






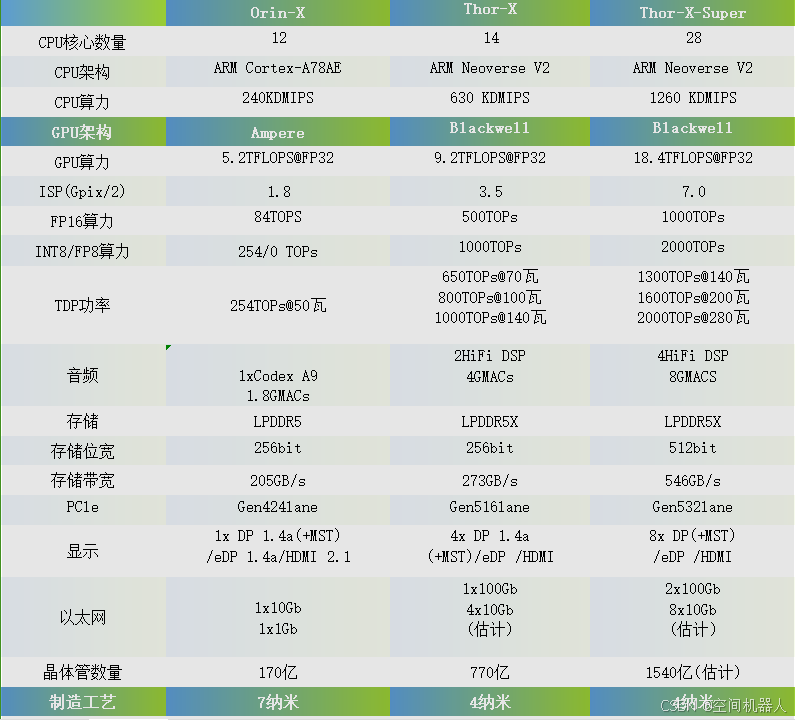
1. CPU性能与架构分析
从表格信息来看,这三款芯片采用了不同的CPU架构和核心数量:
- Orin-X:12核心,ARM Cortex-A78AE架构,性能为240 KDMIPS。
- Thor-X:14核心,ARM Neoverse V2架构,性能为630 KDMIPS。
- Thor-X-Super:28核心,ARM Neoverse V2架构,性能提升至1260 KDMIPS。
技术特点分析
Cortex-A78AE架构
- Cortex-A78AE是专为汽车电子与高安全性需求设计的架构,支持锁步执行模式,用于提高安全性。
- 相比普通Cortex-A系列,A78AE在任务处理上更加注重实时性和确定性。
Neoverse V2架构
- Neoverse V2是针对数据中心和高性能计算优化的架构,支持更高的并行处理能力。
- 相比A78AE,Neoverse V2的每核心算力更强,同时具备更好的功耗性能比。
核心数量与性能对比
核心数量的增加是提升算力的直接手段,但需要注意内存带宽和任务调度的瓶颈。
- Orin-X适用于较低功耗的任务场景,如ADAS(高级驾驶辅助系统)。
- Thor-X适用于多任务处理环境,例如车载域控制器。
- Thor-X-Super更适合复杂场景,如自动驾驶系统的集中式计算需求。
如何选型
- 如果关注实时性和高安全性,Orin-X是理想选择。
- 如果任务复杂度较高且对性能要求较高,Thor-X或Thor-X-Super更合适。
- 在预算允许的情况下,优先选择Thor-X-Super,其高核心数量和强大的Neoverse V2架构能够显著提升系统冗余度和处理能力。
当前瓶颈与改进方向
当前ARM架构在复杂计算场景中的瓶颈主要体现在以下几个方面:
- 内存带宽限制:随着核心数量增加,内存子系统的瓶颈愈加显著。
- 改进方向:采用更宽的内存位宽(如Thor-X-Super的512位宽)以及高速缓存一致性协议。
- 功耗优化难度:高性能与低功耗的平衡仍是设计挑战。
- 改进方向:引入更高效的电源管理机制,例如DVFS(动态电压和频率调节)。
2. GPU性能及应用场景
GPU参数显示:
- Orin-X:Ampere架构,5.2 TFLOPS(FP32算力)。
- Thor-X:Blackwell架构,9.2 TFLOPS(FP32算力)。
- Thor-X-Super:Blackwell架构,18.4 TFLOPS(FP32算力)。
技术特点分析
Ampere架构
- Ampere是NVIDIA较早的GPU架构,侧重于图形渲染和部分AI推理任务。
