







英飞凌Aurix2G TC3XX 芯片内核详解(二)——TriCore上下文切换及CSA机制
本文主要介绍Infineon Aurix2G TC3XX系列芯片内核上下文切换逻辑及CSA硬件机制,以及相关实例演示。
目录
1 上下文概念介绍
众所周知,计算机程序在编写过程中,需要使用模块化、封装、分层、抽象等设计理念,这就使得程序在运行中需要不断地在多个子程序中不断地调用、返回,形成一个程序执行树。
对于单任务系统来说,在程序调用子程序之前,需要把当前的寄存器、系统状态等信息进行保存,并在子程序返回时,将这些信息加载回来。
而对于多任务系统,每个任务都有自己的上下文,在任务切换过程中需要将一个进程的执行环境切换到另一个进程的执行环境,这是多任务处理的基本机制。
另外在发生中断或异常时,当前程序的运行环境和寄存器信息需要进行保存,称为保护现场。
以上这些,从广义上来说,都属于上下文切换。
为什么需要上下文切换呢,就比如你春节放假很久,再回来工作时感觉很陌生,需要一点点回忆春节前的工作细节、进度,然后慢慢进入节奏,这就类似上下文切换。上下文切换对于操作系统用户或上层应用程序用户来说,是透明不可见的,他们也不需要关注。但对于系统级的软件工程师,尤其是操作系统开发人员,上下文切换是极其重要的内容。
下面通过一个简单程序,说明在单任务系统中上下文切换的流程。
void FuncA();
void FuncB();
void FuncC();
void FuncA()
{
...
FuncB();
...
}
void FuncB()
{
...
FuncC();
...
}
void FuncC()
{
...
}
如上图是一个简单的函数调用,调用关系为FuncA -> FuncB -> FuncC。
当程序执行到FuncB中即将调用FuncC时(PC指向14行),因为是FuncA调用的FuncB,所以当前返回地址为上面代码第9行,并且稍后调用FuncC后返回地址寄存器会被覆盖为第15行,因此在调用执行FuncC之前,程序需要先保存返回地址寄存器(一般存在栈中)。
另外此时的通用寄存器用于FuncB中的一些数据计算,并且其中的数据在调用完FuncC之后还需要继续使用,而FuncC在执行过程中肯定需要使用寄存器,因此需要先把通用寄存器中的值保存下来,这样FuncC才能使用通用寄存器。
除此之外,FuncC中可能还会声明局部变量,因此它会移动栈指针,这就需要把栈指针寄存器的值也保存下来,FuncC执行完之后,释放占用的栈空吉间。
以上是对上下文切换的简单介绍,如果大家不曾接触过操作系统的相关概念,这里介绍两本书,一本是《操作系统教程》,版本比较多,推荐高等教育出版社的;另一本是黑皮计算机科学丛书系列的《嵌入式与实时操作系统》(王孔啟著)。
2 TriCore上下文切换及CSA机制
2.1 上下文内容
我们知道,在常见的嵌入式内核比如ARM中,上下文的内容都是保存在栈中的,当程序进行调用时,将通用寄存器和链接寄存器等压入栈中,等到调用返回时,再从栈中弹出,形成一个上下文保存机制。
