








目录
一、Softmax

Softmax 激活函数 常接在神经网络最后一层之后,以用于分类任务。相比于 Sigmoid 只能用于二分类,Softmax 还可用于多分类。
当然,这并不意味着 Softmax 总是优于 Sigmoid,还需要具体情况具体分析。例如,Softmax 在调整数值范围时,会影响数值间的相对关系,故有时各自独立约束数值范围的 Sigmoid 会更受欢迎。
通常,Softmax 用于所有 预测值 (logits) 转换为 预测概率值 (probs),并约束在有意义的 (0, 1] 范围之间,且概率值之和为 1。
例如,第 个类别的样本预测值 (logit)
,经 Softmax 得到的预测概率值 (prob)
为:

由于网络输出的预测值可能存在负值,故采用 指数处理,使得预测值总大于 0,既得到了符合实际意义的 (0, 1] 概率范围,又统一了量纲便于比较。
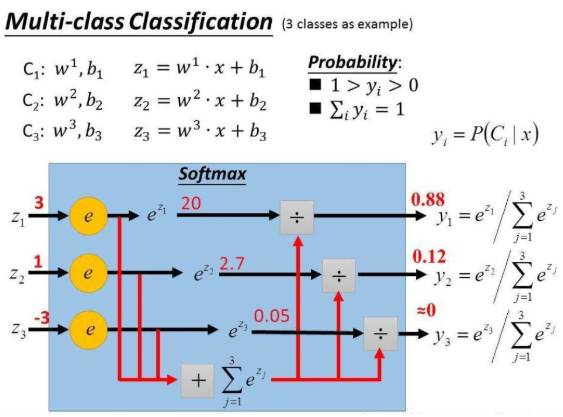

此外,由于是指数运算,往往也会因网络预测值过大造成 指数溢出 的情况 ,如 等就 指数爆炸 了。
因此,通常还需增加一个数值处理,即 令每个预测值先减去最大预测值,再进行指数运算。例如,第 个类别的预测值
经 Softmax 处理和去最大值处理后,得到的预测概率值
为:
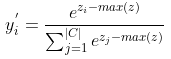
为方便起见,后续说明仍使用未经减去最大预测值处理的 Softmax。
二、Cross Entropy Loss
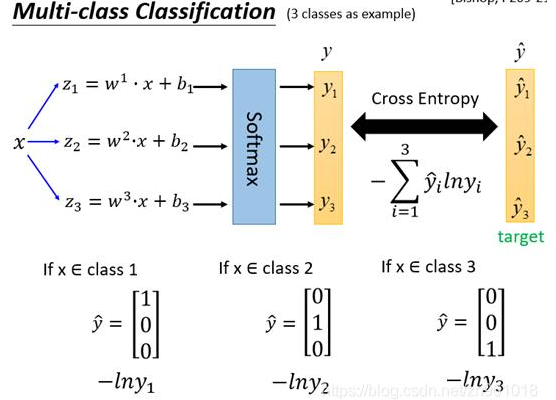
在 单标签多分类 任务中,常用 交叉熵损失 (Cross Entropy Loss) 作为损失函数。
设在某个 分类问题下,模型对第
个样本的 预测值 (logits) 为
,经 Softmax 得到 预测概率值 (probs) 为
,其 GroundTruth / Label / Target 为
,则 第
个样本的交叉熵损失
为 (如上图例子所示):

注意,当使用 One-Hot 编码时可知,只有当前第 个样本的预测概率值
及其对应的真实标签为
,故该项损失为
;而其余项因
计算损失时均为 0。因此,单标签多分类任务下,每个样本仅属于一个类别,即只有一项损失不为 0。那么,第
个样本的交叉熵损失
实际可表示为:
![]()
因此,设 batch size = ,则 一个 batch 的交叉熵损失
可表示为:
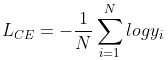
三、Softmax Cross Entropy Loss
紧接上节,若将网络最后一个全连接层的 Softmax 操作单独提取出来,可得到针对 一个 batch 的预测值 (logit) (而非预测概率值) 的 Softmax Loss 为:

举个例子,设在某三分类问题下 ,对某一模型输入
的 batch。
其中样本 1 的模型预测值 ,
,那么该 batch 的 Softmax Loss 为:
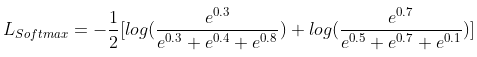
实际操作中,通常会在网络最后一层接一个 Softmax,很多 paper 将 传统 Softmax loss 表示为如下形式:
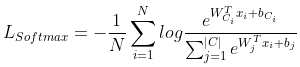
其中, 和
是网络最后一个全连接层的第
个权重和偏置;
和
则是馈入的深层特征
的 GT / Target / Label
所对应的权重和偏置,简称 Target 权重 和 Target 偏置。
简言之,Softmax Loss 与 Softmax 和 Cross Entropy Loss 的关系是:将网络输出的预测值 (logit) 先用使用 Softmax 转换为预测概率值 (probs),再传入 Cross Entropy Loss 计算,就得到了最终的 Softmax Loss。
换言之,Softmax Cross Entropy Loss = Softmax + Cross Entropy Loss。


















 3613
3613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