- FP32算力较低,适用于中低复杂度的任务。
Blackwell架构
- Blackwell是最新一代架构,相比Ampere架构,其能效比和AI计算性能均有大幅提升。
- 支持更高的INT8/FP8算力,更适合自动驾驶中的深度学习推理任务。
应用场景
- Orin-X:适合中等复杂度的AI任务,如驾驶员监控、道路标志识别等。
- Thor-X:更适合多摄像头的场景,例如多目标跟踪和3D环境感知。
- Thor-X-Super:适合全自动驾驶系统,能处理高复杂度的AI任务,如多模态融合和实时决策。
当前瓶颈与改进方向
- 存储带宽不足:GPU算力强大,但需要高速内存带宽支持。
- 改进方向:采用HBM(高带宽内存)或进一步提升LPDDR5X的频率。
- 算力利用率:在实际场景中,GPU算力利用率较低。
- 改进方向:优化软件算法,充分利用硬件资源。
3. 存储系统设计与选型建议
存储参数显示:
- Orin-X:LPDDR5,256位宽,带宽205GB/s。
- Thor-X:LPDDR5X,256位宽,带宽273GB/s。
- Thor-X-Super:LPDDR5X,512位宽,带宽546GB/s。
技术特点分析
LPDDR5与LPDDR5X
- LPDDR5X在LPDDR5的基础上,进一步提升了数据传输速率和功耗性能。
- 带宽提升显著,尤其适合高数据吞吐需求的AI计算场景。
位宽与带宽
位宽和带宽的增加对AI和GPU任务的性能提升至关重要。
- Thor-X-Super采用512位宽设计,存储带宽达到546GB/s,能够满足高算力需求。
如何选型
- Orin-X适用于带宽需求不高的场景,如单一传感器处理。
- Thor-X适合中等复杂度的应用,带宽略有冗余。
- Thor-X-Super在复杂AI任务中表现最佳,但需注意成本与功耗的平衡。
当前瓶颈与改进方向
- 能效优化:高带宽设计通常伴随高功耗。
- 改进方向:优化电路设计,采用更先进的低功耗技术。
- 存储器兼容性问题:LPDDR5X的支持在软件和硬件层面仍需优化。
- 改进方向:通过仿真和测试,确保系统的稳定性。
4. 功耗与散热优化
TDP(热设计功耗)显示:
- Orin-X:50瓦。
- Thor-X:70瓦到140瓦。
- Thor-X-Super:140瓦到280瓦。
功耗设计挑战
随着算力的增加,功耗大幅提升,对散热设计提出了更高要求。
- 散热设计:需要高效的散热方案,如液冷或热管技术。
- 电源设计:高功耗芯片对电源的瞬态响应提出了挑战。
改进方向
- 引入先进的功率调节技术,例如多相供电与动态电压调整。
- 采用高导热材料,提升散热效率。
5. 接口扩展与系统集成
