






神经网络与深度学习(3)
数据集与评价指标
TP: 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数
FP: 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数
FN:被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数
TN: 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目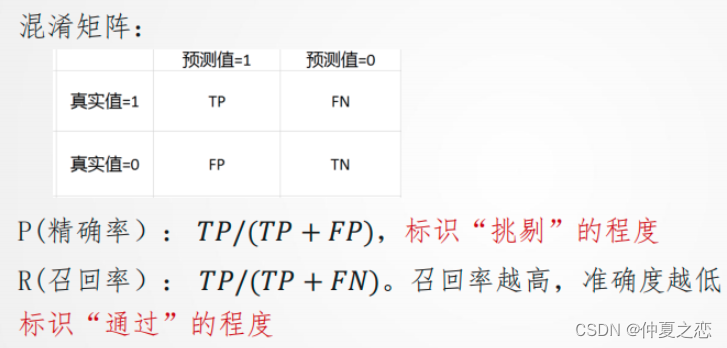
算法评估根据计算PR与PR曲线,mAP等指标进行评估
置信度:置信度是指模型对其预测结果的信心程度或可信度的度量。在机器学习中,通常会为每个预测结果分配一个置信度分数,表示模型对该预测的确信程度。这个分数可以是概率,也可以是其他类型的度量值。例如,如果一个模型对某个分类问题的预测结果是“猫”的概率为0.8,那么置信度就是0.8,表示模型对这个预测结果相当有信心。
准确率:准确率是指模型在所有预测中正确预测的比例。它是一个简单而直观的度量,通常用于评估分类模型的性能。准确率可以通过将模型正确预测的样本数量除以总样本数量来计算。例如,如果一个模型在100个样本中正确预测了90个样本,那么它的准确率就是90%。
P-R曲线展示了在不同阈值下,模型的准确率和召回率之间的权衡关系。曲线越靠近右上角,代表模型的性能越好,即在保持较高的准确率的同时,也能保持较高的召回率。通常来说,如果需要高召回率(尽可能捕获更多真正例),可以降低阈值;如果需要高准确率(尽可能减少误判),可以提高阈值。
正确度P: Precision = TP/(TP+FP)
召回度R:Recall(召回率) = Sensitivity(敏感指标,True Positive Rate,TPR)= 查全率
mAP:
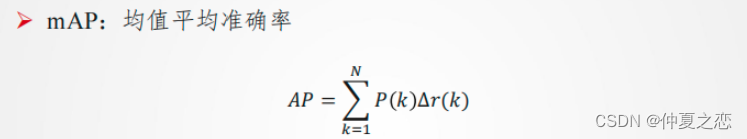
YOLO算法:
目标检测是在给定的图片中精确找到物体所在位置,并标注出物体的类别。
物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图
片的任何地方,并且物体还可以是多个类别
分类模型一般都是接受相同大小的输入图像,摒弃空间坐标。其使用的全连接层可以被看成一个核能够覆盖全部元素的卷积层。
FCN 方法是第一个基于深度学习的分割方法,只包含卷积层,可以输入任意大小的图然后生成其分割结果图
贡献:该方法是图像分割的一个重要的转折点,证明了深度学习网络可以端到端的实现对不同大小图像的语义分割。
缺点:FCN 模型速度较慢,无法支持实时的语义分割;没有考虑全局上下文信息;无法方便的扩展到 3D 图像。

YOLO网络结构:
卷积层(BackBone):主干特征提取网络包含24个卷积层,这些层主要用于从输入图像中提取丰富的特征。卷积层通过不同大小的卷积核和步长来提取图像的局部特征,每个卷积层后通常会跟一个激活函数,yolov1的backbone使用的主干为Darknet19
随机初始化的卷积层:接下来的4个卷积层没有进行预训练,而是在目标检测的训练过程中随机初始化并训练。这些层专门用于从预训练的特征中提取对特定目标检测任务更敏感的特征
最后是全连接层和输出层,用于整合之前卷积层提取的特征,并最终输出预测结果,输出层用于根据全连接层的输出,得到一个7x7x30的输出张量。
YOLO中的包围框是用来表示目标在图像中位置和大小的矩形框。这些框由算法预测并定位,用于确定图像中的目标对象的位置和边界 在YOLO中,归一化通常指的是对包围框的位置和尺寸进行归一化处理。这种归一化是为了使模型更好地学习到不同尺寸和位置的目标
在YOLO中,归一化通常指的是对包围框的位置和尺寸进行归一化处理。这种归一化是为了使模型更好地学习到不同尺寸和位置的目标
同时YOLO的定位置信度是根据包围框的IOU计算的,而输出的置信度为是物体的概率与分类置信度,二者并不相同。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









