






论文链接:https://arxiv.org/pdf/2203.02119.pdf
主要目的和思想
使用机械臂完成对动态物体(将物体放在移动盘上)的抓取,采用强化学习的理念,设计机械臂和移动盘的对抗。
现有的问题
机械臂只能抓取运动轨迹简单的动态物体
对未知场景的泛化能力不足
主要方法
整个对抗游戏可以用一个元组进行表示
<
S
,
A
1
,
A
2
,
O
1
,
O
2
,
R
1
,
R
2
,
P
,
γ
1
,
γ
2
>
<\mathcal{S},\mathcal{A}_1,\mathcal{A}_2,\mathcal{O}_1,\mathcal{O}_2,\mathcal{R}_1,\mathcal{R}_2,\mathcal{P},\gamma_1,\gamma_2>
<S,A1,A2,O1,O2,R1,R2,P,γ1,γ2>,这里
S
,
A
,
O
,
R
,
P
\mathcal{S},\mathcal{A},\mathcal{O},\mathcal{R},\mathcal{P}
S,A,O,R,P和
γ
\gamma
γ分别表示状态空间、动作空间、观测空间、回报函数、状态转移概率和系数。对
t
t
t时刻,对机器人和移动盘的观测分别记为
o
1
,
t
o_{1,t}
o1,t和
o
2
,
t
o_{2,t}
o2,t,并同时针对其分别采取动作
a
1
,
t
∼
π
(
o
1
,
t
)
a_{1,t}\sim\pi(o_{1,t})
a1,t∼π(o1,t)和
a
2
,
t
∼
π
(
o
2
,
t
)
a_{2,t}\sim\pi(o_{2,t})
a2,t∼π(o2,t),这里
π
\pi
π代表采取的方法。机器人的移动盘分别得到回报
r
1
,
t
(
s
t
,
a
1
,
t
,
a
2
,
t
)
r_{1,t}(s_t,a_{1,t},a_{2,t})
r1,t(st,a1,t,a2,t)和
r
2
,
t
(
s
t
,
a
1
,
t
,
a
2
,
t
)
r_{2,t}(s_t,a_{1,t},a_{2,t})
r2,t(st,a1,t,a2,t)。再根据状态转移概率
P
\mathcal{P}
P,得到
t
+
1
t+1
t+1时刻的状态
s
t
+
1
s_{t+1}
st+1。而机器人和移动盘的目标都是最大化自己的回报:
E
a
i
,
t
∼
π
i
(
o
i
,
t
)
[
∑
t
=
1
T
γ
i
t
−
1
r
i
,
t
(
s
t
,
a
1
,
t
,
a
2
,
t
)
]
\mathbb{E}_{a_{i,t}\sim\pi_i(o_i,t)}[\sum^T_{t=1}\gamma_i^{t-1}r_{i,t}(s_t,a_{1,t},a_{2,t})]
Eai,t∼πi(oi,t)[t=1∑Tγit−1ri,t(st,a1,t,a2,t)]
由于机械臂的抓取范围大于移动盘的移动范围,所以机器臂的对抗难度更高。本文提出了一个非对称的回报结构来稳定这种对抗学习。
机器人的回报
由于需要机器人抓住物体,所以希望机械臂的夹子尽可能接近移动盘上的物体,定义距离惩罚:
d
1
,
2
=
(
g
x
−
o
x
)
2
+
(
g
y
−
o
y