接口扩展设计
各芯片支持多种高性能接口:
- Orin-X:支持PCIe 4.0,带宽充足,但接口数量有限。
- Thor-X和Thor-X-Super:支持PCIe 5.0,提供更高带宽和更多接口数量,适合大规模数据吞吐应用。
应用场景分析
- Orin-X:适用于有限接口扩展的应用,如单独处理ADAS摄像头输入。
- Thor-X:在车载域控制器中表现出色,可连接多传感器和外部存储设备。
- Thor-X-Super:适合需要大规模数据交互的系统,如全自动驾驶域控制器。
当前瓶颈与改进方向
- PCIe接口瓶颈:在多设备高负载情况下,PCIe链路的拥堵可能影响性能。
- 改进方向:增加接口通道,或引入CXL(Compute Express Link)技术提升数据吞吐能力。
- 兼容性问题:新接口标准可能需要外部设备的硬件升级。
- 改进方向:优化硬件驱动与中间件设计。
6. 制造工艺与可靠性
制造工艺
从图中推测,这些芯片均采用先进的5nm制程工艺:
- 功耗降低:更小的制程工艺显著降低了动态功耗。
- 性能提升:晶体管密度增加带来更高的计算能力。
可靠性设计
汽车级芯片需满足AEC-Q100认证标准,确保在严苛环境下的稳定性。
当前技术瓶颈与改进方向
- 散热可靠性:小制程工艺的高密度晶体管易产生热点。
- 改进方向:通过热仿真优化芯片内部和外部的热分布。
- 制造良率:先进工艺带来良率降低的问题。
- 改进方向:通过芯片测试技术提升良率,如内建自测(BIST)。
7. 技术瓶颈与未来发展方向
技术瓶颈
- 算力需求增长:AI与自动驾驶对算力需求不断提升,但单芯片提升面临瓶颈。
- 功耗与散热:算力提升伴随功耗增加,对散热设计提出更高要求。
- 系统集成复杂性:多传感器、多域集成对硬件和软件提出挑战。
未来发展方向
- 异构计算:引入更多NPU(神经网络处理单元)和专用AI加速器,优化AI任务处理。
- 3D封装技术:通过堆叠设计提升芯片算力密度。
- 边缘计算与云计算协同:提升数据处理的实时性和效率。
8. 应用案例分析
Orin-X实际应用
- 用于L2/L3级ADAS系统。
- 处理单摄像头感知任务,例如车道线检测和障碍物识别。
Thor-X实际应用
- 用于多域控制器,如驾驶与停车集成。
- 处理多摄像头与雷达数据,支持车辆环境感知和路径规划。
Thor-X-Super实际应用
- 集成至L4/L5全自动驾驶车辆。
- 处理多传感器融合、高精度地图匹配和实时决策。
总结
Orin-X、Thor-X和Thor-X-Super分别面向不同复杂度的汽车应用场景,其性能、架构与接口设计均体现了NVIDIA在汽车芯片领域的先进技术。选型需根据实际应用需求综合考虑算力、带宽、功耗与成本。同时,未来技术发展需持续关注内存带宽优化、异构计算架构以及系统可靠性提升。
