






 本文深入讲解了使用dc_shell和dc_shell-topo模式下进行设计综合优化的方法,包括不同层次的优化策略,如结构级、逻辑级和门级的优化细节。同时,探讨了时序优化的各种技巧,如BRT技术和路径组的自定义,以及如何保护特定模块不受优化影响。
本文深入讲解了使用dc_shell和dc_shell-topo模式下进行设计综合优化的方法,包括不同层次的优化策略,如结构级、逻辑级和门级的优化细节。同时,探讨了时序优化的各种技巧,如BRT技术和路径组的自定义,以及如何保护特定模块不受优化影响。
Lab5:预备知识整理(也可以先跳过直接先看实验,看完实验记得回来看哦)
1、dc_shell 模式下使用 compile 来综合优化设计;dc_shell -topo 模式下使用 compile_ultra 来综合优化设计;
2、设计的综合分层为:Architectural(结构级)、Logicl(逻辑级)、Gate(门级)
3、各层次优化策略:
(1)、Architectural(结构级)包括:设计结构的选择、数据通路的优化、共享(算术电路)子表达式、资源共享(其中的算术资源共享默认是约束驱动,将 hlo_resource_allocation 变量设置为 area,使得算术资源共享的策略是约束面积的(面积优化);将 hlo_resource_allocation 变量设置为 none 即使 DC 综合时停用资源共享,但此时也可以在 RTL 代码中指明资源共享)、重新排序运算符号。
(2)、Logicl(逻辑级):电路的功能以 gtech 器件表示,进行 Structuring(结构)和 Flattening(展平)优化。
其中 Structuring( 结构 ) 优化采用 共用 ( 门级电路 ) 子表达式 的策略,优化速度和面积,set_structure ture 命令启用。
Flattening(展平)优化将组合逻辑路径减少为先与后或的两级,即将门级电路的表达式写成多个乘积的和,优化速度,set_flatten ture -effort low(medium 或 high)。
(3)、Gate(门级)优化:DC 开始映射(延迟优化、设计规则调整、以时序为代价的设计规则调整、面积优化)完成门级电路,例如组合逻辑电路的映射是从目标库中选择满足时序、面积要求的组合单元来完成组合逻辑设计(其中可以包括有调整逻辑表达式和分割关键路径手段);时序电路的映射是从目标库中选择满足时序、面积要求的时序单元(通常比较复杂)来完成组合逻辑设计;
4、其他的优化情况:一个寄存器驱动多个寄存器时复制驱动寄存器并且分割被驱动的寄存器组(dc_shell -topo 下使用 compile_ultra -timing);
一个模块被多次调用时,将名字唯一化(虽然是同个模块,但名字不同),对应 uniquify 命令。
5、时序优化的一些方法:时序违规在 25%情况下时可以使用:
(1)、compile_ultra 的一些开关选项:
compile_ultra -scan -no_autoungroup -no_boundary_optimization -no_uniquify -area(timing)_high_effort_script
分别对应:DFT 可测试编辑、关闭自动取消划分功能、不进行边界优化、不进行模块名称唯一化来加速含多次调用例化模块的设计的时间、面积(时序)优化。
(2)、set compile_ultra_ungroup_dw ture#取消所有的 DesignWare 层次,综合之后各个大模块间的边界被清除。
set compile_auto_ungroup_delay_num_cells NUM#综合之后大模块 A 与被 A 调用的小模块 B之间的边界被清除。
(3)、边界优化:对一些固定电平或者固定逻辑的边界引脚(GND、VCC)进行优化。
