




 本文深入探讨了二代测序技术的基础知识,包括FQ数据格式、数据过滤与质量控制、测序原理、建库流程、数据比对分析及变异检测等内容,是理解高通量测序关键技术的全面指南。
本文深入探讨了二代测序技术的基础知识,包括FQ数据格式、数据过滤与质量控制、测序原理、建库流程、数据比对分析及变异检测等内容,是理解高通量测序关键技术的全面指南。
二代测序基础知识
二代测序基础概念
(这个是与二代测序相关每个部门都要掌握的)
FQ数据格式
- 高通量测序(如Illumina HiSeqTM/MiseqTM)得到的原始图像数据文件经CASAVA碱基识别(Base Calling)分析转化为原始测序序列(Sequenced Reads),我们称之为 Raw Data或Raw Reads,结果以 FASTQ (简称为fq)文件格式存储,其中包含测序序列(reads)的序列信息以及其对应的测序质量信息。
FASTQ格式文件中每个read由四行描述,如下:
@HWI-ST1276:71:C1162ACXX:1:1101:1208:2458 1:N:0:CGATGT
NAAGAACACGTTCGGTCACCTCAGCACACTTGTGAATGTCATGGGATCCAT
+
#55???BBBBB?BA@DEEFFCFFHHFFCFFHHHHHHHFAE0ECFFD/AEHH
- 其中:
第一行以“@”开头,随后为Illumina 测序标识别符(Sequence Identifiers)和描述文字(选择性部分);
第二行是碱基序列;
第三行以“+”开头,随后为Illumina 测序标识别符(选择性部分);
第四行是对应碱基的测序质量,该行中每个字符对应的 ASCII 值减去 33,即为对应第二行碱基的测序质量值。
