






标题:A Nonvolatile AI-Edge Processor with 4MB SLC-MLC Hybrid-Mode ReRAM Compute-in-Memory Macro and 51.4-251TOPS/W
机构:台湾清华大学/TSMC
时间:2023/ISSCC
-
边缘设备需要提供短延时和低功耗,从而可以对事件触发的计算任务做出高精度的推理,这需要大容量的非易失存储器来存储断电时的高精度的权重数据和高bit精度的MAC结果。SRAM CIM和数字处理器功耗大延时长。存内计算IMC(in memory computing)提供了短的计算时间和高能效,但是计算效率低。近存计算NMC(near memory computing)提供了高计算效率,但延时长能效低。
-
16.6.1展示了AI边缘处理器的现存挑战:缺少非易失CIM(nvCIM)友好的计算数据流与芯片架构;SLC(single-level-cell)和MLC(multi-level-cell)的工艺偏差,计算产率和面积开销之间的平衡;由于按word输入的稀疏机制以及每个周期统一数量的累加带来的长的计算延时和低能效,
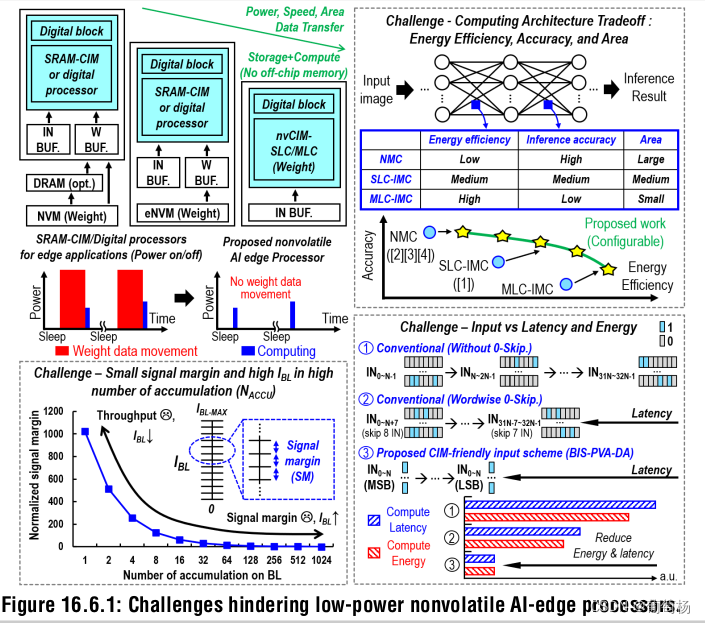
-
