









朱松纯教授场景理解相关文章简介
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image
基于单张图像的整体场景解译与重建

我们提出了一个计算框架来联合解译单帧RGB图像,通过使用一系列的随机语法模型生成的CAD模型构成整体的3D结构。具体地说,我们引入了整体场景语法(HSG)来表示三维场景结构,其建立了一个室内场景的功能与几何性的联合分布,提出的HSG方法捕捉三种必要的而且常见的潜在室内场景的表示:
- 潜在的人背景,描述一个房间布置的可视性和功能性,对场景配置的几何约束.
- 保证物理上合理解析的物理约束重建。
- 物理约束
我们解决了这个联合解译和重建问题以综合分析的方式,寻求最小化差异在输入图像和我们的3D生成的渲染图像之间表示,在空间的深度,表面法线,和对象分割图。用解析图表示的最佳配置,用马尔可夫链蒙特卡洛(MCMC)进行推断,有效地遍历不可微解空间,共同优化对象定位,3D布局和隐藏的目标上下文语义。实验结果表明,该算法提高了三维布局的泛化能力,显著优于现有算法估计、三维目标检测和整体场景理解。
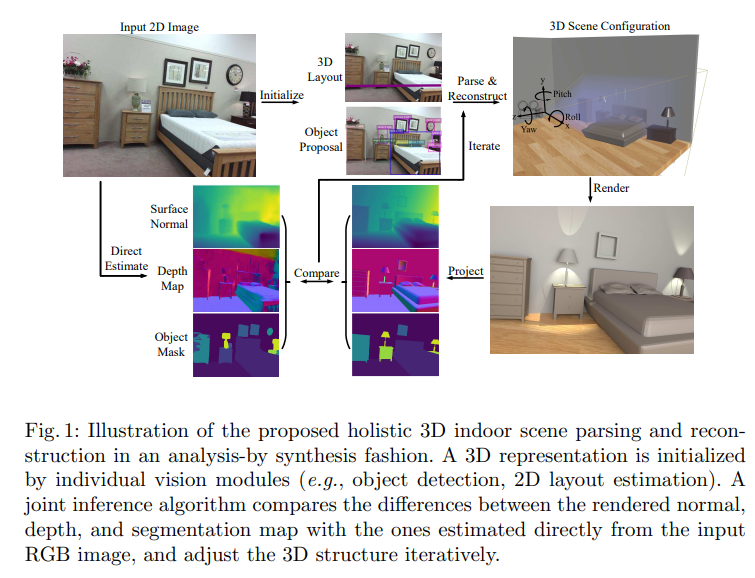
Single-View 3D Scene Parsing by Attributed Grammar

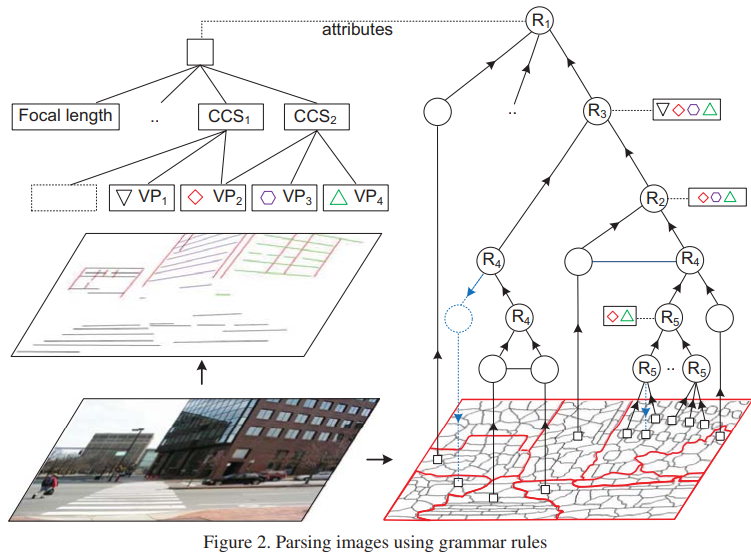
我们提出了一种属性语法,用于解译man-made的外部场景同时用于语义外表与3D模型恢复,这个语法将超像素作为最终节点并使用5个生产规则用于产生层次化的解译图,每个图节点实际关联着在3D世界或者图片中的一个表面或者表面的一部分,他们通过一些全局场景的模型属性表示,例如focal length,vanishing points, suface properties, relative localtion等等,每个产生规则都与一些等式,这些等式限制了父节点或者子节点的属性,通过输入一张图片,我们的目标是构建一个层次化的解译图,通过递归地应用五个语法规则当保存属性限制的时候,我们开发了一种有效的、自上而下的聚类采样流程,能够有效地探索受限空间。我们我们通过公开数据集和自建的新数据集验证我们的想法,并取得了SOTA的结果,在布局估计和区域分割任务上。我们也展示了我们方法能够恢复3D模型的细节。
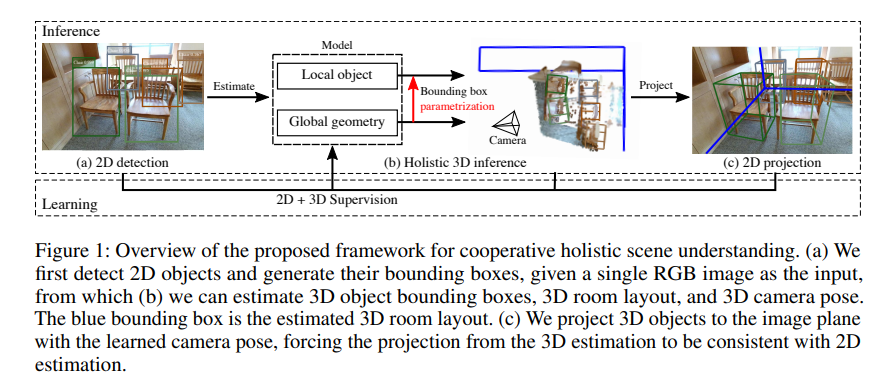
Cooperative Holistic Scene Understanding: Unifying 3D Object, Layout, and Camera Pose Estimation