原始数据过滤
- 测序得到的原始测序序列(Sequenced Reads)或者 raw reads,里面含有带接头的、低质量的reads。为了保证信息分析质量,必须对raw reads过滤,得到clean reads,后续分析都基于 clean reads。数据处理的条件如下(非标准条件,可参考,比较松的条件,这个是诺禾的过滤条件,大家比例会有所调整,但是都是过滤的这三项):
- 去除带接头(adapter)的reads pair;
- 当单端测序read中含有的N的含量超过该条read长度比例的10%时,需要去除此对paired reads;
- 当单端测序read中含有的低质量(Q ≤ 5)碱基数超过该条read长度比例的 50% 时,需要去除此对paired reads。
数据质量统计概念:
-
Raw Base(bp):原始数据产量,测序序列的个数乘以测序序列的长度,以bp为单位。
-
Clean Base(bp):过滤之后的有效数据量,过滤后测序序列的个数乘以测序序列的长度,以bp为单位。
-
Effective Rate(%):过滤后获得clean data 与raw data的比值。
-
Error Rate(%):碱基错误率。
-
GC Content(%):碱基G和C的数量总和占总的碱基数量的百分比。
-
adapter:接头,用于上机测序。建库时引入的接头序列与测序芯片(flow cell)上固定的接头相互识别。
-
index:测序的标签,用于测定混合样本,通过每个样本添加的不同标签进行数据区分,鉴别测序样品。
-
Q20,Q30:Phred 数值大于20、30的碱基占总体碱基的百分比,其中Phred=-10log10(e),e为错误率。
-
