







文章介绍了Mini-Omni模型,这是一种开源的端到端多模态大语言模型,旨在实现实时语音交互。为了解决现有模型在语音交互中的延迟问题,作者提出了文本指令的并行生成方法和批量并行解码策略,这些方法能够在保留原有语言模型推理能力的同时,显著提升语音输出的实时性和质量。此外,文章还介绍了"Any Model Can Talk"的训练方法和专门用于语音助手优化的VoiceAssistant-400K数据集。
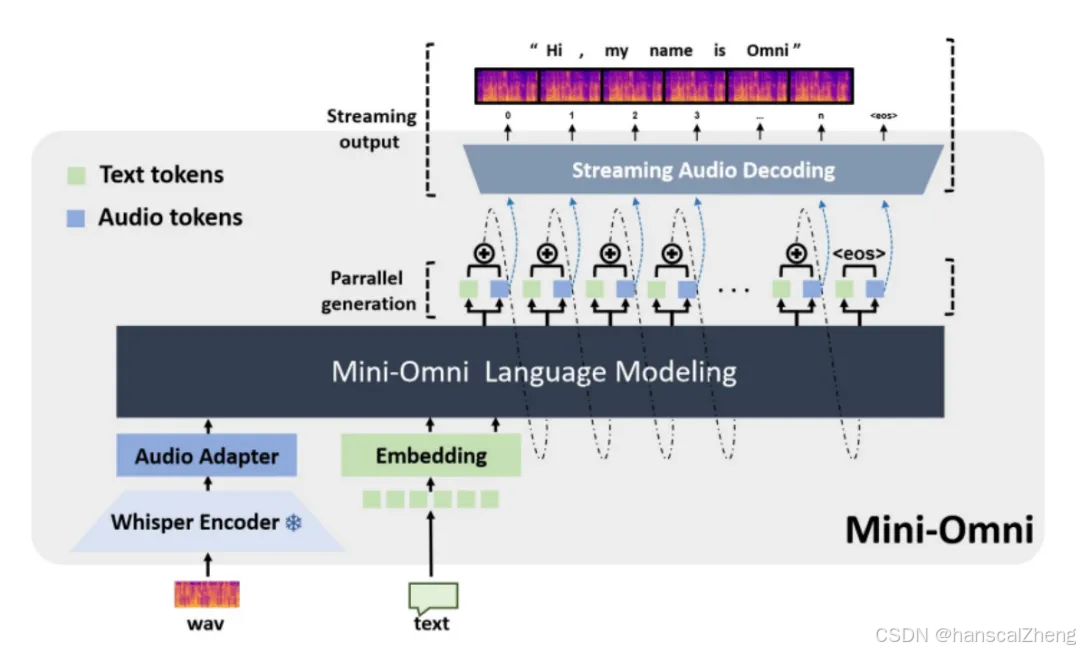
1 Mini-Omni模型
多模态大语言模型Mini-Omni,具备实时语音交互能力,该模型通过引入适配器和并行生成策略,实现了音频和文本的同时生成。目标是提升模型的实时语音输出能力,解决现有模型在语音生成中的延迟问题。
Audio Language Modeling
-
(1)将连续的语音信号离散化为语音标记,并将这些标记与文本标记结合在一起进行建模。
-
(2)提出了一种新的词汇表,结合了语音和文本标记,实现了音频与文本的联合建模。
-
(3)使用负对数似然损失函数对模型进行训练,以优化语音和文本标记的生成过程。
Decoding Strategies
-
(1)音频生成与文本指令:提出了一种并行解码方法,同时生成文本和音频标记,以确保实时性。
-
(2)文本延迟并行解码:通过在生成音频标记之前生成对应的文本标记,增强模型的推理能力。
-
(3)批量并行解码:在推理过程中使用批量并行策略,将文本推理能力最大化转移到音频领域,提升模型在语音任务中的推理能力。

Any Model Can Talk
-
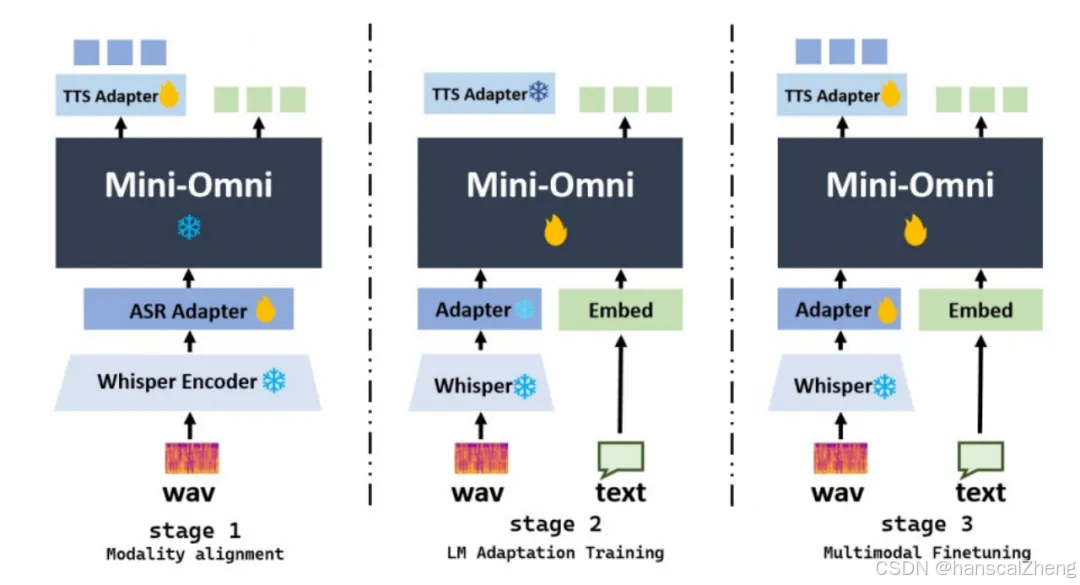
(1)提出了一个三阶段的训练方法,旨在最小化对原有模型能力的影响。
-
(2)音频编码:重点是从输入音频中提取特征,使用多码本方法来捕捉音频细节。
-
(3)三阶段训练:
-
模态对齐:增强文本模型的语音理解和生成能力。
-
适配训练:专注于文本输入下的语音生成训练。
-
多模态微调:对整个模型进行全面微调,以确保多模态输出的质量。
2 结语
文章介绍了Mini-Omni模型,一种能够实现实时语音交互的端到端多模态大语言模型,并提出了提升语音生成效率的方法。
论文题目: Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
论文链接: https://arxiv.org/abs/2408.16725
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!


















 1648
1648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









