









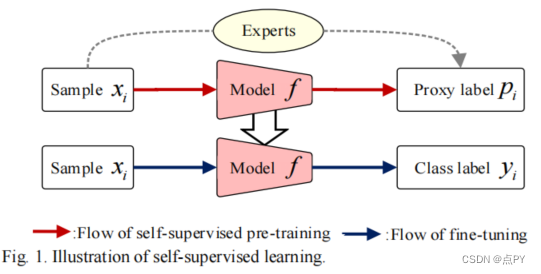
 这篇博客探讨了知识转移在深度学习中的应用,特别是在模型压缩和迁移学习中的作用。文章介绍了多个研究,如自监督学习框架、概率知识转移、神经元选择性转移和结构化知识转移,展示了如何通过这些方法提升模型性能,减少计算资源需求。这些方法在图像分类、对象检测、人群计数等任务中表现出色,同时提供了开源实现供进一步研究。
这篇博客探讨了知识转移在深度学习中的应用,特别是在模型压缩和迁移学习中的作用。文章介绍了多个研究,如自监督学习框架、概率知识转移、神经元选择性转移和结构化知识转移,展示了如何通过这些方法提升模型性能,减少计算资源需求。这些方法在图像分类、对象检测、人群计数等任务中表现出色,同时提供了开源实现供进一步研究。
2018
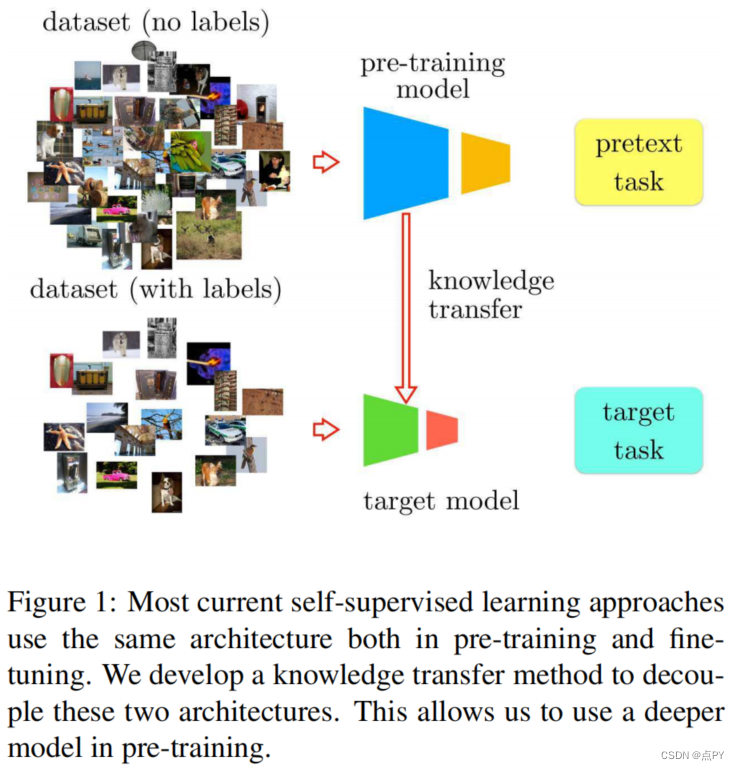
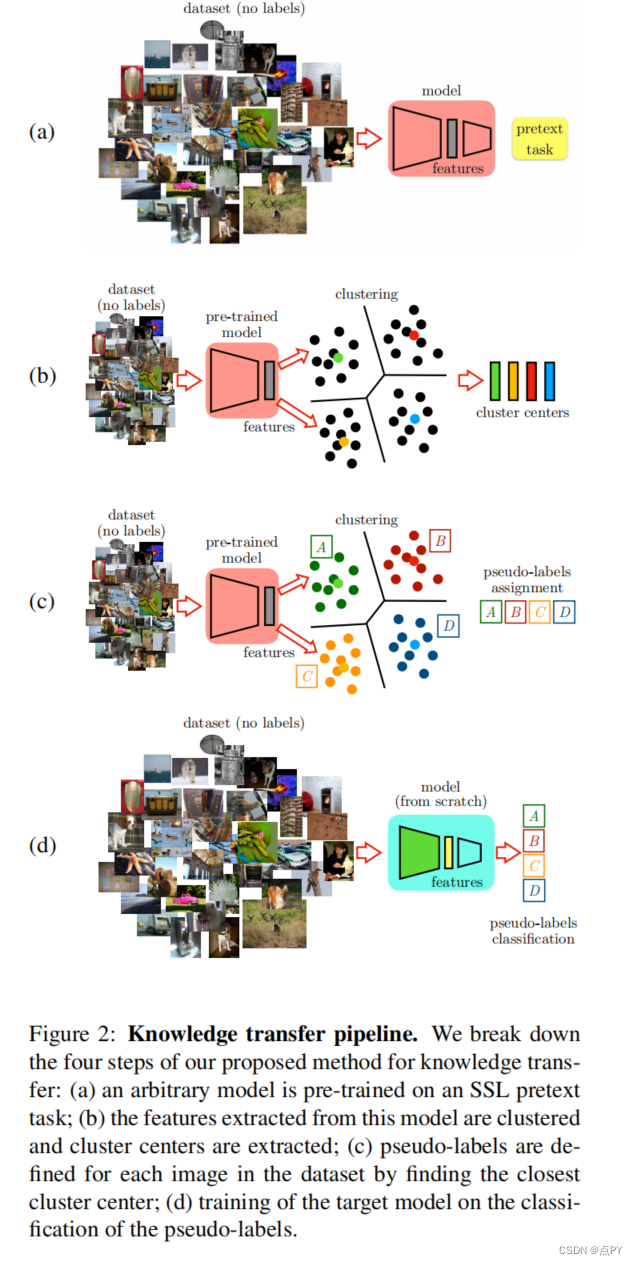
Boosting Self-Supervised Learning via Knowledge Transfer
摘要:在自监督学习中,人们训练一个模型来解决数据集上所谓的借口任务,而不需要人工注释。然而,其主要目标是将这个模型转移到一个目标领域和任务中。目前,最有效的转移策略是微调,这限制了人们在借口任务和目标任务中同时使用相同的模型或该模型的部分任务。在本文中,我们提出了一个新的自监督学习框架,它克服了在设计和比较不同的任务、模型和数据领域时的局限性。特别是,我们的框架将自监督模型的结构与最终的特定于任务的微调模型解耦。这使得我们可以: 1)定量评估以前不兼容的模型,包括手工制作的特征;2)表明更深的神经网络模型可以从相同的借口任务中学习更好的表示;3)将深度模型学习到的知识转移到较浅的模型,从而提高其学习能力。