







发表时间:2021
论文地址:https://arxiv.org/abs/2107.00781
摘要
我们提出了UTNet,一个简单而强大的混合Transformer结构,将自注意力整合到了一个卷积神经网络用于医学图像分割。UTNet使用自注意力模块在编码器和解码器用于在不同尺度以最小的开销捕获长距离的相关性。为此,我们提出了一个有效自注意力机制和相对位置编码,可以减小注意力操作的复杂度从 O ( n 2 ) O(n^2) O(n2) 到 O ( n ) O(n) O(n)。一个新的自注意力解码器被用于恢复来自于编码器跳跃连接的细粒度特征。我们的方法解决了Transformer需要大量数据来学习视觉归纳偏置的困境。我们的混合层设计允许Transformer在卷积网络的初始化不需预训练。
方法
2.1 重提自注意力机制
Transformer是基于多头自注意力(MHSA)模块建立的,可以使模型计算来自于不同表示子空间的注意力。来自于不同头的结果被连接起来,再被一个前向网络转换。
输入特征图 X ∈ R C × H × W X∈R^{C×H×W} X∈RC×H×W,三个1×1卷积将 X X X 投影成 Q , K , V ∈ R d × H × W Q,K,V∈R^{d×H×W} Q,K,V∈Rd×H×W,此时将它们压平和转置成大小为 n × d n×d n×d 的序列, n = H W n=HW n=HW。
对于自注意力的计算:

P
∈
R
n
×
n
P∈R^{n×n}
P∈Rn×n 叫作上下文聚合矩阵或者相似度矩阵。第 i 个query的上下文聚合矩阵是
P
i
=
s
o
f
t
m
a
x
(
q
i
K
T
d
)
,
P
i
∈
R
1
×
n
P_i=softmax(\frac{q_iK^T}{\sqrt{d}}),P_i∈R^{1×n}
Pi=softmax(dqiKT),Pi∈R1×n,表示
q
i
q_i
qi 和keys的标准化点积。上下文聚合矩阵用于作为权重来聚合来自于values的上下文信息。
然而n×d矩阵的点积导致了 O ( n 2 d ) O(n^2d) O(n2d) 的复杂度,一般,当特征图分辨率较高时,n远大于d。因此序列长度影响自注意力的计算,并且不能将自注意力应用到高分辨率的特征图上。
2.2 Efficient Self-attention Mechanism
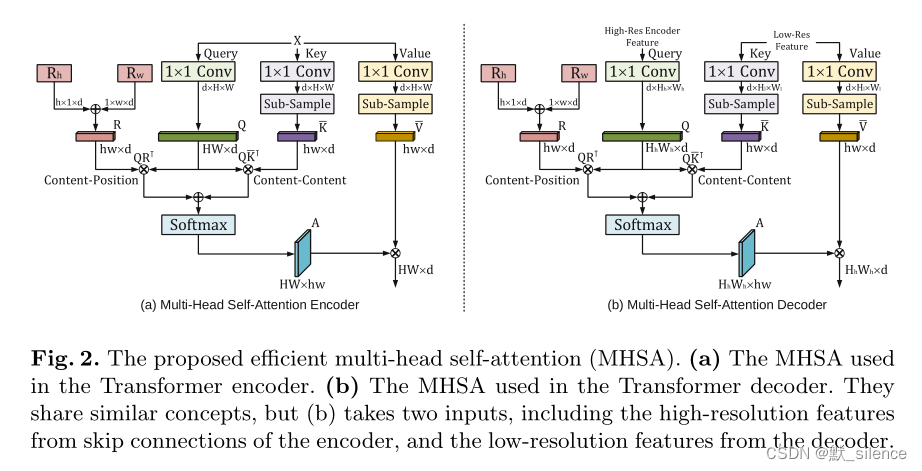
主要的想法是使用两个投影,将 K , V ∈ R n × d K, V∈R^{n×d} K,V∈Rn×d 投影到低维的嵌入: K ‾ , V ‾ ∈ R k × d \overline{K} ,\overline{V}∈R^{k×d} K,V∈Rk×d,
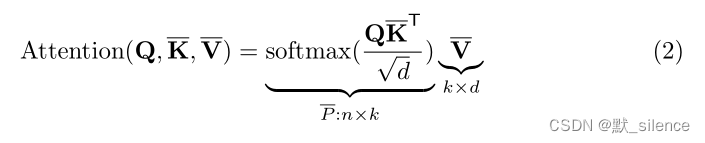
计算复杂度减小到了
O
(
n
k
d
)
O(nkd)
O(nkd)。
2.3 相对位置编码
像素
i
=
(
i
x
,
i
y
)
i=(i_x,i_y)
i=(ix,iy) 和
j
=
(
j
x
,
j
y
)
j=(j_x,j_y)
j=(jx,jy) 之间的注意力 logit:
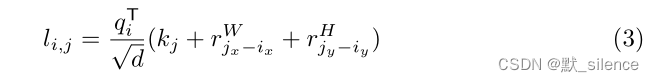
对于efficient注意力计算:
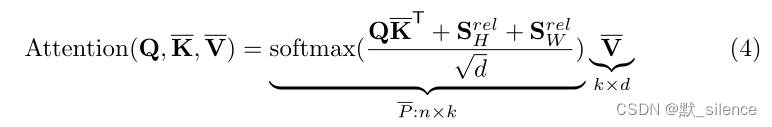
2.4 网络结构
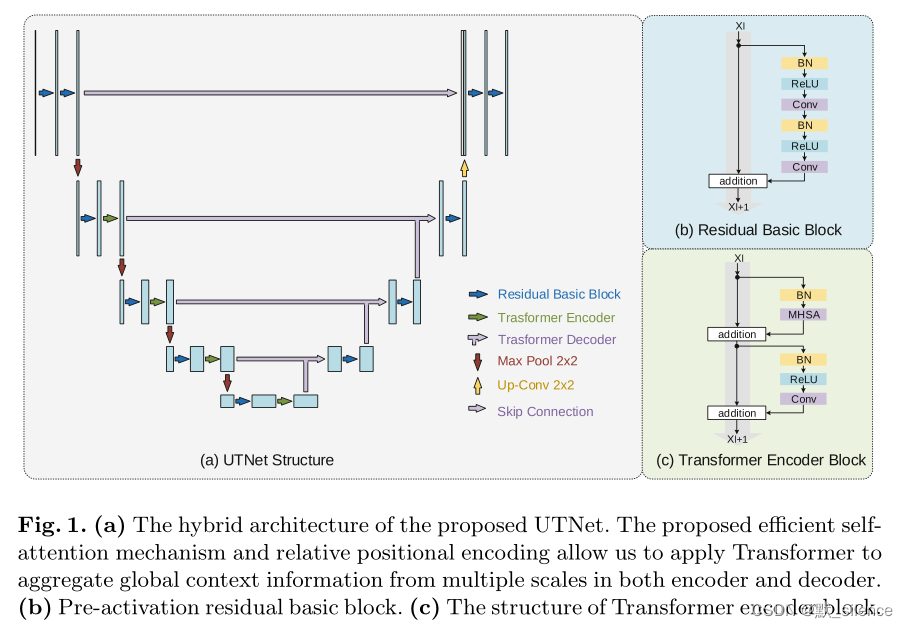
这种混合架构可以利用卷积图像的归纳偏差来避免大规模预训练,Transformer也具有捕获长距离全局特征的能力。因为分割错误的区域通常位于感兴趣区域的边界,高分辨率的上下文信息可以在分割中起到很重要的作用。因此,我们的关注点放在了提出的自注意力模块上,使它可以有效处理大尺度特征图。没有将自注意力模块直接使用到CNN的特征图上,而在编码器和解码器的每一层用于手机不同尺度的长距离依赖。注意到我们没有将Transformer用于原始分辨率,因为在网络的浅层添加Transformer模块对实验没有帮助,但会引入额外的计算。一个可能的原因使浅层更注意细节的上下文特征,收集全局上下文信息不理想
4 结论
我们提出了一个UTNet来整合卷积层和自注意力层用于医学图像分割。我们的混合层设计允许Transformer的初始化进入到卷积网络中,不要需要预训练。新颖的自注意力允许我们在不同层捕获长距离相关性。我们相信这个设计会帮助Transformer在医学视觉应用中更可用。有效处理长序列的能力打开了UTNet应用在更多下游医学图像任务的可能性。

















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









