下降,基于token的动态量化已经成为量化llm的关键技术[14,56]。LLM.int8()方法[14]提出了一种分解方法,解决了llm中异常值的系统性出现,该方法在INT8中进行大部分计算,并将有限数量的异常值去量化到FP16,导致llm中的延迟仅略有减少。
SmoothQuant[53]采用了一种先进的方法,通过数学方法将激活的方差(由于存在异常值而难以量化)转换为相对容易量化的权重。这种技术可以使用INT8算术单元(即W8A8)高效地计算llm,即使在使用静态量化激活时也是如此。根据-1 SmoothQuant的结果,当异常值系统出现时,llm可以加速1.5倍,α0 = 2, GPU使用减少2倍。然而,应该注意的是,要在新的llm中应用SmoothQuant,在应用迁移技术之前,有必要对异常值的发生进行经验观察和验证。
另一方面,如前所述,token生成过程的自回归特性限制了硬件的最大吞吐量,即使具有INT8精度。因此,像chatGPT[39]这样需要生成大量token的服务,可能不会通过采用INT8精度来获得显著的性能提升。
最近的研究集中在生成步骤的低效率上,作为回应,提出了使用W4A16格式[18,58],该格式将模型权重压缩为4位整数,而不量化激活。考虑到当前的计算系统无法加速W4A16格式,OPTQ[18]通过首先将权重解量化为FP16格式,然后执行矩阵乘法运算来解决这一问题。通过利用生成步骤的内存限制特性,该方法可以减少gpu的数量并改善生成延迟,尽管有去量化的开销。
二值量化BCQ
在本文中,我们介绍了二进制编码量化(BCQ)的应用,这是一种通用的非均匀量化方案,它涵盖了均匀量化,我们将在下一节中讨论。BCQ在[45]中首次被引入,作为传统均匀量化方法的一种令人信服的替代方案。
权重向量是W,大小为n。量化位数记为q。W近似表示为 ∑ i = 1 q a i b i \sum_{i=1}^qa_ib_i i=1∑qaibia是scale系数,b是二值符号(取值为{-1, +1})。
请注意,缩放因子a可以由许多权重共享(𝑛可以是任何数字),因此较大的𝑛值会导致缩放因子占用相对较小的内存。量化过程大致包括寻找比例因子和二值向量,以最小化量化误差,如下所示:
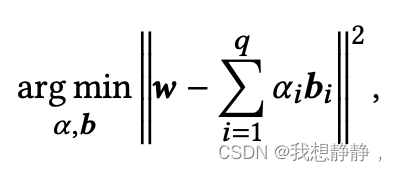
除𝑞= 1外没有解析解。因此,通过迭代搜索方法[20,54]或量化感知训练[12]获得缩放因子和二值向量。最近,Kwon等人[29]提出了AlphaTuning,这是一种结合了参数有效自适应和BCQ方案的方法,证明了各种生成式LMs可以通过下游数据集进行微调,同时实现极低的比特量化,甚至低至1或2比特。
LUT-GEMM
LUT-GEMM旨在为LLM开发高性能、低能耗的推理系统。为了实现这一目标,LUT-GEMM采用了几种创新方法。
- 通过增加偏置项对传统的BCQ方法进行扩展,显著提高了表征能力。这个简单的加法可以在扩展的BCQ格式中表示非均匀和均匀的量化方法,使我们能够根据具体的LLM要求利用各种量化方法。
- 扩展二值量化,实现了压缩比和量化误差之间的权衡,以更好地利用llm的特性。
- 最后,由于大多数非均匀量化方法通常涉及低并行性的复杂操作,并且可能缺乏硬件支持,因此我们设计了LUT-GEMM来有效地适应BCQ格式。我们提出的内核LUT-GEMM直接利用BCQ格式,消除了对额外开销的需要,例如去量化。因此,LUT-GEMM证明了LLM推理所需的延迟降低和/或gpu数量减少,同时内在地适应各种仅权重量化方法。
二值量化扩展
非对称二进制编码量化:
传统的BCQ方法基本上局限于表现出相对于零点的对称量化形状。BCQ方法的另一个限制源于它们由于对称量化特性而无法表示零的值。为了增强BCQ的表征能力,我们扩展了传统的BCQ方法,加入了一个偏差项,如下所示:
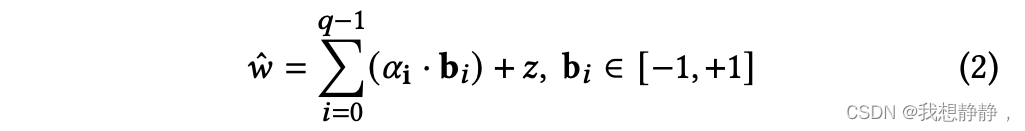