)
2
+
(
g
z
−
o
b
z
)
2
d_{1,2}=\sqrt{(g_x-o_x)^2+(g_y-o_y)^2+(g_z-o_{bz})^2}
d1,2=(gx−ox)2+(gy−oy)2+(gz−obz)2
其中
g
x
,
g
y
,
g
z
g_x,g_y,g_z
gx,gy,gz分别代表机械臂夹子中心点的x,y,x坐标。
o
x
,
o
y
o_x,o_y
ox,oy代表物体中心点的x,y坐标以及物体bounding box上z方向的最大值。这些坐标的定义以世界坐标系为基准。
由于在机械臂的抓取过程中,可能会和物体发生碰撞,导致物体损坏,所以不希望这种事情发生,加上物体形状对抓取的影响,这进一步加大了机械臂的对抗难度。为了鼓励机器臂正确抓取物体,设计了一个正回报函数
R
b
R_b
Rb,当机械臂夹子的中心点进入物体的bounding box时鼓励机械臂抓取,同时为了防止不必要的碰撞,设计了一个碰撞函数
P
c
o
l
l
P_{coll}
Pcoll,惩罚不是因为正确抓取所产生的不必要碰撞。同时,为了提高机械臂的抓取速度,设计了时间函数
P
t
i
m
e
P_{time}
Ptime,鼓励机械臂用尽可能少的时间和步骤完成抓取任务。当机械臂抓取物体失败后,回报
r
1
r_1
r1直接置位为
P
o
u
t
P_{out}
Pout,并且结束本次抓取。当物体的高度以一定高度高于原始的位置时,认为机械臂抓取成功,
r
1
r_1
r1直接置位为
R
s
R_s
Rs,并且结束本次抓取。
正规机器人(机械臂)的回报定义为:

这里
R
s
>
0
,
P
o
u
t
<
0
,
P
d
i
s
<
0
,
R
b
>
0
,
P
c
o
l
l
<
0
,
P
t
i
m
e
<
0
R_s>0,P_{out}<0,P_{dis}<0,R_b>0,P_{coll}<0,P_{time}<0
Rs>0,Pout<0,Pdis<0,Rb>0,Pcoll<0,Ptime<0,
1
b
=
1
\mathbb{1}^b=1
1b=1当机械臂夹子的抓取点再物体的bounding box内时。
移动盘(物体)的回报
为了保证不被抓取,要保持和机械臂一定的抓取距离,
P
d
i
s
P_{dis}
Pdis函数同样被用到。除此之外,还为物体设计了一个安全距离
d
s
a
f
e
d_{safe}
dsafe,当{d_12}(机械臂夹子和物体之间的距离)小于
d
s
a
f
e
d_{safe}
dsafe,设计一个
P
c
l
o
s
e
P_{close}
Pclose函数来惩罚物体。
r
2
=
−
P
d
i
s
+
1
s
a
f
e
P
c
l
o
s
e
r_2=-P_{dis}+\mathbb{1}^{safe}P_{close}
r2=−Pdis+1safePclose
这里,
P
d
i
s
<
0
,
P
c
l
o
s
e
=
−
d
s
a
f
e
P_{dis}<0,P_{close}=-d_{safe}
Pdis<0,Pclose=−dsafe,
1
s
a
f
e
=
1
\mathbb{1}^{safe}=1
1safe=1当
d
12
<
d
s
a
f
e
d_{12}<d_{safe}
