






语义分割是计算机视觉中的一个任务,常用的语义分割损失函数包括:
交叉熵损失(Cross Entropy Loss)
「交叉熵损失(Cross Entropy Loss)」是在分类任务中常用的一种损失函数,也被称为负对数似然损失(Negative Log-Likelihood Loss)。它主要用于测量模型输出的概率分布与实际标签之间的差异。在语义分割任务中,交叉熵损失通常被应用于像素级别的分类。
假设有一个像素属于C类别的图像,其真实标签为one-hot编码的向量[0, 0, ..., 1, ..., 0],其中1表示该像素属于第C类别。而模型的输出是一个概率分布向量,表示每个类别的预测概率。交叉熵损失的计算公式如下: 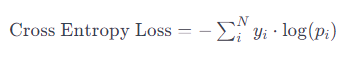
其中:
-
(N) 是类别的数量。 -
(yi) 是真实标签的第i个元素(0或1,表示不属于或属于该类别)。 -
(pi) 是模型预测的第i个类别的概率。
交叉熵损失的目标是最小化模型输出的概率分布与真实标签之间的交叉熵。当模型的预测概率分布与真实标签完全一致时,交叉熵损失达到最小值为0。但如果预测与真实不一致,则损失增大,模型被鼓励调整参数以更好地逼近真实分布。
Dice损失
「Dice Loss」是一种常用于语义分割任务的损失函数,它基于Dice系数,旨在优化模型的预测与真实标签之间的重叠。Dice系数衡量了两个集合的相似性,特别适用于不平衡类别的分割任务。 Dice系数(或F1 Score)的计算公式如下: 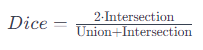 其中:
其中:
-
Intersection 表示预测掩码和真实掩码的交集(相交的区域)。 -
Union 表示预测掩码和真实掩码的并集。 Dice Loss是根据Dice系数设计的损失函数,其计算公式为:  Dice Loss的目标是最小化模型预测掩码和真实掩码之间的差异,鼓励模型更好地匹配真实分割。与交叉熵损失不同,Dice Loss关注的是像素级别的重叠,尤其在存在类别不平衡的情况下效果显著。
Dice Loss的目标是最小化模型预测掩码和真实掩码之间的差异,鼓励模型更好地匹配真实分割。与交叉熵损失不同,Dice Loss关注的是像素级别的重叠,尤其在存在类别不平衡的情况下效果显著。
在训练语义分割模型时,可以选择使用Dice Loss作为损失函数,也可以将其与其他损失函数(如交叉熵损失)结合起来,以平衡各种任务需求。
Jaccard损失
「Jaccard损失」是一种用于语义分割任务的损失函数,它基于Jaccard系数,也被称为Intersection over Union (IoU) 或者 Jaccard Index。Jaccard系数测量了两个集合的相似性,常用于评估预测掩码与真实标签的重叠程度。
Jaccard系数的计算公式如下: 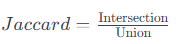
其中: Intersection 表示预测掩码和真实掩码的交集(相交的区域)。 Union 表示预测掩码和真实掩码的并集。 Jaccard损失是根据Jaccard系数设计的损失函数,其计算公式为: 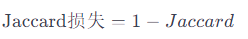
Jaccard损失的目标是最小化模型预测掩码和真实掩码之间的差异,鼓励模型更好地匹配真实分割。与Dice Loss相似,Jaccard损失也关注像素级别的重叠,而不仅仅是类别的正确分类。
在训练语义分割模型时,可以选择使用Jaccard损失作为损失函数,或者将其与其他损失函数结合起来,以满足任务的需求。 Jaccard损失在处理类别不平衡或者关注对象边缘细节的分割任务中常常表现良好。
Focal Loss
「Focal Loss」是一种专为解决类别不平衡问题而设计的损失函数,最初提出用于目标检测任务。然而,它也可以应用于语义分割等其他任务。Focal Loss通过降低易分类的样本的权重,减缓容易分类样本对梯度的贡献,从而专注于难以分类的样本,提高模型对难分样本的关注度。
Focal Loss的计算公式如下:
其中:
-
是模型对样本的预测概率。 -
是平衡因子,用于调整易分类样本和难分类样本的权重。 -
是调整因子,用于调整难易样本的重要性。