在TriCore内核的上下文切换机制中,上下文是保存在称为CSA的一片区域中的,虽然和栈一样都在RAM中,但是得益于和栈的区分式管理,以及CSA的硬件自动切换机制,能够有效地提高内存使用效率和实时性。下面我们先介绍TriCore内核上下文的结构。
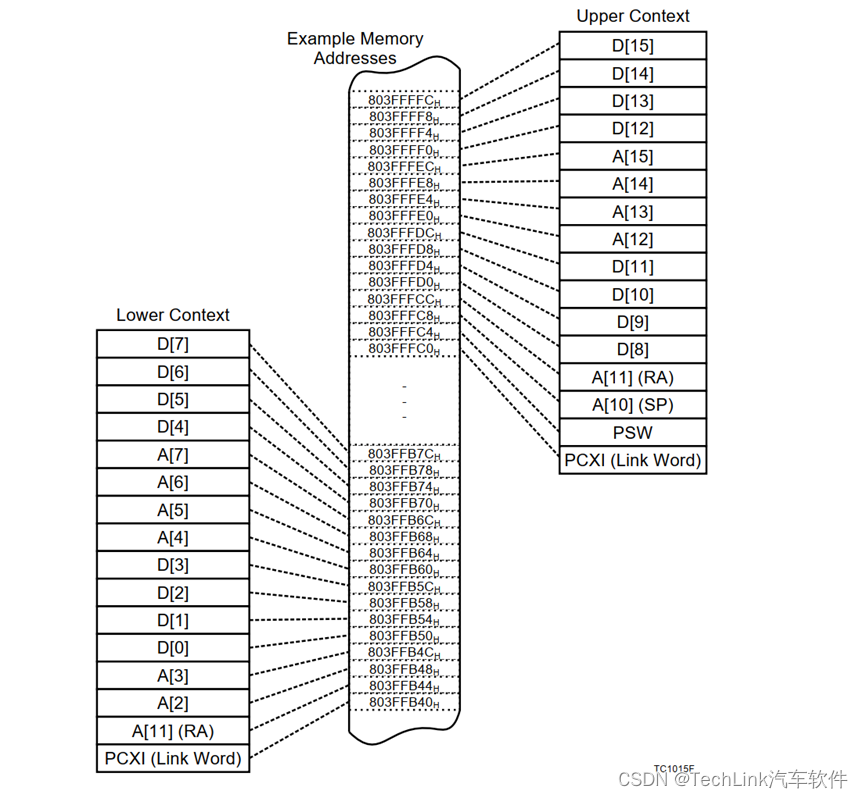
如上图所示,TriCore有高上下文和低上下文,高上下文包括A[10]~A[15]、D[8]~D[15]、程序状态字PSW,低上下文包括A[2]~A[7]、D[0]~D[7]以及A[11],其中仅有返回地址寄存器A[11]在两部分中都存在。A[0]、A[1]、A[8]、A[9]作为全局地址寄存器,不存储在上下文中。
之所以分成两部分上下文,是因为程序在调用过程中,有时候子程序不需要那么多的寄存器,如果所有的寄存器都进行保存则浪费系统开销。TriCore架构中,高上下文是在中断、Trap发生时,由硬件自动保存的,保存后子程序可任意使用高上下文的寄存器。如果高上下文的这些寄存器不够使用,则软件再保存低上下文,以供子中断、Trap程序使用。当然,这些都是由编译器编译过程处理的,编写代码时不需要关注寄存器使用。
每段上下文还有一个PCXI(CPUx Previous Context Information),也称链接字(Link Word)。因为CSA是链表结构,PCXI的功能之一是作为链表指针,另外还用来指示系统保存上下文时的状态,比如中断优先级、中断使能。
高、低上下文都是一段64字节的数据,存储在RAM中,地址由用户分配(需64字节对齐),被分配的内存称为上下文存储区(Context Save Area,CSA)。
2.2 PCXI
PCXI是上下文中第一个4字节的内容,其作为链接字,能够充当链表指针的作用,将多层调用的上下文进行连接,以此来将程序的调用栈展示出来。
每个核有一个PCXI寄存器,指向任务链表的Head,其指向内存中最后保存的64字节上下文,也就是调用栈的栈顶。这段上下文的PCXI又指向下一段上下文,以此来形成任务链表,来表示函数调用关系。我们在TriCore调试过程中调试器给我们展示的调用栈,就是通过上下文的PCXI进行解析的。
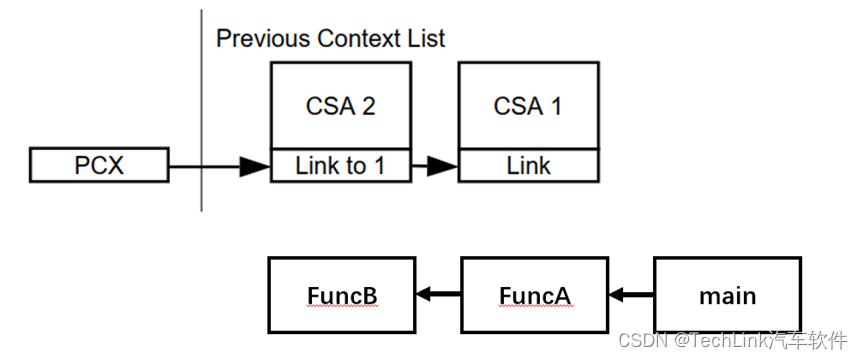
我们可以举个简单的例子,当main函数进行第一层调用,调用FuncA时,会保存一次上下文到CSA1中,FuncA在继续调用FuncB时,又会保存一次上下文到CSA2中,此时的CSA就如上图表示。此时CPU的PCXI指向CSA2,CSA2的PCXI指向CSA1。那这样在FuncB返回时,先从CSA2中加载回到FuncA的运行环境,并将PCX指向CSA1;当FuncA返回时,又从CSA1加载回到main的运行环境,完成上下文的切换。
下面我们介绍PCXI的内容。