(4)、BRT 技术:(Behavioral ReTiming):包括对包含寄存器的门级网表进行 optimize_registers,将前后级寄存器间的组合逻辑进行分割再组合使得寄存器间的时序均满足要求,或者加入 -retime 选项进行路径间的逻辑迁移(adaptive retiming),使得不满足时序要求的路径可以被逻辑迁移到相邻的满足时序的路径上去(一般是通过迁移时序器件),set_dont_retime [XXX] ture 可以让 dc 不迁移某些器件;和对纯组合逻辑的门级网表进行 pipeline_design(流水线设计),使用这个命令时需要先在 RTL 中将寄存器预置好。 compile -scan -inc#编译时不做逻辑级优化只进行门级优化。
(路径组:多条时序路径的组合(寄存器到寄存器的路径组由于受 clk 控制,默认是 clk 路径组)。路径延时:cell 时间弧(cell 延时+setup/hold time 检查+c-q 时间等)+连线延时(线负载模型计算),并且路径延时中 cell 延时与起点是上升沿(输入信号上升跳变)还是起点是下降沿(输入信号下降跳变)有关(tphl、tplh)。DC 执行 report_timing 时就是计算起点上升沿延时和计算起点下降沿延时并且找出每个路径组中的关键路径,最后显示每个组的时序报告。DC 默认行为是对于同一个路径组中对关键路径进行优化完成之后才对次关键路径(sub-critical paths)进行优化,关键路径不满足时序要求时永远不会对次关键路径进行优化。但是有时候我们想在关键路径没被优化完成的基础上优化次关键路径时,就是可以自定义路径组或者设置关键范围)
自定义路径组:group_path -name XXX -from [XXX] -to [XXX],-from -to 优先级最大,-from 次之,-to 优先级最小。综合时 DC 对每个路径组中时序最差的路径做各自组别相互独立的优化。还可以设置优化权重(各个路径组之间的权重)和优化关键范围(只对时序违规超过这个范围的路径进行优化)group_path -name XXX -from [XXX] -to [XXX] -critical critical num -weight weight num
重新划分模块:自动划分和手动划分。
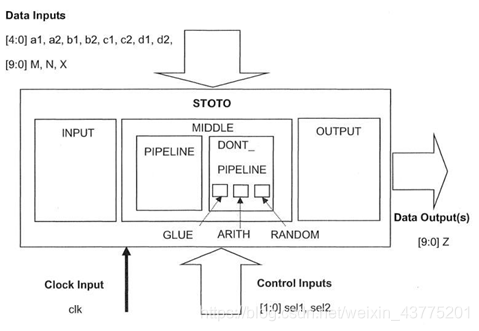
Lab5:实验结构图如下:
顶层结构图:
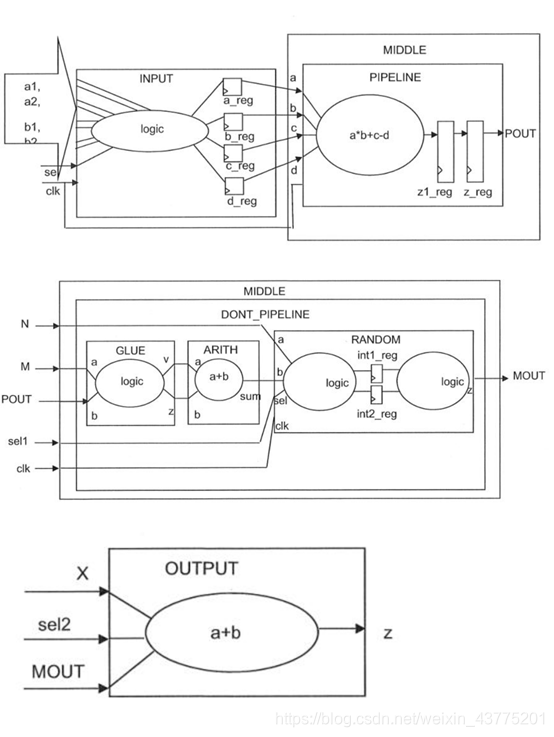
各子模块结构图:
实验要求和对应脚本的解析:
1、
group_path -name clk -critical 0.21 -weight 5
group_path -name INPUTS -from [all_inputs]
group_path -name OUTPUTS -to [all_output]
group_path -name COMBO -from [all_inputs] -to [all_output]
自定义路径组且 clk 路径组的权重为最高(5)。
2、对应实验要求 3 和 4:子模块 INPUT 结构需要被保护,子模块 PIPELINE 需要进行 BRT 技术中的optimize_registers,也需要被保护,所以这两个子模块均不可以被打散。
set_ungroup [get_designs “INPUT”] false
set_optimize_registers true -design PIPELINE
3、对应实验要求 5 和 6:子模块 PIPELINE 的输出寄存器不可以被流水线移动,子模块 I_DONT_PIPELINE 的寄存器也不可以被流水线移动。
set_dont_retime [get_cells I_MIDDLE/I_PIPELINE/z_reg*] true set_dont_retime [get_cells I_MIDDLE/I_DONT_PIPELINE] true
4、设置综合中时序优先:set_cost_priority -delay
5、验证:
①、查看时序路径组情况是否与上述分组一致:
report_path_group