raw data/raw reads:测序下机的原始数据。
-
clean data/clean reads:对原始数据进行过滤后,剔除了低质量数据的剩余数据。后续分析均基于clean data。
参考基因组的一些概念:
- Seq number:基因组组装的序列总数。
- Total length:基因组组装结果总长度。
- GC content:碱基G和C的含量。
- Gap rate:组装结果中N所占的比例。
- N50 length:scaffold N50长度,表示组装结果中有一半的序列长度大于该值。
- N90 length:scaffold N90长度,表示组装结果中有90%的序列长度大于该值。
比对统计的一些概念:
- Mapped reads:比对到reference上的reads条数(包括单端比对和双端比对)。
- Total reads:有效测序数据的reads总条数。
- Mapping rate:比对率,比对到参考基因组上的reads数目除以有效测序数据的reads数目。
- Average depth:平均测序深度,比对到参考基因组的碱基总数除以基因组大小。
- Coverage at least 1X:参考基因组中至少有1个碱基覆盖的位点占基因组的百分比。
- Coverage at least 4X:参考基因组至少有4个碱基覆盖的位点占基因组的百分比。
SNP概念
- SNP(单核苷酸多态性) 主要是指在基因组水平上由单个核苷酸的变异所引起的DNA序列多态性,包括单个碱基的转换、颠换等。
主要类型: - Exonic:变异位于外显子区域;
- missense:非同义变异;
- Stop gain:使基因获得终止密码子的变异;
- Stop loss:使基因失去终止密码子的变异