如图是PCXI的结构,也就是CPU的PCXI寄存器的结构,主要包括以下内容:
- RES:预留;
- PCPN:前一个CPU中断优先级(Previous CPU Priority Number),在之前关于中断的文章中我们提到过,中断的处理流程的一个步骤,是将ICR.CCPN,也就是当前的CPU中断优先级位,写入到PCPN,也就是本寄存器位中,用于中断环境的保存,中断执行完之后再进行恢复;
- PIE:先前中断使能位(Previous Interrupt Enable),同PCPN,在中断处理流程中将CPU中断使能状态位ICR.IE,保存到PIE中,用于中断环境保存,中断执行完之后再进行恢复;
- UL:高、低上下文标签(Upper or Lower Context Tag),1表示高上下文,0表示低上下文;
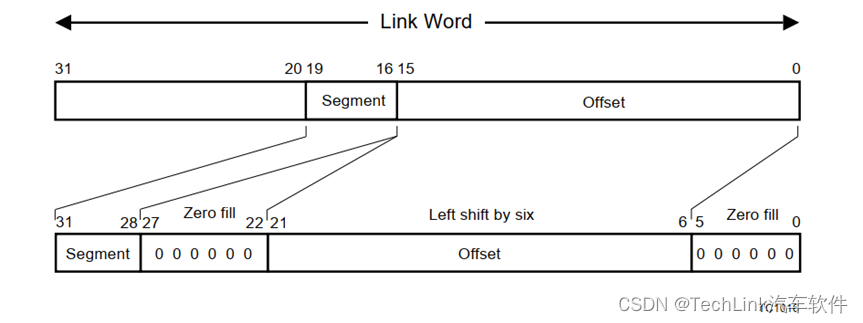
- PCXO、PCXS:PCXI内存地址偏移,与PCXI Segment编号,一起组成链表指针,指向最后一个被保存的上下文段,也就是调用栈的栈顶。地址计算关系为**((PCXS<<12) | (PCXO<<6))**。如下为地址计算示意图:
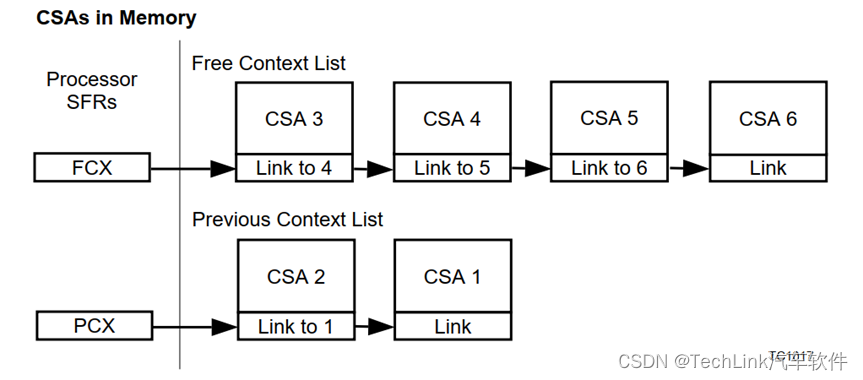
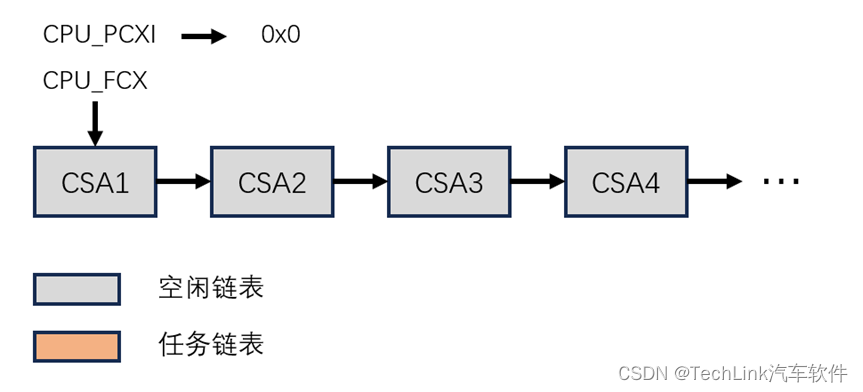
除了PCXI,每个CPU中还有FCX寄存器和LCX寄存器。FCX(CPUx Free CSA List Head Pointer)指向的是空闲的CSA链表的头,也就是第一个可用的CSA,当发生调用时,从这个头依次使用CSA段。因为CSA是可分配的内存段,当CSA区域被使用完时,系统会进入异常。而LCX(CPUx Free CSA List Limit Pointer)就是用来表示CSA的终点。
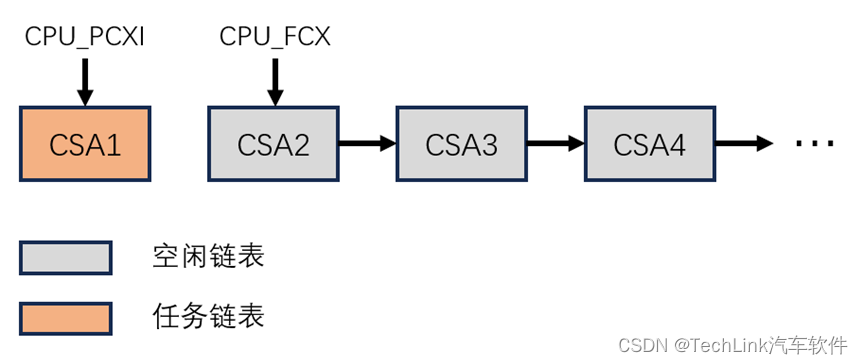
也就是说,对于单任务系统来说,PCXI和FCX以及内存中上下文中的PCXI,利用内存中的CSA区域,构成了两个链表,一个空闲链表,一个已保存当前上下文的任务链表,当系统需要保存上下文时,就会从空闲链表开头中取一个CSA段,连接到任务链表的头位置;当系统恢复上下文时,会从任务链表的头,也就是调用栈的栈顶,将这个CSA段还给空闲链表的头。如下图所示当前使用了两个CSA,PCX指向最后一个保存的上下文CSA2,FCX指向第一个空闲可用的上下文CSA3。
而对于多任务系统来说,因为每个任务都是独立的线程,因此会有自己独立的任务链表,这个内容则需要操作系统进行维护,在每次切任务的时候切换任务链表指针。但是空闲链表还是只有一个,仍然是依靠上下文中的链接字来保持链表关系。
2.3 CSA(Context Save Area)
介绍完CSA的内容和结构,我们来介绍下CSA的保存和切换机制。
CSA是分配在内存中的一片RAM区域,所以我们可以在工程的链接文件中看到CSA的内存分配:

因为CSA中每段上下文是64字节,且取地址过程中末位6位填充为0,因此CSA段必须严格64字节对齐。
并且在系统初始化阶段,会初始化PCXI寄存器和FCX、LCX寄存器,并初始化CSA区域的链表结构。以下为Infineon官方MCAL代码提供的示例。
IFX_SSW_INLINE void Ifx_Ssw_initCSA(unsigned int *csaBegin, unsigned int *csaEnd)
{
unsigned int k;
unsigned int nxt_cxi_val = 0U;
unsigned int *prvCsa = 0U;
unsigned int *nxtCsa = csaBegin;
unsigned int numOfCsa = (((unsigned int)csaEnd - (unsigned int)csaBegin) / 64U);
for (k = 0U; k < numOfCsa; k++)
{
nxt_cxi_val = ((unsigned int)((unsigned int)nxtCsa & ((unsigned int)0XFU << 28U)) >> 12U) | \
((unsigned int)((unsigned int)nxtCsa & ((unsigned int)0XFFFFU << 6U)) >> 6U);
if (k == 0U)
{
Ifx_Ssw_MTCR(CPU_FCX, nxt_cxi_val); /* store the new pcxi value to LCX */
}
else
{
*prvCsa = nxt_cxi_val;
}
if (k == (numOfCsa - 3U))
{
Ifx_Ssw_MTCR(CPU_LCX, nxt_cxi_val); /* Last but 2 context save area is pointed in LCX to know if there is CSA depletion */
}
prvCsa = (unsigned int *)nxtCsa;
nxtCsa += IFX_SSW_CSA_SIZE; /* next CSA */
}
*prvCsa = 0U; /* Store null pointer in last CSA (= very first time!) */
Ifx_Ssw_DSYNC();
}
我们可以调试查看实例,我们从编译后的map文件可以看到,分配的CSA地址为0x70039c00~0x7003bc00,一共8k空间。