②、查看子模块 PIPELINE 有没有进行optimize_registers:
get_attribute [get_designs “PIPELINE”] optimize_registers

③、查看 INPUT 的打散情况和该需要不被移动的单元或者模块的移动情况:
i、get_attribute [get_designs “INPUT”] ungroup

INPUT 模块没有被打散。
ii、get_attribute [get_cells I_MIDDLE/I_PIPELINE/z_reg*] dont_retime

所有的 z_reg*寄存器在 retiming 过程中没有被移动。
iii、get_attribute [get_cells I_MIDDLE/I_DONT_PIPELINE] dont_retime
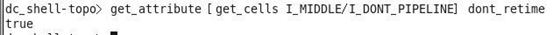
模块 I_MIDDLE/I_DONT_PIPELINE 在 retiming 过程中没有被移动。
④、查看综合中是否是设置建立时间冲突的优先级高于 DRC 冲突 (Prioritize fixing of setup timing (delay) violations over DRC violations): get_attribute [get_designs “STOTO”] cost_priority

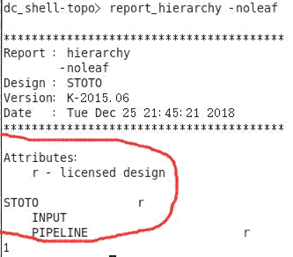
⑤、compile_ultra -retime -scan 之后查看没有被打散 ungroup 的模块:
report_hierarchy -noleaf
⑥、查看时序报告:
redirect -tee -file rt_compile_ultra.rpt {report_timing} 可以看到各个路径组分别的时序报告。
其中 clk 组中优化权重最高并且在 PIPELINE 加入 optimize_registers,不存在时序违规,slack为正值:
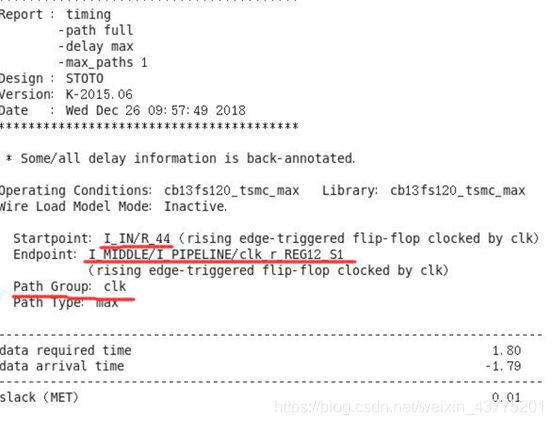