其中,将权重矩阵分成二值向量bi和相应的比例因子向量ai。因此,修改后的BCQ格式,加上偏置项,可以表示以z为中心的不对称量化,如图5(a)所示。
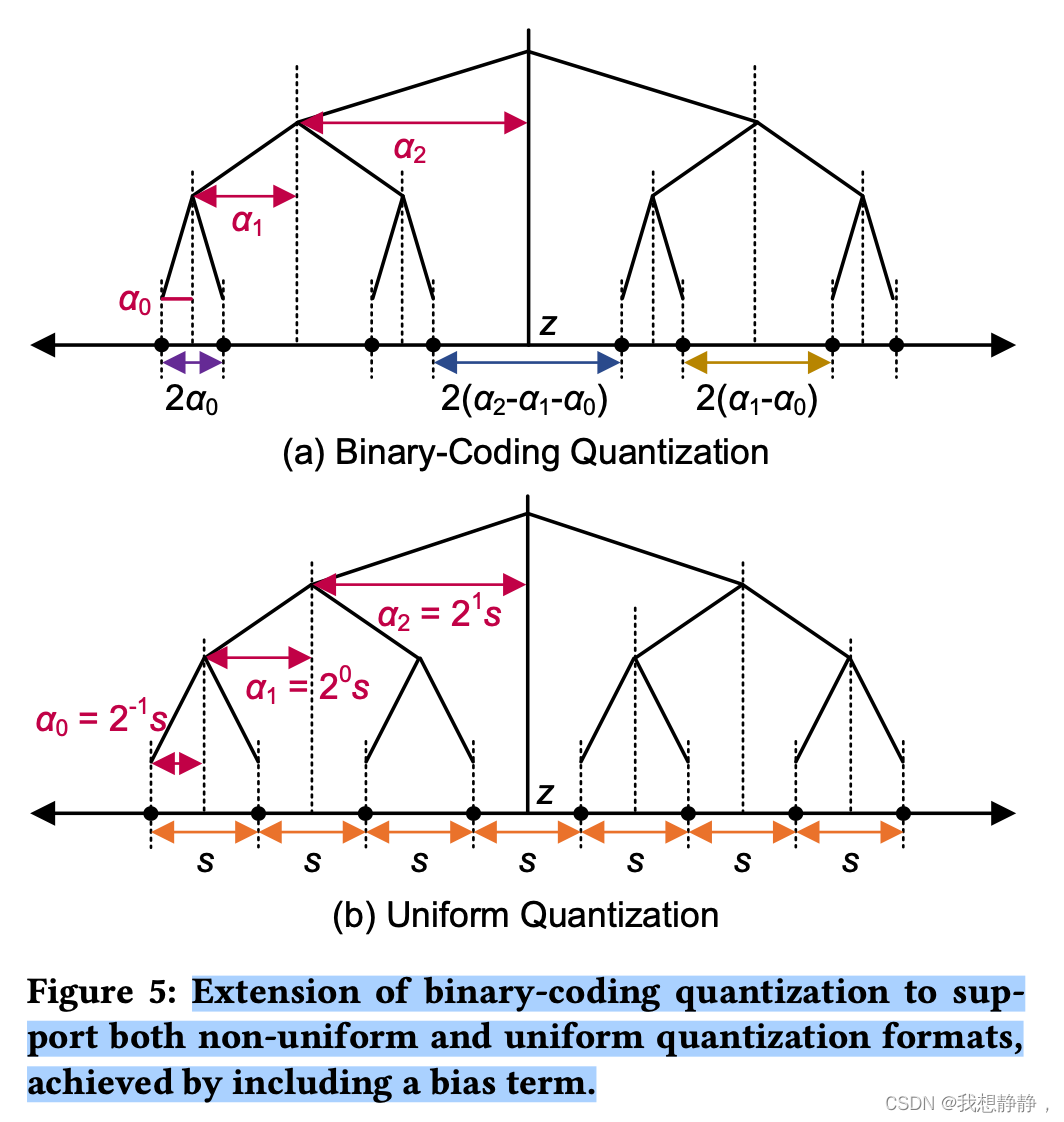
上图包括非均匀量化和均匀量化(z-2s -s-0.5s,z-2s-s+0.5s, z-2s + s-0.5s, …,每一项间隔s)
Uniform Quantization:
我们发现,在BCQ格式中引入偏置项,通过仔细调整比例因子和偏置项,可以在扩展的BCQ格式中表示均匀量化(图5(b))。让我们详细说明如何将非对称均匀量化转换为带偏置项的对称BCQ。
具有比例因子𝑠的𝑞-bit均匀量化权重𝑤´可以表示为BCQ格式

只需要将其中的公式代换成了BCQ里的abz
如图5,均匀量化方法使用了一个简单的scale因子s,而非均匀量化技术要求使用𝑞个不同的比例因子。因此,由于引入了扩展的二进制编码量化格式,我们提出的基于lut的矩阵乘法方案既适用于均匀量化,也适用于基于二进制编码的非均匀量化方法。
Group-wise 𝛼分配
- 分组求缩放因子可以适应超大hidden size
- 分组求缩放因子可以更好调整量化位数q,来平衡量化误差和压缩比
在实践中,传统的BCQ方法假设为权重矩阵的每一行(甚至整个矩阵)分配一个缩放因子,以支持cpu或gpu的向量指令[45,54]。随着大规模LMs引入更深更宽的模型结构以及不断增加的参数大小[43,47]。然而,我们认为这种传统的逐行BCQ格式遇到了各种挑战。
假设选择相对较小的隐藏大小(例如,对于OPT 350M,𝑑= 1024)以及相应的模型小权重矩阵,按行分配比例因子可能是合理的,可以获得较小的量化误差。但随着大规模LMs的出现,隐藏大小迅速增加(例如,GPT-3 175B的𝑑model = 12288),则计算由大量权重共享的适当比例因子将变得更加困难。为了实现低比特量化方案,有必要研究分配比例因子的不同方法,只要新的分配可以得到实际实现的支持。
作为行量化的替代方案,我们提出了组量化,其中一个比例因子可以由任意数量的权重共享。我们提出的新BCQ格式引入了一个新的超参数𝑔作为组大小,表示由比例因子共享的权重数量。 𝑔是一个固定的数字,其范围为32到矩阵的列宽(相当于逐行量化)。由于𝑔是一个常数,因此隐藏的大小不会影响我们的group-wise的BCQ格式。
对压缩比的影响:
设𝑞为量子化位的个数。对于给定的𝑞,较小的组大小𝑔可以降低量化误差,但代价是增加缩放因子的内存占用。然后,目标量化误差作为确定𝑞和𝑔之间折衷的约束,从而产生可实现的压缩比范围。换句话说,由于引入𝑔,我们可以控制缩放因子和二进制向量的数量,作为一个权衡过程。 请注意,传统的逐行量化技术的内存占用是由二进制向量的大小决定的,因为如果矩阵的列宽度足够大,通常可以忽略缩放因子的大小。与传统方案相比,我们提出的分组BCQ为量化格式提供了一个新的宽搜索空间,以满足目标压缩比。
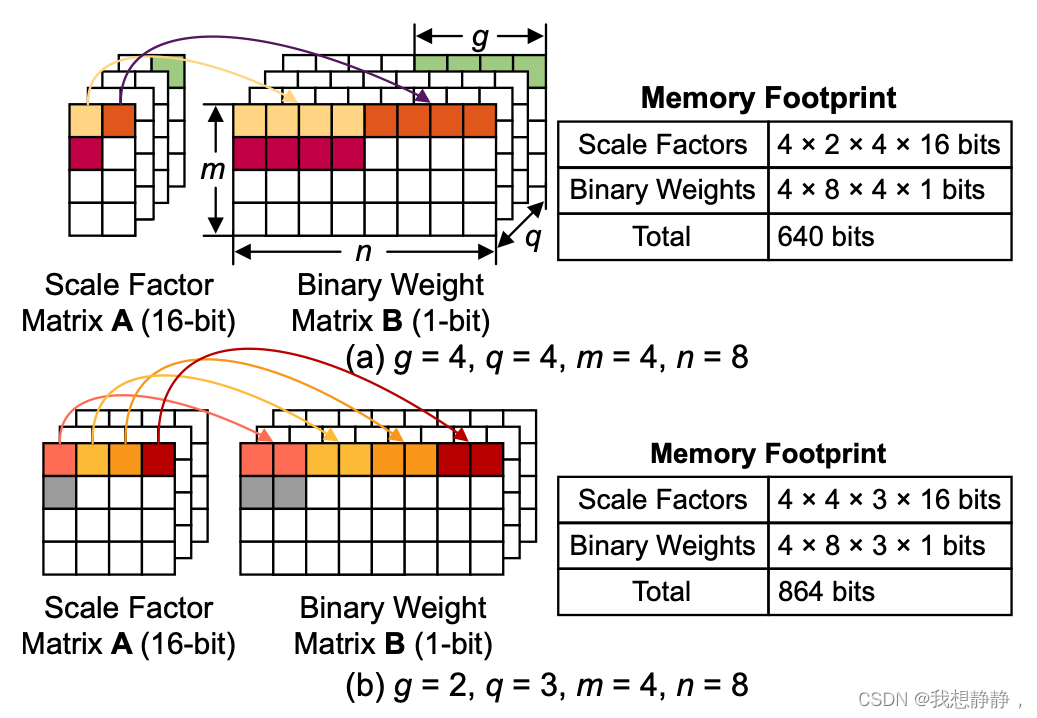
图6显示了一个示例,其中有两个(𝑔,𝑞)配置来量化一个(4 × 8)矩阵。实际上,即使量化位的数量较小,当组大小𝑔较小(即使用更多缩放因子)时,内存占用也会很大。(scale: m ∗ n / g ∗ q ∗ s i z e o f ( a ) m*n/g * q * sizeof(a) m∗n/g∗q∗sizeof(a),binary: m ∗ n ∗ q ∗ s i z e o f ( b ) m*n*q*sizeof(b) m∗n∗q∗sizeof(b))
基于LUT的量化矩阵乘法
我们的量化方案利用BCQ格式进行权重量化,同时保持激活的完全精度,导致原始矩阵乘法中的重复和冗余部分计算。为了说明,假设二元矩阵
B
∈
{
−
1
,
+
1
}
4
×
4
B\in \{−1, +1\}^{4\times4}
B∈{−1,+1}4×4,激活向量
x
∈
R
4
x\in R^4
x∈R4
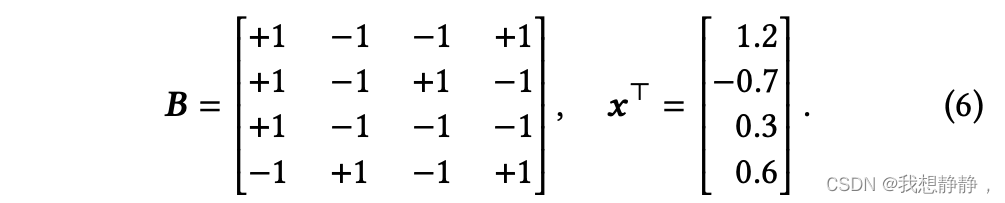