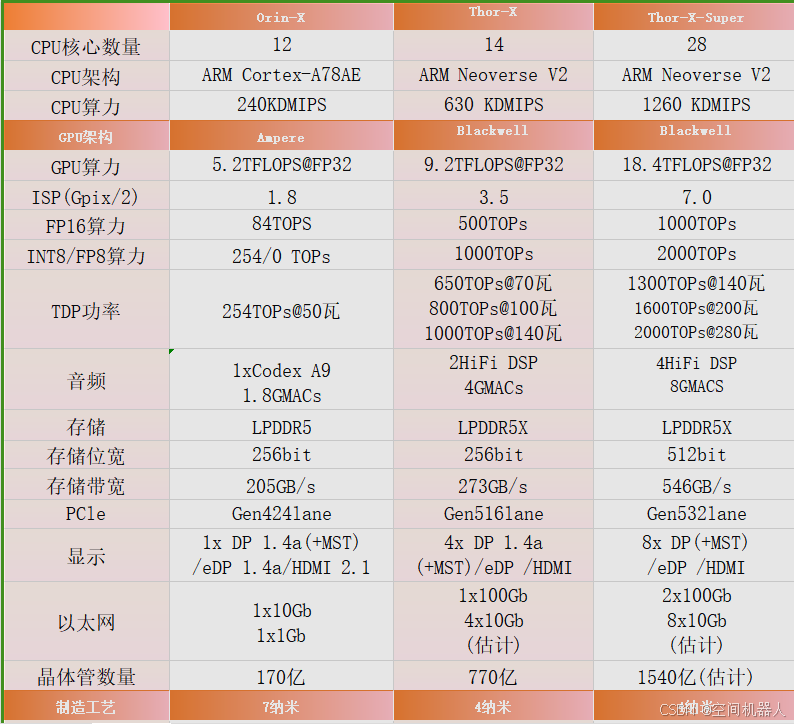
1. ARM Cortex-A78AE 与 ARM Neoverse V2 详细介绍
Cortex-A78AE
- 架构特点:
- 专为汽车电子和高安全性场景设计。
- 支持 锁步执行模式,适合功能安全需求(如 ISO 26262 标准)。
- 具备 实时性 和 确定性 的任务调度能力。
- 应用场景:
- 自动驾驶域控制器。
- ADAS 系统中的实时决策模块。
- 确保任务执行的可靠性和低延迟性。
Neoverse V2
- 架构特点:
- 针对数据中心、高性能计算设计。
- 提供更高的并行计算能力,单位算力功耗比提升。
- 支持 下一代互联协议(如 PCIe Gen5、CXL)。
- 应用场景:
- 自动驾驶中的深度学习推理。
- 高负载环境感知与多传感器数据融合。
- 高性能边缘计算。
2. CPU 算力与应用
-
算力介绍:
- KDMIPS 是衡量 CPU 每秒执行百万条指令的单位。
- Orin-X(240 KDMIPS)适合中低负载任务。
- Thor-X(630 KDMIPS)支持复杂环境感知和多任务调度。
- Thor-X-Super(1260 KDMIPS)适合高密度数据处理和集中式计算。
-
应用场景:
- 240 KDMIPS:单传感器处理(如摄像头、雷达数据预处理)。
- 630 KDMIPS:支持多任务操作,例如实时地图重建。
- 1260 KDMIPS:满足自动驾驶系统的深度学习需求和决策计算。
3. GPU 架构对比:Ampere vs Blackwell
Ampere
- 发布于 2020 年,采用 TSMC 7nm 工艺。
- 特点:
- 优化图形渲染性能。
- FP32 算力较强(5.2 TFLOPS),但 AI 性能较弱。
- 适合传统图形任务和轻量级 AI 推理。
- 应用场景:
- 中低复杂度 AI 任务(如驾驶员监控、车道线检测)。
Blackwell
- 发布于 2024 年,采用 TSMC 4nm 工艺。
- 特点:
- 大幅提升 AI 推理性能,支持 INT8 和 FP8 精度。
- 能效比显著提升(单位算力功耗下降)。
- 更高的并行计算能力,支持实时多模态融合。
- 应用场景:
- 自动驾驶高复杂度任务(如 3D 环境感知、多模态数据融合)。
4. GPU 算力与 ISP 比较
-
TFLOPS 算力:
- 表示每秒执行万亿次浮点运算能力。
- FP32(浮点运算):
- 5.2 TFLOPS:中等复杂度推理。