我们使用这个框架设计了一个新的自我监督任务,它在PASCAL VOC 2007、ILSVRC12和Places的公共基准上取得了最先进的性能。在PASCAL VOC 2007上,我们的学习特征将通过自监督学习和监督学习训练的模型之间的mAP差距从5.9%缩小到2.6%。
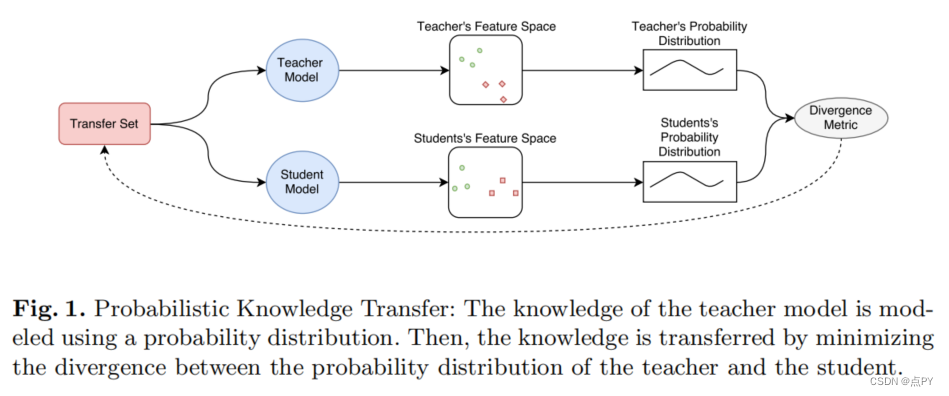
Learning Deep Representations with Probabilistic Knowledge Transfer(ECCV)
code: https://paperswithcode.com/paper/learning-deep-representations-with
摘要: 知识转移(Knowledge Transfer, KT)技术解决了将知识从一个大型而复杂的神经网络转移到一个更小而更快的神经网络的问题。然而,现有的KT方法是针对分类任务量身定制的,它们不能有效地用于其他表示学习任务。本文提出了一种新的概率知识转移方法,该方法是匹配数据在特征空间中的概率分布,而不是它们的实际表示。除了优于现有KT技术,提出的方法允许克服的局限性提供新的见解KT以及小说KT应用程序,从KT从手工制作的特性提取器跨模式KT从文本模式到表示从视觉模式中提取的数据。
2019
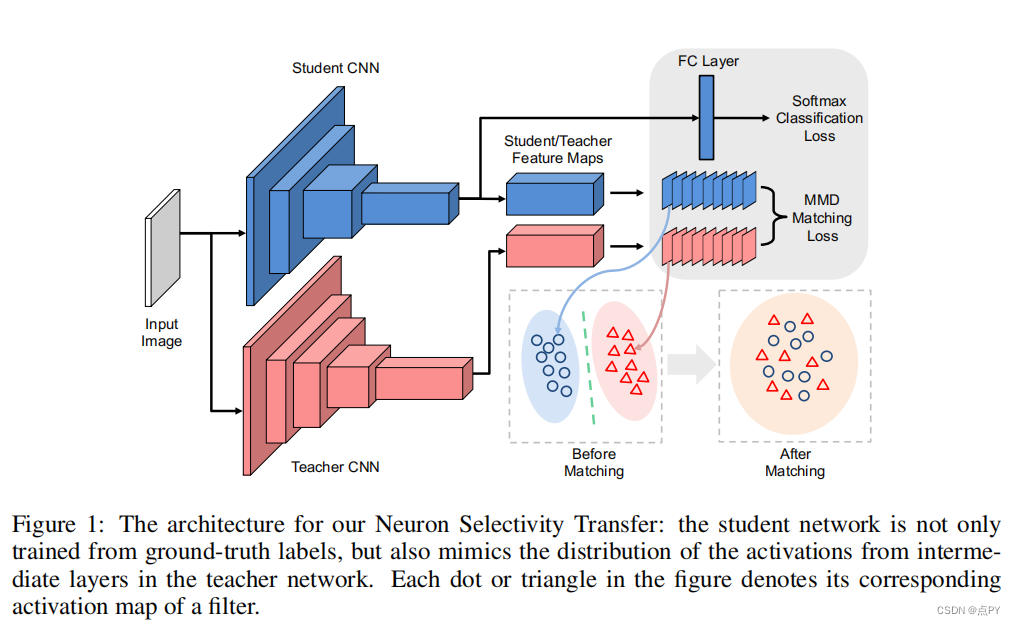
LIKE WHAT YOU LIKE: KNOWLEDGE DISTILL VIA NEURON SELECTIVITY TRANSFER
code: https://paperswithcode.com/paper/like-what-you-like-knowledge-distill-via