然后,计算𝑩𝒙(即乘以缩放因子)将重复(1.2−(−0.7))三次,(−0.3 + 0.6)两次。这种冗余计算是由𝑩的数字化元素引起的,因此,随着模型尺寸的增长,随着矩阵大小的增加,我们预计会有更多的重复计算。此外,加载𝑩的每个元素需要位级内存访问,这对于商用cpu和gpu来说可能很慢。
为了避免位级内存访问并有效地执行𝑩𝒙,我们可以预先计算全精度激活和二进制模式的所有可能组合。请注意,查找表(LUT)已被广泛用于节省处理时间,当大量计算在一个限制集合内产生输出时[13,34,55]。基于LUT的计算是合理的,特别是当从LUT中检索值比执行原始计算快得多时。
BCQ格式(不需要对训练代码和模型结构进行大量修改的量化激活[24,52])也可以通过基于lut的方法实现。例如,对于𝒙中的每3个元素{𝑥1,𝑥2,𝑥3},我们可以预先计算
8
=
2
3
8=2^3
8=23个可能的值,如表1所示,并将这些值存储在LUT中。
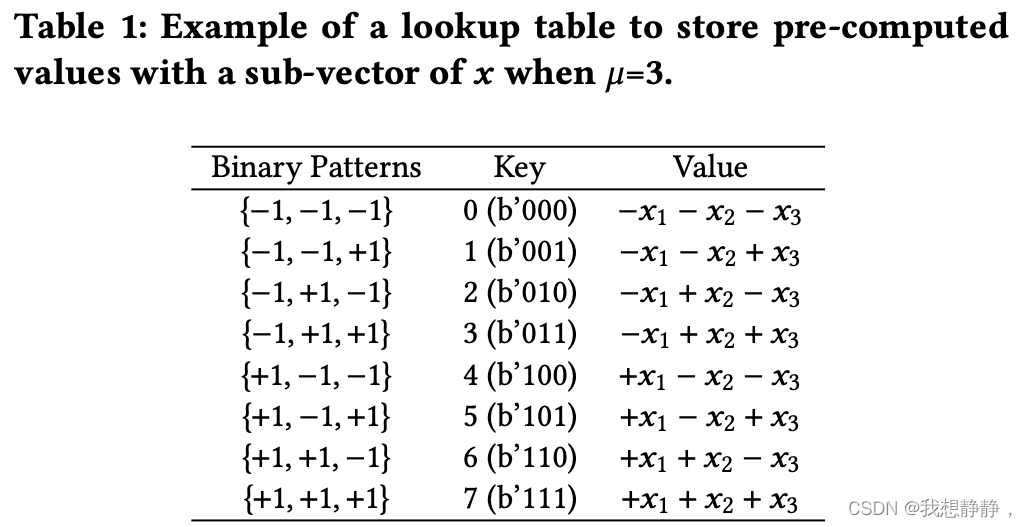
设μ为构建一个LUT的𝒙子向量的长度(表1中的μ为3)。一旦使用𝒙的子向量生成了一个LUT的 2 μ 2^μ 2μ值。 通过连接𝑩的μ个二进制元素给出一个键,用LUT检索操作替换获得( B x T Bx^T BxT的)部分点积的算术运算。为了完成 B x T Bx^T BxT的计算,作为最后一步,这些偏积被求和,然后乘以比例因子。当𝑩的行维增加时(随着生成式lm变大),由于冗余计算的出现更多,LUT的利用率也会增加。
让我们简单解释一下如何优化μ。如果μ增加,LUT的建设成本也增加 2 μ 2^μ 2μ。然而,这样增加的μ可以增强计算并行性,因为我们可以用一个LUT检索操作替换FP16加法的μ个数。因此,如文献[25]所述,存在一个使加速最大化的最优μ。注意,优化μ还需要考虑对齐内存访问。在我们的工作中,μ = 8是一个实际的选择。
LUT-GEMM
除了基于lut的方案(消除冗余计算和位级内存访问),我们提出的LUT-GEMM需要通过分组量化实现高性能,以提高给定𝑞的准确性。我们在gpu上优化单批操作的策略如下:
- 为了提高并行性,我们创建尽可能多的线程,同时允许每个线程执行独立的LUT访问。
- 线程访问的二进制权重可以共享一个通用的缩放因子,这样与缩放因子相关的操作就不会降低线程的性能。
- 如果我们为一个线程分配的资源太少,那么LUT的利用率就会很低,同步开销就会增加。因此,我们需要根据经验优化线程配置。
为了简单起见,我们将提出的group-wise量化矩阵乘法表述为 y = ∑ i = 1 q ( A i ∘ ( B i ∗ x ) ) y = \sum_{i=1}^{q}(A_i \circ(B_i * x)) y=∑i=1q(Ai∘(Bi∗x)),其中𝑨是 m ∗ n m*n m∗n的FP16缩放矩阵,𝑩是 m ∗ n m*n m∗n的FP16二进制矩阵,𝒙是大小为𝑛的FP16输入向量,操作符 ∘ \circ ∘表示element-wise乘法。请注意,在实际情况下,由于每个𝑔权重共享一个缩放因子,因此,变量的内存占用减少了𝑔。
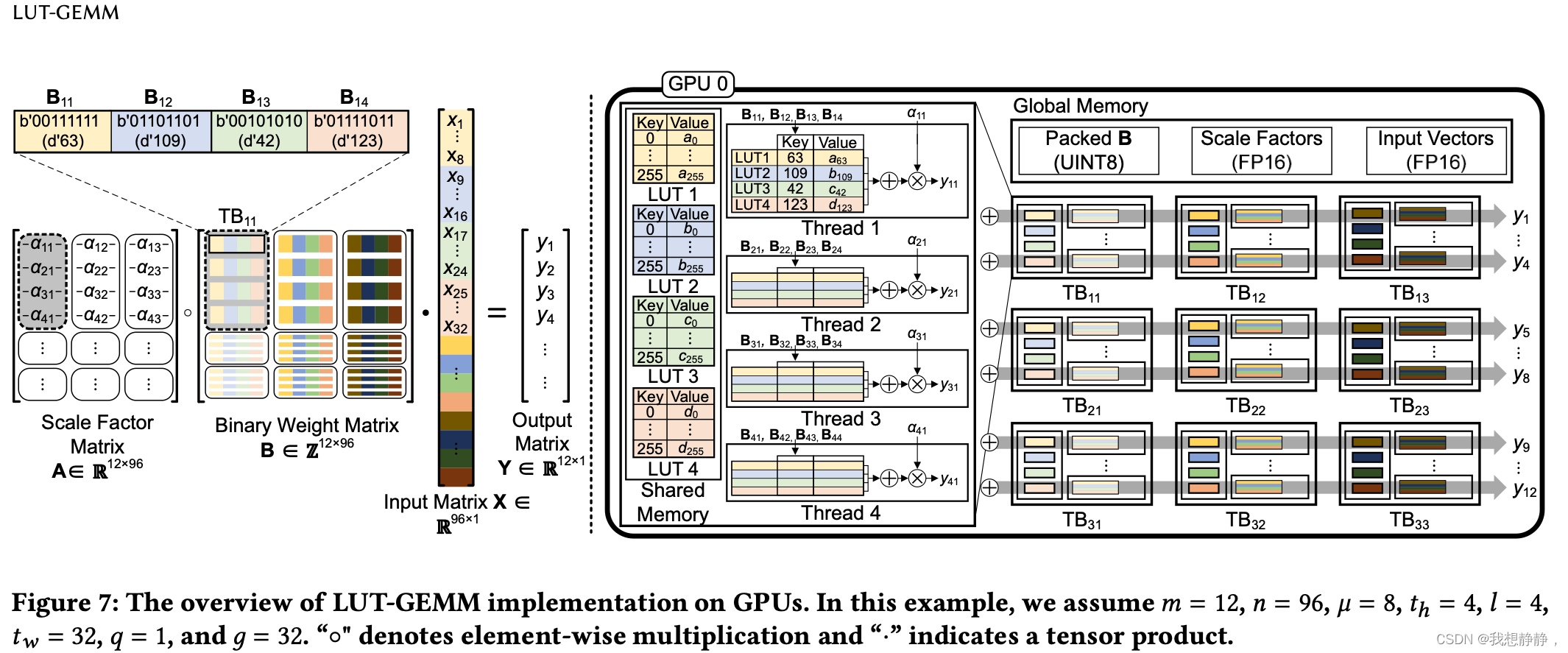
总体的结构。对于LUT-GEMM,我们将 l l l 个lut分配给GPU的线程块(TB)。那么,当 t w = l × μ t_w=l\times μ tw=l×μ时,分配给每个TB的𝑨和𝑩的子矩阵的大小变为 ( t h × t w ) (t_h \times t_w) (th×tw)。
较小的 t h t_h th可以增加可用线程的数量,而较大的 t h t_h th可以提高TB内的LUT利用率。因此, t h t_h th是经验上确定的(2048是大规模LMs的实际数字)。
