







 本文介绍DiffSTG,一种用于概率时空图预测的框架。它结合STGNN时空学习能力与扩散模型不确定度测量,设计UGnet去噪网络,采用非自回归预测架构和样本加速策略。实验表明,该方法在多个数据集上表现良好,能提供可靠概率性预测。
本文介绍DiffSTG,一种用于概率时空图预测的框架。它结合STGNN时空学习能力与扩散模型不确定度测量,设计UGnet去噪网络,采用非自回归预测架构和样本加速策略。实验表明,该方法在多个数据集上表现良好,能提供可靠概率性预测。

Motivations
Motivation of background
当前的STGNN方法不能对STG数据的细微不确定特征(intrinsic uncertainties)进行建模。这些确定性方法很大程度上消减了他们在下游任务做决策时的可用性。
文章中举的这个例子很好:“Figure 1(b) depicts the prediction results of passenger flows in a metro station. In the black box, the deterministic method cannot provide the reliability of its predictions. Conversely, the probabilistic method renders higher uncertainties (see the green shadow), which indicates a potential outbreaking of passenger flows in that region. By knowing a range of possible outcomes we may experience and the likelihood of each, the traffic system is able to take operations in advance for public safety management.”
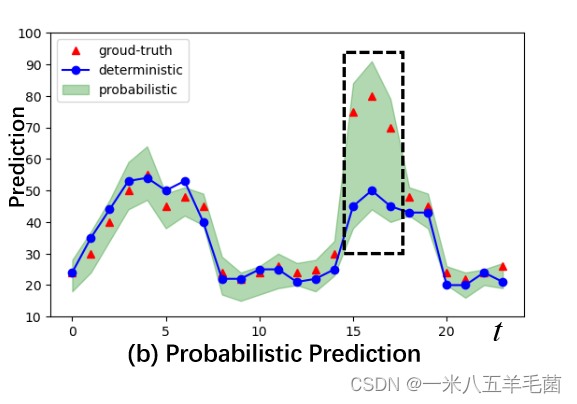
比如对行人流量进行预测,黑框中是我们要预测的区域,而像STGNN那样的方法,我们只能预测到蓝色线段(deterministic),而概率方法可以给出更高的不确定度,也就是图中的绿色区域(probabilistic),他比确定性方法来说更可能涵括正确的预测,也就是图中的红色标识(ground-truth)。通过知道可能结果的范围以及每种结果的可能性,交通系统能够针对公共安全管理提前做出措施。
Motivation of solution
利用时间序列概率模型来对STG建模仍具有一些挑战:
- 他们只是针对一个节点来建模它时间上的关系,而没有考虑到不同节点之间空间上的关系。
- 时间序列概率模型在训练和推理时的效率较低,对于长期预测来说比较困难。
Q1. 其实也有别的针对时间序列的概率方法,文中也提到过:“While prior endeavors on stochastic STG forecasting were conventionally scarce, we are witnessing a blossom of probabilistic models for time series forecasting [25, 29, 30].” (Wen 等, 2023, p. 1) (pdf) ,但是为什么他们用diffusion model?
Contribution
- 他们第一个从score-based扩散角度来解决概率STG预测的问题;
- 他们首次提出了为STG设计的UGNet去噪网络;
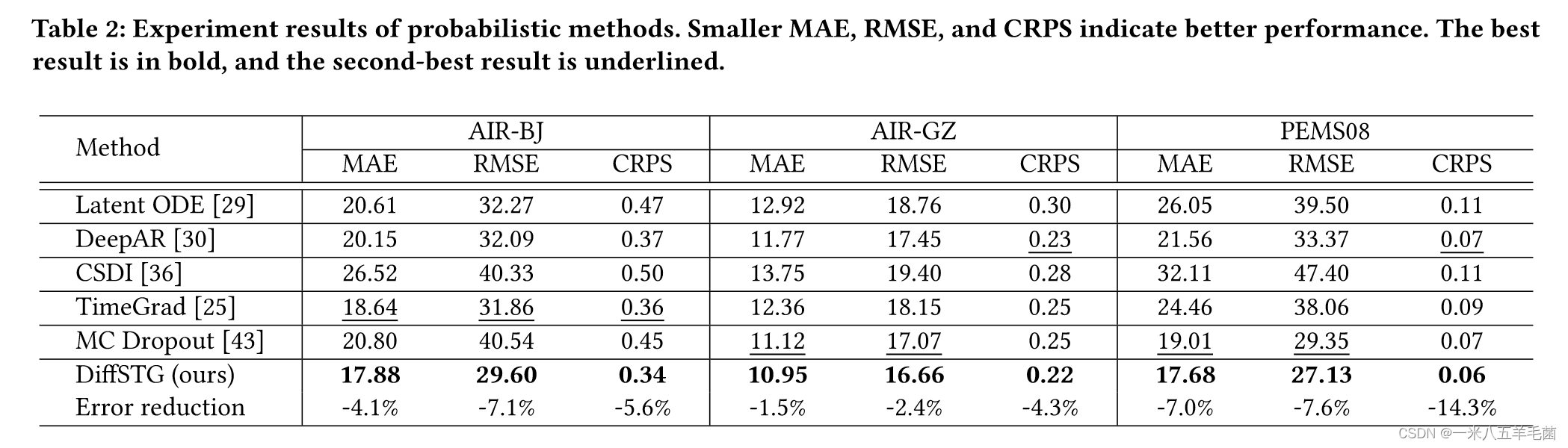
- 他们的实验结果表明所提出的DiffSTG对比已有的概率模型,在CRPS(Continuous Ranked Probability Score)指标上降低了4%-14%,在RMSE上降低了2%-7%。
Notes: 什么是CRPS?
