1. 在代码中,multihead attention(X)的形状和X形状一样,所以才方便将其相加,multihead attention代码和attention代码如下,,在代码中,w_q,w_k,w_v的形状都是(d_model, d_model),得到Q,K,V后将其d_model拆成(h, d_k=d_model//h),最后再拼接成d_model,注意K、V形状一样,Q形状不一定和K、V形状一样
def attention(query, key, value, mask=None, dropout=None):
"""
实现 Scaled Dot-Product Attention
:param query: 输入与Q矩阵相乘后的结果,size = (batch , h , L , d_model//h)
:param key: 输入与K矩阵相乘后的结果,size同上
:param value: 输入与V矩阵相乘后的结果,size同上
:param mask: 掩码矩阵
:param dropout: drop out
"""
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 计算QK/根号d_k,size=(batch,h,L,L)
if mask is not None:
# 掩码矩阵,编码器mask的size = [batch,1,1,src_L]
# 解码器mask的size= = [batch,1,tgt_L,tgt_L]
scores = scores.masked_fill(mask=mask, value=torch.tensor(-1e9))
p_attn = F.softmax(scores, dim = -1)
# 以最后一个维度进行softmax(也就是最内层的行),size = (batch,h,L,L)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
# 与V相乘。第一个输出的size为(batch,h,L,d_model//h),第二个输出的size = (batch,h,L,L)
def clones(module, N):
"工具人函数,定义N个相同的模块"
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout):
"""
实现多头注意力机制
:param h: 头数
:param d_model: word embedding维度
:param dropout: drop out
"""
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
#检测word embedding维度是否能被h整除
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h # 头的个数
self.linears = clones(nn.Linear(d_model, d_model), 4)
#四个线性变换,前三个为QKV三个变换矩阵,最后一个用于attention后
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"""
:param query: 输入x,即(word embedding+postional embedding),size=[batch, L, d_model] tips:编解码器输入的L可能不同
:param key: 同上,size同上
:param value: 同上,size同上
:param mask: 掩码矩阵,编码器mask的size = [batch , 1 , src_L],解码器mask的size = [batch, tgt_L, tgt_L]
"""
if mask is not None:
# 在"头"的位置增加维度,意为对所有头执行相同的mask操作
mask = mask.unsqueeze(1)
# 编码器mask的size = [batch,1,1,src_L]
# 解码器mask的size= = [batch,1,tgt_L,tgt_L]
nbatches = query.size(0) # 获取batch的值,nbatches = batch
# 1) 利用三个全连接算出QKV向量,再维度变换 [batch,L,d_model] ----> [batch , h , L , d_model//h]
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
# view中给-1可以推测这个位置的维度
for l, x in zip(self.linears, (query, key, value))]
# 2) 实现Scaled Dot-Product Attention。x的size = (batch,h,L,d_model//h),attn的size = (batch,h,L,L)
x, self.attn = attention(query, key, value, mask=mask,dropout=self.dropout)