请注意,分配给每个TB的资源量足够小,因此只要𝑔大于 l × μ l\times\mu l×μ,多个TB就可以共享一个比例因子。图7给出了在gpu上的整体lut- gemm实现方案,我们假设: μ = 8 , l = 4 , t w = 32 , t h = 4 , q = 1 , g = 32 \mu=8,l= 4,t_w= 32,t_h = 4,q= 1,g= 32 μ=8,l=4,tw=32,th=4,q=1,g=32。至于q大于1时,图7的整个过程可迭代𝑞次,中间结果累积。
详细的实现
每个TB首先使用分配的部分分值进行预计算,以填充 l l l 个lut数。然后, l l l lut可以由TB内的所有线程共享(从而减轻昂贵的全局内存访问),并且𝑩的子矩阵的多行可以由多个线程处理(从而提高吞吐量)。当线程完成对LUT值的检索和求和时,将获取缩放因子(每个线程只获取一次)并将其相乘以产生部分输出。
最后,跨tb累积 n l × μ \frac{n}{l\times\mu} l×μn个部分输出(通过atomicAdd操作,如图7所示)以生成最终输出。
lut存储在GPU内部的共享内存中,共享内存提供高带宽(例如A100的19TB/s)。因此,LUT的高内存访问(虽然可以用一个LUT访问替换多个flop)可以实现快速矩阵计算。至于lut的内存大小,每8个隐藏维度只需要1KB,共享内存大小超过几兆字节(例如,A100的内存大小为20MB,每个SM为192KB,有108个SMs可用)。因此,整个lut可以安全地存储在共享内存中。为了说明,A100的隐藏维度可以高达324,000,而GPT-3 175B的隐藏维度为12,288。
为了检查LUT-GEMM在组大小𝑔上的延迟方差,我们在𝑔值变化时执行矩阵乘法(使用(𝑚×𝑛)矩阵和(𝑛× 1)矩阵)。在图8中,对于每个𝑚(=𝑛)选择,将不同𝑔的矩阵乘法延迟与逐行(即𝑔=𝑛)BCQ格式的矩阵乘法延迟进行比较。有趣的是,当𝑔>32、在图8中,无论𝑚是否存在,组方向的LUT-GEMM与行方向的LUT-GEMM一样快。换句话说,一个相当大的𝑔(例如128和256)可以导致快速的lut - gem,而分组的精度提高是实质性的。
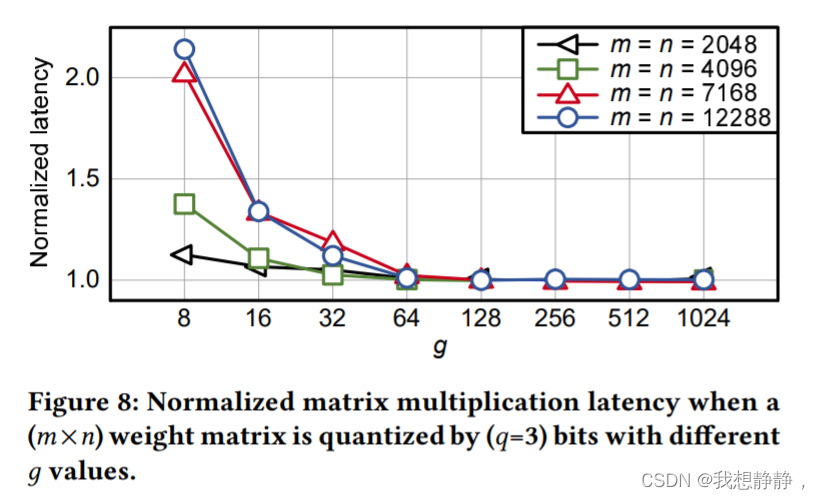
内存占用
为了深入了解图8中的底层机制,我们分析了LUT-GEMM的内存占用,因为单批操作主要是内存受限的,并且延迟与内存占用成正比。设 S b S_b Sb和 S b S_b Sb分别表示二元权值和scale因子的空间复杂度。那么整体空间复杂度𝑆可以描述为
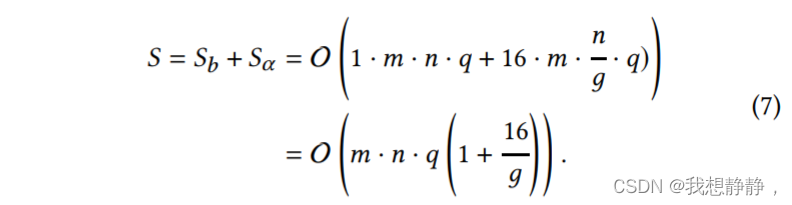
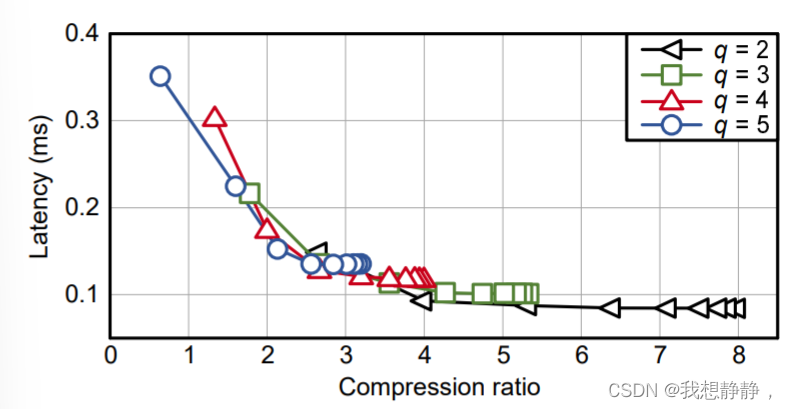
当g >> 16, S可以独立于g,并且近似为O (m·n·q)。为了验证我们的声明,即LUT-GEMM的延迟与内存占用成正比(当运行单批操作时),我们相应地探索了各种(q,g)对和压缩比,并测量了m = n = 12288时的矩阵乘法延迟,如图9所示。可以注意到,附加的搜索参数g允许压缩比的细粒度搜索空间,这是单独使用q无法获得的。在图9中所有可用的压缩比中,延迟是压缩比的函数。
16 1 + 16 g ∗ 1 q = g 0.0625 g + 1 ∗ 1 q \frac{16}{1+\frac{16}{g}} * \frac{1}{q} = \frac{g}{0.0625g + 1} * \frac{1}{q} 1+g1616∗q1=0.0625g+1g∗q1
实验
在本节中,我们将介绍利用LUT-GEMM在各种复杂程度上获得的实验结果,从单层实验设置(不包括组大小)到完整的模型水平。首先,我们研究了LUT-GEMM对特定层的影响,而不考虑群体大小。随后,我们比较了张量平行度与LUT-GEMM,随后研究了组大小的影响。最后,我们分析了OPT模型的端到端延迟[59],以确定LUT-GEMM对性能的总体影响。
Simple Comparisons with Various Kernels
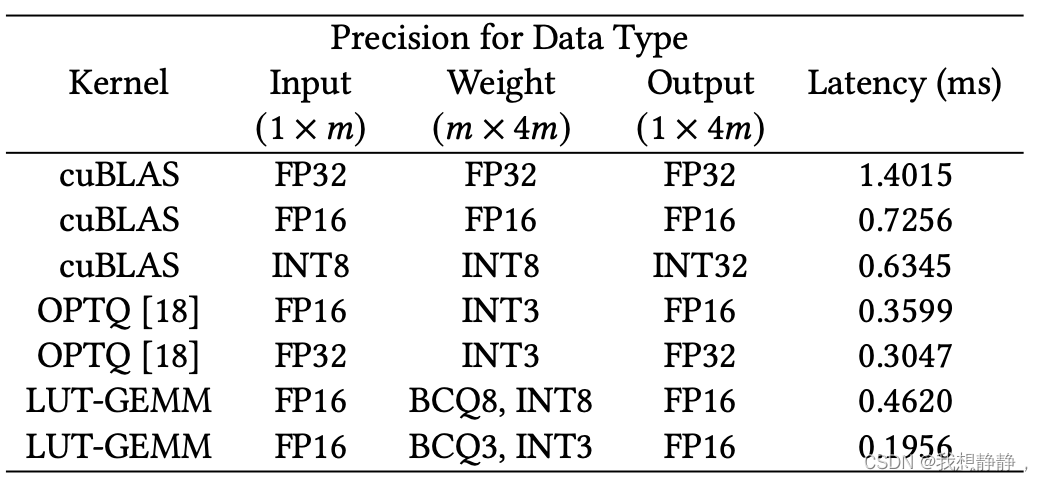
