







 论文《SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks》提出了一种新的注意力模块SimAM,它无需额外参数即可实现特征图的三维注意力权重推断。SimAM基于神经科学理论,通过优化能量函数计算神经元重要性,并通过简单的闭合形式解实现。在ImageNet、CIFAR等任务中,SimAM提升了网络性能且易于实现,适用于资源受限的环境和轻量级模型。"
132387834,19048838,UG次开发:读取装配体体TAG号的方法,"['UG开发', 'API接口', 'C++编程', 'C#编程', '软件开发']
论文《SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks》提出了一种新的注意力模块SimAM,它无需额外参数即可实现特征图的三维注意力权重推断。SimAM基于神经科学理论,通过优化能量函数计算神经元重要性,并通过简单的闭合形式解实现。在ImageNet、CIFAR等任务中,SimAM提升了网络性能且易于实现,适用于资源受限的环境和轻量级模型。"
132387834,19048838,UG次开发:读取装配体体TAG号的方法,"['UG开发', 'API接口', 'C++编程', 'C#编程', '软件开发']

论文名称:《SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks》
论文地址:http://proceedings.mlr.press/v139/yang21o/yang21o.pdf
代码地址:https://github.com/ZjjConan/SimAM
在这篇论文中,我们提出了一个概念上简单但非常有效的注意力模块,用于卷积神经网络。与现有的基于通道和空间的注意力模块不同,我们的模块通过推断特征图中的三维注意力权重来工作,而无需向原始网络添加参数。具体而言,我们基于一些著名的神经科学理论,并提出了优化能量函数以找到每个神经元重要性的方法。我们进一步推导了能量函数的快速闭合形式解,并展示了该解可以用不到十行代码实现。该模块的另一个优点是,大多数运算符是基于定义的能量函数解的选择,避免了过多的结构调整的工作。对各种视觉任务的定量评估表明,所提出的模块具有灵活性和有效性,可以提高许多ConvNets的表征能力。

图1. 不同网络获得的特征激活的可视化。所有比较的网络都在相同条件下基于ImageNet(Russakovsky等, 2015)进行训练。特征在验证集上提取,并通过Grad-CAM(Selvaraju等, 2017)展示。我们的SimAM帮助网络聚焦于一些主要区域,这些区域与下方显示的图像标签非常接近。
问题背景
在深度学习和卷积神经网络(CNN)的世界里,注意力机制被认为是提升模型性能的重要工具。然而,大多数注意力机制在通道或空间维度上增加了复杂性,带来了额外的参数和计算负担。这对资源受限的环境和轻量级模型而言是一个挑战。SimAM(Simple, Parameter-Free Attention Module)旨在解决这些问题,它通过一种简单但非常有效的方法,实现了三维(3D)注意力权重的推断,而无需增加任何额外的参数。
核心概念
SimAM的核心概念基于一些神经科学理论,提出了一种优化能量函数的方式,以找到每个神经元的重要性。该模块无需增加参数,而是通过闭合形式的解决方案来估算特征图中的3D注意力权重。这种方式可以在模型不增加参数的情况下,增强特征图的表达能力。SimAM强调通过优化一个能量函数来推断每个神经元的重要性,然后使用这个能量函数的闭合形式解决方案来赋予特征图权重。
模块的操作步骤
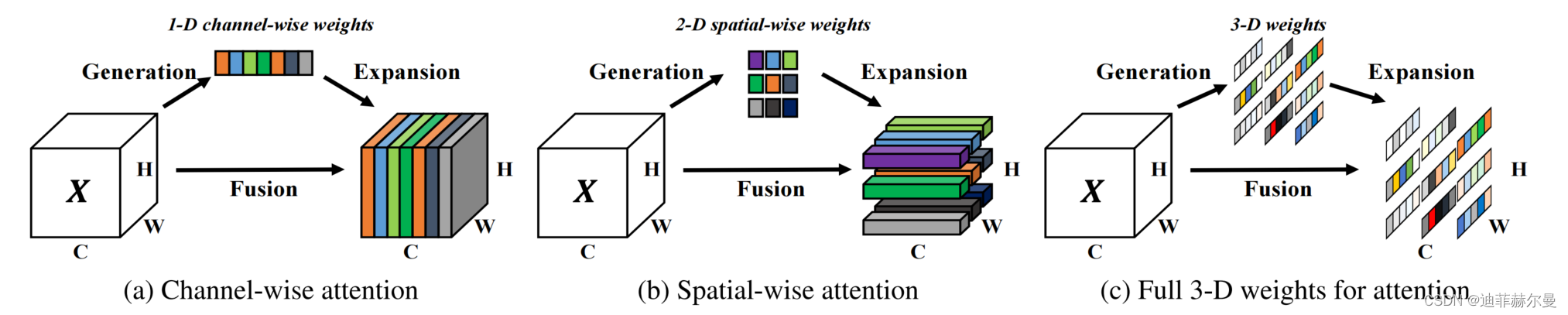
图2. 不同注意力步骤的比较。大多数现有的注意力模块从特征 X 生成 1-D 或 2-D 权重,然后将生成的权重扩展到通道 (a) 和空间 (b) 注意力。我们的模块则直接估计 3-D 权重 ©。在每个子图中,相同的颜色表示每个通道、空间位置或特征上的每个点使用相同的标量。
SimAM的操作步骤非常简单。首先,通过全局平均池化获取每个通道的特征,然后通过一个1D卷积来执行通道之间的交互。这种操作方式将空间维度和通道维度的信息相结合,生成三维的注意力权重。最终,Sigmoid激活函数用于生成通道权重,并将其与原始特征图相乘,重新加权特征。这一过程实现了特征的自适应调整,提升了网络的表达能力。
文章贡献
这篇文章的主要贡献在于提出了一个新的注意力模块SimAM,它可以在不增加参数的情况下为卷积神经网络提供三维注意力权重。这种方法在多种视觉任务上表现出色,且实现方式简单,只需要几行代码。SimAM模块不需要手动调整结构设计,避免了复杂性和额外参数的增加。该模块在多种视觉任务上的实验证明了其灵活性和有效性。
实验结果与应用
实验结果显示,SimAM模块在各种卷积神经网络架构中都表现出色。在ImageNet、CIFAR等知名数据集上的实验结果表明,SimAM可以显著提升网络的准确性,而无需增加额外的参数。此外,SimAM在对象检测和实例分割等下游任务中也表现良好,进一步证明了其广泛的适用性和效率。由于SimAM的轻量级特点,它非常适合移动设备和资源受限的环境。
对未来工作的启示
SimAM的成功启示了高效注意力机制在深度学习中的重要性。未来的工作可以探索将SimAM应用于更多类型的卷积神经网络,或者将其与其他注意力机制相结合。此外,SimAM的轻量级特征使其在移动设备和嵌入式系统中的应用具有潜力。研究人员还可以考虑将SimAM应用于其他领域,如自然语言处理和音频分析,以进一步拓展其应用范围。
代码
import torch
import torch.nn as nn
class SimAM(torch.nn.Module):
def __init__(self, channels=None, e_lambda=1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
y = (
x_minus_mu_square
/ (
4
* (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)
)
+ 0.5
)
return x * self.activaton(y)
if __name__ == "__main__":
input = torch.randn(64, 256, 8, 8)
model = SimAM(64)
output = model(input)
print(output.shape)


















 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











