







 本文介绍迁移学习的概念及其在机器学习中的应用方式。重点讲解基于样本、特征、模型及关系的迁移方法,并探讨不同数据集下如何选择合适的迁移策略。同时,文章还分析了迁移学习在实践中的优势和挑战。
本文介绍迁移学习的概念及其在机器学习中的应用方式。重点讲解基于样本、特征、模型及关系的迁移方法,并探讨不同数据集下如何选择合适的迁移策略。同时,文章还分析了迁移学习在实践中的优势和挑战。
1.迁移学习简介
迁移学习(transfer learning)通俗来讲,就是运用已有的知识来学习新的知识,核心是找到已有知识和新知识之间的相似性,用成语来说就是举一反三。由于直接对目标域从头开始学习成本太高,我们故而转向运用已有的相关知识来辅助尽快地学习新知识。比如,已经会下中国象棋,就可以类比着来学习国际象棋;已经会编写Java程序,就可以类比着来学习C#;已经学会英语,就可以类比着来学习法语;等等。世间万事万物皆有共性,如何合理地找寻它们之间的相似性,进而利用这个桥梁来帮助学习新知识,是迁移学习的核心问题。
具体地,在迁移学习中,我们已有的知识叫做源域(source domain),要学习的新知识叫目标域(target domain)。迁移学习研究如何把源域的知识迁移到目标域上。特别地,在机器学习领域中,迁移学习研究如何将已有模型应用到新的不同的、但是有一定关联的领域中。传统机器学习在应对数据的分布、维度,以及模型的输出变化等任务时,模型不够灵活、结果不够好,而迁移学习放松了这些假设。在数据分布、特征维度以及模型输出变化条件下,有机地利用源域中的知识来对目标域更好地建模。另外,在有标定数据缺乏的情况下,迁移学习可以很好地利用相关领域有标定的数据完成数据的标定。
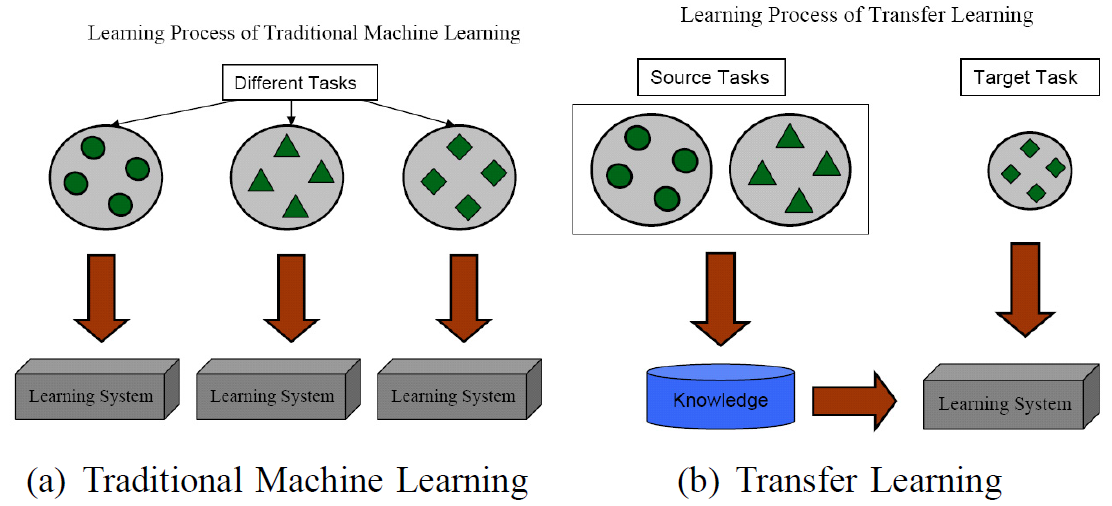
图2 迁移学习与传统机器学习的不同:(a)传统机器学习对不同的学习任务建立不同的模型,(b)迁移学习利用源域中的数据将知识迁移到目标域,完成模型建立。
迁移学习按照学习方式可以分为基于样本的迁移,基于特征的迁移,基于模型的迁移,以及基于关系的迁移。
- 基于样本的迁移通过对源域中有标定样本的加权利用完成知识迁移;
- 基于特征的迁移通过将源域和目标域映射到相同的空间(或者将其中之一映射到另一个的空间中)并最小化源域和目标域的距离来完成知识迁移;
- 基于模型的迁移将源域和目标域的模型与样本结合起来调整模型的参数;
- 基于关系的迁移则通过在源域中学习概念之间的关系,然后将其类比到目标域中,完成知识的迁移。
理论上,任何领域之间都可以做迁移学习。但是,如果源域和目标域之间相似度不够,迁移结果并不会理想,出现所谓的负迁移情况。比如,一个人会骑自行车,就可以类比学电动车;但是如果类比着学开汽车,那就有点天方夜谭了。如何找到相似度尽可能高的源域和目标域,是整个迁移过程最重要的前提。
2.为什么要迁移学习?