知乎讲解
连续分级概率评分(CRPS)是将单个真实值与累积分布函数(CDF)进行比较,也就是与其预测分布进行比较。这在模型输出的分布预测而不是逐点估计的情况下,可以看作是MAE对分布预测的推广。其公式为:
C
R
P
S
(
F
,
y
)
=
∫
(
F
(
x
)
−
I
{
x
≥
y
}
)
2
d
x
CRPS(F, y) = \int{(F(x)-I_{\{x\geq y\}})^2}dx
CRPS(F,y)=∫(F(x)−I{x≥y})2dx
在计算测试集每个观察值的CRPS后,需要将结果聚合成一个值,与RMSE和MSE类似,使用(或加权)平均对他们进行汇总:
∑
i
ω
i
∫
(
F
^
i
(
x
)
−
I
{
x
≥
y
i
}
)
2
d
x
;
∑
i
ω
i
=
1
\sum_i{\omega_i\int{(\hat F_i(x)-I_{\{x\geq y_i\}})^2}dx}; \sum_i{\omega_i}=1
i∑ωi∫(F^i(x)−I{x≥yi})2dx;i∑ωi=1
这里的单值实际上被转换成了分布的表示,也就是将真值转换为带有指标函数的退化分布。例如真值为7,那么:
P
(
7
≤
y
)
=
I
{
y
≥
7
}
=
{
0
,
i
f
y
<
7
1
,
o
t
h
e
r
w
i
s
e
P(7\leq y)=I_{\{y\geq 7\}}= \left\{ \begin{array}{rcl} 0, &if\,y<7 \\ 1, &otherwise \end{array} \right.
P(7≤y)=I{y≥7}={0,1,ify<7otherwise
我们希望预测分布尽可能接近真实情况,CRPS计算的实际上是两个CDF之间的平方面积,如下图所示,当然是希望这个面积越小越好:

Solution
这篇文章主要针对概率时空图预测,它在对不确定特征和复杂的ST关系建模上具有挑战性。”uncertainties” <–> “probabilistic“
他们提出DiffSTG,结合了STGNN的时空学习能力和diffusion model的不确定度测量。
针对上述挑战,他们分别提出了应对措施:
- 针对扩散模型中的去噪网络,他们设计了名为UGnet的网络,利用基于Unet的架构来提取多尺度时间关系,并且利用GNN来建模空间关系。“Targeting the first challenge, we devise an effective module (UGnet) as the denoising network of DiffSTG. As its name suggests, UGnet leverages a Unet-based architecture [28] to capture multiscale temporal dependencies and GNN to model spatial correlations.”
- 他们提出的DiffSTG生成未来样本的方法是基于非自回归风格的,也就是说他们不是一步一步生成样本,而是一次性生成多尺度的预测。“To overcome the second issue, our DiffSTG produces future samples in a non-autoregressive fashion. In other words, our framework efficiently generates multihorizon predictions all at once, rather than producing them step by step as what TimeGrad did.”
DiffSTG Formulation
- G = { V , E , A } G = \{V, E, A\} G={V,E,A}—图;
- A ∈ R V × V A \in \mathbb{R}^{V \times V} A∈RV×V—带权重的邻接矩阵,用来描述图的拓扑结构;
- x t ∈ R F × V x_t \in \mathbb{R}^{F \times V} xt∈RF×V —在时刻 t t t,通过 V V V个节点生成的维度为 F F F的信号;其实也可以理解为该时刻图的特征;
给定历史图 G G G在前 T h T_h Th个时间步长的图信号(特征) x h = [ x 1 , . . . , x T h ] x^h=[x_1,...,x_{T_h}] xh=[x1,...,xTh]作为输入,STG预测的目标在于学习到一个函数 F \mathscr{F} F,来预测未来 T p T_p Tp步的图信号 x p x^p xp: F : ( x h ; G ) → [ x T h + 1 , … , x T h + T p ] : = x p \mathscr{F}:(x^h;G) \to [x_{T_{h+1}}, …, x_{T_{h+T_p}}]:=x^p F:(xh;G)→[xTh+1,…,xTh+Tp]:=xp
Conditional Diffusion Model
为了基于STG预测任务建模,直观的方法就是让历史数据
x
h
x^h
xh和图结构
G
G
G作为概率条件,逆向去噪过程可以表示为:
p
θ
(
x
0
:
N
p
∣
x
h
,
G
)
=
p
(
x
N
p
)
∏
n
=
N
1
p
θ
(
x
n
−
1
p
∣
x
n
p
,
x
h
,
G
)
p_\theta(x_{0:N}^p|x^h, G) = p(x_N^p) \prod_{n=N}^1{p_\theta(x_{n-1}^p|x_n^p, x^h, G)}