摘要: 尽管深度神经网络在各种应用中都表现出了非凡的能力,但它们优越的性能是以牺牲高存储和计算成本为代价的。因此,神经网络的加速和压缩问题最近引起了人们的广泛关注。知识转移(KT)是一种流行的解决方案之一,它旨在通过从较大的教师模式转移知识来培训较小的学生网络。本文提出了一种新的知识转移方法,并将其作为一个分布匹配问题来处理。特别地,我们匹配了教师和学生网络之间的神经元选择性模式的分布。为了实现这一目标,我们设计了一个新的KT损失函数,通过最小化这些分布之间的最大平均差异(MMD)度量。结合原始的损失函数,我们的方法可以显著提高学生网络的性能。我们在几个数据集上验证了我们的方法的有效性,并进一步将其与其他KT方法结合起来,以探索可能的最佳结果。最后但并非最不重要的是,我们对模型调整到其他任务,如对象检测。结果也令人鼓舞,这证实了学习特征的可转移性。
论文的贡献:
- 本文提出了一种关于知识传递问题的新观点,并提出了一种用于网络加速和压缩的神经元选择性传递(NST)的新方法。
- 我们在几个数据集上测试了我们的方法,并提供证据,表明我们的神经元选择性转移比学生取得了更高的表现。
- 我们证明了我们提出的方法可以与其他知识转移方法相结合,以探索最佳的模型加速和压缩结果。
- 我们演示了知识转移有助于学习更好的特征,而其他计算机视觉任务,如目标检测也可以从中受益。
2020
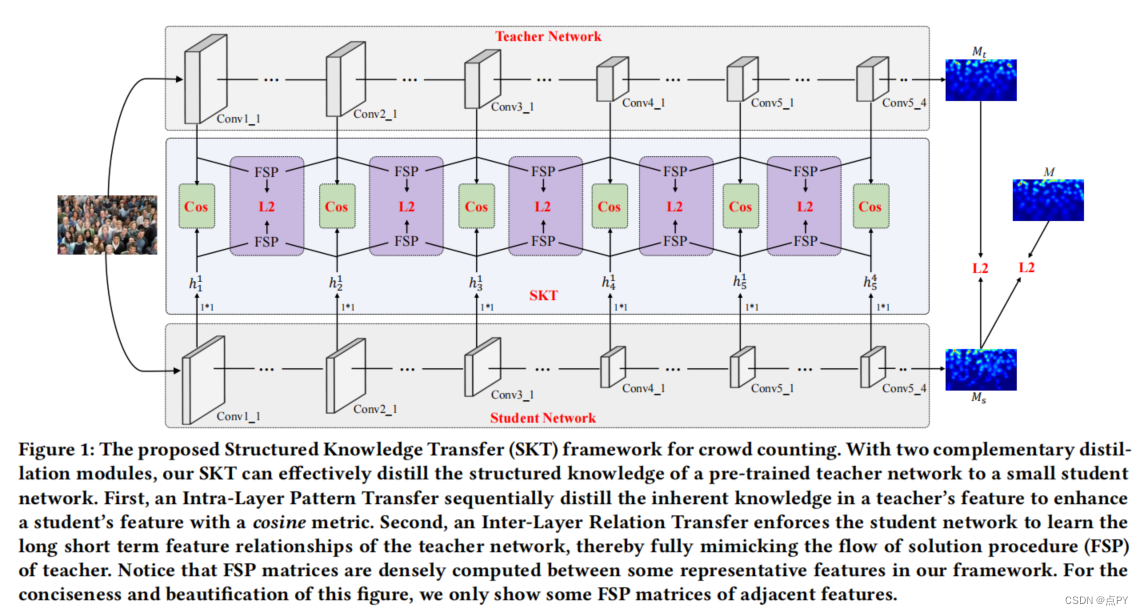
Efficient Crowd Counting via Structured Knowledge Transfer
code: https://paperswithcode.com/paper/efficient-crowd-counting-via-structured