然后我们将断点打在CSA初始化代码之后,查看寄存器:

通过前文提到的PCXI地址转换关系可知FCX指向0x70039C00,也就是指向了CSA的第一个段。LCX指向0x7003BB40,距离CSA的末尾地址还有192字节,也就是预留了3个CSA段的安全间隙。FCX为0表示当前还没有进行过上下文保存。
然后我们再打开内存中的CSA区域查看数据内容:

我们可以看到,系统的FCX寄存器指向了第一个CSA段,CSA段中的PCXI依次指向下一个CSA段,形成一个空闲链表。
2.4 上下文切换操作
介绍完了上下文内容以及上下文的内存结构,我们接下来介绍下在哪些场景下,CSA中的上下文会进行保存和恢复。
上下文的保存和恢复是由一个事件或指令来触发的,事件包括中断、异常或CALL调用。下表列出了具体的操作场景:
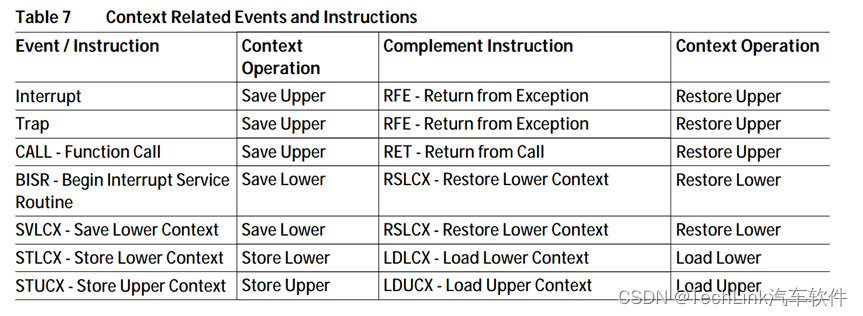
首先我们看前三个,中断、异常和函数调用,这三种场景下,高上下文是会自动保存的。对于中断和异常,编译器会在返回处添加RFE指令,用于恢复高上下文,归还CSA段,并且加载返回地址到PC中,完成调用返回。对于函数调用也会添加一条RET指令,同样也执行上述操作。
然后我们看BISR和SVLCX指令,这两条指令会保存低上下文,是由编译器根据寄存器的使用情况来定的,用户也可通过内联汇编来保存低上下文。一般当高上下文包含的寄存器不够用时,才会使用低上下文。比如中断程序较长,或调用子程序较长时。恢复的话则需要使用RSLCX指令,将上下文中的数据恢复到指定寄存器中。
最后我们看STLCX和STUCX,这两条指令使用较少,它们的功能是仅将通用寄存器以CSA的格式,保存到指定的内存中(非CSA区域),并在LDLCX和LDUCX时将数据恢复到通用寄存器中。其他寄存器如PCXI、FCX等均不受影响。也就是说该指令仅做全局寄存器的暂存和恢复,不做任何系统状态切换。
2.5 上下文小结
我们来回看下TriCore上下文的机制,以便我们理解下面的实例。
TriCore的上下文为64字节存储段,包括通用寄存器、PSW等内容,包括高上下文和低上下文两类。
上下文段存储在RAM中称为CSA的内存区域中,以链表的形式体现。有空闲链表和任务链表,任务链表也可以表征系统的调用栈。当发生中断、异常或调用时,从空闲链表中取一个链接到任务链表的头,返回时将任务链表的头去除归还到空闲链表。
CPU对链表的句柄包括PCXI寄存器、FCX寄存器和LCX寄存器。PCXI指向最后一个保存的上下文段,也就是任务链表的头;FCX指向下一个可用的CSA段,也就是空闲可用链表的头;LCX表示CSA区域的使用限制,在保存时如果FCX指向LCX指向的区域,则发生异常。
上下文切换的操作包括中断、异常和函数调用时的硬件自动保存操作,自动操作的对象为高上下文,编译器或用户可通过指令操作低上下文。
另外还有一点需要注意的是CSA的内存大小分配,我们都知道嵌入式的内存资源是有限的,因此CSA不能分配太大,但是分配太小如果使用超出范围会产生异常导致系统崩溃。在分配的过程中根据实际情况来定,已知一层函数调用使用一个CSA段64字节,可分析系统的最大调用深度,再加上安全预留空间。如果是多任务操作系统,因为每个线程的调用栈是独立的,所以所有任务的CSA段资源消耗是累加的,分配时也需要注意综合考虑(inline函数和较短的函数编译器会进行优化,一般调用过程不占CSA)。
3 使用示例
下面我们通过两个使用示例来观察上下文的操作流程,第一个是单任务系统中的逐级调用,第二个是中断服务程序。
3.1 单任务系统中的上下文切换
单任务系统也就是单线程系统,除了中断以外系统的调用栈是单线的。下面我们通过一段函数调用来看CSA的使用过程。
3.1.1 初始化阶段
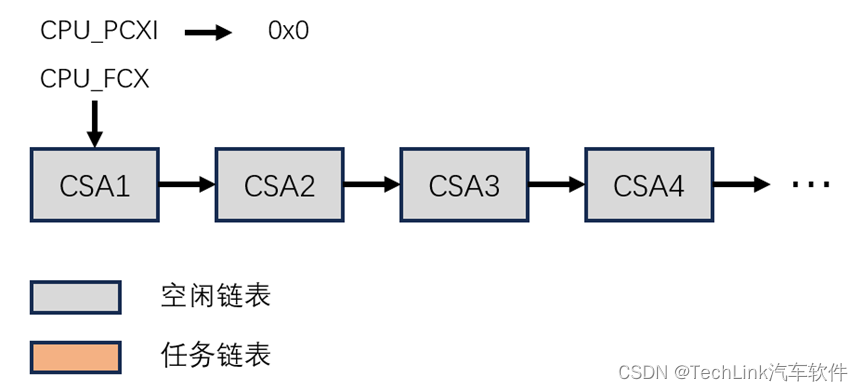
首先我们让函数执行到main中,此时没有调用,也没有上下文保存,PCXI指向空,FCX指向CSA的第一个段CSA1。

