






1.目标物种的蛋白质信息下载
2.目标家族隐马尔可夫模型下载
2.1知道目标家族的pfam号
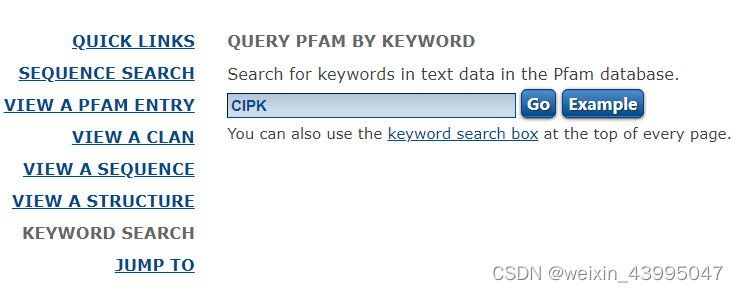
直接搜索下载
2.2不知道pfam号
老师好,请问怎么找一个家族基因隐马尔科夫模型的pfam索取号 - 组学大讲堂问答社区
比如,知道基因家族基因的缩写,如,NBS,MYB,AP2,WRKY等等, 就可以搜索一下相关的基因家族文章来从文章中获得:
如谷歌学术搜索,关键词:genome wide gene family + 基因家族缩写,筛选一下最新,在方法部分查看
2.3下载
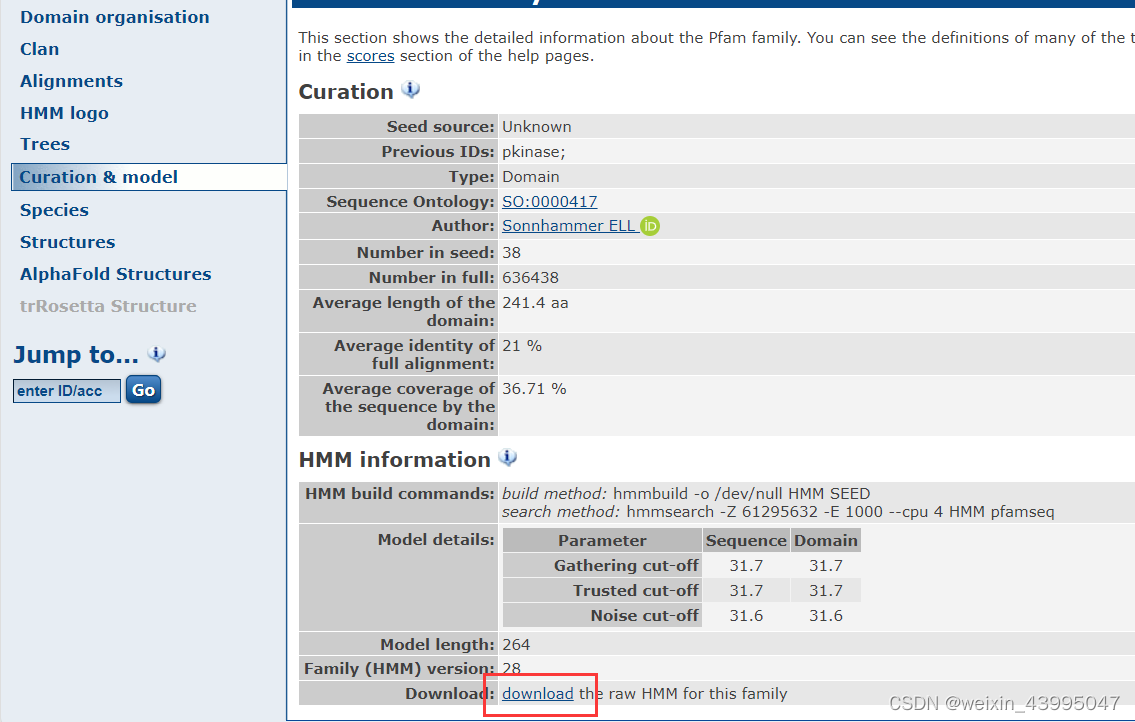
2.4自己构建hmm模型
主要的构建逻辑就是直接在NCBI网站搜索CBL,肯定会出现很多结果,为了我们我们构建的HMM model相对精确,可以在搜索时指定几个物种,比如指定拟南芥和水稻作为搜索物种,这时会搜索到所有与拟南芥和水稻相关的CBL的基因,将搜索到的所有基因的蛋白序列保存为fasta文件。最好的方法是,想办法获取到拟南芥和水稻已经发表的CBL蛋白序列,这样就可以构建出更为准确的HMM model文件。最好是这样,不过也不影响。