pθ(x0:Np∣xh,G)=p(xNp)n=N∏1pθ(xn−1p∣xnp,xh,G)
训练目标可以表示为:
min
θ
L
(
θ
)
=
min
θ
E
x
0
p
,
ϵ
∥
ϵ
−
ϵ
θ
(
x
n
p
,
n
∣
x
h
,
G
)
∥
2
2
\min_\theta{\mathscr{L}(\theta)}=\min_\theta{\mathbb{E}_{x_0^p, \epsilon}\parallel{\epsilon-\epsilon_\theta(x_n^p, n|x^h, G)}\parallel_2^2}
θminL(θ)=θminEx0p,ϵ∥ϵ−ϵθ(xnp,n∣xh,G)∥22
Generalized Conditional Diffusion Model
在上面的公式中,条件
x
h
x^h
xh和去噪的目标
x
p
x^p
xp被分开在了两个样本空间中,即:
x
h
∈
X
h
x^h \in X^h
xh∈Xh,
x
p
∈
X
p
x^p \in X^p
xp∈Xp,但是他们实际上是两段连续的时间序列。他们将历史
x
h
x^h
xh和未来
x
p
x^p
xp视作一个整体:
x
a
l
l
=
[
x
h
,
x
p
]
∈
R
F
×
V
×
T
x^{all}=[x^h, x^p]\in\mathbb{R}^{F\times V\times T}
xall=[xh,xp]∈RF×V×T
其中,
T
=
T
h
+
T
p
T=T_h+T_p
T=Th+Tp。那么历史数据可以看作是遮住所有未来时间的
x
a
l
l
x^{all}
xall。这样一来,条件就变成了
x
m
s
k
a
l
l
x_{msk}^{all}
xmskall,去噪目标变成了
x
a
l
l
x^{all}
xall,他们共享同一个样本空间
X
a
l
l
X^{all}
Xall。上面的公式可以改写为:
p
θ
(
x
0
:
N
a
l
l
∣
x
m
s
k
a
l
l
,
G
)
=
p
(
x
N
a
l
l
)
∏
n
=
N
1
p
θ
(
x
n
−
1
a
l
l
∣
x
n
a
l
l
,
x
m
s
k
a
l
l
,
G
)
p_\theta(x_{0:N}^{all}|x_{msk}^{all}, G) = p(x_N^{all}) \prod_{n=N}^1{p_\theta(x_{n-1}^{all}|x_n^{all}, x_{msk}^{all}, G)}
pθ(x0:Nall∣xmskall,G)=p(xNall)n=N∏1pθ(xn−1all∣xnall,xmskall,G)
min
θ
L
(
θ
)
=
min
θ
E
x
0
a
l
l
,
ϵ
∥
ϵ
−
ϵ
θ
(
x
n
a
l
l
,
n
∣
x
m
s
k
a
l
l
,
G
)
∥
2
2
\min_\theta{\mathscr{L}(\theta)}=\min_\theta{\mathbb{E}_{x_0^{all}, \epsilon}\parallel{\epsilon-\epsilon_\theta(x_n^{all}, n|x_{msk}^{all}, G)}\parallel_2^2}
θminL(θ)=θminEx0all,ϵ∥ϵ−ϵθ(xnall,n∣xmskall,G)∥22
为什么要这么做?论文中给出了两点原因:
- 修改后的loss函数统一了历史数据和预测数据的重建,这样历史数据能更加充分的被利用来建模数据分布。“Firstly, the loss in Eq. (14) unifies the reconstruction of the history and estimation of the future, so that the historical data can be fully utilized to model the data distribution.”
- 这样可以统一不同的STG任务到同样的框架下,包括STG预测、生成和插值等等。
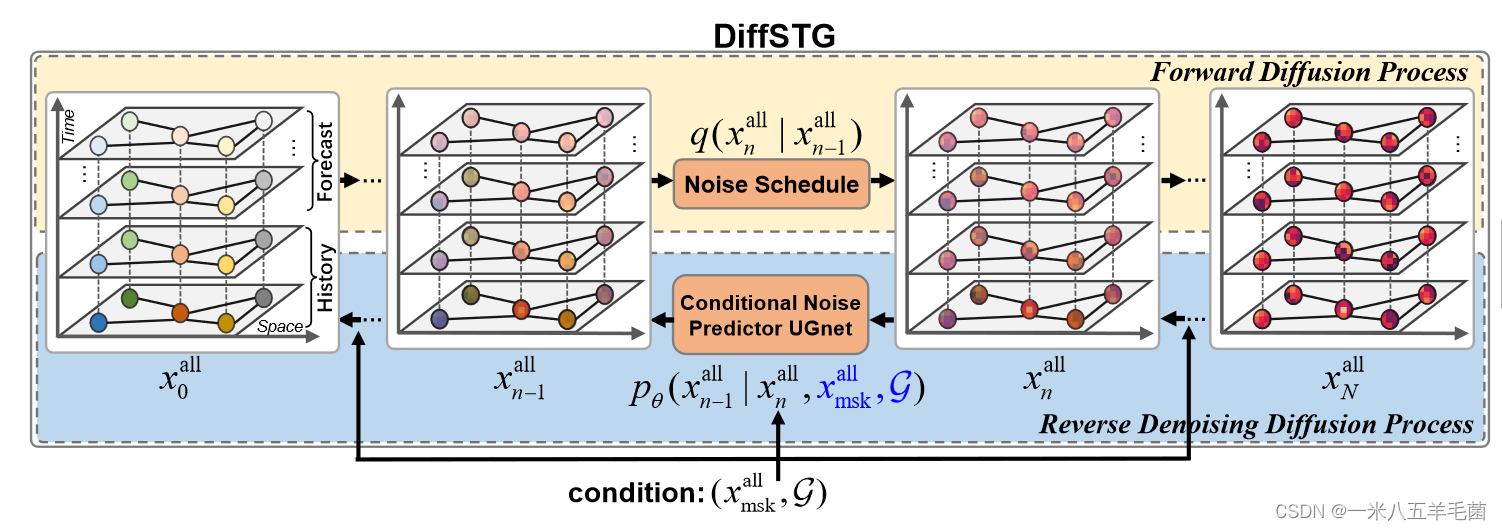
DiffSTG Implementation
Denoising Network: UGnet
去噪网络 ϵ θ \epsilon_\theta ϵθ在之前的工作中可以被分为两类,一类是基于Unet结构(主要用来做与图像相关的任务),一类是基于WaveNet结构(主要用来做与序列相关的任务)。但这些网络往往是将输入视为网格(grids)或者块(segments),缺少提取STG数据中时空关系的能力。
因此,他们提出了UGnet,在时间维度上采用了Unet的结构,在不同的时间粒度来提取时间关系(例如15分钟或者30分钟);利用GNN来对空间关系进行建模。“To bridge this gap, we propose a new denoising network 𝝐𝜃 (Xall × R|Xall msk, G) → Xall, named UGnet. It adopts an Unet-like architecture in the temporal dimension to capture temporal dependencies at different granularities (e.g., 15 minutes or 30 minutes), and utilizes GNN to model the spatial correlations.”