d12<dsafe。
过程展示
对于每一步,6D位姿tracker
Ψ
\Psi
Ψ首先从环境中得到RGB-D图像
I
I
I,并且估计出物体的6D位姿,并且用相应的栅格给出物体的bounding box(bounding box的朝向和物体一致),使用bounding box上的特征点来表示物体的状态
ψ
\psi
ψ。对于机械臂夹子的6D位姿
ε
\varepsilon
ε,可以直接通过机械臂参数回传得到。
物体和机械臂夹子直接的相对信息时我们关注的重点。因此,使用一个坐标转换器将物体状态和
ε
\varepsilon
ε转换到相对状态。对于机械臂来说,
ε
\varepsilon
ε的变换是基于机械臂底座坐标系,物体状态
ψ
\psi
ψ的变换基于机械臂的架子(执行器)。对于机械臂来说,变换后的状态表示为
ϕ
12
=
[
ε
12
,
ψ
12
]
\phi_{12}=[\varepsilon_{12},\psi_{12}]
ϕ12=[ε12,ψ12],将
ϕ
12
\phi_{12}
ϕ12作为机械臂控制器
Ω
1
\Omega_1
Ω1的输入,得到操作
a
1
=
[
x
1
,
y
1
,
z
1
,
θ
1
,
g
1
]
a_1=[x_1,y_1,z_1,\theta_1,g_1]
a1=[x1,y1,z1,θ1,g1],这里,
x
1
,
y
1
,
z
1
x_1,y_1,z_1
x1,y1,z1表示相对物体的3D位置,
θ
1
\theta_1
θ1代表相对物体的yaw方向朝向,
g
1
g_1
g1代表机械臂夹子的开合。对于物体来说,
ε
\varepsilon
ε的变换和物体状态
ψ
\psi
ψ的变换都是基于机械臂底座坐标系,变换后的状态表示为
ϕ
21
=
[
ε
21
,
ψ
21
]
\phi_{21}=[\varepsilon_{21},\psi_{21}]
ϕ21=[ε21,ψ21],将
ϕ
21
\phi_{21}
ϕ21作为移动盘
Ω
2
\Omega_2
Ω2的输入,得到操作
a
2
=
[
x
2
,
y
2
,
θ
2
]
a_2=[x_2,y_2,\theta_2]
a2=[x2,y2,θ2],这里,
x
2
,
y
2
x_2,y_2
x2,y2表示物体的2D平移量,
θ
2
\theta_2
θ2代表物体yaw方向朝向。
训练策略
为了鼓励机械臂在早期阶段抓到物体,首先将系数 γ 1 \gamma_1 γ1设置的比较小,然后逐渐增加 γ 1 \gamma_1 γ1,来引导机械臂学习长期的抓取策略。对机械臂和移动盘采取同时训练的策略,但是这样容易导致机械臂过度拟合并发对象策略。因此,我们创建了一个模型池来在训练期间保存不同的对象策略。收敛后,选择性能最好的机器人策略,并从模型池中随机抽取对象策略对机器人策略进行微调。为了生成更多样化的轨迹进行微调,我们随机给定物体状态和动作。对于对抗性训练阶段,我们使用基础状态作为策略的输入。
实验结果
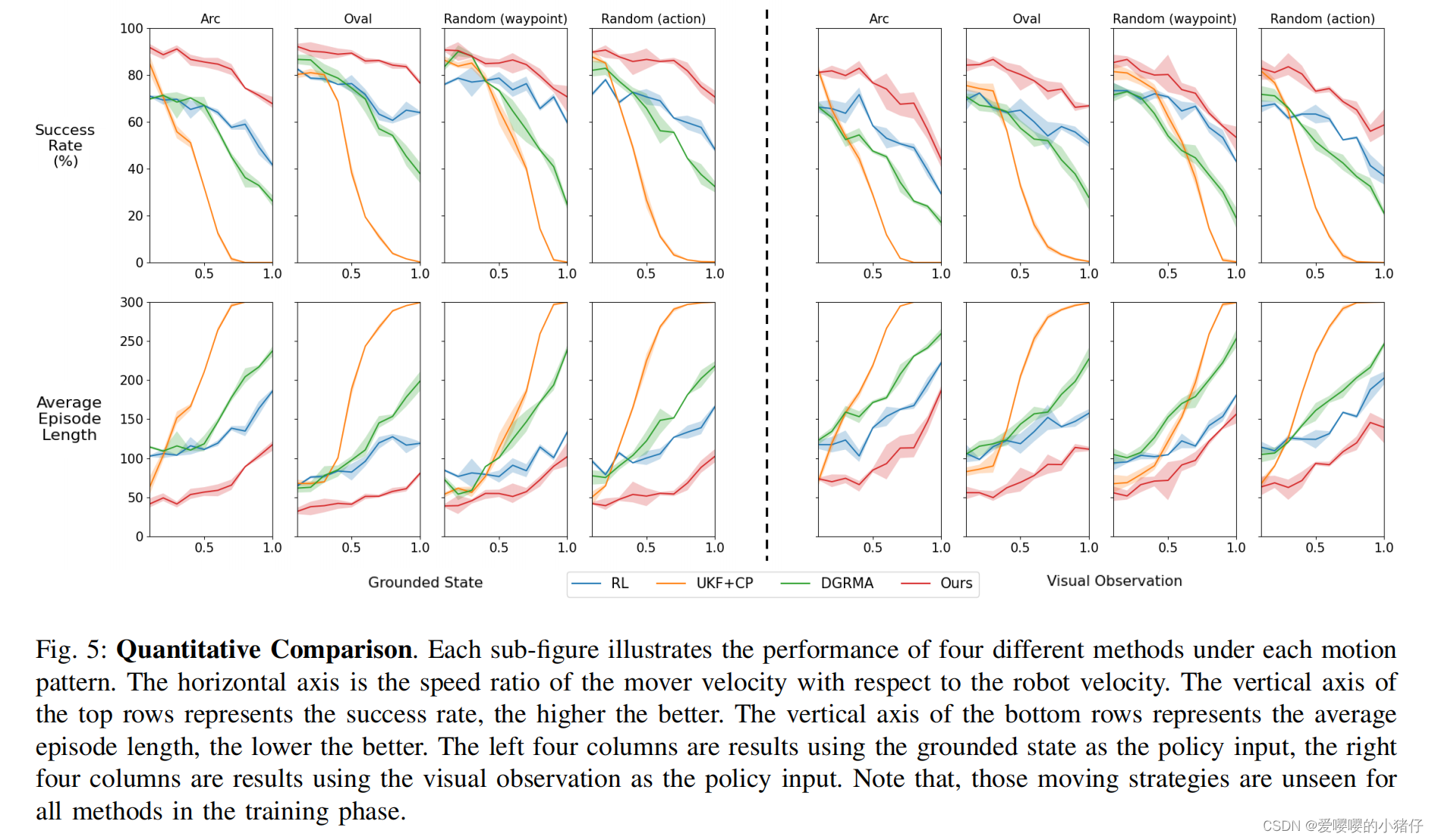

















 2737
2737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