在内存中第一个段为0x70039C00,它是空闲链表的头,指向下一个空闲CSA:
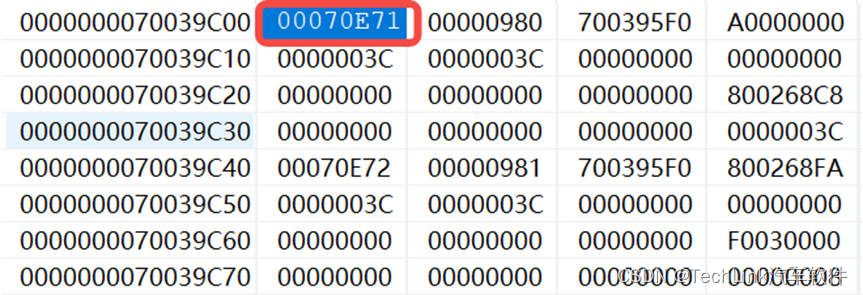
为了方便理解,我们将CSA按段画成示意图,用下图表示在没有上下文保存发生时的CSA状态。
3.1.2 第一层调用
然后我们向下执行代码,调用EcuM_Init。CALL指令表示跳转,同时自动保存高上下文。

此时执行了一次CALL指令,因此寄存器发生了变化:

我们通过换算可以看出,PCXI指向了CSA1,FCX指向了CSA2,因此CSA2成了空闲链表的头。并且CPU的PCXI中的UL位为1,表示其指向的上下文是一个高上下文(CALL指令调用自动保存高上下文)。
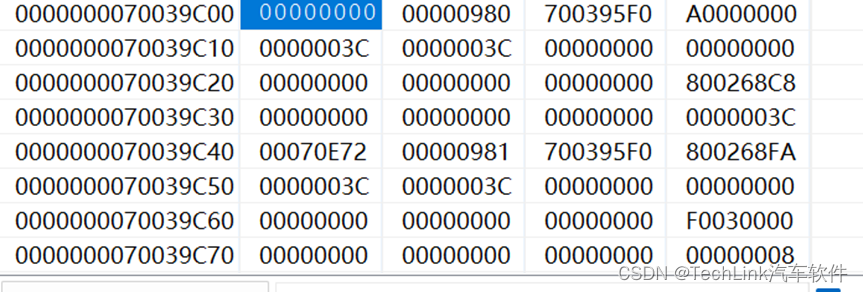
然后从内存中我们可以看到CSA第一个段CSA1的PCXI指向了0,因为任务链表仅有一个元素,所有它指向空;CSA2仍然指向CSA3,此时的CSA内容如下图所示:
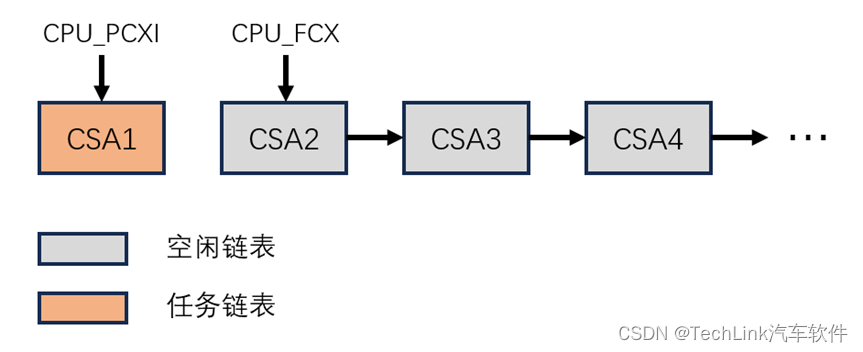
3.1.3 第二层调用
我们再继续往下,让EcuM_Init调用Mcu_Init。
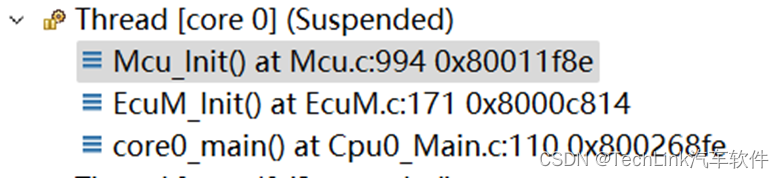
然后观察此时的寄存器,发现此时PCXI已经向下偏移了一个CSA段,指向了CSA2,同时FCX也指向了CSA3。

然后我们到内存中,发现此时任务链表的头CSA2,已经指向了CSA1,CSA3没有被修改,继续指向CSA4。
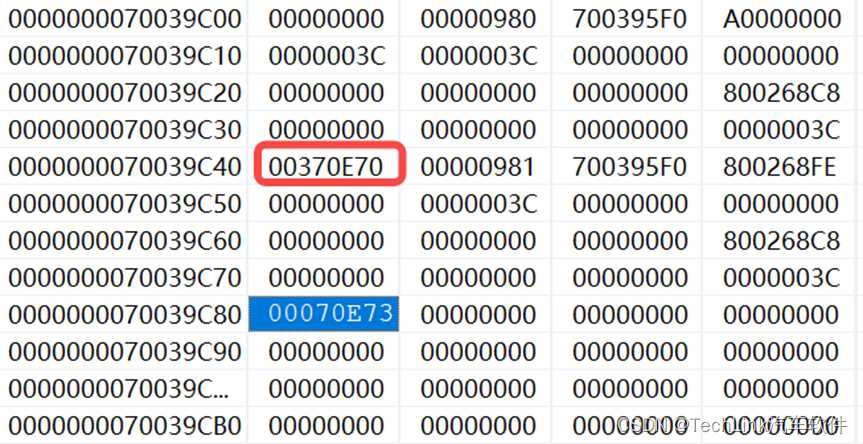
同样我们画出CSA示意图:
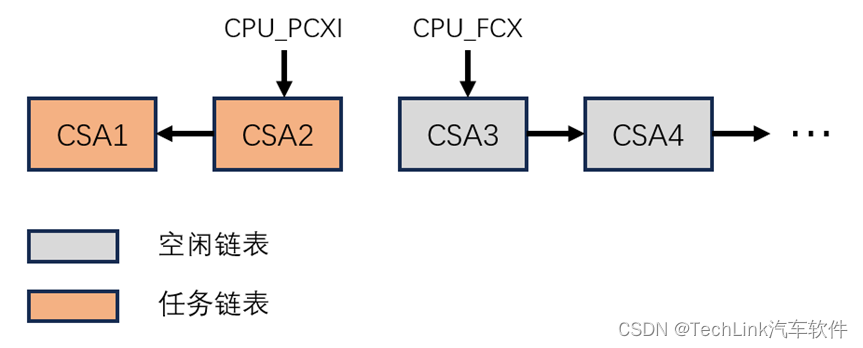
在这个阶段程序的上下文链表的形式得以展示出来,我们可以看到,随着调用栈的逐级增多,任务链表逐渐加长。
我们还可以观察,CSA2中保存的A11返回地址寄存器0x800268FE,它表示上一层调用EcuM_Init的返回地址,而Mcu_Init的返回地址在当前的A11返回地址寄存器中。其他的通用寄存器也是一一对应的。
3.1.4 第二层调用返回
首先我们将断点打在第二层调用Mcu_Init的最后一行,我们可以清楚地看到这里有一个RET指令,这是编译器添加的与CALL成对的指令。它的执行会恢复高上下文,并根据当前返回地址返回到上一层调用。

