







文末有福利!
【引子】 关于大模型及其应用方面的文章层出不穷,聚焦于自己面对的问题,有针对性的阅读会有很多的启发,本文源自Whyhow.ai 上的一些文字和示例。对于在大模型应用过程中如何使用知识图谱比较有参考价值,特汇总分享给大家。
在基于大模型的RAG应用中,可能会出现不同类型的问题,通过知识图谱的辅助可以在不同阶段增强RAG的效果,并具体说明在每个阶段如何改进答案和查询。知识图谱更类似于结构化数据存储,而不是仅仅是一个用于各种目的的结构化数据的一般存储,可以利用它在 RAG 系统中战略性地注入人类推理。

1. RAG简介
对于复杂的 RAG 和多跳数据检索的一般场景,如下图所示, 关于RAG的更多信息可以参考《[大模型系列——解读RAG]》。
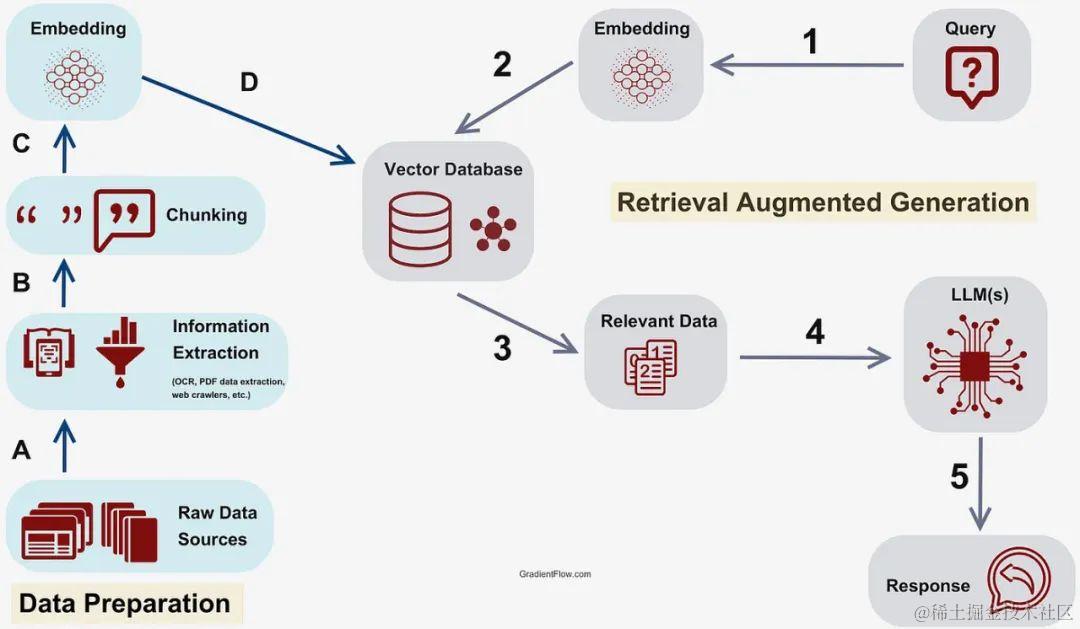
使用上图所示的阶段来介绍知识图谱支持的 RAG 过程中不同的步骤:
- 阶段1——预处理: 这指的是在查询被用于帮助从向量数据库中提取数据块之前对其进行处理
- 阶段2/D——数据块提取: 这是指从数据库中检索最相关的信息块
- 阶段3-5——后处理: 这指的是为准备检索到的信息以生成答案而执行的过程
在不同阶段应该使用哪些知识图谱技术呢?
2.知识图谱在RAG各阶段的应用
2.1 阶段一:查询增强
查询增强是 在从向量数据库中进行检索之前,向查询添加上下文。此策略用于在缺少上下文的情况下增加查询并修复错误查询。这也可以用来注入一个我们的世界观,明确如何定义或看待某些共同或基础术语。
在许多情况下,我们可能对特定术语有自己的世界观。例如,一家旅游科技公司可能希望确保开箱即用 LLM 能够理解“海滨”住宅和“靠近海滩”住宅代表非常不同类型的房产,不能互换使用。在预处理阶段注入这个上下文有助于确保 RAG系统中的这种区别能够提供准确的响应。
从历史上看,知识图谱在企业搜索系统中的一个常见应用是帮助建立首字母缩略词词典,以便搜索引擎能够有效地识别提出的问题或文档/数据存储中的首字母缩略词。这在第一阶段可以用于多跳推理。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