整个的3D室内场景理解指的是:联合预测以下几点:一,预测目标的锚框,二,内部环境的布局,三,相机的位姿,目前已有的方法要么效率不高,要么就只解决了部分的问题。在本工作中,我们提出了一个端到端的模型能够同步地解决以上的三个任务并且能够实时运行,仅用输入RGB图像。我们提出的方法的本质就是:一是将目标参数化而不是直接估计目标,二是通过协作训练而不是单个的训练多个模块。特别指出,我们如何对目标参数化?通过预测相机位姿、目标的属性来实现目标的3d bbox的参数化,目前已提出的方法有两个优点:一个是参数化能够保证2D&3D空间的连续性,因此能够大量减小3D坐标中的预测方差,二是限制条件也能够影响到不同模块的训练。我们称这些方法为“协作损失”,我们使用了三种协作损失用于3D bbox预测、2D投影,物理实体的限制,去估计一个具有几何连续性和实体灵活性的3D场景。作者在SUN RGB-D数据集上做了实验,能够很好的提升3D检测、3D布局的预测性能,相机位姿估计任务等。
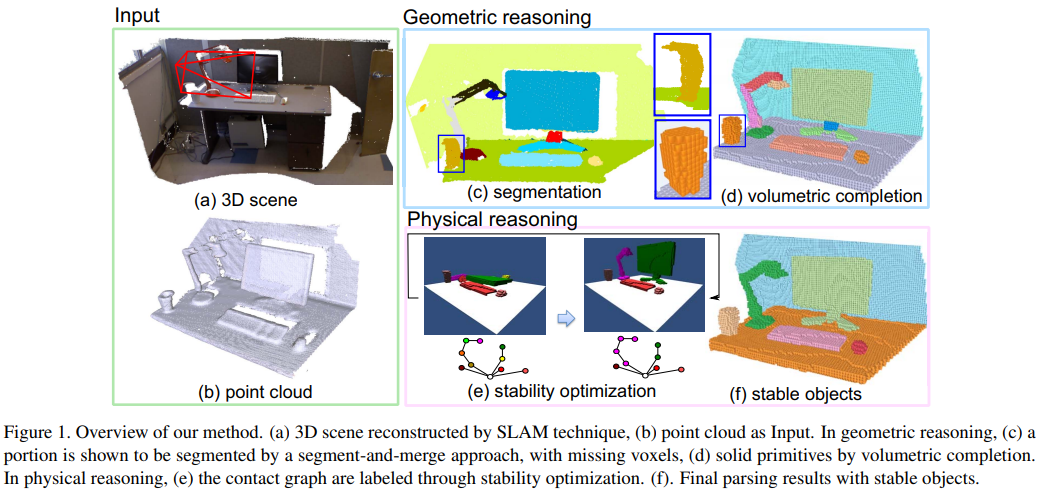
Beyond Point Clouds: Scene Understanding by Reasoning Geometry and Physics