我们执行该指令,然后观察寄存器。

发现此时PCXI向前回退了一个CSA段,指向了CSA1,同时FCX也会退了一个段指向了CSA2。
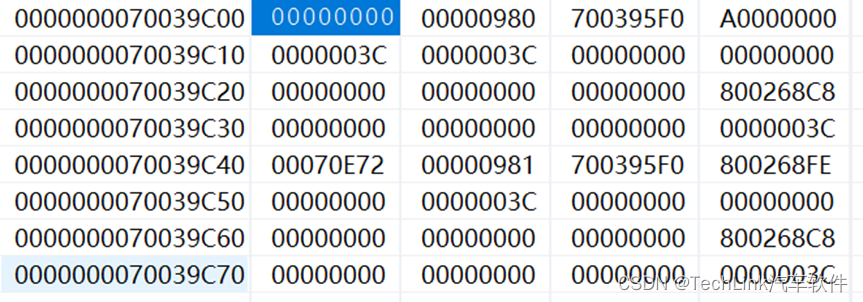
我们观察内存发现CSA2的PCXI(70E72)指向CSA3,而CSA1指向空,同样我们画出示意图:
此时其实就是回到了第二层调用之前的状态,也就是归还了第二层调用所使用的CSA。
3.1.5 第一层调用返回
同样的,在执行到EcuM_Init的最后时,也会执行RET指令,恢复上下文并返回到之前调用位置,我们直接画出示意图,也就回到了最初的状态。
以上我们就完成了单任务系统调用过程中的上下文切换流程,对于多任务系统也是类似的,只是在任务切换过程中操作系统需要把对应的三个系统寄存器都切换到对应Task的状态即可。
另外对于CSA在切换时的内部硬件逻辑,因为其与软件没有太大相关性,这里没有介绍,感兴趣的读者可以自行阅读内核手册。
3.2 中断服务程序中的上下文切换
下面我们介绍中断服务程序中的上下文切换。
3.2.1 进入中断程序
因为中断是在常规任务执行时进入的,所以首先我们需要在中断的入口处打一个断点,这里我选择了ADC3的中断。可以看到CPU进行了一层子函数调用,然后被ADC中断打断。
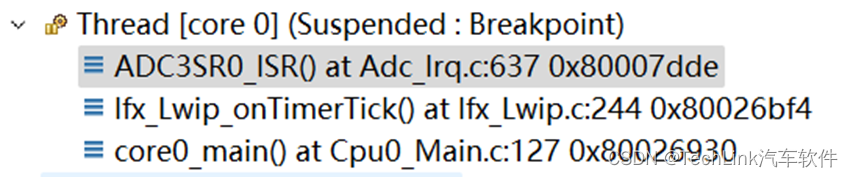
然后我们观察CSA相关寄存器:

我们可以看到PCXI指向了CSA2,FCX指向了CSA3。这里我们直接画出CSA示意图,因为存在普通程序调用栈和中断程序调用栈,我们加一个底色进行区分:
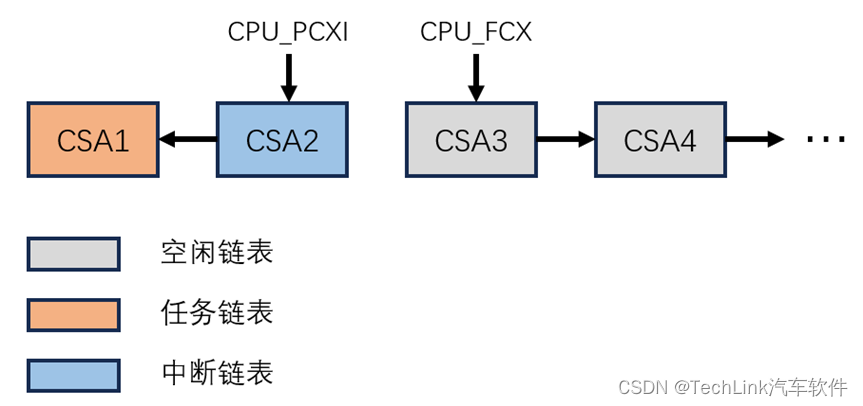
从图上我们可以看出,main经过了一层调用,所以使用了CSA1,随后中断发生后由硬件保存了CSA2。
3.2.2 保存低上下文
由于中断的服务程序比较长,所以编译器在这里使用SVLCX指令保存了低上下文,这里我们介绍下这个流程。
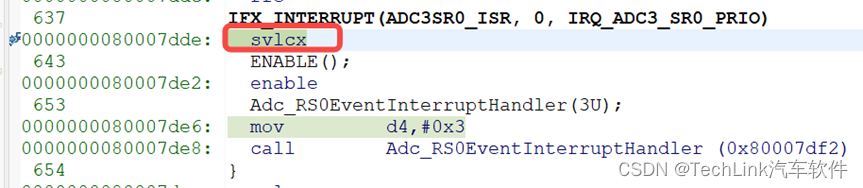
我们执行该指令然后观察CSA相关寄存器:

同样的我们发现PCXI和FCX都发生了偏移。这里我们注意到PCXI的PCPN位为120,这是因为进入中断后,当前中断优先级为120,所以在进行上下文保存时会保存到PCPN位域中。同时SVLCX保存的是低上下文,所以PCXI的UL位域为0。同样我们也画出示意图:
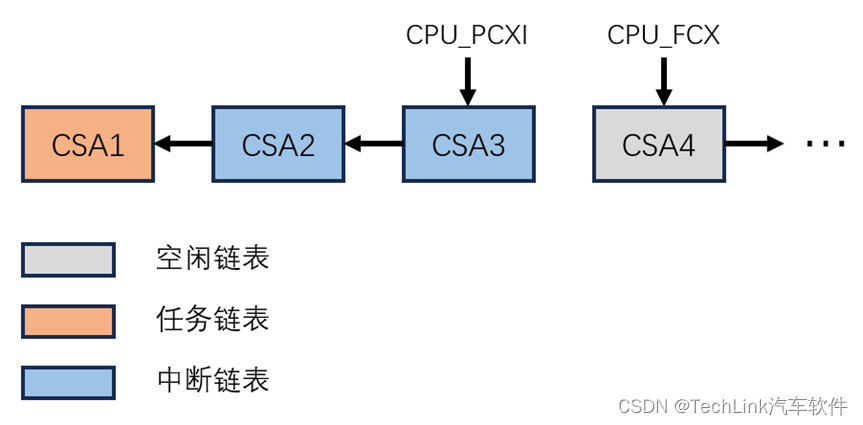
中间还有一步CALL来调用中断的服务程序,这和普通程序流程一样,这里不做描述。
3.2.3 恢复低上下文
在执行完中断的服务程序之后,编译器这里添加了一条和SVLCX成对的RSLCX指令来进行低上下文恢复。
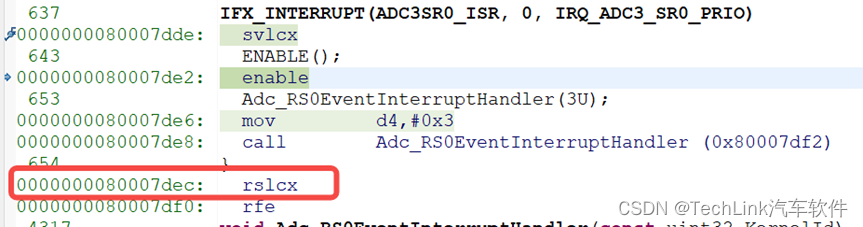
执行之后CSA回到了SVLCX执行之前的状态:
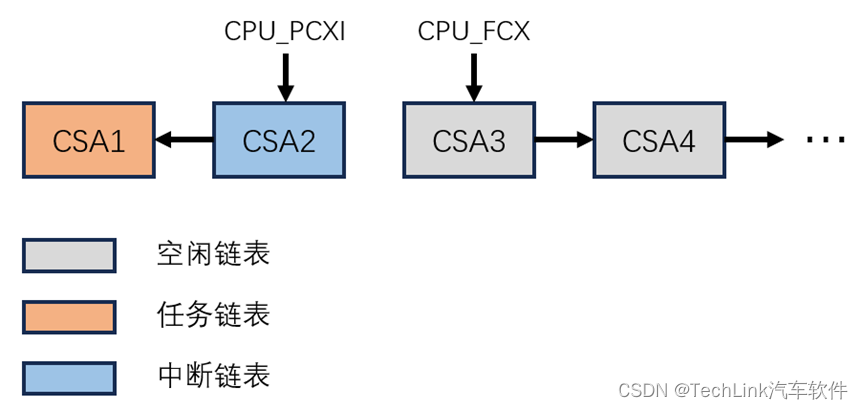
3.2.4 退出中断程序
执行完这些之后,程序会在最后执行RFE指令时退出中断程序,恢复硬件自动保存的高上下文,返回到中断前的地址,并切换相关的系统状态。到这里想必你已经很熟悉CSA的流程了,我们直接看示意图。
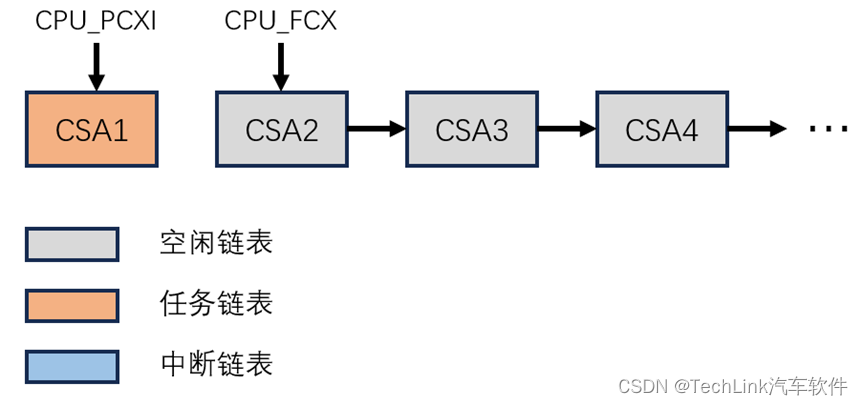
此时中断的处理完全结束,系统继续处理常规程序。
4 小结
本文详细介绍了TriCore内核的上下文机制,以及CSA的存储和实现逻辑。并通过实例向读者展示了TriCore内核在程序调用和中断等过程中的上下文处理流程,能够使读者对TriCore的内核有更深刻的认知,并且能够帮助读者在调试过程中更好地处理一些系统调用方面的内核问题。下一篇,我们将介绍一个实用性非常强,也是大家在处理系统性问题必须要掌握的模块——Trap系统,敬请期待!
参考资料
- Infineon-AURIX_TC3xx_Architecture_vol1-UserManual-v01_00-EN.pdf

















 1800
1800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









