







Deformable 3D Gaussians
欢迎各位大佬们批评指正,交流沟通;
OmniRe中提到他们参考了DeformableGS来构建非刚体object的构建,所以看了一下DeformableGS论文,论文是去年9月发表,也是紧跟3DGS的工作,当时对整个结构的改动不是特别大,主要贡献就是在原版上面加入了一个MLP用于二次优化部分高斯属性;
代码地址:https://github.com/ingra14m/Deformable-3D-Gaussians
论文解读
这篇论文介绍了一种名为Deformable 3D Gaussians的方法,用于从单目动态场景中重建高保真度的三维几何结构,并能够渲染出高质量的图像。该方法在新颖视角合成和时间插值任务中均能实现优秀的性能。
- 方法介绍:提出了一种可变形的3D高斯散射方法,通过在规范空间中学习3D高斯,并使用变形场来模拟单目动态场景。
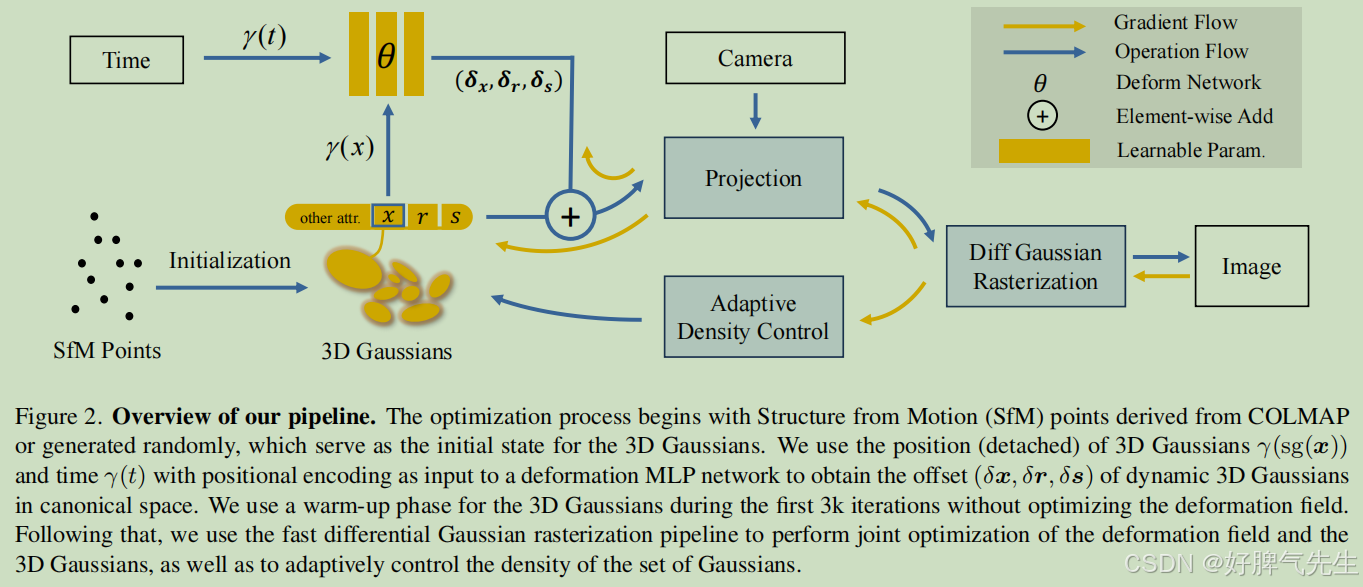
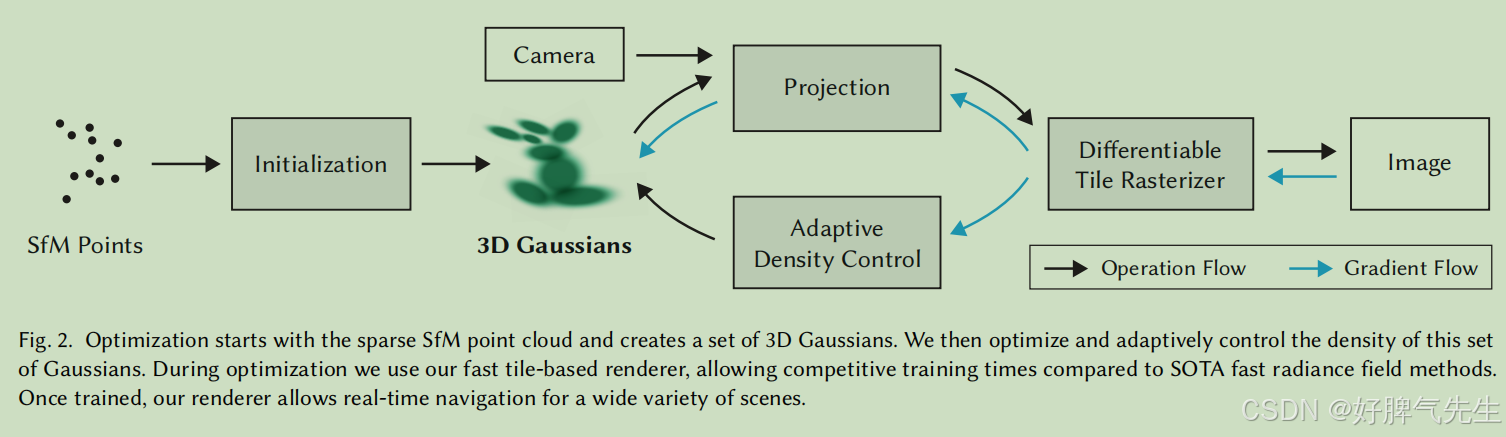
此处放上3DGS的流程图作为对比;
主要贡献有两个
- 变形场:通过一个变形网络,将3D高斯的位置和当前时间作为输入,输出3D高斯的位移、旋转和缩放的偏移量。
- 退火平滑训练机制(Annealing Smooth Training, AST):引入了一种新的训练机制,可以在不增加额外计算负担的情况下,减轻不准确位姿对时间插值任务的影响。
代码分析
- 在3DGS基础上增加了一个MLP来重新计算位置,rot和scale的高斯属性,以此来适应动态场景的变化;MLP的输入就是时间和经过3DGS优化的高斯属性;下面看一下代码中如何调用这个模型的,从
training函数开始看起
def training(dataset, opt, pipe, testing_iterations, saving_iterations):
tb_writer = prepare_output_and_logger(dataset)
gaussians = GaussianModel(dataset.sh_degree)
# 初始化MLP模型
deform = DeformModel(dataset.is_blender, dataset.is_6dof)
deform.train_setting(opt)
# 下面的代码和3DGS基本一致,不再赘述
scene = Scene(dataset, gaussians)
gaussians.training_setup(opt)
bg_color = [1, 1, 1] if dataset.white_background else [0, 0, 0]
background = torch.tensor(bg_color, dtype=torch.float32, device="cuda")
iter_start = torch.cuda.Event(enable_timing=True)
iter_end = torch.cuda.Event(enable_timing=True)
viewpoint_stack = None
ema_loss_for_log = 0.0
best_psnr = 0.0
best_iteration = 0
progress_bar = tqdm(range(opt.iterations), desc="Training progress")
# 对应文章中的公式6的后一个公式的参数设置,get_linear_noise_func这个函数和3DGS中基本一致,不再赘述
smooth_term = get_linear_noise_func(lr_init=0.1, lr_final=1e-15, lr_delay_mult=0.01, max_steps=20000)
for iteration in range(1, opt.iterations + 1):
if network_gui.conn == None:
network_gui.try_connect()
while network_gui.conn != None:
try:
net_image_bytes = None
custom_cam, do_training, pipe.do_shs_python, pipe.do_cov_python, keep_alive, scaling_modifer = network_gui.receive()
if custom_cam != None:
net_image = render(custom_cam, gaussians, pipe, background, scaling_modifer)["render"]
net_image_bytes = memoryview((torch.clamp(net_image, min=0, max=1.0) * 255).byte().permute(1, 2,
0).contiguous().cpu().numpy())
network_gui.send(net_image_bytes, dataset.source_path)
if do_training and ((iteration < int(opt.iterations)) or not keep_alive):
break
except Exception as e:
network_gui.conn = None
iter_start.record()
# Every 1000 its we increase the levels of SH up to a maximum degree
if iteration % 1000 == 0:
gaussians.oneupSHdegree()
# Pick a random Camera
if not viewpoint_stack:
viewpoint_stack = scene.getTrainCameras().copy()
total_frame = len(viewpoint_stack)
time_interval = 1 / total_frame
viewpoint_cam = viewpoint_stack.pop(randint(0, len(viewpoint_stack) - 1))
if dataset.load2gpu_on_the_fly:
viewpoint_cam.load2device()
fid = viewpoint_cam.fid
# 这里开始和原版有些区别,此处调用了deform对高斯模型的结果进行再次优化;
if iteration < opt.warm_up:
d_xyz, d_rotation, d_scaling = 0.0, 0.0, 0.0
else:
N = gaussians.get_xyz.shape[0]
time_input = fid.unsqueeze(0).expand(N, -1)
# 对应文章中的公式6的后一个公式,
ast_noise = 0 if dataset.is_blender else torch.randn(1, 1, device='cuda').expand(N, -1) * time_interval * smooth_term(iteration)
# step对应文章中的公式6的前一个公式,输入pos、时间和AST噪声的混合值给DeformModel;
d_xyz, d_rotation, d_scaling = deform.step(gaussians.get_xyz.detach(), time_input + ast_noise)
# Render
render_pkg_re = render(viewpoint_cam, gaussians, pipe, background, d_xyz, d_rotation, d_scaling, dataset.is_6dof)
image, viewspace_point_tensor, visibility_filter, radii = render_pkg_re["render"], render_pkg_re[
"viewspace_points"], render_pkg_re["visibility_filter"], render_pkg_re["radii"]
# depth = render_pkg_re["depth"]
# Loss
gt_image = viewpoint_cam.original_image.cuda()
Ll1 = l1_loss(image, gt_image)
loss = (1.0 - opt.lambda_dssim) * Ll1 + opt.lambda_dssim * (1.0 - ssim(image, gt_image))
loss.backward()
iter_end.record()
if dataset.load2gpu_on_the_fly:
viewpoint_cam.load2device('cpu')