1)站在巨人的肩膀上:前人花很大精力训练出来的模型在大概率上会比你自己从零开始搭的模型要强悍,没有必要重复造轮子。
2)训练成本可以很低:如果采用导出特征向量的方法进行迁移学习,后期的训练成本非常低,用CPU都完全无压力,没有深度学习机器也可以做。
3)适用于小数据集:对于数据集本身很小(几千张图片)的情况,从头开始训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越大,过拟合无法避免。这时候如果还想用上大型神经网络的超强特征提取能力,只能靠迁移学习。
3.迁移学习的几种方式

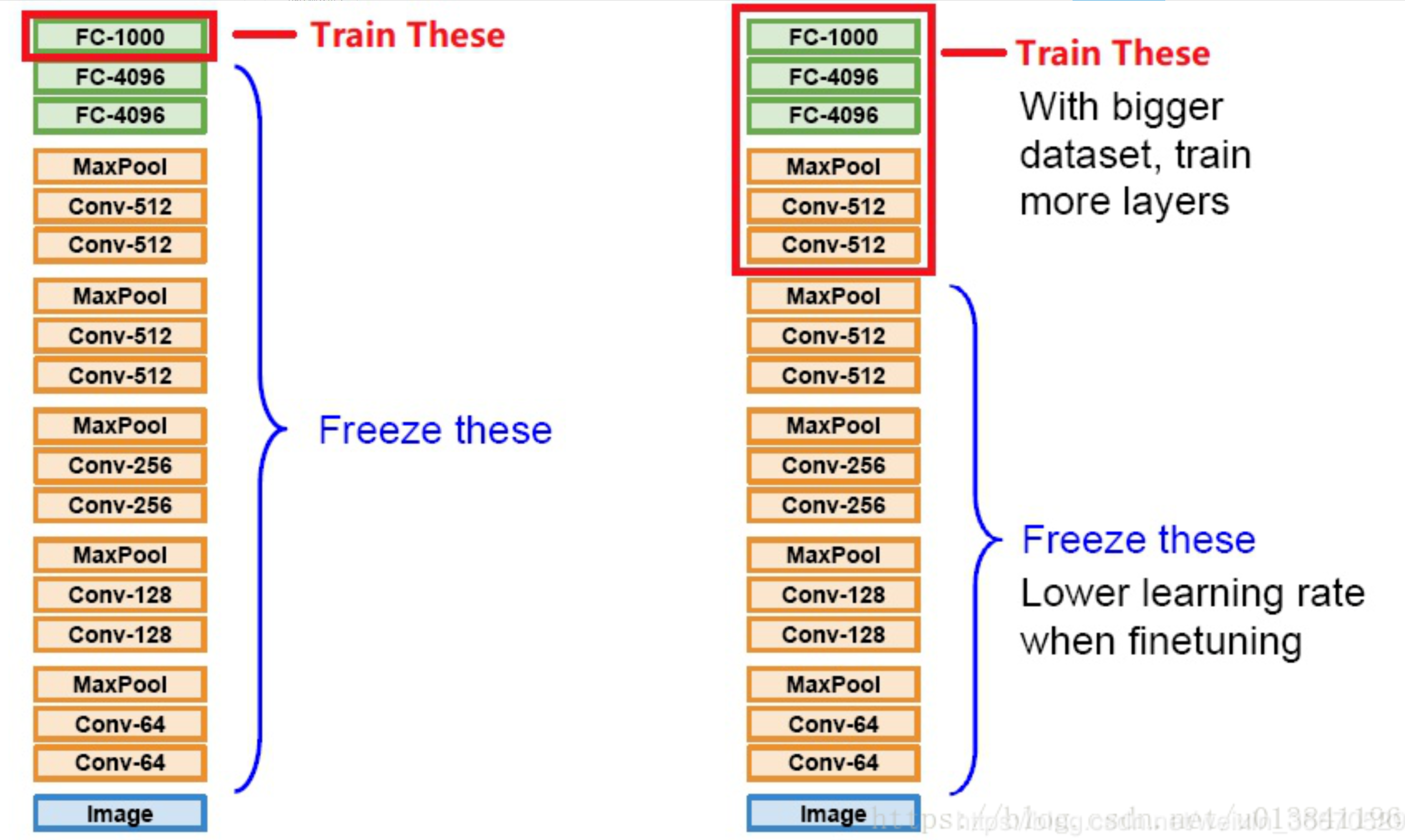
图二:Transfer Learning与Fine-tune训练过程的对比
1)Transfer Learning:
冻结预训练模型的全部卷积层,只训练自己定制的全连接层。
2)Extract Feature Vector:
先计算出预训练模型的卷积层对所有训练和测试数据的特征向量,然后抛开预训练模型,只训练自己定制的简配版全连接网络。
3)Fine-tune:
冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层),训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。
* 注:Transfer Learning关心的问题是:什么是“知识”以及如何更好地运用之前得到的“知识”,这可以有很多方法和手段,eg:SVM,贝叶斯,CNN等。
而fine-tune只是迁移学习的一种手段,更常用于形容迁移学习的后期微调中。
4、三种迁移学习方式的对比
1)第一种和第二种训练得到的模型本质上并没有什么区别,但是第二种的计算复杂度要远远优于第一种。
2)第三种是对前两种方法的补充,以进一步提升模型性能。要注意的是,这种方法并不一定能真的对模型有所提升。 本质上来讲:这三种迁移学习的方式都是为了让预训练模型能够胜任新数据集的工作,能够让预训练模型原本的特征提取能力得到充分的释放和利用。但是,在此基础上如果想让模型能够达到更低的Loss,那么光靠迁移学习是不够的,靠的更多的还是模型的结构以及新数据集的丰富程度。
实验:尝试对模型进行微调,以进一步提升模型性能
1.Fine-tune所扮演的角色
拿到新数据集,想要用预训练模型处理的时候,通常都会先用上面方法一或者方法二来看看预训练模型在新数据上的表现怎么样,摸个底。如果表现不错,还想看看能不能进一步提升,就可以试试Fine-tune,进一步解锁卷积层以继续训练模型。
但是不要期待会有什么质的飞跃。
另外,如果由于新数据集与原数据集(例如ImageNet数据集)的差别太大导致表现很糟,那么一方面可以考虑自己从头训练模型,另一方面也可以考虑解锁比较多层的训练,亦或干脆只用预训练模型的参数作为初始值,对模型进行完整训练。