将上述搜索到的全部基因的蛋白序列首先进行多序列比对,得到align.fasta文件
然后通过下述命令行操作,即可得到HMM model。
hmmbuild CBL.hmm align.fa
3 利用HMM model在基因组文件中搜寻候选基因家族成员
可以提前手动将上述两个HMM model文件进行合并,合并为一个HMM model文件,就像操作txt记事本那样,把其中一个复制后粘贴在另一个后面,然后重命名即可
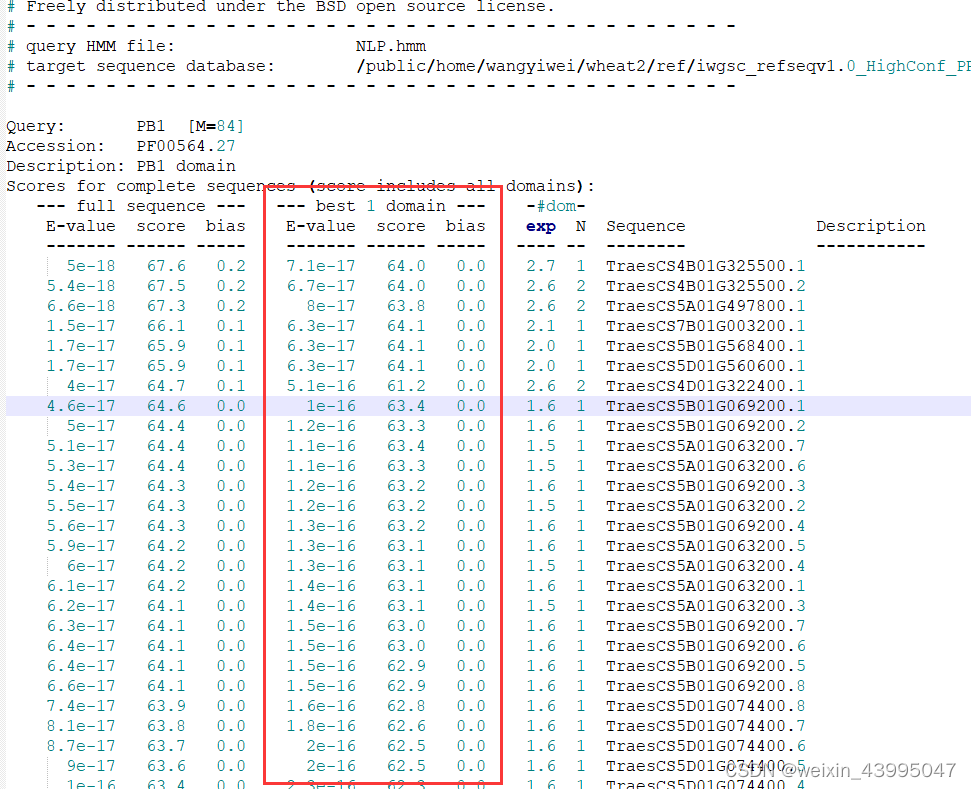
hmmsearch CIPK.hmm /public/home/wangyiwei/wheat2/gene_family/wheat_trans_longest.fa > wheat_hmmsearch_CIPK.out
这里展示了几列信息,很好辨识,左边三列是全序列比对结果(按score从高到低排序),红框中的三列是hmm模型结构域最佳匹配结果(排序同上)。这里我们主要以红色框中的搜索结果为准,以10-5进行限制
4.将两种的id求交集
5.获取id的蛋白质信息