摘要: 群计数是一项面向应用程序的任务,其推理效率对现实应用程序至关重要。然而,以前的大多数工作依赖于重主干网络,需要禁止的运行时消耗,这将严重限制其部署范围,并导致较差的可伸缩性。为了解放这些人群计数模型,我们提出了一个新的结构化知识转移(SKT)框架,该框架充分利用一个训练有素的教师网络的结构化知识来生成一个轻量级但仍然高效的学生网络。具体来说,它集成了两个互补的转移模块,包括一个层内模式转移顺序提取知识嵌入分层特征教师网络的特征学习学生网络和层间关系转移密集提取教师的跨层相关知识规范学生的特征进化。因此,我们的学生网络可以从教师网络中获得分层和跨层的知识,来学习紧凑而有效的特征。对三个基准的广泛评估很好地证明了我们的SKT对广泛的人群计数模型的有效性。特别是,仅使用原始模型约6%的参数和计算成本,我们蒸馏的基于VGG的模型在Nvidia 1080 GPU上获得了至少6.5×的加速,甚至达到了最先进的性能。
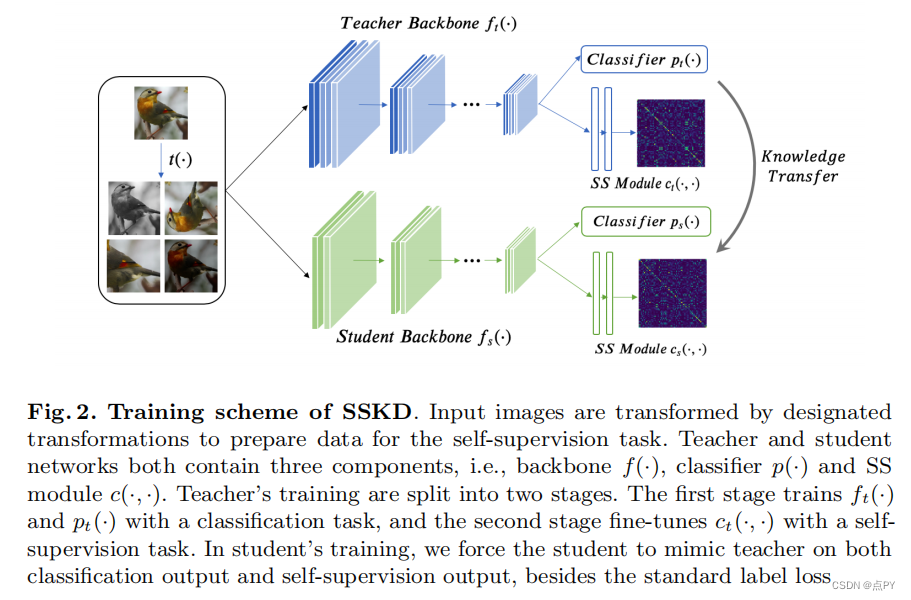
Knowledge Distillation Meets Self-Supervision
code: https://github.com/xuguodong03/SSKD
摘要:知识蒸馏是指从教师网络中提取“暗知识”来指导学生网络的学习,已成为模型压缩和迁移学习的重要技术。不同于以往的工作,利用架构特定的线索,如激活和注意力进行蒸馏,在这里,我们希望探索一种更一般和模型无关的方法,从预先训练的教师模型中提取“更丰富的黑暗知识”。我们表明,看似不同的自我监督任务可以作为一个简单而强大的解决方案。例如,当在转换后的实体之间进行对比学习时,教师网络的噪声预测反映了其语义和姿态信息的内在组成。利用这些自我监督信号之间的相似性作为辅助任务,可以有效地将隐藏的信息从老师传递给学生。本文讨论了利用这些具有选择性转移的噪声自监督信号进行蒸馏的实际方法。我们进一步表明,在少镜头和噪声标记的情况下,自监督信号改善了常规蒸馏,具有实质性的增益。由于从自我监督中挖掘出更丰富的知识,我们的知识蒸馏方法在标准基准结构和跨架构设置下,即CIFAR100和ImageNet,实现了最先进的性能。在跨架构设置下,这种优势更加明显,我们的方法在6对不同的CIFAR100上的平均准确率平均高出2.3%。
