







0 摘要
多视图数据包含来自多种模态的信息,可能为机器学习任务提供更丰富全面的特征。多视图分析中一个基本问题是:额外视图带来的附加信息是什么,以及如何识别这些额外的信息。本文通过解纠缠的思想将多视图表征分解为多视图共有的共享潜在表征(shared latent representation)以及每个视图特有的私有表征(private representation),称之为解纠缠信息瓶颈(disentangled variational information bottleneck,DVIB)。文章证明了shared talent represention和private representation各自保留了共享的公共标签和单个视图的唯一标签识别能力。
1 Introduction
多视图学习是否比单视图学习带来更多的优势?回答这个问题,需要将多视图中的纠缠信息分解为共享表征和私有表征,以此明确的度量每个视图的共享度,并且共享表征代表了样本的一般和共同特征,可以用于减少数据损坏和噪声的影响。私有表征表示了单一视图的独特属性,可以用来评估其对特定认为的重要性。
挑战在于,如何解开纠缠的表征。本文基于信息瓶颈下的框架描述解纠缠表征学习。训练优化目标:①最大化不同视图生成的共享潜在表征(shared latent representation)之间的互信息;②最小化不同视图生成的私有表征(private representation)之间的互信息。

2 DVIB
如图所示,以两个视图,
为例,各自的共享表征和私有表征分别为,
。利用信息瓶颈公式优化共享表征和私有表征。
共享表征学习目标:
①要求单个视图的共享表征与其本身的原特征互信息最大;
②要求单个视图的共享表征与其他视图的原特征互信息最大。
(是平衡因子超参数)
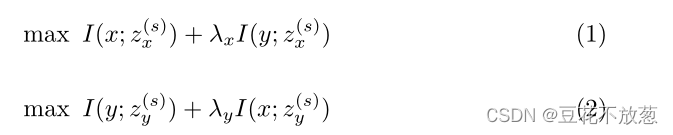
私有表征学习目标:私有表征表示该视图的特有信息,与其他视图无关。
①要求单个视图的私有表征与其本身的原特征互信息最大;
②要求单个视图的私有表征与其他视图的原特征互信息最小;

2.1 互信息计算推导
下界推导:

的熵与优化无关,可以舍去。
下界推导:

上界推导:

其中,分别表示x,y生成私有各自私有表征的编码器。优化第一项表示相同输入y输入不同的编码器生成的x,y的私有表征差异度要足够大,第二项表示y生成的私有表征与x私有表征的先验分布差异度要足够大。
实现第一项的操作是困难的,但考虑到神经网络的随机参数,以及与第二项是同一方向的优化,因此舍去第一项。由此得到,

最终的优化目标函数:

使用变分自编码器实现优化,四个编码器encoder分别得到,使用解码器decoder重构原始特征。
3 Experiments
编码器和解码器使用简单的多层神经网络实现,先验分布。
数据集:MINIST
视图生成:通过不同的变换,旋转角度生成x,翻转生成视图y。
图a表示两种视图的生成结果。图b表示,视图的共享表征有利于识别数字标签,而视图的私有表征有利于识别各个视图下标签识别。

多视图学习的一个重要应用是应对存在破坏、噪声的视图,利用多视图的相关性(共有特征)对其进行修复。
实验数据集:ImageNet
视图生成:视图x添加高斯噪声,视图y使用散焦模糊。
DVIB将多个视图学习的共享表征进行拼接,通过softmax回归分类。与其他方法对比结果如下:

4 总结
论文关键点在于:
1. 多视图解纠缠,利用信息瓶颈优化得到同一个对象在不同表征下的共有特征;
2. 共有特征仍然是针对每个视图得到的,并没有考虑如何融合多个视图下的共有特征得到唯一的共有特征表示;
3. 解纠缠的思想在于求解不同视图下的交集特征。















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