- synonymous:同义变异。
- Intronic:变异位于内含子区域。
- Splicing:变异位于剪接位点(内含子中靠近外显子/内含子边界的2bp)。
- Downstream:基因下游1 Kb区域。
- Upstream/Downstream: 基因上游1 Kb区域,同时也在另一基因的下游1 Kb区域。
- Intergenic:变异位于基因间区。
- ts:transitions,转换。
- tv:transversions,颠换。
- ts/tv:转换与颠换的比率。
二代测序原理
测序技术发展

illumina测序原理
- 高通量测序(High-Throughput Sequencing)又名二代测序|下一代测序(Next Generation Sequencing,NGS),是相对于传统的桑格测序|一代测序(Sanger Sequencing)而言的。相对于Sanger测序而言,二代测序可以提供中等的读长和适中的价格,适合de novo 测序、转录组测序、宏基因组研究等。
- Solexa的测序原理是可逆终止化学反应。Solexa是一种基于边合成边测序技术(Sequencing-By-Synthesis,SBS)的新型测序方法。通过利用单分子阵列实现在小型芯片(Flow Cell)上进行桥式PCR反应。由于新的可逆阻断技术可以实现每次只合成一个碱基,并标记荧光基团,再利用相应的激光激发荧光基团,捕获激发光,从而读取碱基信息。
- 桥氏PCR原理
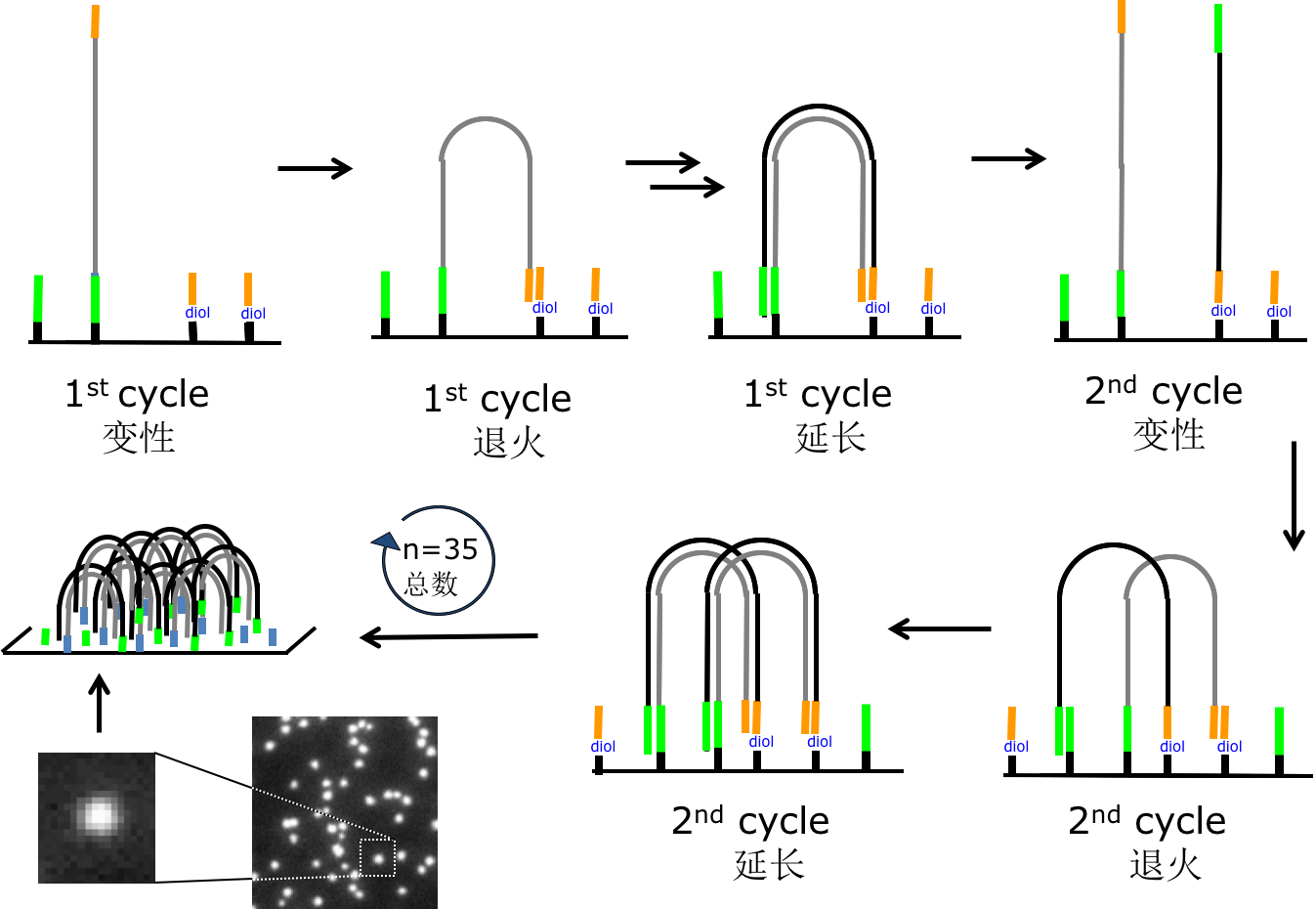
- 二代测序建库测序大致流程