2021
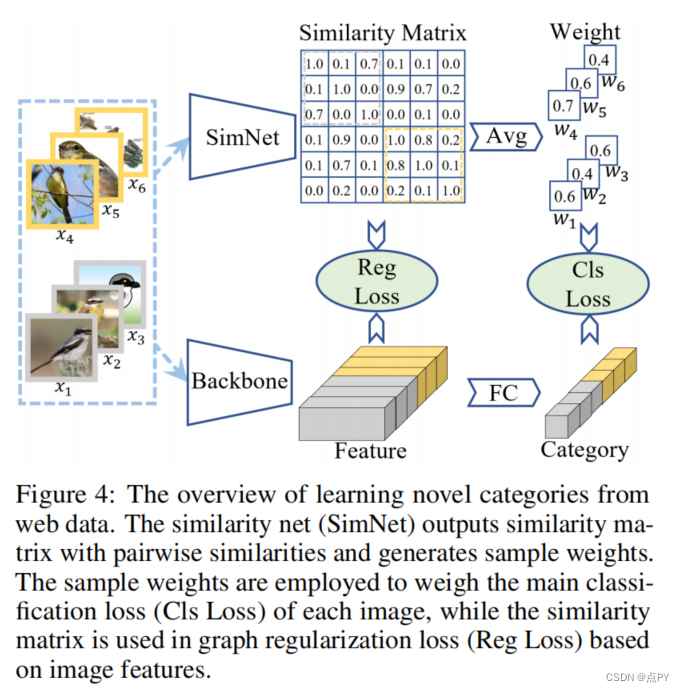
Weak-shot Fine-grained Classification via Similarity Transfer
code: https://github.com/bcmi/SimTransWeak-Shot-Classification
摘要:识别细粒度的类别仍然是一项具有挑战性的任务,因为不同的从属类别之间的细微差别,这导致了需要丰富的注释样本。为了缓解对数据匮乏的问题,我们考虑了在支持一组干净的基本类别的情况下从web数据中学习新类别的问题,这被称为弱射击学习。在这种情况下,我们提出了一种称为SimTrans的方法,将成对的语义相似度从基本类别转移到新的类别。具体来说,我们首先在干净的数据上训练一个相似度网,然后利用转移的相似度,使用两种简单而有效的策略对网络训练数据进行去噪。此外,我们在相似度网上应用对抗性损失来提高相似度的可转移性。综合的实验证明了我们的弱镜头设置和我们的模拟变换方法的有效性。
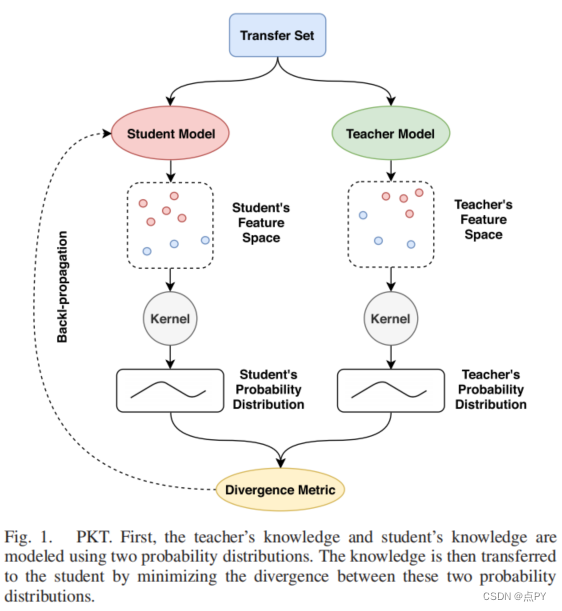
Probabilistic Knowledge Transfer for Lightweight Deep Representation Learning