表2给出了OPT-175B模型上前馈神经网络(FFN)第一层的延迟测量[59]。
结果是通过各种输入和权重化方法获得的,包括FP-FP(基线)、INT-INT、FP-INT和FP-BCQ。
选择用于测量的内核包括cuBLAS(用于FP-FP或INT-INT), OPTQ18或LUT-GEMM(用于FP-INT或FP-BCQ)。
注意,OPTQ内核包括去量化过程,然后是GEMM,而LUT-GEMM直接接受逐行量化的权重,而不需要去量化。我们可以观察到,与FP-FP相比,INT8-INT8(带有cuBLAS)实现的延迟仅显示出边际延迟改善,因为cuBLAS没有很好地优化单批操作。与INT8-INT8量化方法相比,OPTQ内核实现了更低的延迟,但由于去量化的开销,它比LUT-GEMM慢。因此,所提出的LUT-GEMM内核在单个内核中同时支持BCQ和INT全化,在所考虑的内核中实现了最低的延迟。
Comparison with FP16 Tensor Parallelism
表3总结了使用cuBLAS(具有张量并行性)或LUT-GE- MM(具有一个GPU)执行矩阵乘法的分析结果。
使用nvidia-smi实用程序收集GPU功耗和其他指标[1,49]。同样,(𝑚×𝑚)矩阵乘以(𝑚× 1)矩阵,其中我们将𝑚设置为8192和12288。这个操作与我们对GPT-3 175B的调查特别相关,其中隐藏的大小是12288。我们将LUT-GEMM的𝑞= 2的情况包括在内,因为据报道,通过量化感知训练和BCQ格式,转换器的2位量化是可行的[12]。
我们注意到,在cuBLAS中使用额外GPU的张量并行性可以显著降低GPU利用率、内存利用率和计算延迟比率。正如通信延迟比的增加所证明的那样,这种利用率的降低表明一些gpu可能暂时空闲,直到所有gpu都同步。因此,张量并行所能获得的加速量远小于gpu的数量。因此,具有更多gpu的cuBLAS会导致矩阵乘法的能量消耗增加。另一方面,LUT-GEMM(使用一个GPU)可以提供高速加速(无法通过张量并行实现),同时保持高GPU/内存利用率。结合低延迟和减少gpu的数量,因此,LUT-GEMM大大节省了矩阵乘法的能量消耗。例如,当𝑚= 12288时,LUT-GEMM(𝑞= 2且只有一个GPU)与cuBLAS相比,能耗降低4.8倍,速度提高6.0倍。
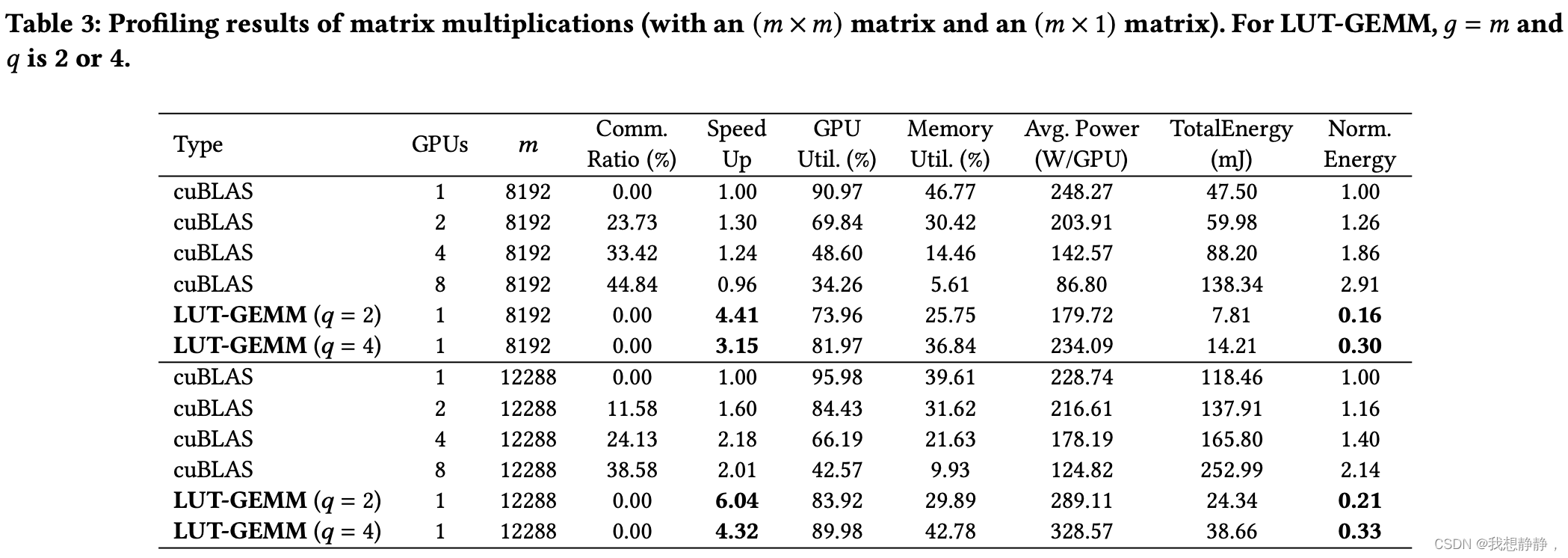
Exploration of Compression Ratio
为了研究群智能BCQ扩大压缩搜索空间的能力,我们在三个预训练的OPT模型上进行了实验[59],这些模型是公开的2。具体来说,我们将训练后量化(使用[54]中引入的迭代求解器)应用于预训练的OPT模型,而𝑔和𝑞各不相同。然后,在LAMBADA[40]数据集上对每个量化模型进行评估,找出压缩比与精度之间的关系。
图10显示了当我们尝试不同的𝑞值和𝑔值时的精度和压缩比3。从图10中,我们观察到,与传统的逐行量化相比,组智能BCQ提供了新的最佳配置(参见附录中的图11,以获得我们的广泛结果)。因此,**为了获得最佳的压缩比(或最小的精度退化),有必要对给定目标同时探索不同的𝑞和𝑔值。**请注意,对于OPT-13B和OPT-30B,正如我们讨论的大规模LMs逐行量化的限制一样,较小的𝑔值对于实现低精度退化至关重要(而较小的𝑔不会严重影响延迟)。总而言之,𝑞和𝑔对精度的影响因模型而异,因此𝑞和𝑔是需要优化的超参数。
端到端延迟
现在,我们用单个批大小评估推理的端到端延迟,在保持完全精度激活的情况下,考虑具有量化权重的各种OPT模型。表4显示了当使用最接近(RTN)方法统一量化权重时,每个令牌的端到端延迟和困惑度。注意,延迟测量是在FasterTransformer框架内进行的。我们利用不同数量的gpu来访问通过模型并行实现的潜在加速增益。从我们在表4中的观察中,我们可以得出以下结论:1)减少组大小(𝑔)有效地减少困惑,即使采用简单的RTN量化方案,代价是延迟的边际增加,2)增加GPU的数量(因此,并行性)不会显着减少延迟,因为各种开销,如GPU到GPU的通信成本,如图4所示。值得一提的是,在LUT-GEMM的情况下,矩阵乘法被加速,相对gpu到gpu的通信与cuBLAS相比变得更加明显。因此,模型并行性对于LUT-GEMM似乎不太有效。换句话说,对于高性能矩阵乘法引擎,通信开销变得更加突出。