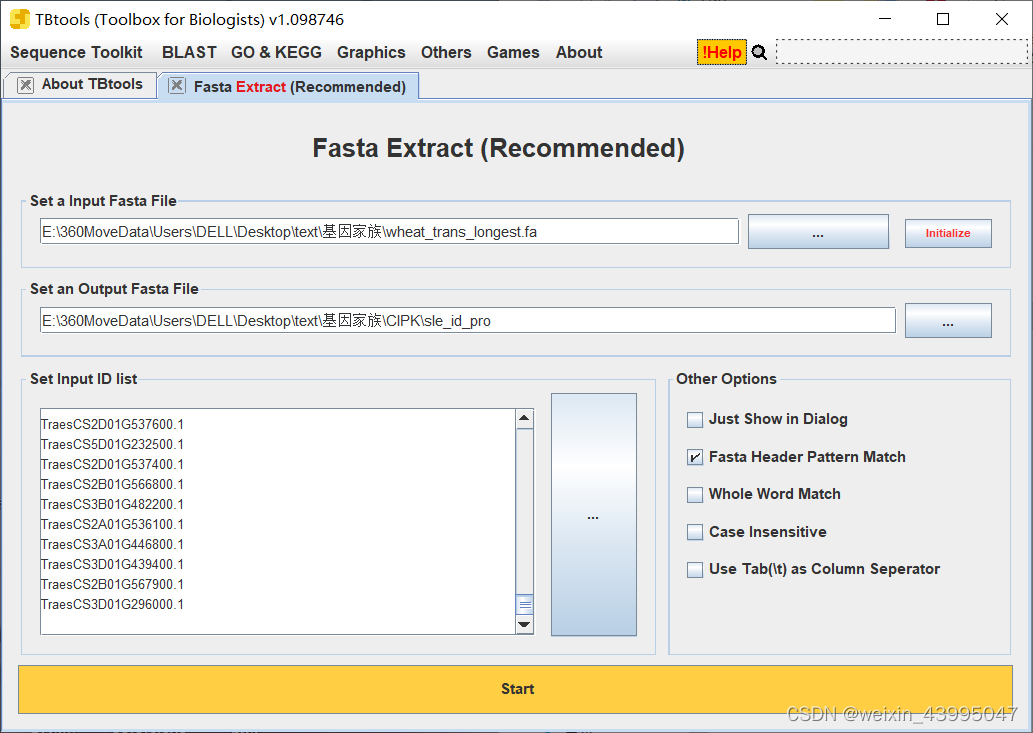
6.smart interpro 分析基因序列,检查结构域
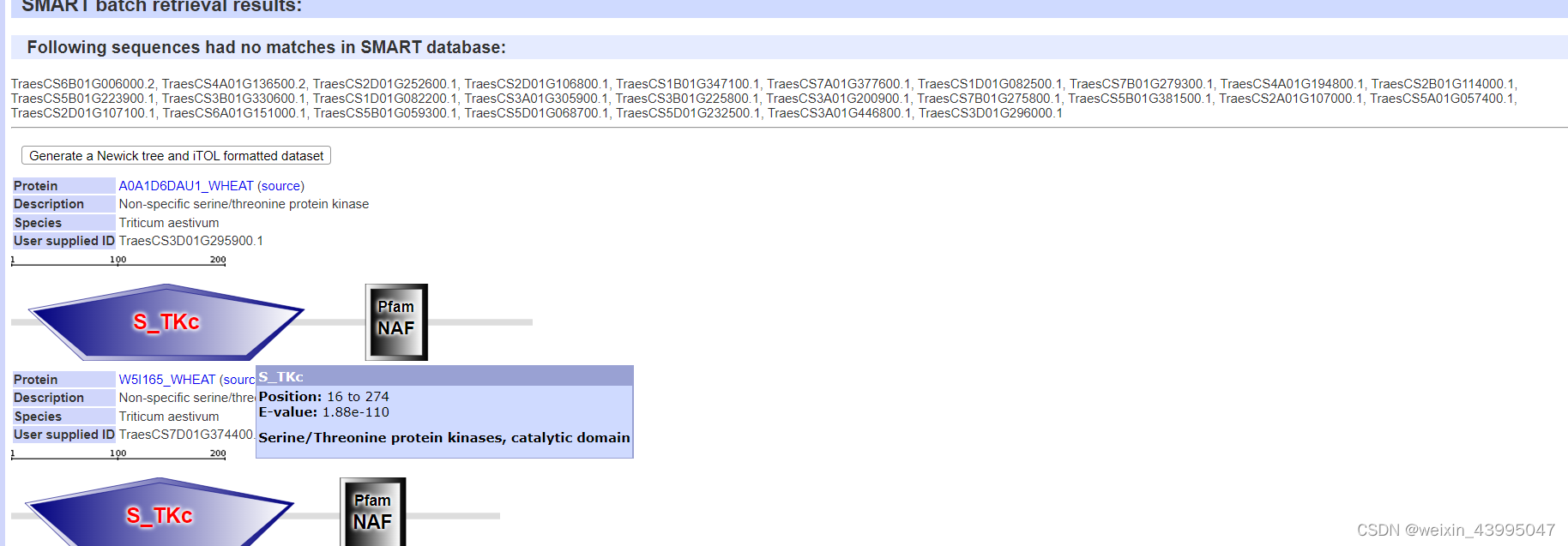
InterProScan - InterPro (ebi.ac.uk)

在线网站一次只可以检测100个序列,可以安装本地版
/public/home/wangyiwei/software/my_interproscan/interproscan-5.56-89.0/interproscan.sh -appl CDD,COILS,Gene3D,MobiDBLite,PANTHER,Pfam,PIRSF,PRINTS,SFLD,SMART,SUPERFAMILY,TIGRFAM -i hmmer_pro -f tsv -dp
Interproscan linux版本详细安装教程及运行报错解决方案_努力的猪猪包的博客-CSDN博客_interproscan安装
7.获取拟南芥对应的家族id
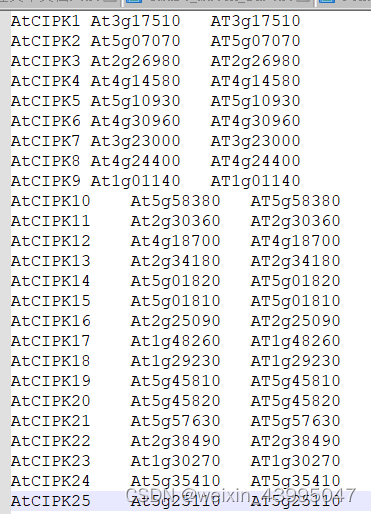
8.拟南芥对应家族id的蛋白质信息
9.将拟南芥和小麦的CIPK蛋白内容存放在一个文件内
10.MAFFT多序列比对
MAFFT < Multiple Sequence Alignment < EMBL-EBI
/public/home/wangyiwei/miniconda3/bin/mafft --auto --inputorder all > mafft
11.修剪
trimal -in mafft -out mafft_trimal -automated1
作者建议构建最大似然法的树使用-automated1参数,构建NJ树使用-strictplus参数
12建树
fasttree mafft> tree.nwk
FastTreeMP -boot 1000 SpeciesTreeAlignment.fa > tree
iqtree -s /public/home/wangyiwei/ywsx/TaDCL2/mafft -m MFP -B 1000 --bnni -T AUTO


















 4619
4619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