摘要: 知识转移(KT)方法允许将一个大型深度学习模型中包含的知识转移到一个更轻量级和更快的模型中。然而,现有的绝大多数KT方法主要被设计用于处理分类和检测任务。这限制了他们在其他任务上的表现,如表示/度量学习。为了克服这一限制,本文提出了一种新的概率KT(PKT)方法。PKT能够通过保存尽可能多的信息,将知识转移到一个更小的学生模型中,就像通过教师模型所表达的那样。该方法能够使用不同的内核来估计教师和学生模型的概率分布,以及可用于传递知识的不同散度度量,允许方便地将所提出的方法适应不同的应用。PKT优于现有的几种最先进的KT技术,同时它能够通过启用几个新的应用程序来提供对KT的新见解,正如它是通过在几个具有挑战性的数据集上的广泛实验得到证明的那样。
Beyond Self-Supervision: A Simple Yet Effective Network Distillation Alternative to Improve Backbones
code: https://github.com/bytedance/next-vit
摘要:近年来,研究主要集中在揭示预训练模型对神经网络性能的影响上。自我监督和半监督学习技术已经被社区广泛探索,并被证明在获得一个强大的预训练模型方面具有巨大的潜力。然而,这些模型需要巨大的训练成本(即,数亿张图像或训练迭代)。在本文中,我们提出通过从现有的预先训练过的大型强大模型中进行知识蒸馏来改进现有的基线网络。现有的知识蒸馏框架要求学生模型与教师模型生成的软标签和人类标注的硬标签保持一致,我们的解决方案只通过驱动与教师模型一致的学生模型预测来进行蒸馏。因此,我们的蒸馏设置可以摆脱手工标记的数据,并可以用额外的未标记数据进行训练,以充分利用教师模型的能力,以更好地学习。根据经验,这种简单的蒸馏设置非常有效,例如,MobileNetV3大和ResNet50-D的ImageNet-1k验证集的前1精度可以分别从75.2%提高到79%和79.1%提高到83%。我们还彻底分析了影响蒸馏性能的主要因素,以及它们如何产生影响。广泛的下游计算机视觉任务,包括迁移学习、目标检测和语义分割,可以显著受益于提炼的预训练模型。