本文工作包含混合模式的ReRAM存算宏。
- 可配置电路支持NMC和IMC
- SLC, SLC-MLC, MLC存储模式和计算产率的配置
- 动态累加电流量化来降低IBL的波动和功耗
- 电流电压模式的ADC来扩大感知余量和IMC的计算产率
-
CIM友好的数据流和架构
-
bitwise 的输入稀疏和位置敏感的动态累加来缩短计算时间,增加能效和计算产率。
-
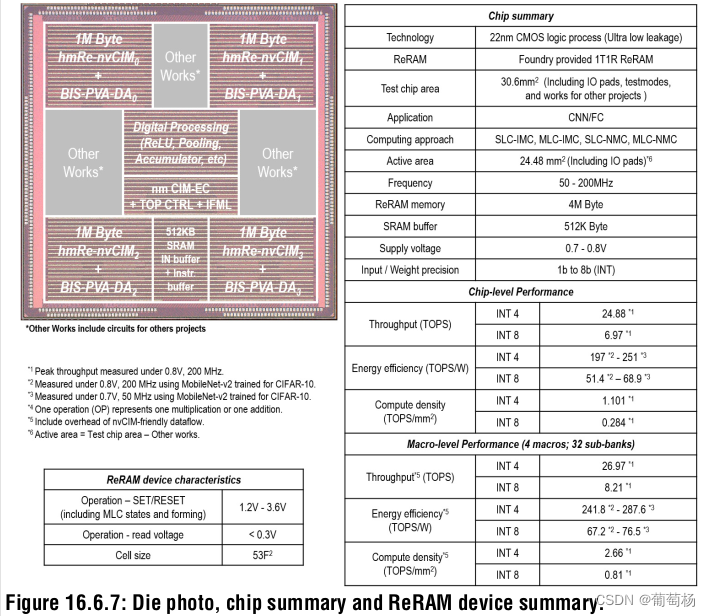
图16.2展示了数据流和处理器架构。nvCIM的使用消除了权重的SRAM BUFFER。4MB = 32 sub-bank = 32 x 128 KB = 32 x 1024 x 1024 b。可提供6种不同的模式来实现神经网络层的不同配置。
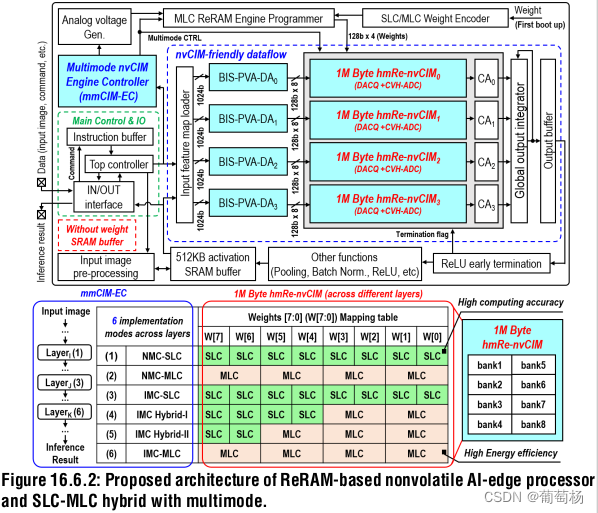
-
图16.6.3展示了权重映射机制。输入8b wordwise会基于BW-IN的值切分成8 bitwise的输入组。对于每个组,会重新安排输入流。1-1, 1-0, 0-0会被分为不同组别。
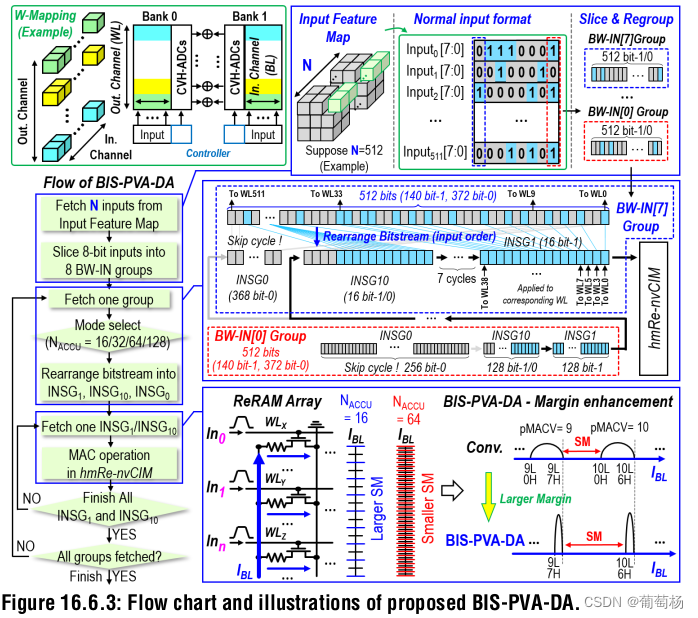
-
图16.6.4 展示了sub bank (512 行1024列?)