# 3) 这步实现拼接。transpose的结果 size = (batch , L , h , d_model//h)
# view的结果size = (batch , L , d_model)
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x) # size = (batch , L , d_model)
2. 词向量编码和位置编码代码如下,词向量编码后的形状和位置编码后的形状一样,方便相加,送入multihead attention
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
"""
:param d_model: word embedding维度
:param vocab: 语料库词的数量
"""
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
"""
:param x: 一个batch的输入,size = [batch, L], L为batch中最长句子长度
"""
return self.lut(x) * math.sqrt(self.d_model) #这里乘了一个权重,不改变维度. size = [batch, L, d_model]
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
"""
:param d_model: pe编码维度,一般与word embedding相同,方便相加
:param dropout: dorp out
:param max_len: 语料库中最长句子的长度,即word embedding中的L
"""
super(PositionalEncoding, self).__init__()
# 定义drop out
self.dropout = nn.Dropout(p=dropout)
# 计算pe编码
pe = torch.zeros(max_len, d_model) # 建立空表,每行代表一个词的位置,每列代表一个编码位
position = torch.arange(0, max_len).unsqueeze(1) # 建个arrange表示词的位置以便公式计算,size=(max_len,1)
div_term = torch.exp(torch.arange(0, d_model, 2) * # 计算公式中10000**(2i/d_model)
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 计算偶数维度的pe值
pe[:, 1::2] = torch.cos(position * div_term) # 计算奇数维度的pe值
pe = pe.unsqueeze(0) # size=(1, L, d_model),为了后续与word_embedding相加,意为batch维度下的操作相同
self.register_buffer('pe', pe) # pe值是不参加训练的
def forward(self, x):
# 输入的最终编码 = word_embedding + positional_embedding
x = x + Variable(self.pe[:, :x.size(1)],requires_grad=False) #size = [batch, L, d_model]
return self.dropout(x) # size = [batch, L, d_model]
3. 编码器和解码器的mask生成,实际在一个batch中,句子会补充成固定的长度,所以编码器会有mask,但对于时序预测,就没有编码器mask。解码器mask是两个mask的交集(类似于编码器补充成固定长度mask & 下三角mask矩阵)
class Batch:
def __init__(self, src, trg=None, pad=0):
"""
:param src: 一个batch的输入,size = [batch, src_L]
:param trg: 一个batch的输出,size = [batch, tgt_L]
"""
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
#返回一个true/false矩阵,size = [batch , 1 , src_L]
if trg is not None:
self.trg = trg[:, :-1] # 用于输入模型,不带末尾的<eos>
self.trg_y = trg[:, 1:] # 用于计算损失函数,不带起始的<sos>
self.trg_mask = self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).data.sum()
@staticmethod #静态方法
def make_std_mask(tgt, pad):
"""
:param tgt: 一个batch的target,size = [batch, tgt_L]
:param pad: 用于padding的值,一般为0
:return: mask, size = [batch, tgt_L, tgt_L]
"""
tgt_mask = (tgt != pad).unsqueeze(-2)