2022
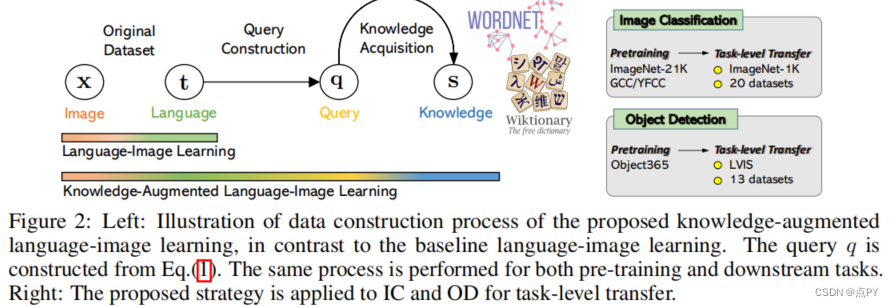
K-LITE: Learning Transferable Visual Models with External Knowledge
摘要: 新一代最先进的计算机视觉系统是从自然语言监督训练而来的,从简单的对象类别名称到描述性字幕。这种形式的监督确保了学习到的视觉模型的高通用性和可用性,因为通过大规模的数据收集过程实现了广泛的概念覆盖。另外,我们认为使用外部知识进行学习是一种很有前途的方法,它利用了更结构化的监督来源,并提供了样本效率。我们提出了K-LITE1,一种简单的策略来利用外部知识来构建可转移的视觉系统:在训练中,它用WordNet和维基词典知识丰富了文本中的实体,从而产生了一种高效和可扩展的方法来学习使用关于视觉概念的知识的图像表示。在评估中,文本还增加了外部知识,然后用于参考学习到的视觉概念(或描述新的概念),以使预训练模型的零射击和少射击转移。我们研究了K-LITE在两个重要的计算机视觉问题上的性能,即图像分类和目标检测,并分别对20个和13个不同的现有数据集进行了基准测试。与现有方法相比,所提出的知识增强模型在迁移学习性能方面有显著提高。
Prior Knowledge-Augmented Self-Supervised Feature Learning for Few-shot Intelligent Fault Diagnosis of Machines
摘要:数据驱动的智能诊断模型期望从大量的监测数据中挖掘机器的健康信息。然而,在工程场景中收集的故障监测数据的规模有限,这导致了少镜头故障诊断成为一个有价值的研究点。幸运的是,通过将先前的诊断知识集成到诊断模型中,可以减少所需的训练数据量。受此启发,我们提出了一个用于少镜头故障诊断的先验知识增强自监督特征学习框架。