2.Fine-tune 也可以有三种操作方式
注:其实基本思路都是一样的,就是解锁少数卷积层继续对模型进行训练。
场景1:已经采用方法一的方式,带着冻僵的卷积层训练好分类器了。 如何做:接着用方法一里的模型,再解锁一小部分卷积层接着训练就好了。
场景2:已经采用方法二里的方式,把分类器训练好了,现在想要进一步提升模型。 如何做:重新搭一个预训练模型接新分类器,然后把方法二里训练好的分类器参数载入到新分类器里,解锁一小部分卷积层接着训练。
场景3:刚上手,想要 Transfer Learning + Fine-tune一气呵成。 如何做:和方法一里的操作一样,唯一不同的就是只冻僵一部分卷积层训练。需要注意的是,这么做需要搭配很低的学习率,因此收敛可能会很慢。 摘录:迁移学习实战猫狗大战 - 知乎
3.如何不同数据集下使用微调※
数据集1 -
数据量少,但数据相似度非常高
- 在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别。
数据集2 -
数据量少,数据相似度低
- 在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
数据集3 -
数据量大,数据相似度低
- 在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch)。
数据集4 -
数据量大,数据相似度高
- 这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。
5、微调的注意事项
1)通常的做法是截断预先训练好的网络的最后一层(softmax层),并用与我们自己的问题相关的新的softmax层替换它。
2)使用较小的学习率来训练网络。
3)如果数据集数量过少,我们进来只训练最后一层,如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。
注:卷积神经网络的核心是:
(1)浅层卷积层提取基础特征,比如边缘,轮廓等基础特征。
(2)深层卷积层提取抽象特征,比如整个脸型。
(3)全连接层根据特征组合进行评分分类。
多重预训练视觉模型的迁移学习
和上面的方法二类似,只是我们现在拥有多个预训练模型,采用特征提取方法,使用堆叠技术将不同的预训练模型的特征组合在一起去训练。使用多个预训练模型后,与使用一个特征集的情况相同:它们希望提供一些不重叠的信息,从而使组合时性能更优越。 注:不同预训练模型的预处理方式



















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