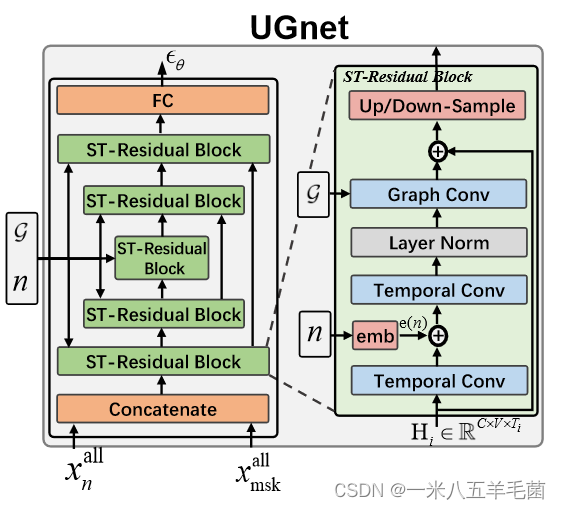
总体过程:
- 首先将 x n a l l ∈ R F × V × T x_n^{all}\in \mathbb{R}^{F\times V\times T} xnall∈RF×V×T和 x m s k a l l ∈ R F × V × T x_{msk}^{all}\in \mathbb{R}^{F\times V\times T} xmskall∈RF×V×T连接起来,变成一个新的tensor: x ~ n a l l ∈ R F × V × 2 T \tilde x_n^{all}\in \mathbb{R}^{F\times V\times 2T} x~nall∈RF×V×2T
- 通过一个线性层映射为一个高纬度特征表示: H ∈ R C × V × 2 T H\in \mathbb{R}^{C\times V\times 2T} H∈RC×V×2T,其中 C C C为映射后的维度
- 然后 H H H被送入几个ST-Residual块,每一个都分别提取时间和空间关系
这里用 H i ∈ R C × V × T i H_i\in \mathbb{R}^{C\times V\times T_i} Hi∈RC×V×Ti表示第i个ST-Residual的输入。( H 0 = H H_0=H H0=H, T i T_i Ti是时间维度的长度,可能经过ST-Residual输出会变化)
Temporal Dependency Modeling
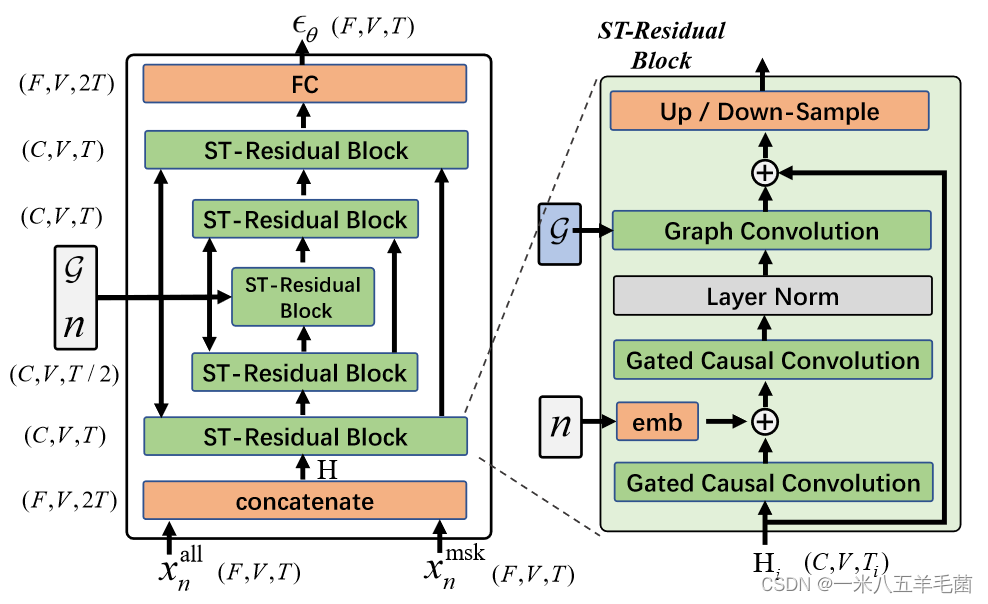
这里
H
i
H_i
Hi首先被送入一个TCN层来建模时间关系,他采用的是一个**一维门限因果卷积(1D gated causal convolution)**:
Γ
γ
(
H
i
)
=
P
i
⊙
σ
(
Q
i
)
∈
R
C
o
u
t
×
V
×
T
i
\Gamma_\gamma(H_i)=P_i\odot \sigma(Q_i)\in \mathbb{R}^{C_{out}\times V\times T_i}
Γγ(Hi)=Pi⊙σ(Qi)∈RCout×V×Ti
其中, Γ γ ∈ R K × C i n t × C o u t t \Gamma_\gamma\in \mathbb{R}^{K\times C_{in}^t\times C_{out}^t} Γγ∈RK×Cint×Coutt表示卷积核,它可以将输入 H i ∈ R C × V × T i H_i\in \mathbb{R}^{C\times V\times T_i} Hi∈RC×V×Ti映射到具有相同大小的输出 P i , Q i ∈ R C o u t t × V × T i P_i, Q_i \in \mathbb{R}^{C_{out}^t\times V\times T_i} Pi,Qi∈RCoutt×V×Ti。
σ ( Q i ) \sigma(Q_i) σ(Qi)可以被是为一个门限,可以过滤出有用的信息 P i P_i Pi进入下一层。TCN的输出表示为 H ˉ i \bar H_i Hˉi。
Spatial Denpendency Modeling
利用GCN在空间领域来提取特征:
Γ G ( H ˉ i ) = σ ( Φ ( A g c n , H ˉ i ) W i ) \Gamma_G(\bar H_i)=\sigma(\Phi(A_{gcn}, \bar H_i)W_i) ΓG(Hˉi)=σ(Φ(Agcn,Hˉi)Wi)