在该框架中,构建了24个信号特征指标,基于现有的诊断知识形成先验特征集。此外,还使用卷积自动编码器来挖掘一般特征,这些特征被认为可能包含先前特征不具备的故障信息。我们设计了一个自监督学习方案来训练诊断模型,使模型能够学习先验特征和一般特征。因此,该模型有望从有限的监测数据中挖掘出更丰富的特征。通过两个机械故障仿真实验,验证了该框架的有效性。从先验诊断知识的角度出发,所提出的框架为机器的少镜头智能诊断问题提供了一个新的视角。
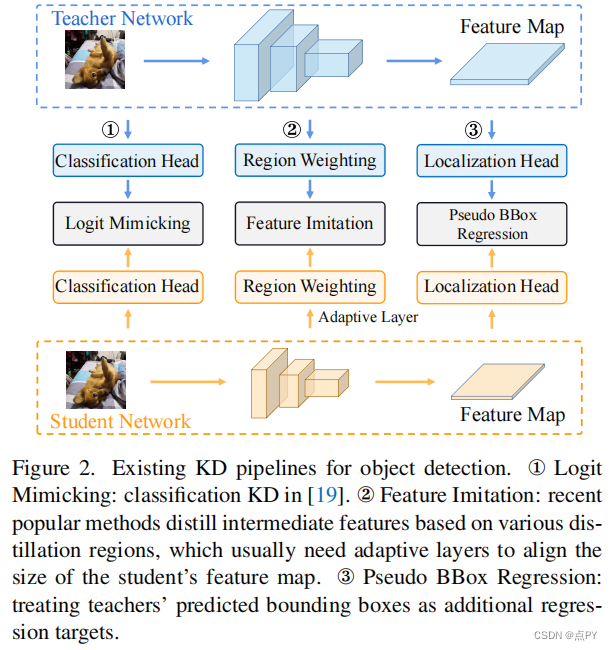
Localization Distillation for Dense Object Detection
code: https://github.com/HikariTJU/LD
知识蒸馏(KD)在目标检测中学习紧凑模型方面的强大能力。以往的目标检测KD方法主要集中在模仿模仿区域内的深度特征,而不是模拟分类日志,因为它在提取定位信息方面效率低下,而且改进微不足道。本文通过重构定位上的知识精馏过程,提出了一种新的定位精馏(LD)方法,该方法可以有效地将定位知识从教师传递给学生。此外,我们还启发式地引入了有价值的定位区域的概念,可以帮助选择性地提取特定区域的语义和定位知识。结合这两个新组件,我们首次证明了logit模拟可以优于特征模仿,并且定位知识蒸馏在提取对象检测器方面比语义知识更重要、更有效。我们的蒸馏方案简单而有效,可以很容易地应用于不同的密集物体探测器。实验表明,在COCO基准上,采用单尺度1×训练计划可以将GFocal-ResNet-50的AP评分从40.1提高到42.1,而不牺牲推理速度。


















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