DNA片段经末端修复、加ployA尾、加测序接头、纯化、PCR扩增等步骤完成整个文库制备。构建好的文库通过illumina HiSeqTM PE150进行测序。文库构建完成后,先使用Qubit2.0进行初步定量,稀释文库至1ng/μl,随后使用Agilent 2100对文库的insert size进行检测,insert size符合预期后,使用Q-PCR方法对文库的有效浓度进行准确定量(文库有效浓度>2nM),以保证文库质量。
二代测序数据拆分
- 原始下机数据睡bcl文件,根据前面建库的index信息,进行数据的拆分,除非是包lane或者包run,否则二代测序公司是不会提供该文件的
- 外包测序返回的是拆分后的rawdata及质控后的cleandata,由rawdata到cleandata的数据过滤过程称为质控
二代测序数据质控
- 质控主要进行低质量,含N,含adpter的过滤
- 过滤主要考虑的参数:
- 数据有效数据利用率,一般要求高于95%,现在正常项目大多在99%
- 数据量,数据量所有样品,高于约定数据量的95%,看合同签订的是raw还是clean
- Q20一般要>90%(illunima官方承诺85%)
- Q30一般要>85%(illunima官方承诺80%)
- GC含量,一般波动不大,5%波动以内,群体复杂的要特殊考虑
- GC波动情况(WGS几乎无波动,简化基因组及panel的另行考虑)
- NT比对情况,要求无污染,现在公司不会直接提供,GC波动大时,可以要求测序公司提供,以排除污染。
- 参考资料:两份测序公司的质控报告,供参考学习(有报告是有明显异常的,需要大家找出)
- 上述质控参考指标的图表
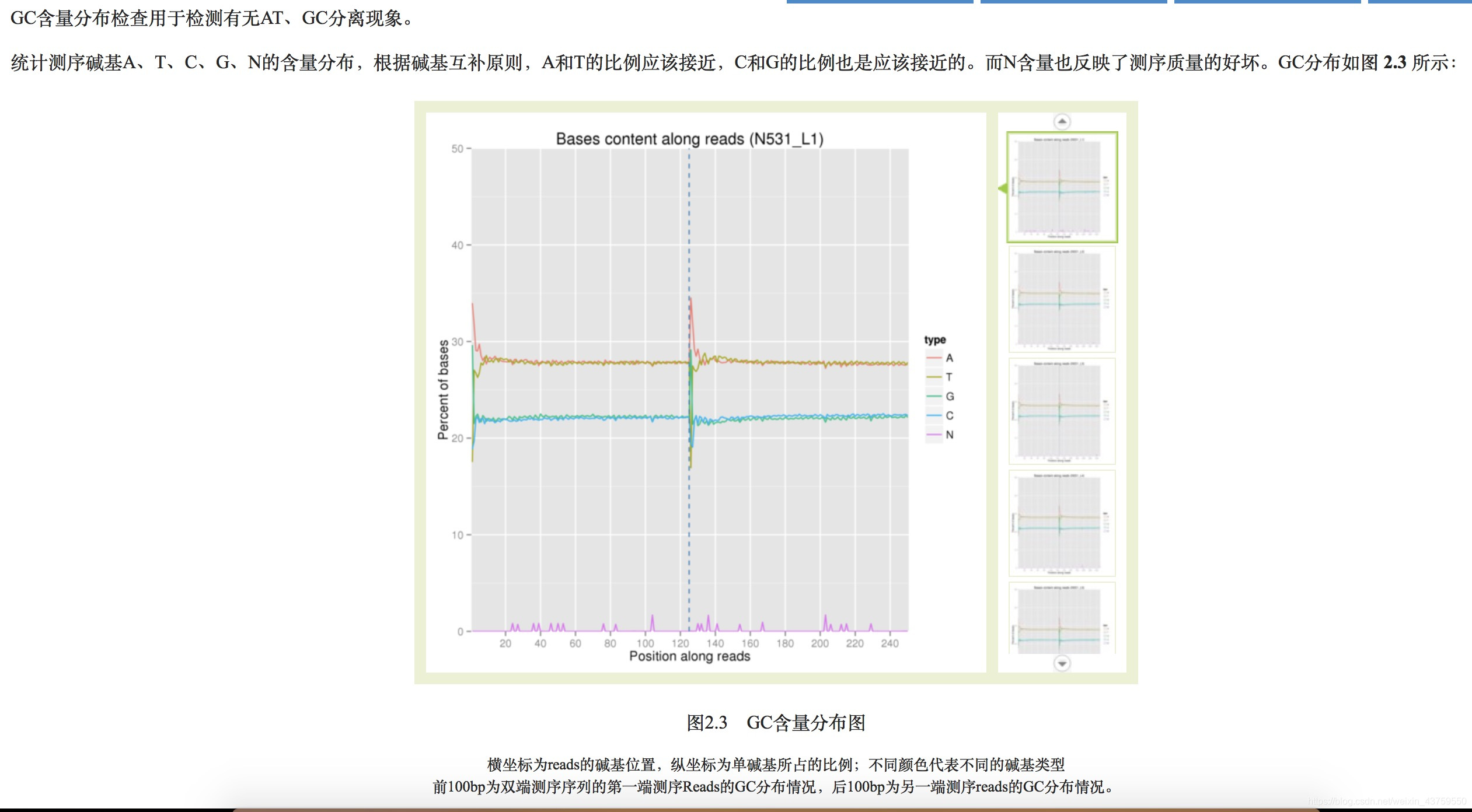
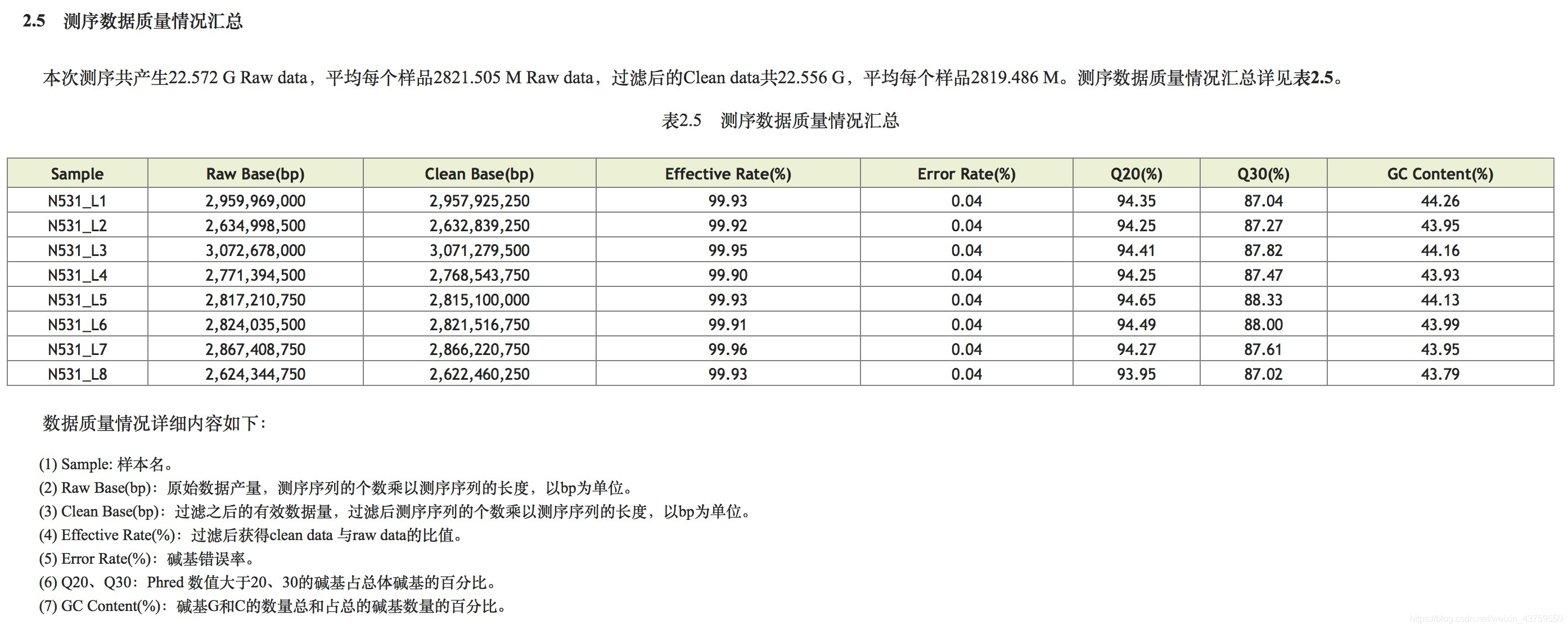