在OPT-30B模型的情况下,可以在单个GPU上执行带有FP16权重的端到端推理。然而,对于具有FP16权重的OPT-66B模型,由于模型大小超过单个GPU的内存容量(A100为80GB),因此必须使用模型对等化技术。然而,当OPT-66B模型的权重量化为3或4位时,如[18]中所证明的可行解决方案,推理可以在单个GPU上进行。假设3位量化和𝑔=32的LUT-GEMM的实现,OPT-30B(使用一个GPU)和OPT-66B(使用两个GPU)的加速分别为2.43倍和2.25倍。请注意,我们在表4中对LUT-GEMM性能的演示依赖于基本的训练后量化,而llm的更高级量化方法是可用的。例如,当在构建预训练模型之后进行微调时,如ChatGPT[39]所示,更有效的量化技术如AlphaTuning[29]甚至可以实现2位量化。与先进的量化方法相结合,进一步增强了LUT-GEMM的实用性,减少了量化比特的数量。其他评估结果见附录A.1。
ACCELERATING QUANTIZED OPT-175B
表5提供了在使用fasttransformer框架的具有代表性的大规模LM OPT-175B中生成令牌的端到端延迟的比较。我们评估了三种不同的实现:1)原始的FP16 cuBLAS, 2)与FP16 cuBLAS集成的脱量子化(从3位开始)(使用OPTQ[18]中的库),以及3)LUT-GEMM(假设均匀量子化)。通过只关注前面讨论的四种特定的矩阵乘法,LUT-GEMM证明了它能够减少运行推理所需的gpu数量,同时随着𝑞减少或gpu数量增加而减少延迟。对于带有FP16的OPT-175B,执行推理至少需要8个gpu。然而,在应用BCQ格式进行量化后,LUT-GEMM能够仅使用单个GPU执行推理,同时保持相当的总体延迟。应该注意的是,在比较相同的3位(仅权重和逐行)量化场景时,使用LUT-GEMM生成令牌的延迟比使用LUT-GEMM的延迟低2.1倍OPTQ图书馆。延迟的显著减少主要归因于LUT-GEMM直接接受量化权重的能力,从而消除了去量化的需要。
让我们证明LUT-GEMM的灵活特性(主要归功于扩展的BCQ格式)可以加速现有的均匀量化方法。表6显示了使用OPT- Q方法获得的不同𝑞和𝑔配置下OPT- 175B的困惑度。该表还显示了LUT-GEMM(不包括FP16)实现的相应延迟(每个生成的令牌)。结果清楚地表明,当𝑞减少时,LUT-GEMM提供更低的延迟,尽管过小的𝑔可能有一个边际对延迟的不利影响。总而言之,通过以增加可接受的复杂性为代价集成LUT-GEMM和OPTQ,可以将运行OPT-175B推理所需的GPU数量从8个GPU减少到单个GPU,同时保持高性能。重要的是要注意,当包括去量化时,这种性能的改进是无法实现的。
使用量化权重的上下文处理
如前所述,生成式LM推理包括两个阶段:总结、使用输入上下文和生成,如图3所示。这些阶段需要不同的批量大小。摘要允许并行处理多个令牌,而生成由于其自回归的特性,是一个单批操作。因此,生成LM推理平衡了计算约束(上下文处理的高并行性)和内存约束(生成的低并行性)。我们提出的推理策略包括使用(扩展的)BCQ存储全权权。然后,这些权重:1)在上下文处理阶段进行去量化以执行全精度cuBLAS矩阵乘法,2)在生成阶段用作LUT-GEMM的输入。注意,权重化对于有效使用内存是必不可少的,即使在上下文处理过程中也是如此。此外,由于权重重用率高,上下文处理的去量化延迟相对于生成阶段相对较低。因此,LUT-GEMM是生成阶段的理想方法,因为需要生成更多的令牌(生成LMs的常见需求),它通常占总体推理延迟的主导地位。
我的理解