其中, W i ∈ R C i n g × C i n g W_i\in \mathbb{R}^{C_{in}^g\times C_{in}^g} Wi∈RCing×Cing表示可训练参数, σ \sigma σ是激活函数。 Φ ( ) \Phi() Φ()是聚合函数,用来决定哪些邻居特征要被聚合到目标节点中,他们使用的是最经典的GCN,具体将其定义为一个对称的归一化的聚合函数:
Φ g c n ( A g c n , H i ˉ ) = A g c n H i ˉ \Phi_{gcn}(A_{gcn}, \bar{H_i})=A_{gcn}\bar{H_i} Φgcn(Agcn,Hiˉ)=AgcnHiˉ
其中, A g c n = D − 1 2 ( A + I ) D − 1 2 ∈ R V × V A_{gcn}=D^{-\frac{1}{2}}(A+I)D^{-\frac{1}{2}}\in \mathbb{R^{V\times V}} Agcn=D−21(A+I)D−21∈RV×V是一个标准化后的邻接矩阵。 D D D是对角度矩阵, D i i = ∑ j ( A + I ) i j D_{ii}=\sum_j(A+I)_{ij} Dii=∑j(A+I)ij。
值得一提的是,他们将TCN层的输出的大小变成了 H i ˉ ∈ R V × C i n g \bar{H_i}\in \mathbb{R^{V\times C_{in}^g}} Hiˉ∈RV×Cing,这里 C i n g = T i × C o u t t C_{in}^g=T_i\times C_{out}^t Cing=Ti×Coutt,然后再把这个节点特征 H i ˉ \bar{H_i} Hiˉ送入GCN。
Noise Level Embedding
在这里记录一下为什么要有noise level embedding:我们每一步去噪的网络都是同一个网络,也就是这里的UGnet。拿cv生成任务来说,如果单独输入一张带有噪声的图,他并不知道这张图的噪声情况,就无法合理恢复噪声,所以我们输入图的同时,还要输入噪声等级(noise level)去告诉网络噪声的情况,也就是当前是denoise的哪一步。
他们对采用了transformer的位置编码:
e
(
n
)
=
[
.
.
.
,
c
o
s
(
n
/
r
−
2
d
D
)
,
s
i
n
(
n
/
r
−
2
d
D
)
]
T
e(n)=[..., cos(n/r^{\frac{-2d}{D}}), sin(n/r^{\frac{-2d}{D}})]^T
e(n)=[...,cos(n/rD−2d),sin(n/rD−2d)]T
他们所提出的UGnet和CV任务中普遍使用的Unet相比,有什么不一样的地方?
- Unet是用来从欧式数据中提取语义特征的(例如图像),而UGnet是用来为非欧式的STG数据建模时空关系的。
- Unet中的U型结构用来聚合空间维度的特征,进而提取图像中高层次的语义特征,而UGnet中的U型结构聚合的是时间维度的特征,进而提取不同粒度的时间关系。
- Unet利用二维CNN提取空间关系,而UGnet利用图卷积来建模空间关系,因而更适合基于图的数据。
Sampling Acceleration
因为要得到一个好的结果,N往往被设置的很大(例如1000),但这样就使得采样过程很低效,因为需要进行N次迭代推理。为了加速采样过程,他们采用了DDIM(Song 等, 2022)中的采样加速方式。
Q2. “reducing the number of the reverse diffusion process from 𝑆 to 𝑆/𝑘” ?