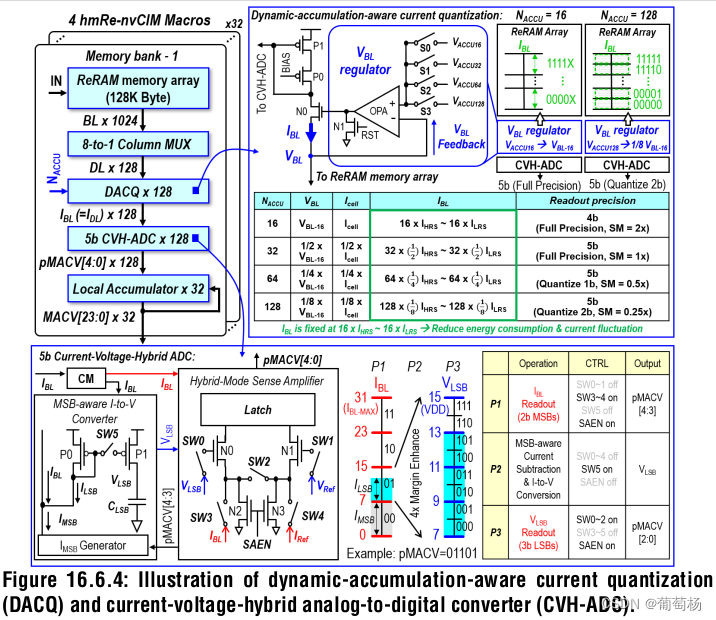
-
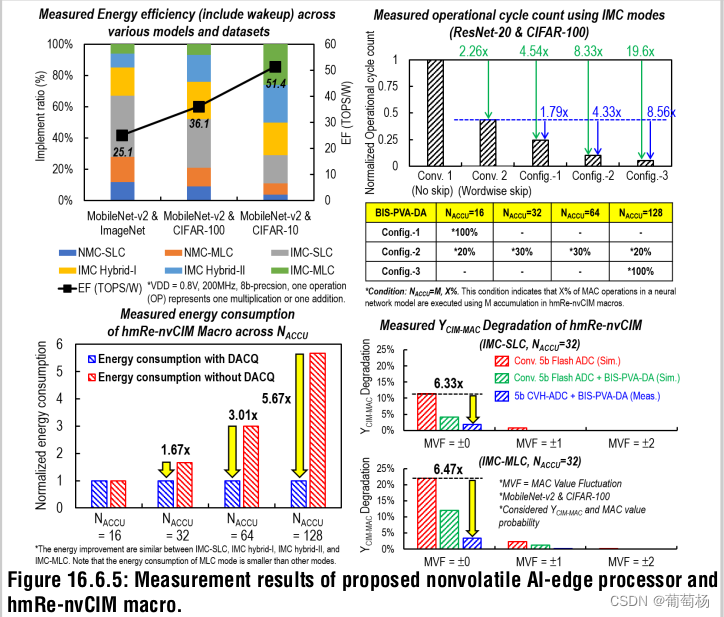
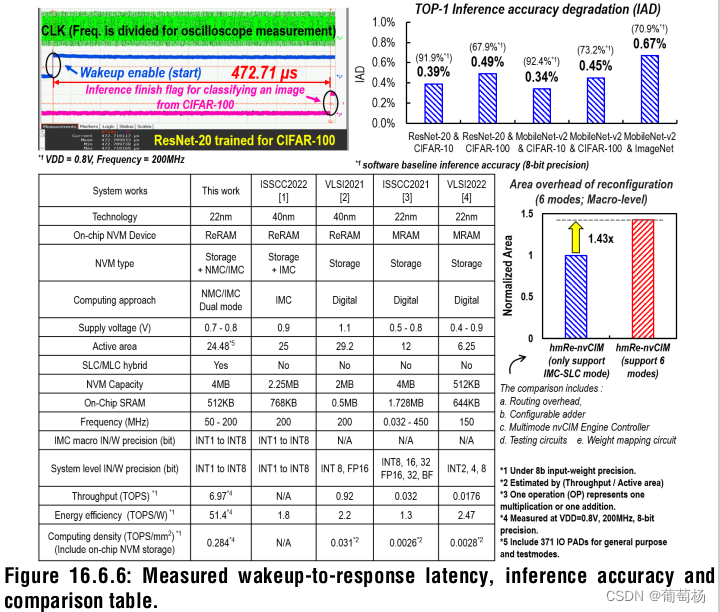
此后的部分展示了测量结果















 1222
1222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