⑦、查看子模块 PIPELINE 进行 optimize_registers 之后被移动的寄存器: report_cell -nosplit I_MIDDLE/I_PIPELINE#查看例化名字对应的原模块的名字 report_cell -nosplit I_IN#查看例化名字对应的原模块的名字
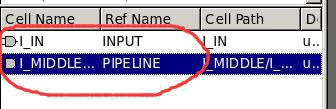
或者:
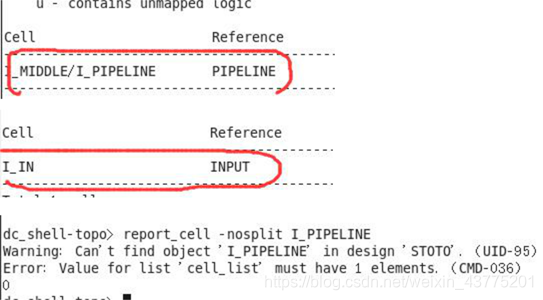
get_cells -hier r_REG_S*#optimize_registers 之 后 被 移 动 的 寄 存 器 的 名 字 为 r_REG_S*(start_gui 查看图形界面,查看 I_MIDDLE/I_PIPELINE 中的大部分寄存器名称)
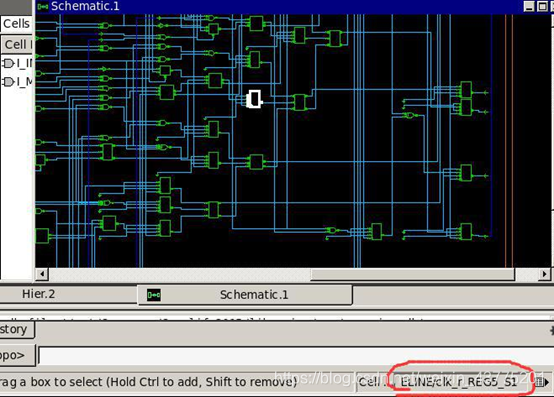
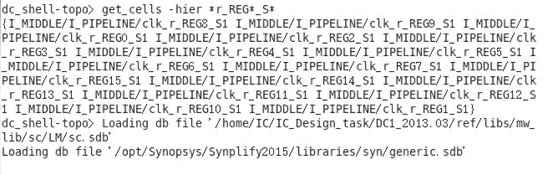
估计被移动的寄存器有 z1_reg 等寄存器。
get_cells -hier z_reg#验证寄存器 z_reg 是否被移动过:

有存在值,说明 z_reg 没被移动。
get_cells -hier z1_reg#验证寄存器 z1_reg 是否被移动过
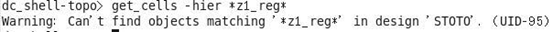
无存在值,说明被 retiming 移动的寄存器为 z1_reg。
get_cells -hier R_#查看被 retiming 过程移动过的却不是流水线中的寄存器,retiming 过程中被移动过的却不是流水线中的寄存器被命名为 R_

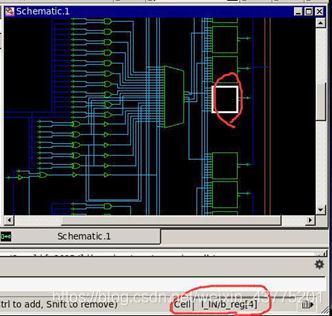
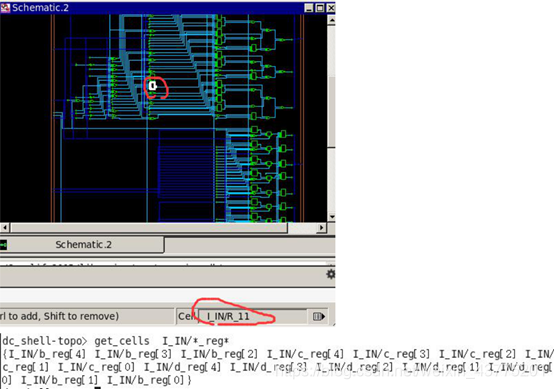
get_cells I_IN/_reg#查看 INPUT 模块中没有被移动过的寄存器(start_gui 对比 INPT 模块前后的电路图中寄存器的名称差别)
前:
后:
其实没有Lab6嘻嘻

















 7246
7246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