Experiments
Experimental Setup
- 数据集:一个交通流数据集PEMS08(他们用了STSGCN提取的数据集),两个空气质量数据集AIR-BJ和AIR-GZ。这三个数据集的邻接矩阵是根据真实道路构建的,如果两个传感器在同一条道路上,那么这两个节点在空间网络上是视为有连接的。

- Baselines
- Probabilistic baselines:
- Latent ODE
- DeepAR
- TimeGrad
- CSDI
- MC Dropout
- Deterministic baselines
- DCRNN
- STGCN
- STGNCDE
- GMSDR
- Probabilistic baselines:
- Metrics:
- Probabilistic baselines: Continuous Ranked Probability Score (CRPS)
- Deterministic baselines: MAE+RMSE
- 实施细节:我们还通过平均𝑆个(在我们的论文中设置为 8)生成的样本来报告确定性预测结果的 MAE 和 RMSE。 请注意,CRPS 仍然是评估这些概率方法性能的主要指标。
Performance Comparison
- Probabilistic methods:
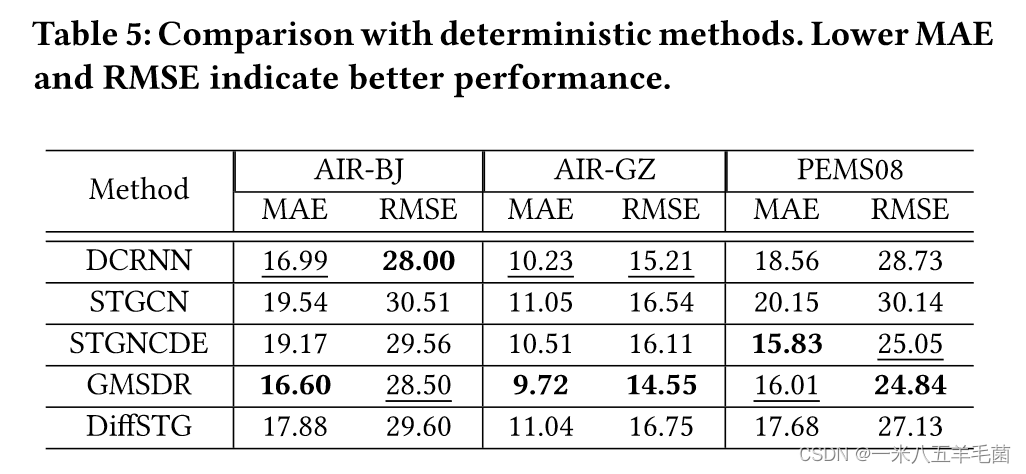
- Deterministic baselines:
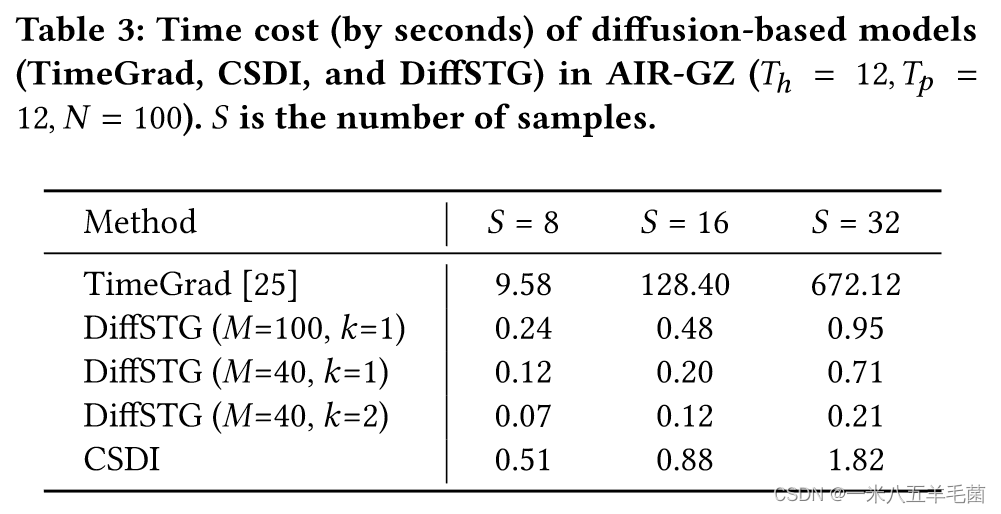
Inference Time
通常来讲,基于diffusion的方法都要比其他方法推理速度要慢,但是他们能够呈现更好的模型表现力。所以他们在这里只对基于diffusion方法进行比较,包括DiffSTG,TimeGrad和CSDI。
- TimeGrad因为它本身的循环结构,导致他的速度是最慢的。
- 这里DiffSTG的M和k是指做加速后的前向步数(原本是N)和后向步数。 M = 100 , k = 1 M=100, k=1 M=100,k=1是没有加速的,也比TimeGrad快乐40多倍。
- 当样本数量S更大时,我们可以通过增加k的大小来保证效率,同时没有性能的损失。
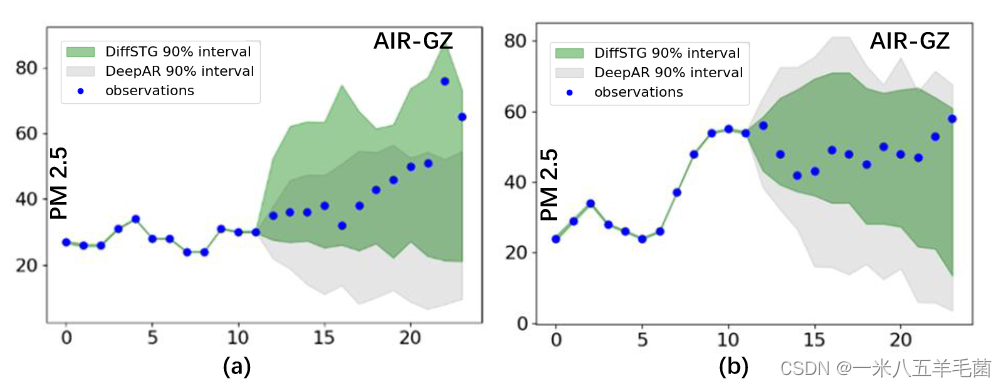