linear层的计算为Y=WX。经过BCQ量化( ∑ i = 1 q a i b i \sum_{i=1}^qa_ib_i ∑i=1qaibi),可以将W分解成两个 m ∗ n ∗ p m*n*p m∗n∗p 张量A、B。A是scale,B是binary。A和B的点积,沿p维求和的结果就约等于W。即: W i j = ∑ k = 1 p A i j k ∗ B i j k W_{ij} = \sum_{k=1}^{p}A_{ij}^k *B_{ij}^k Wij=k=1∑pAijk∗Bijk

但是不可能为每个元素Wij设置一个scale向量。所以设g个W中的元素(一行中的g个元素)组成一个group,group内共享一个p维的scale向量,同时也会有相应的g*p大小的binary 。为了便于计算,将group中的scale向量复制group份,因此A矩阵与B矩阵和W矩阵的宽高相同。
在计算Y时,先在最外层遍历p,对于第i个位(channel),计算 ( A i 点乘 B i ) ∗ X (Ai点乘Bi)*X (Ai点乘Bi)∗X,累加p次结果,即可获得Y。因此p大于1时,只需要重复内层计算并累加结果即可。 所以下面以p=1为例讲解内层计算过程:
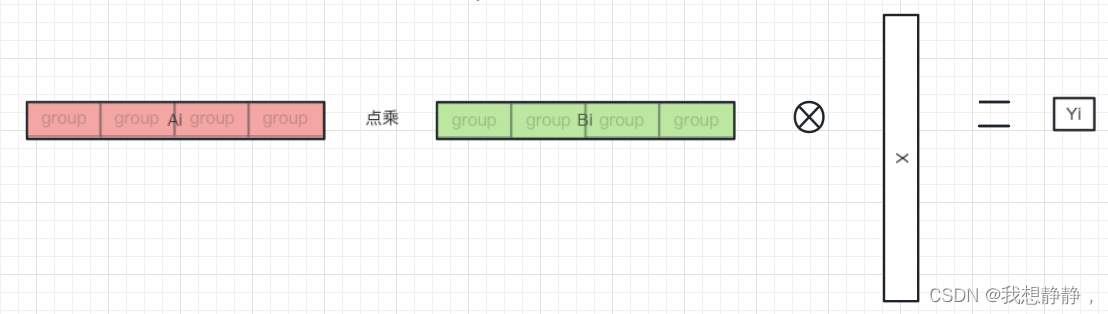
结果Yi 等于
n
g
\frac{n}{g}
gn个((groupA 点乘 groupB) * groupX)的和。由于groupA内的数值完全相同,所以((groupA 点乘 groupB) * groupX)=scale*(groupB * groupX),其中scale是标量,是group中共享的缩放因子。
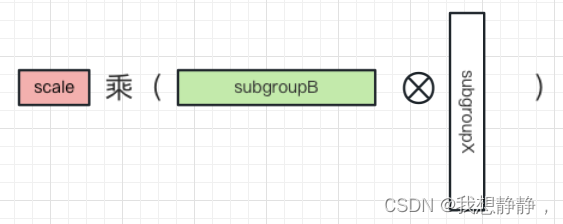
继续对group做细分,令μ个值为一个subgroup,一个group内有 l l l个subgroup。 g = μ ∗ l g = μ*l g=μ∗l,那 g r o u p B ∗ g r o u p X = ∑ l ( s u b g r o u p B ∗ s u b g r o u p X ) groupB*groupX = \sum^{l}(subgroupB*subgroupX) groupB∗groupX=∑l(subgroupB∗subgroupX)。
通常μ=8,由于B中元素是二值,符合二进制,则subgroupB向量 ∈ R 8 \in R^8 ∈R8 刚好可以由一个int8表示。仅需由该int8的每一位与subgroupX相乘即可获得subgroupB*subgroupX结果。
而又因为subgroupB的每一位都是二值,所以 s u b g r o u p B ∗ s u b g r o u p X subgroupB*subgroupX subgroupB∗subgroupX仅有 2 μ 2^μ 2μ个取值,所以可以为subgroupX向量构建查找表T,key是int8数值,value就是 2 μ 2^μ 2μ个结果。这样subgroupB*subgroupX仅需查表 T . g e t ( i n t 8 ( s u b g r o u p B ) ) T.get(int8(subgroupB)) T.get(int8(subgroupB))就能得到结果。将 T . g e t ( i n t 8 ( s u b g r o u p B ) ) T.get(int8(subgroupB)) T.get(int8(subgroupB))与scale相乘即可。
查找表的另一个好处是减少重复计算,在计算BX的过程中,X会与m个二值向量求内积,在这m个内积中,很有可能局部的二进制序列是相同的,也就是内积相同,当使用查找表时,就避免了重复计算内积。
上面讲解了如何用BCQ获取的量化结果在推理时计算linear(WX),整个过程可以被多级细分,即
- 最外层是对p的累加,
- 次外层是对 n g \frac{n}{g} gn个group的累加,