本文提出从点云中通过推理目标的物理稳定性,实现场景理解,我们利用一种简单的观测,通过人工设计,目标在稳定的场景中应该是重力场下稳定的状态,这个假设适用于所有场景中的各类种类,并且对场景的解译问题施加了很多有用的限制。我们的方法包括两个步骤:一是集合推理,通过恢复刚性3D物体的原本形态从有缺陷的点云中,二是物理推理,将不稳定的原始物体组合到一个物理稳定的物体,通过优化稳定性和场景鲜艳,我们提出使用新的不连接图表示地平面并且使用MCMC方法优化。实验中我们算法实现了更好的性能:目标分割、3D物体恢复,场景理解解译
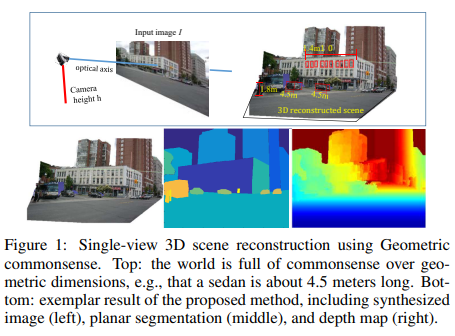
Single-Image 3D Scene Parsing Using Geometric Commonsense

提出一种统一的语法框架,能够重建大量的场景类型例如城市、校园等,从单帧图像中。我们的关键思想在于研究如何学习一种新的通识推理框架,能够主要探索两种类型的先验知识:一是单维度下目标的先验分布,例如某个常见物体的长度等形状信息。二是点对级别的关系在实体之间,例如轿车的长度比巴士要段,这些相对的先验几何知识,在常见的场景下都是成立的,能够极大增强在2D&3D场景下的场景理解。方法上来说,我们提出了一种层次化的图结构图表示作为一种联合表示,用于表示输入图像相关的几何知识。我们将这些客观知识公式化表示,用一种联合概率公式,并且开发了一种数据驱动的方法,推测最佳的解决方案,用一种从下到上或者是从上到下的计算方法。
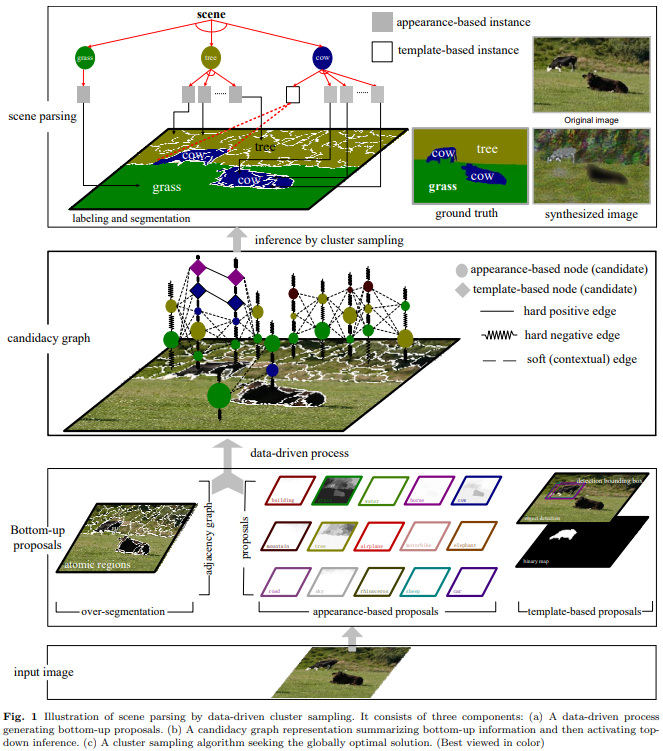
Scene Parsing by Data Driven Cluster Sampling


本文提出一种数据驱动的聚类采样框架,用于解译场景图片到一些常见区域(例如天空,高山,水)和目标(牛,马,车),我们采用了通用模型用于通用区域检测(目标检测和分割),因此他们的置信度概率是通过一些常见的信息投影原则。这种推理算法是一种数据驱动的DDMCMC范式,将目标检测和区域检测模型相互协作和竞争为了实现在贝叶斯框架内的最佳解释。这类算法有两个流程构成:一是自下至上的计算用于通用数据驱动的检测(分割、检测)通过训练一个独一无二的模型根据目标的外表。一个candacy graph的构建可以联合所有的自下而上的信息,通过将这些检测结果作为节点,上下文关系视作边。二是自顶向下,通过聚类采样寻找最优的解决方案,为了最大化贝叶斯后验概率,这类方法包括更有效地探索解空间。在每一步,采样+/-边的概率在candidacy graph中,并将graph拆分成多个子部份。在实验中,我们的算法超越了SOTA方法在LHI 15-class数据集中等等。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