Visualization
- 不同概率方法之间的比较:可以看出DiffSTG更能涵括ground-trueth,能提供能可靠的结果。
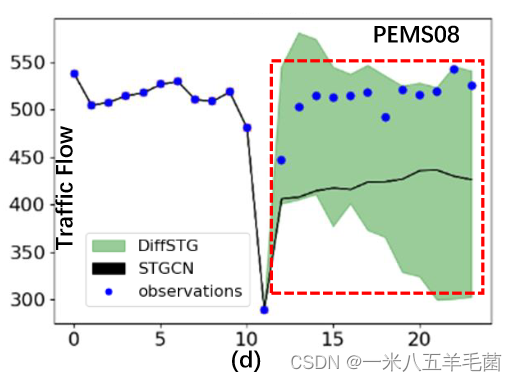
 - 因为diffusion model有对数据分布学习的能力,他们测试了DiffSTG对历史数据重建的能力。 - DiffSTG和确定性方法STGCN的比较。可以看出STGCN对于这种随机性大的预测并不能给出可靠的结果。
- 因为diffusion model有对数据分布学习的能力,他们测试了DiffSTG对历史数据重建的能力。 - DiffSTG和确定性方法STGCN的比较。可以看出STGCN对于这种随机性大的预测并不能给出可靠的结果。
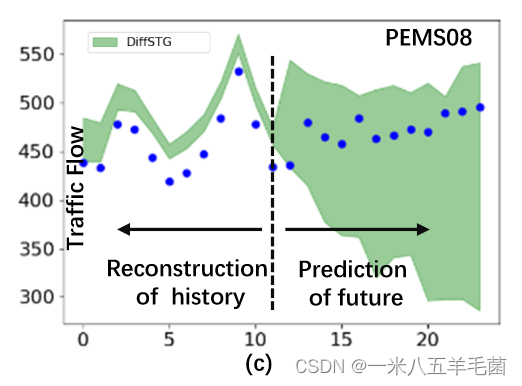
- DiffSTG和确定性方法STGCN的比较。可以看出STGCN对于这种随机性大的预测并不能给出可靠的结果。
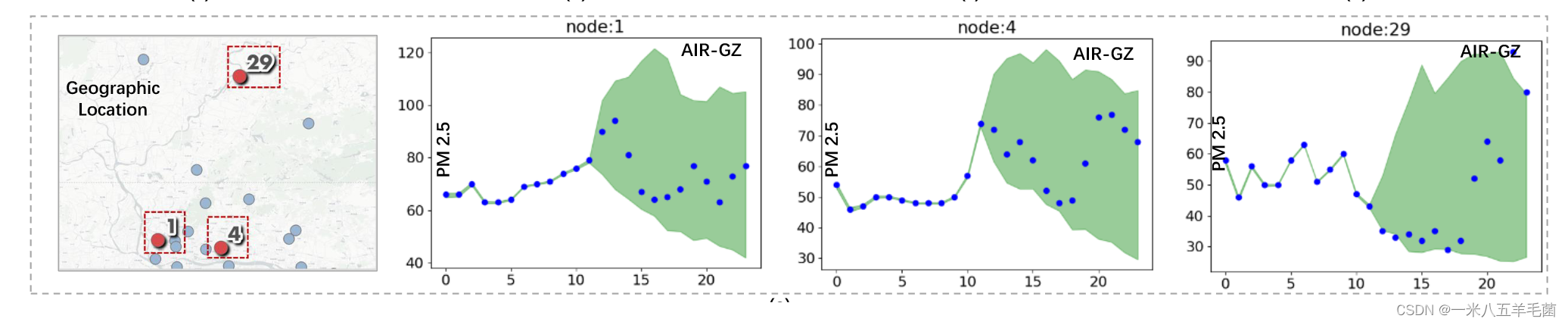
- 同时,他们还对DiffSTG的空间建模能力进行了可视化。可以看出,节点1和4距离比较近,所以他们空气质量情况相似是合理的。
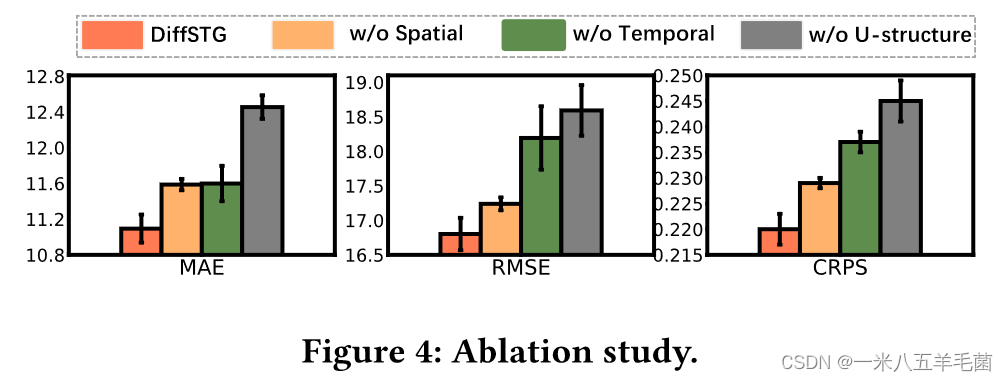
Ablation Study
- w/o Spatial: 除去GNN。
- w/o Temporal: 除去TCN。
- w/o U-structure: 除去Unet结构,并且只用一层TCN进行特征提取。
Hyperparameter Study
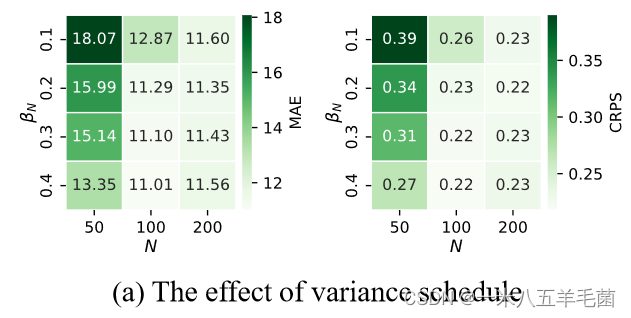
- 不同加噪方案的影响(
β
N
\beta_N
βN和
N
N
N):可以看到当
N
=
50
N=50
N=50,
β
N
=
0.1
\beta_N=0.1
βN=0.1时,结果最不好,这是因为前向加噪的最后并没有将分布变为一个高斯分布,因此违背了后向去噪的假设,是不合理的。可以看出,当N越大,结果越好。
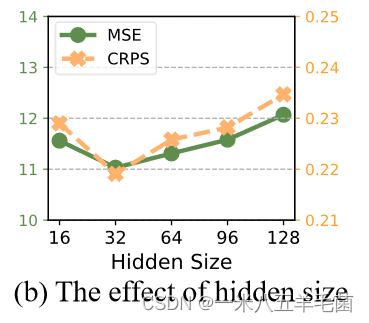
- 隐含层的影响(hidden size C)
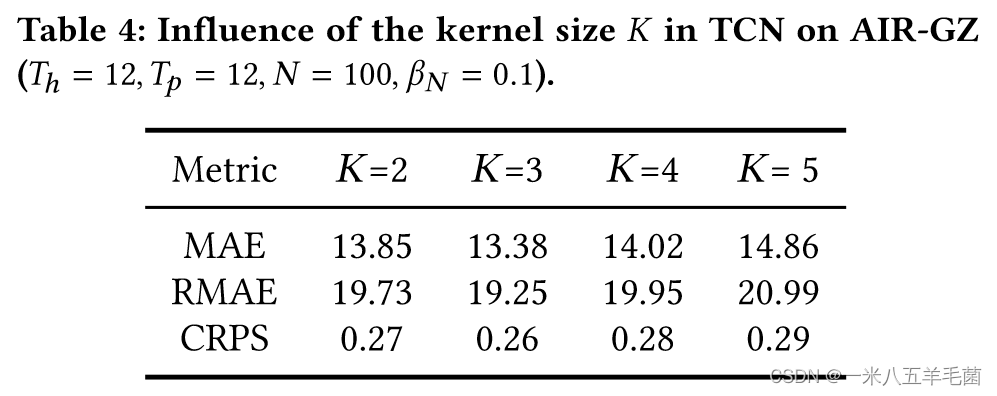
- TCN中卷积核K的大小的影响