- 9.2 TFLOPS:支持多摄像头同步计算。
- 18.4 TFLOPS:高复杂度全自动驾驶系统。
-
ISP(图像信号处理器)能力:
- 1.8 TOPS:适合单摄像头图像处理。
- 3.5 TOPS:支持多传感器图像融合。
- 7.0 TOPS:实时高分辨率视频处理。
5. 精度分析:FP16、INT8、FP8
-
FP16(半精度浮点数):
- 精度较高,适合训练和推理阶段。
- 常用于图像处理和精度要求高的任务。
-
INT8(整型):
- 性能与功耗比优异,适合推理。
- 自动驾驶中的物体检测任务常用 INT8 算力。
-
FP8:
- 新兴标准,进一步降低计算复杂度。
- 在 AI 边缘计算中效率更高。
6. TDP(热设计功耗)分析
-
功耗差异:
- Orin-X(50W):适合低功耗场景。
- Thor-X(70-140W):高效能与功耗的平衡。
- Thor-X-Super(140-280W):高性能任务。
-
功耗优化方向:
- 多相供电设计。
- 使用液冷技术降低散热瓶颈。
7. Codex A9 与 HIFI DSP 应用
-
Codex A9:
- 专为音视频解码设计。
- 支持 HEVC、VP9 等高效解码算法。
-
HIFI DSP:
- 专注于音频信号处理。
- 应用于语音识别、回声消除、噪声抑制。
8. 存储:LPDDR5 与带宽位宽关系
-
LPDDR5 特点:
- 数据速率高达 6400 MT/s。
- 功耗更低,延迟更短。
-
带宽与位宽:
- 带宽(GB/s)= 数据速率(MT/s)× 位宽(位)/ 8。
- Thor-X-Super 的 512 位宽设计有效提升了总带宽(546 GB/s)。
9. 接口分析
-
PCIe Gen4 vs Gen5:
- Gen4:16 GT/s。
- Gen5:32 GT/s,带宽翻倍。
-
DP1.4 vs HDMI2.1:
- DP1.4:32.4 Gbps,支持 8K@60Hz。
- HDMI2.1:48 Gbps,支持更高刷新率,适合高端显示设备。
10. 制程工艺:7nm vs 4nm
-
差异:
- 7nm:晶体管密度约 1.6 亿/平方毫米。
- 4nm:晶体管密度提高至 2.5 亿/平方毫米。
-
头发丝比较:
- 一根头发丝约宽 100,000 纳米。
- 4nm 工艺可容纳约 25,000 层晶体管结构。
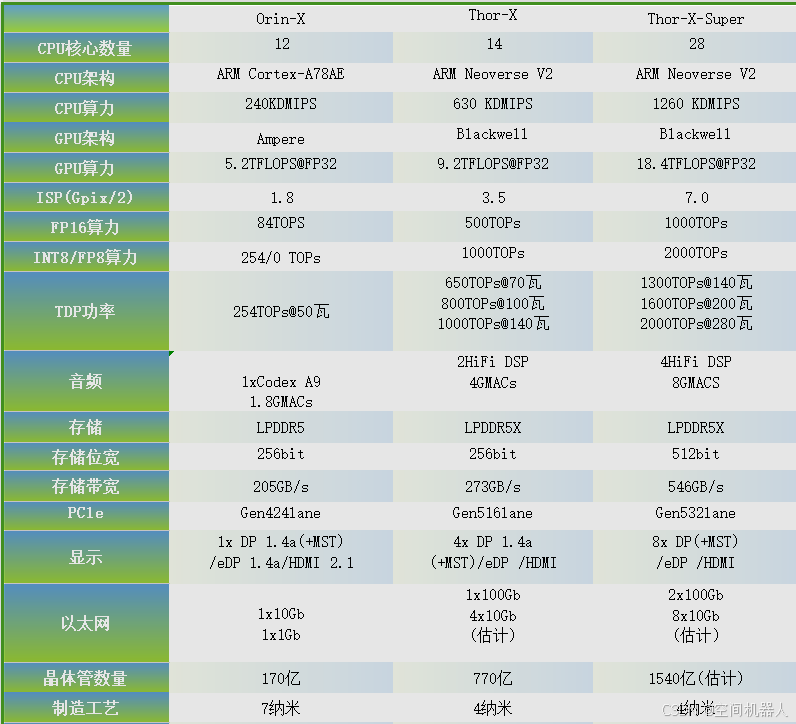


















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