- 内层是对group内 l = g μ l=\frac{g}{\mu} l=μg 个subgroup结果的累加,
- 再内层subgroup是在求scale与subgroupB*subgroupX内积的乘法
- 最内层就是用查找表来求subgroupB*subgroupX
结合论文图说明
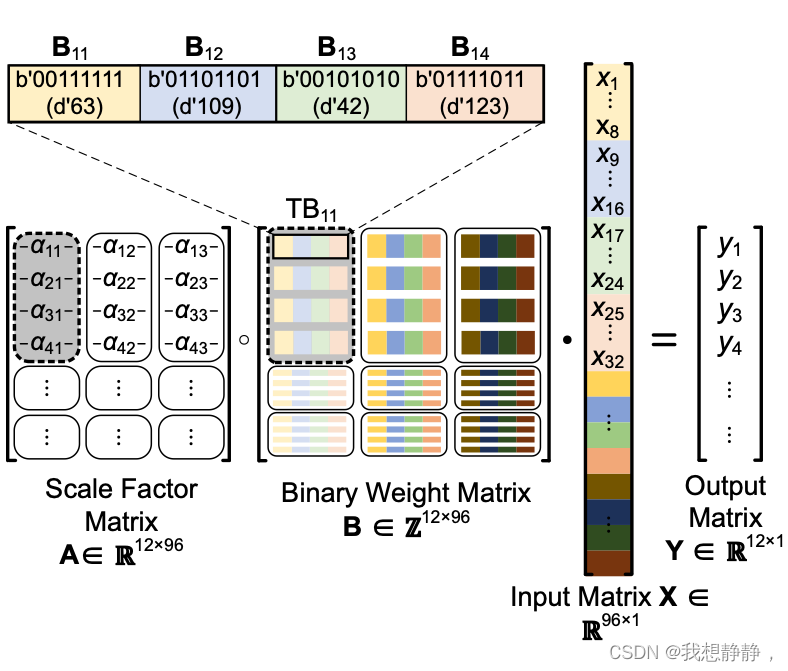
假设: m = 12 , n = 96 , μ = 8 , l = 4 , t w = 32 , t h = 4 , q = 1 , g = 32 m = 12, n = 96,\mu=8,l= 4,t_w= 32,t_h = 4,q= 1,g= 32 m=12,n=96,μ=8,l=4,tw=32,th=4,q=1,g=32。
A、B矩阵大小12*96,group为32,所以可以看到AB矩阵沿n方向分成了三块,a11就是一个groupA(由于在group内scale共享,所以a11也可以看着一个标量),
[B11, B12, B13, B14]是groupB,B11是一个subgroupB二进制向量,大小为μ=8,也就是一个int8,所以groupB内有 l = 4 l=4 l=4个subgroupB。
groupB即[B11, B12, B13, B14]对应求内积的是groupX,即[[x1…8], [x9…x16], [x17…x24], [x25…x32]]。[x1…8]是subgroupX。
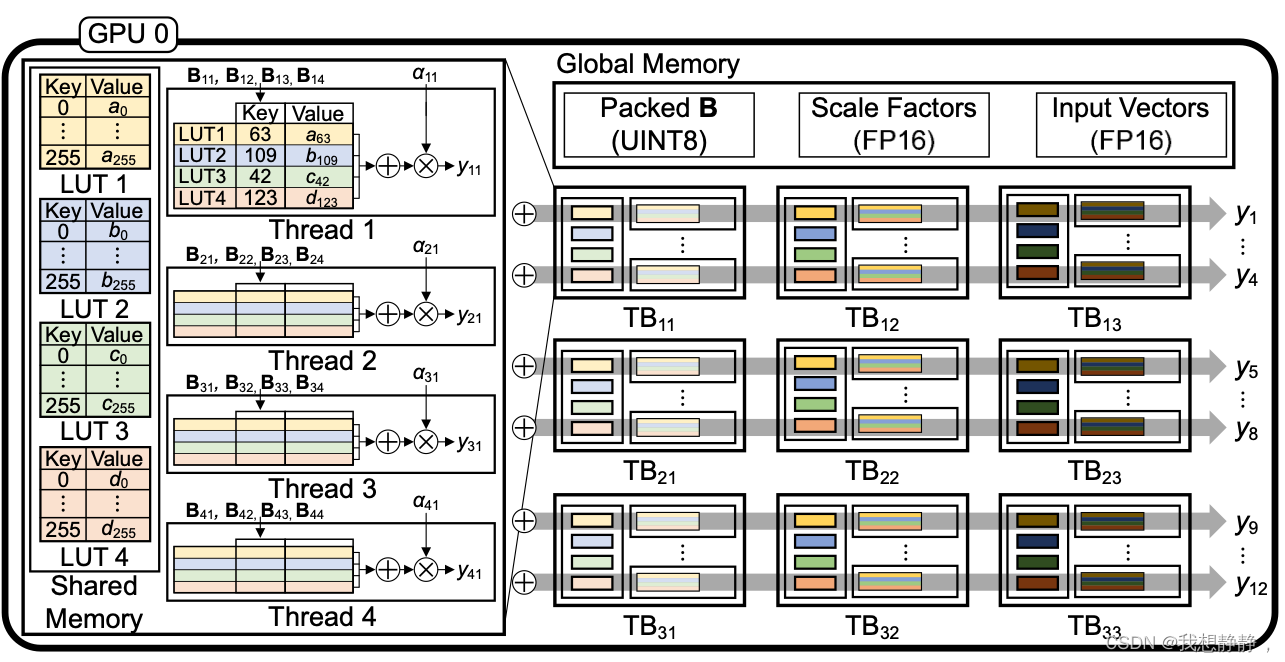
grid的大小是
m
t
h
×
n
g
\frac{m}{t_h} \times \frac{n}{g}
thm×gn(block的数量),每个block即TB处理
t
h
t_h
th个group(比如上图的TB11),一个thread处理一个group,共有
t
h
t_h
th个线程(2048)
- block读取groupX后,计算出 l = g μ = 4 l=\frac{g}{\mu}=4 l=μg=4个[xi…xi+8]的大小为 2 μ 2^\mu 2μ的查询表LUTi,并放置于共享内存。
- 每个thread读取对应行的groupB,就是g bit的二进制数,也就是 l = g μ = 4 l=\frac{g}{\mu}=4 l=μg=4个int8,这 l l l个int8分别从对应的 l l l个查找表中查出 l l l个value,对 l l l个values求和得到[B11, B12, B13, B14]和[[x1…8], [x9…x16], [x17…x24], [x25…x32]]的内积。内积与a11相乘得到y11。
- 以grid中的第一列block看,block中的每个thread执行2的操作,该列block执行完,得到m个y值,但这只是Y的一部分。grid共有 n g \frac{n}{g} gn列block,将这 n g \frac{n}{g} gn个向量求和,就得到了最终的结果。
上面讲解了如何用BCQ获取的量化结果在推理时计算linear(WX),整个过程可以被多级细分,即
- 最外层是对p的累加,
- 次外层是对 n g \frac{n}{g} gn个group的累加,
- 内层是对group内 l = g μ l=\frac{g}{\mu} l=μg 个subgroup结果的累加,
- 再内层subgroup是在求scale与subgroupB*subgroupX内积的乘法
- 最内层就是用查找表来求subgroupB*subgroupX
可以看到,一个thread处理的是第3即内层操作,一个block是多个内层操作的并行,grid中的一行block就是第2即次外层的操作。

















 1926
1926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