# 返回一个true/false矩阵,size = [batch , 1 , tgt_L]
tgt_mask = tgt_mask & Variable(
subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
# 两个mask求和得到最终mask,[batch, 1, L]&[1, size, size]=[batch,tgt_L,tgt_L]
return tgt_mask # size = [batch, tgt_L, tgt_L]
def subsequent_mask(size):
"""
:param size: 输出的序列长度
:return: 返回下三角矩阵,size = [1, size, size]
"""
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
#返回上三角矩阵,不带轴线
return torch.from_numpy(subsequent_mask) == 0
#返回==0的部分,其实就是下三角矩阵
4. 残差和层归一化,层归一化是对每个样本所有特征进行均值方差运算,然后对每个样本进行缩放偏移,残差是指 x + f(x),允许信息直接从前面的层流动到后面的层,防止信息在层与层之间的传递中被过多地改变或丢失,缓解深层网络的梯度消失和梯度爆炸问题,注意残差和层归一化未改变形状
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
"""
实现层归一化
"""
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
# 类似BN层原理,对归一化后的结果进行线性偏移,feature=d_model,相当于每个embedding维度偏移不同的倍数
self.b_2 = nn.Parameter(torch.zeros(features))
# 偏置。系数和偏置都为可训练的量
self.eps = eps # 保证归一化分母不为0
def forward(self, x):
"""
:param x: 输入size = (batch , L , d_model)
:return: 归一化后的结果,size同上
"""
mean = x.mean(-1, keepdim=True) # 最后一个维度求均值
std = x.std(-1, keepdim=True) # 最后一个维度求方差
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
#归一化并线性放缩+偏移
class SublayerConnection(nn.Module):
"""
实现残差连接
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size) # 读入层归一化函数
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"""
:param x: 当前子层的输入,size = [batch , L , d_model]
:param sublayer: 当前子层的前向传播函数,指代多头attention或前馈神经网络
"""
return self.norm(x + self.dropout(sublayer(x)))
#这里把归一化已经封装进来,size = [batch , L , d_model]
5. 前馈神经网络代码
class PositionwiseFeedForward(nn.Module):
"实现全连接层"
def __init__(self, d_model, d_ff, dropout):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
"""
:param x: size = [batch , L , d_model]
:return: size同上
"""
return self.w_2(self.dropout(F.relu(self.w_1(x))))
6. 定义encoder layer和encoder
class EncoderLayer(nn.Module):
"""
Encoder层整体的封装,由self attention、残差连接、归一化和前馈神经网络组成
"""
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
#定义多头注意力,即传入一个MultiHeadedAttention类
self.feed_forward = feed_forward
#定义前馈,即传入一个PositionwiseFeedForward类
self.sublayer = clones(SublayerConnection(size, dropout), 2)
#克隆两个残差连接,一个用于多头attention后,一个用于前馈神经网络后
self.size = size
# size是d_model
def forward(self, x, mask):
"""
:param x: 输入x,即(word embedding+postional embedding),size = [batch, L, d_model]