# ...no_grad部分还是致密化,过程report等部分...
with torch.no_grad():
# Progress bar
ema_loss_for_log = 0.4 * loss.item() + 0.6 * ema_loss_for_log
if iteration % 10 == 0:
progress_bar.set_postfix({"Loss": f"{ema_loss_for_log:.{7}f}"})
progress_bar.update(10)
if iteration == opt.iterations:
progress_bar.close()
# Keep track of max radii in image-space for pruning
gaussians.max_radii2D[visibility_filter] = torch.max(gaussians.max_radii2D[visibility_filter],
radii[visibility_filter])
# Log and save
cur_psnr = training_report(tb_writer, iteration, Ll1, loss, l1_loss, iter_start.elapsed_time(iter_end),
testing_iterations, scene, render, (pipe, background), deform,
dataset.load2gpu_on_the_fly, dataset.is_6dof)
if iteration in testing_iterations:
if cur_psnr.item() > best_psnr:
best_psnr = cur_psnr.item()
best_iteration = iteration
if iteration in saving_iterations:
print("\n[ITER {}] Saving Gaussians".format(iteration))
scene.save(iteration)
deform.save_weights(args.model_path, iteration)
# Densification
if iteration < opt.densify_until_iter:
viewspace_point_tensor_densify = render_pkg_re["viewspace_points_densify"]
gaussians.add_densification_stats(viewspace_point_tensor_densify, visibility_filter)
if iteration > opt.densify_from_iter and iteration % opt.densification_interval == 0:
size_threshold = 20 if iteration > opt.opacity_reset_interval else None
gaussians.densify_and_prune(opt.densify_grad_threshold, 0.005, scene.cameras_extent, size_threshold)
if iteration % opt.opacity_reset_interval == 0 or (
dataset.white_background and iteration == opt.densify_from_iter):
gaussians.reset_opacity()
# Optimizer step
if iteration < opt.iterations:
gaussians.optimizer.step()
gaussians.update_learning_rate(iteration)
deform.optimizer.step()
gaussians.optimizer.zero_grad(set_to_none=True)
deform.optimizer.zero_grad()
deform.update_learning_rate(iteration)
print("Best PSNR = {} in Iteration {}".format(best_psnr, best_iteration))
- 模型结构,从
DeformModel这个类进入,整个网络结构是DeformNetwork定义的;从初始化函数中看到符合论文中的设置,深度8,隐藏层256;
class DeformNetwork(nn.Module):
def __init__(self, D=8, W=256, input_ch=3, output_ch=59, multires=10, is_blender=False, is_6dof=False):
super(DeformNetwork, self).__init__()
self.D = D # 网络深度
self.W = W # 网络宽度,每一层的神经元个数
self.input_ch = input_ch # 输入通道
self.output_ch = output_ch # 输出通道
self.t_multires = 6 if is_blender else 10 # 时间频率
self.skips = [D // 2] # 跳跃链接的层位置
self.embed_time_fn, time_input_ch = get_embedder(self.t_multires, 1) # 时间嵌入编码,得到嵌入编码的函数和输入通道数
self.embed_fn, xyz_input_ch = get_embedder(multires, 3) # 空间位置嵌入编码,
self.input_ch = xyz_input_ch + time_input_ch
if is_blender: # 这个变量一直为True
# Better for D-NeRF Dataset
self.time_out = 30
# 时间网络将时间嵌入设置为30维
self.timenet = nn.Sequential(
nn.Linear(time_input_ch, 256), nn.ReLU(inplace=True),
nn.Linear(256, self.time_out))
# 全连接层,将时间和空间一起处理
self.linear = nn.ModuleList(
[nn.Linear(xyz_input_ch + self.time_out, W)] + [
nn.Linear(W, W) if i not in self.skips else nn.Linear(W + xyz_input_ch + self.time_out, W)
for i in range(D - 1)]
)
else:
self.linear = nn.ModuleList(
[nn.Linear(self.input_ch, W)] + [
nn.Linear(W, W) if i not in self.skips else nn.Linear(W + self.input_ch, W)
for i in range(D - 1)]
)
self.is_blender = is_blender
self.is_6dof = is_6dof
# 如果是6自由度,分别处理旋转和平移
if is_6dof:
self.branch_w = nn.Linear(W, 3)
self.branch_v = nn.Linear(W, 3)
else:
self.gaussian_warp = nn.Linear(W, 3)
self.gaussian_rotation = nn.Linear(W, 4)
self.gaussian_scaling = nn.Linear(W, 3)
def forward(self, x, t):
t_emb = self.embed_time_fn(t) # 时间t嵌入特征空间,并经过时间网络处理
if self.is_blender:
t_emb = self.timenet(t_emb) # better for D-NeRF Dataset
x_emb = self.embed_fn(x) # 位置嵌入
h = torch.cat([x_emb, t_emb], dim=-1) # 时空链接
for i, l in enumerate(self.linear):
h = self.linear[i](h) # 线性层特征提取
h = F.relu(h) # RELU函数激活
if i in self.skips: # 在跳跃链接的指定层进行链接
h = torch.cat([x_emb, t_emb, h], -1)
# 如果需要优化6自由度,将采用旋转轴方法进行计算,中间采用李群李代数进行处理,生成最终的变化量
if self.is_6dof:
w = self.branch_w(h)
v = self.branch_v(h)
theta = torch.norm(w, dim=-1, keepdim=True)
w = w / theta + 1e-5
v = v / theta + 1e-5
screw_axis = torch.cat([w, v], dim=-1)
d_xyz = exp_se3(screw_axis, theta)
else:
d_xyz = self.gaussian_warp(h)
scaling = self.gaussian_scaling(h)
rotation = self.gaussian_rotation(h)
return d_xyz, rotation, scaling
- 时间和空间嵌入编码的实现
def get_embedder(multires, i=1):
# multires 表示多分辨率结果
if i == -1:
return nn.Identity(), 3
embed_kwargs = {
'include_input': True,
'input_dims': i,
'max_freq_log2': multires - 1,
'num_freqs': multires,
'log_sampling': True,
'periodic_fns': [torch.sin, torch.cos], # 周期函数
}
embedder_obj = Embedder(**embed_kwargs) # 嵌入函数初始化
embed = lambda x, eo=embedder_obj: eo.embed(x)
return embed, embedder_obj.out_dim
class Embedder:
def __init__(self, **kwargs):
self.kwargs = kwargs
self.create_embedding_fn()
def create_embedding_fn(self):
embed_fns = []
d = self.kwargs['input_dims']
out_dim = 0
if self.kwargs['include_input']:
embed_fns.append(lambda x: x)
out_dim += d
max_freq = self.kwargs['max_freq_log2']
N_freqs = self.kwargs['num_freqs']
if self.kwargs['log_sampling']:
freq_bands = 2. ** torch.linspace(0., max_freq, steps=N_freqs)
else:
freq_bands = torch.linspace(2. ** 0., 2. ** max_freq, steps=N_freqs)
# 这里对应文章公式5,构建嵌入编码函数,应该是一系列函数,对应不同的L
for freq in freq_bands:
for p_fn in self.kwargs['periodic_fns']:
embed_fns.append(lambda x, p_fn=p_fn, freq=freq: p_fn(x * freq))
out_dim += d
self.embed_fns = embed_fns
self.out_dim = out_dim
def embed(self, inputs):
# 将嵌入编码矩阵进行拼接
return torch.cat([fn(inputs) for fn in self.embed_fns], -1)
小结
在OmniRe中DeformableNodes和DeformableGS的代码一致,去掉了对6自由度的计算,只计算Object的平移变化量,这也和OmniRe论文中的思想一致,在实际工作中我们也发现只优化trans对动态场景有提高,如果加入旋转一起优化,整体表现会下降,也是很迷惑的一件事;
论文的主要贡献代码基本解读完成,综合来看文章增加的变形场模型还是有较大的效果;**我个人认为核心思想在于将位姿的优化放到重建过程中来进行,一定程度上抵消了输入数据在标定和pose上面的误差,最后的效果有了较大收益;**由于场景重建更关注相对位姿,所以训练过程产生的位姿可能和真值相去甚远,这个位姿就是保证了重建的效果;
参考资料
- https://blog.csdn.net/u014090429/article/details/112618607:
Sequential是按顺序执行,ModuleList执行顺序取决于forward里面定义的顺序,Sequential也可以指定单独执行某一层;


















 2276
2276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