Focal Loss的特点在于它引入了 的项,这个项能够有效降低易分类样本的权重。当样本被错误分类时, 趋近于0,从而增加了这个样本的损失值。而对于容易分类的样本, 较大,其损失相对较小。
通过引入Focal Loss,模型更加关注难以分类的样本,从而在类别不平衡的情况下取得更好的性能。这种损失函数的设计使得模型更加容易处理大量容易分类的背景样本,同时专注于关键样本,提高模型对难以分类的对象的检测和分割能力。
Lovasz-Softmax损失
Lovasz-Softmax Loss是一种用于语义分割任务的损失函数,它结合了Lovasz扩展和Softmax损失。Lovasz-Softmax Loss的设计目标是在非平衡的二分类和多类别分割任务中更好地优化模型。
Lovasz扩展主要用于处理非平衡类别的问题,而Softmax损失则用于多类别分割任务。Lovasz-Softmax Loss的计算公式如下: Lovasz-Softmax Loss=Softmax Loss+λ⋅Lovasz Hinge Loss 其中:
-
Softmax Loss是常规的Softmax交叉熵损失,用于处理多类别分割任务。
-
Lovasz Hinge Loss是Lovasz扩展的一种形式,用于处理非平衡的二分类问题。Lovasz Hinge Loss是一种用于处理非平衡二分类问题的损失函数,它是Lovasz扩展的一部分,旨在优化模型对难以分类的样本的性能。Lovasz Hinge Loss在一些任务中,如图像分割中的边缘检测,通常表现得比传统的Hinge Loss更好。Hinge Loss通常用于支持向量机(SVM)等任务,其计算公式为:
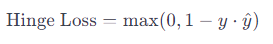 其中:y 是真实标签(+1或-1),y是模型的预测。Lovasz Hinge Loss在此基础上进行了扩展,引入了Lovasz扩展的思想,使得损失函数更适用于非平衡的二分类问题。Lovasz Hinge Loss的计算公式如下:
其中:y 是真实标签(+1或-1),y是模型的预测。Lovasz Hinge Loss在此基础上进行了扩展,引入了Lovasz扩展的思想,使得损失函数更适用于非平衡的二分类问题。Lovasz Hinge Loss的计算公式如下: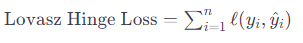 在Lovasz Hinge Loss中,通过对预测概率排序,引入了可微的Hinge Loss。这使得在训练过程中,模型能够更好地学习难以分类的样本。Lovasz Hinge Loss的设计考虑到了非平衡类别的问题,对于一些具有类别不平衡的任务,它通常能够提供更好的性能。 Lovasz Hinge Loss经常用于图像分割等任务,特别是对于那些需要关注对象边缘细节的情况。
在Lovasz Hinge Loss中,通过对预测概率排序,引入了可微的Hinge Loss。这使得在训练过程中,模型能够更好地学习难以分类的样本。Lovasz Hinge Loss的设计考虑到了非平衡类别的问题,对于一些具有类别不平衡的任务,它通常能够提供更好的性能。 Lovasz Hinge Loss经常用于图像分割等任务,特别是对于那些需要关注对象边缘细节的情况。 -
λ 是平衡因子,用于平衡Softmax Loss和Lovasz Hinge Loss的权重。 Lovasz-Softmax Loss的目标是最小化Softmax Loss和Lovasz Hinge Loss的组合,以更好地适应非平衡的分割任务。Lovasz Hinge Loss考虑了样本的排列顺序,通过对预测概率排序,对误分类的样本引入了可微的Hinge Loss,使得模型更关注难以分类的样本。
Lovasz-Softmax Loss在一些语义分割任务中表现出色,特别是在存在类别不平衡的情况下。它的设计考虑到了Softmax损失和Lovasz扩展的优点,以提高模型在非平衡类别分割任务中的性能。
总结
这些损失函数在语义分割任务中有不同的性能表现,选择合适的损失函数通常取决于具体的任务要求和数据集特点。后面将会在具体的案例中对上述损失进行对比。感兴趣的可以加入我们的星球,获取更多数据集、网络复现源码与训练结果的。
 加入前不要忘了领取优惠券哦!
加入前不要忘了领取优惠券哦! 
往期精彩



本文由 mdnice 多平台发布
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