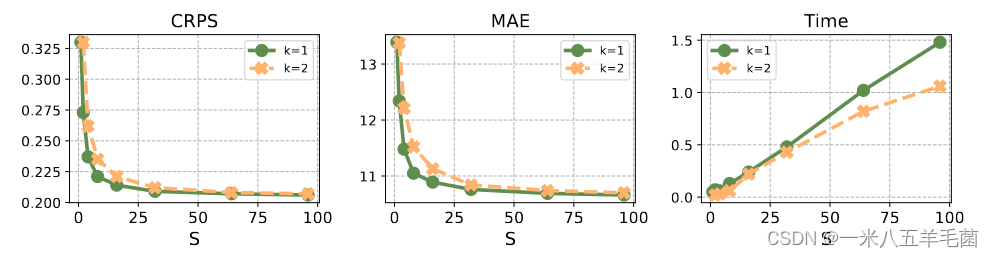
- 生成样本数量S的影响和加速参数k的影响:他们在这里给出了两个建议,当S比较小时,k尽量也选小一点;当S比较大时,为了保持模型效率,k也要跟着增大,这样不会损失其性能。
Limitations
其实在与确定性方法进行比较时可以发现DiffSTG的表现并不是很出色。这是因为:与确定性方法不同,DiffSTG的优化目标是从变分推理的角度得出的,其中当数据样本不足时,所学习的后验分布可能不准确。“Different from deterministic methods, the optimization goal of DiffSTG is derived from a variational inference perspective (see details in Appendix. A.1), where the learned posterior distribution might be inaccurate when the data samples are insufficient.” (Wen 等, 2023, p. 9) (pdf)
他们强调的一点是:DiffSTG有提供概率性预测的能力。这是他们research的出发点,因为甚至基于GNN的SOTA方法都不能提供这一点。
Conclusion
他们是第一个将DDPM推广到时空图的工作,提出了一种称为 DiffSTG 的新颖概率框架,用于时空图预测。
DiffSTG 将 STGNN 的时空学习能力与扩散模型的不确定性测量相结合。 他们设计了去噪网络 UGnet,用于捕获 STG 数据中的空间和时间相关性。 通过利用基于 Unet 的架构来捕获多尺度时间依赖性,并利用图神经网络 (GNN) 来建模空间相关性。此外,他们设计的非自回归预测架构和样本加速策略来加快训练和推理速度。大量的实验证明了他们提出的方法的有效性和效率。
未来工作:为了模型的简单性,他们仅在去噪网络中使用普通 GCN,因此仍然可以合并更强大的图神经网络,以更好地捕获数据中的 ST 依赖性。 另一个方向是将 DiffSTG 应用于其他时空学习任务,例如时空图插补。

















 4049
4049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