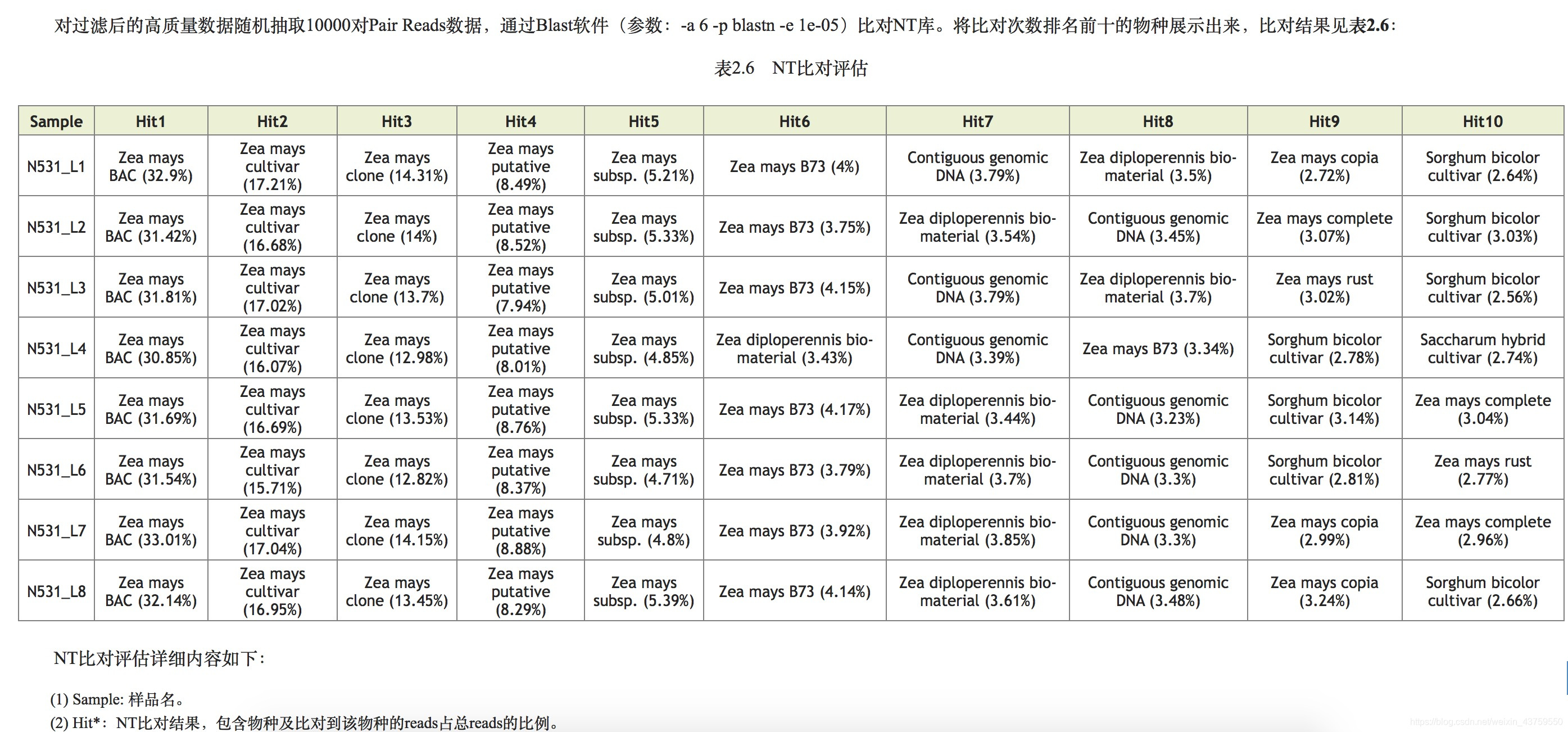
二代测序数据比对分析
比对分析软件及最重要的软件流程
- 重测序
必做
bwa index # 基因组建索引
bwa mem #比对
samtools/gatk sort #排序
可选
samtools/gatk rmdup #去重
gatk remap # 重call
比对分析统计结果展示 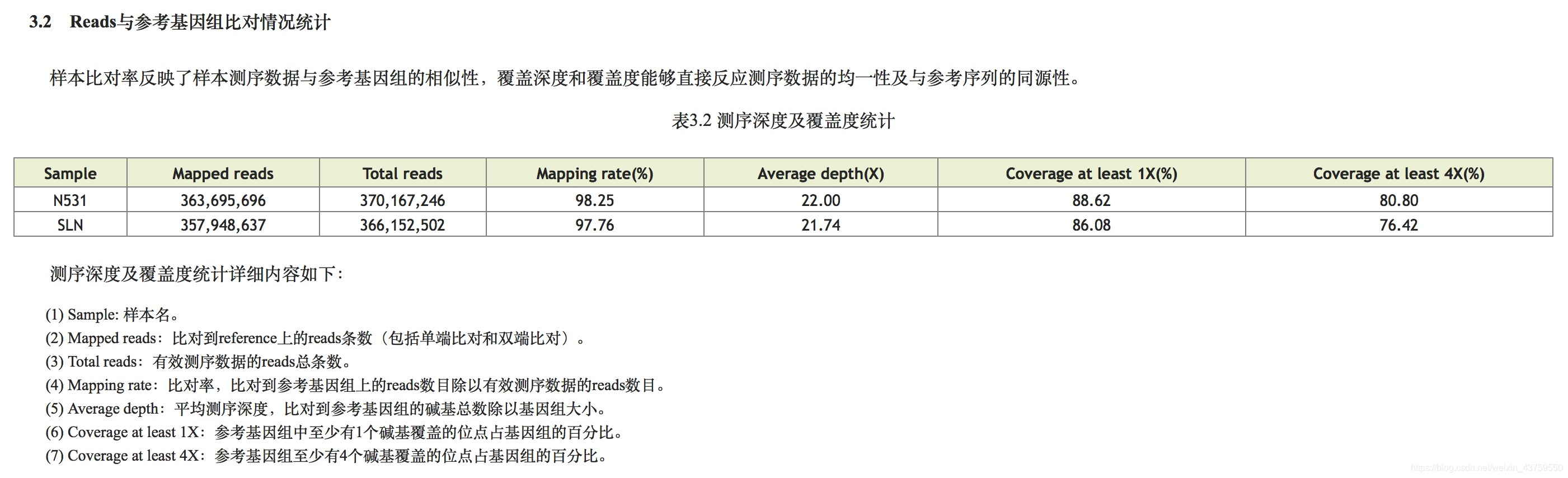
- 一般要求:
- 比对率,大部分非异常样品都会在90%甚至99%以上
- 深度,达到合同或者后续分析的需求
- coverage达到一定水平(85%以上)
- 重复率低于20%,这个报告没有,但是我们可以统计,不会提供给客户,但是是内部测评的重要指标
二代测序变异检测
变异检测软件
- samtools
- GATK
- angsd
- freebase
- 前两个还是主流软件
变异检测注释软件
- annvoar(人,动物比较多)
- snpEff(植物较多使用)
过滤条件
- 个体过滤
- 根据深度情况过滤深度4或者更高的7,10
- 质量值20/30
- 群体过滤
- 根据群体情况,进行总体深度的过滤
- 质量值20/30
- 个体质量值5/10/20和个体深度4/7/10
- miss:0.1/0.2/0.5~
- maf:0.01/0.05
- 上述仅供参考,还需要根据具体情况进行参数的调整,但是一般这些项是要过滤的
结果展示


















 9008
9008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