:param mask: 掩码矩阵,编码器mask的size = [batch , 1 , src_L],解码器mask的size = [batch, tgt_L, tgt_L]
:return: size = [batch, L, d_model]
"""
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
#实现多头attention和残差连接,size = [batch , L , d_model]
return self.sublayer[1](x, self.feed_forward)
#实现前馈和残差连接, size = [batch , L , d_model]
encoder layer架构图如下所示

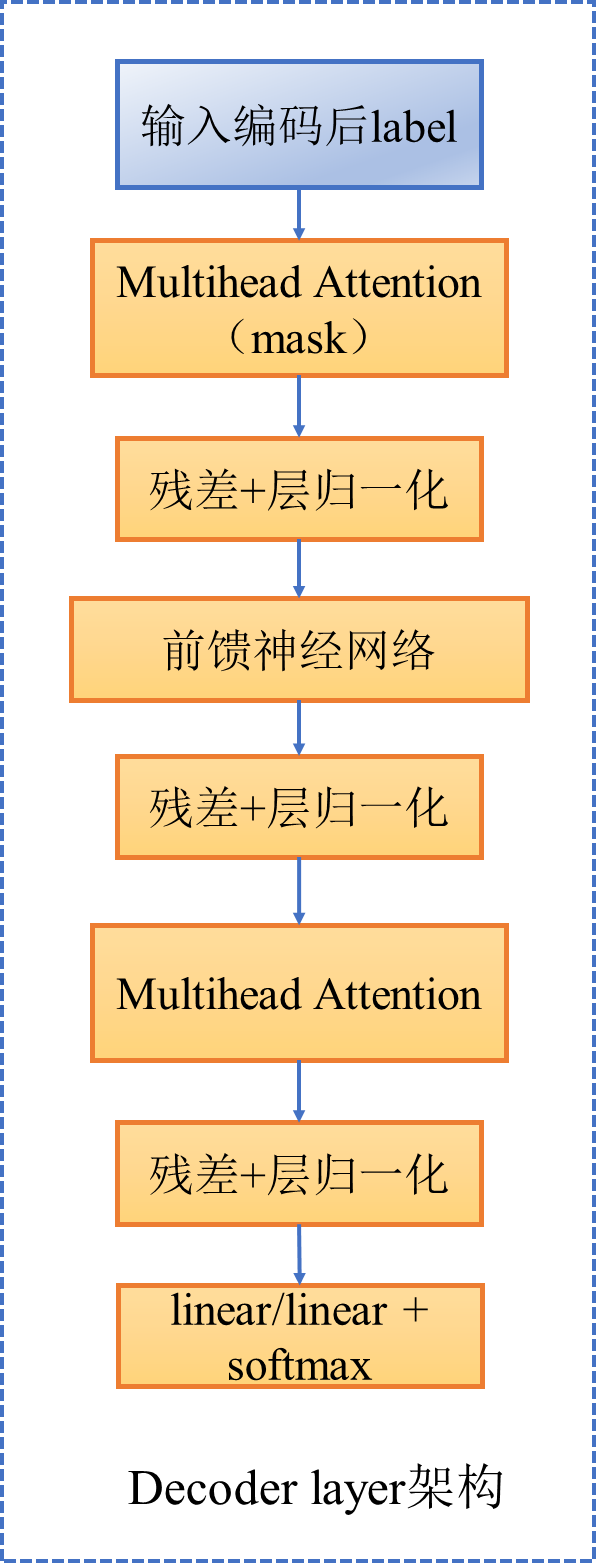
7. 定义decoder layer和decoder,在decoder中,X是label的编码,Q是等于X * w_q,K、V是相同的,都是encoder输出,注意encoder输出会进入到decoder每一层
class DecoderLayer(nn.Module):
"解码器由 self attention、编码解码self-attention、前馈神经网络 组成"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size # embedding的维度
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
#克隆3个sublayer分别装以上定义的三个部分
def forward(self, x, memory, src_mask, tgt_mask):
"""
:param x: target,size = [batch, tgt_L, d_model]
:param memory: encoder的输出,size = [batch, src_L, d_model]
:param src_mask: 源数据的mask, size = [batch, 1, src_L]
:param tgt_mask: 标签的mask,size = [batch, tgt_L, tgt_L]
"""
m = memory
# encoder的KV,size = [batch, L, d_model]
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
# self-atten、add&norm,和编码器一样, size = [batch, tgt_L, d_model]
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
# 编码解码-attention、add&norm,Q来自target,KV来自encoder的输出,size = [batch, tgt_L, d_model]
return self.sublayer[2](x, self.feed_forward)
# 前馈+add&norm, size = [batch, tgt_L, d_model]
class Decoder(nn.Module):
"解码器的高层封装,由N个Decoder layer组成"
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x) # size = [batch, tgt_L, d_model]
decoder layer架构图如下所示
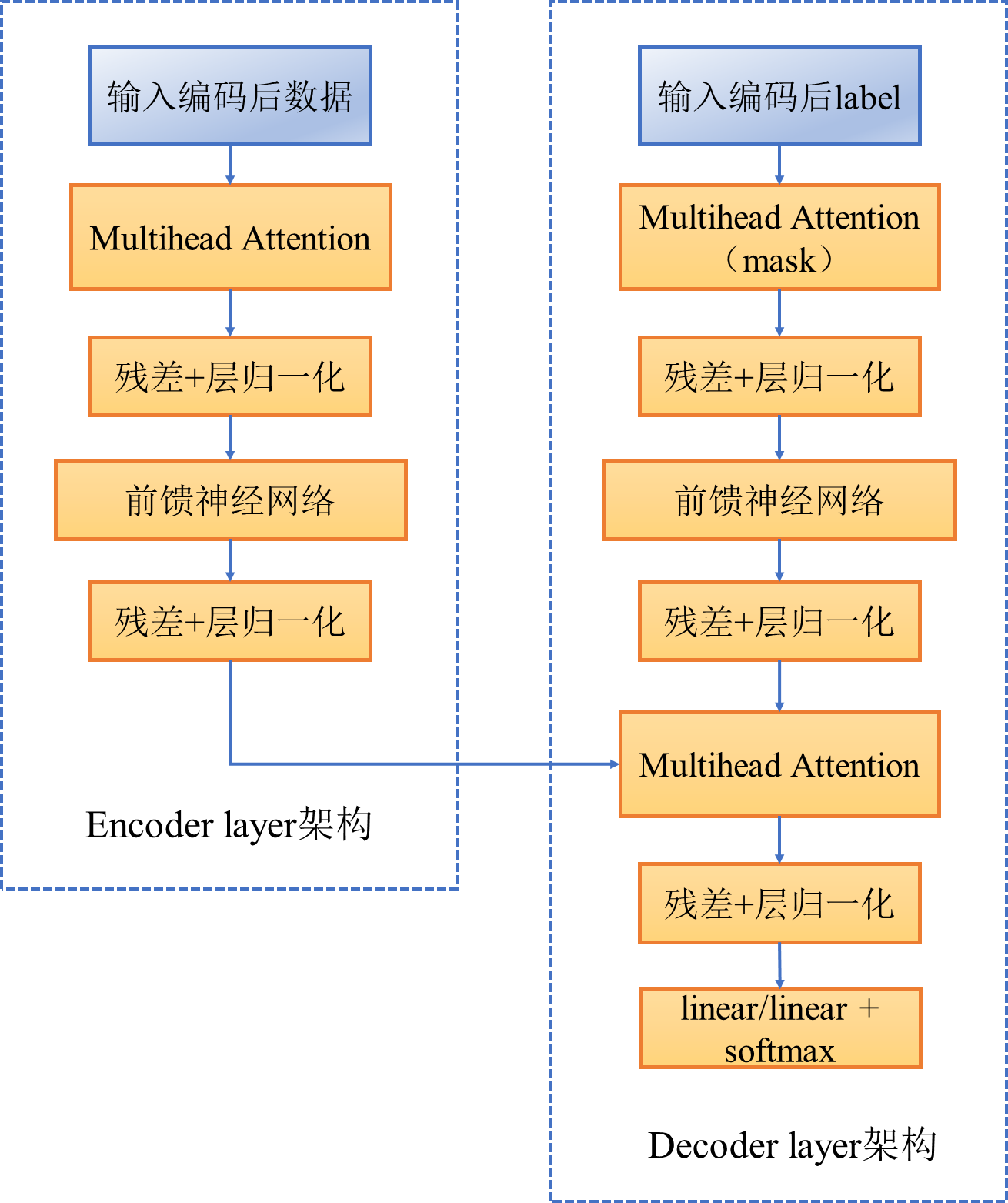
8. 定义encoder和decoder
class EncoderDecoder(nn.Module):
"""
编码解码架构
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder # 编码器
self.decoder = decoder # 解码器
self.src_embed = src_embed #源的embedding
self.tgt_embed = tgt_embed #目标的embedding
self.generator = generator # 定义最后的线性变换与softmax
def forward(self, src, tgt, src_mask, tgt_mask): # 编码解码过程
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
"""
定义一个全连接层+softmax
"""
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab) # vocab为整个词袋的词数
def forward(self, x):
"""
:param x: 输入的 size = [batch, tgt_L, d_model]
"""
return F.log_softmax(self.proj(x), dim=-1) #dim=-1在最后一维上做softmax
整体架构图如下






















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









