







VOTT数据标注工具标注数据集和YOLOX模型部署训练
系列前两篇:
【YOLO&Pytorch】从0开始的基于Pytorch的YOLO系列项目理论+实战部署01 pytorch环境的配置及安装
【YOLO&Pytorch】从0开始的基于Pytorch的YOLO系列项目理论+实战部署02 编辑器的配置
通过这篇文档完整演示如何使用VoTT工具标注自己的视频数据集以及在本地部署YOLOX模型并进行训练和测试。把整个过程遇到的所有坑都完整展示一遍,包括是如何解决问题的,相信能够帮助大家实际完成自己项目的部署。
下载和安装VoTT
这是搜索整理的开源数据标注工具
目前主要包括面向图像、视频、文本和声音四个方面。
其中图像的标注工具有以下的:

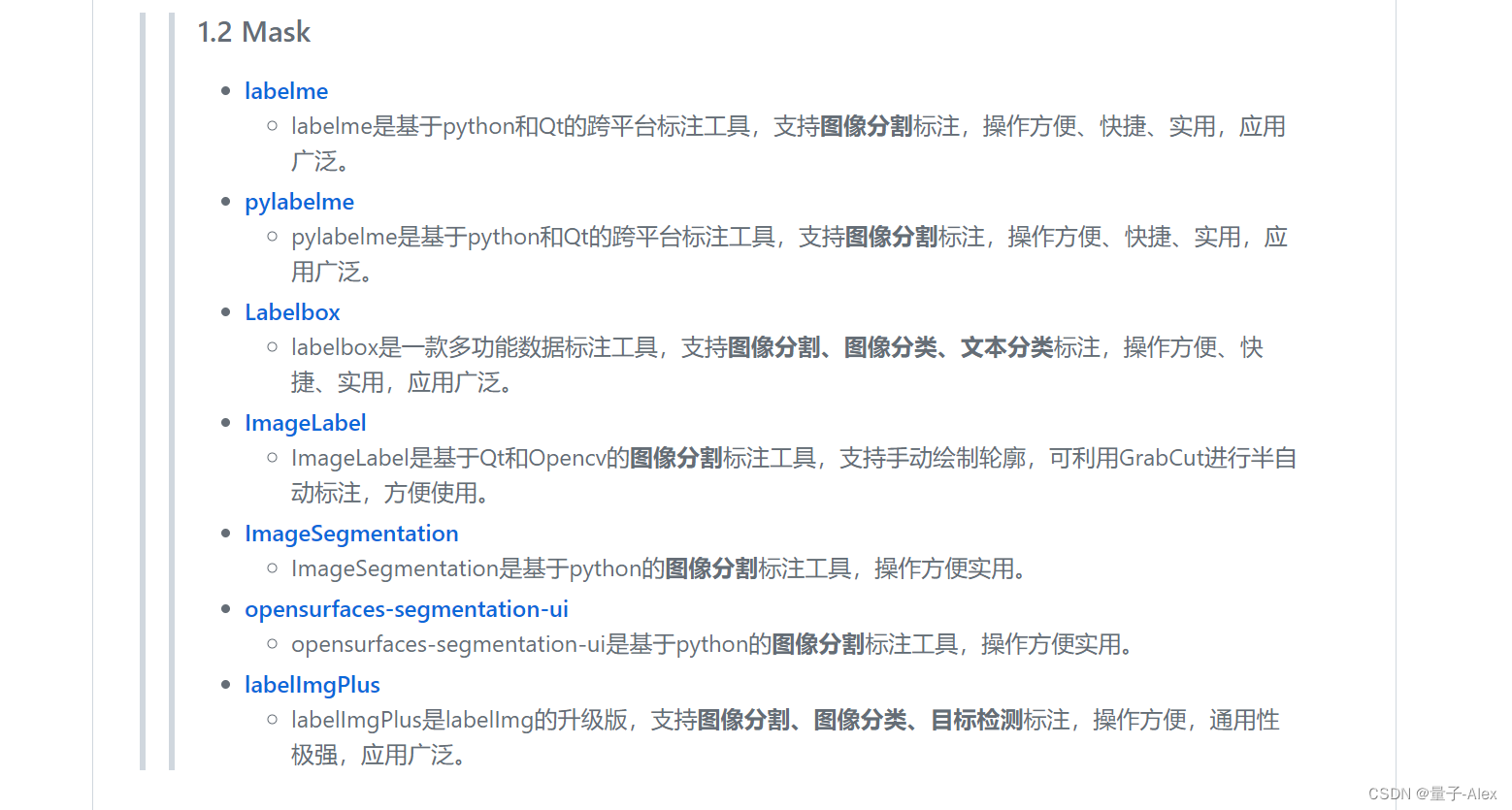
其中视频的标注工具有以下的:
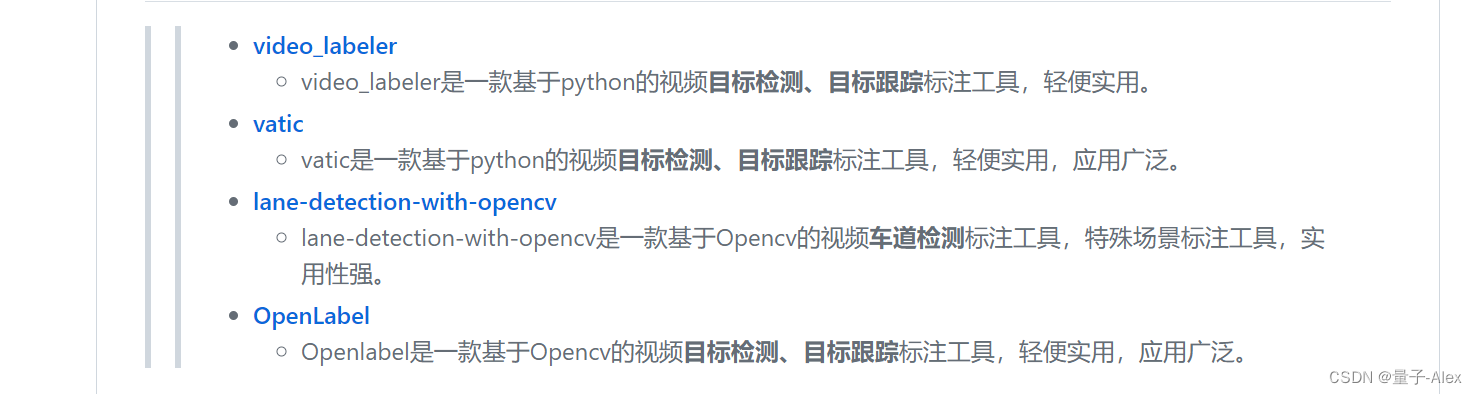
文本的标注工具有以下的:
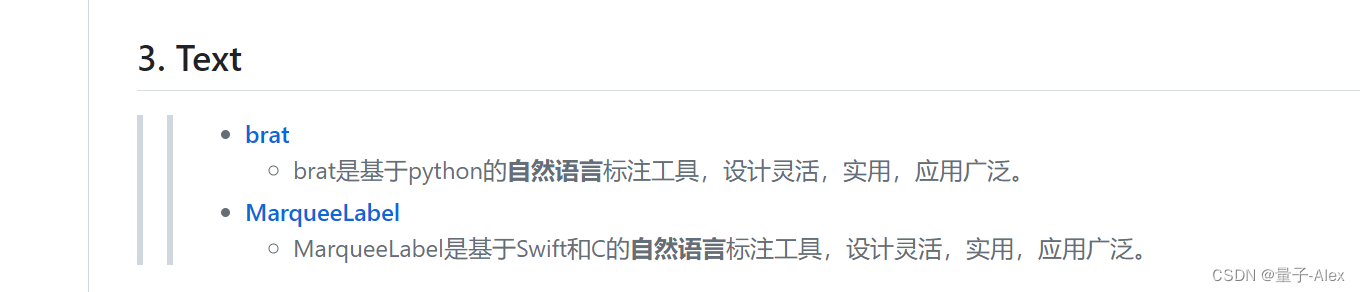
音频的标注工具有以下的:

这篇文章主要介绍VoTT的安装与使用方法。
下载与安装
点击VoTT的链接,进入下面的页面
VOTT
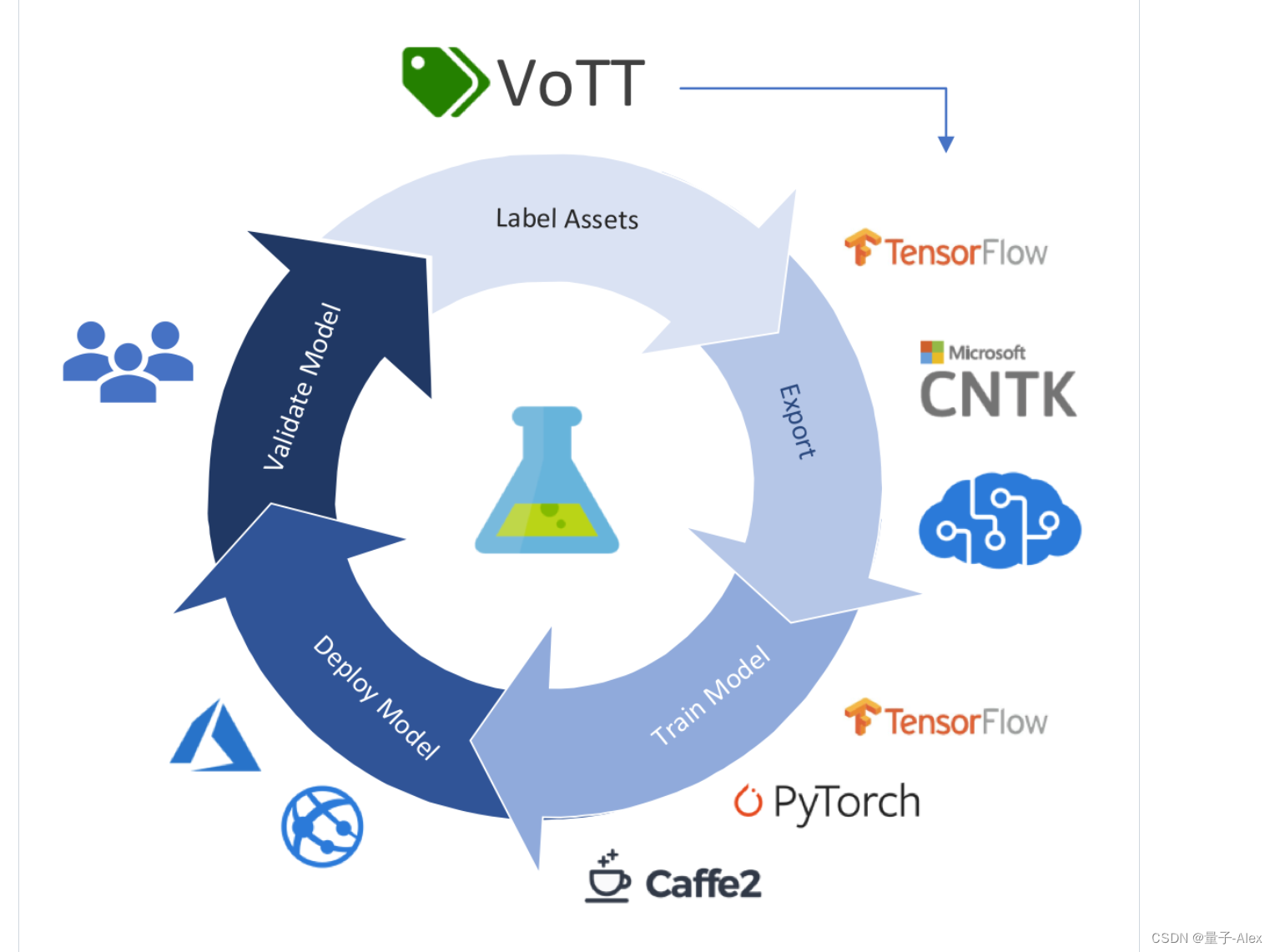

可以看到有对VoTT的介绍和使用教程,教程的话不用细看,我在这篇文章里面会说的很清楚。
点击上图中的release,点击
下载下来就是exe可执行文件可以直接使用,我把它放到D盘的program files里面
使用
首先我们在项目文件夹下面新建两个文件夹
一个命名为source,放源文件,一个命名为target 放处理后的文件

VoTT的界面长这个样子

我们点击左边的New Project图标

Display name 自己命名
Security Token选择它默认的
在Source Connection 中点击后面的Add Connection

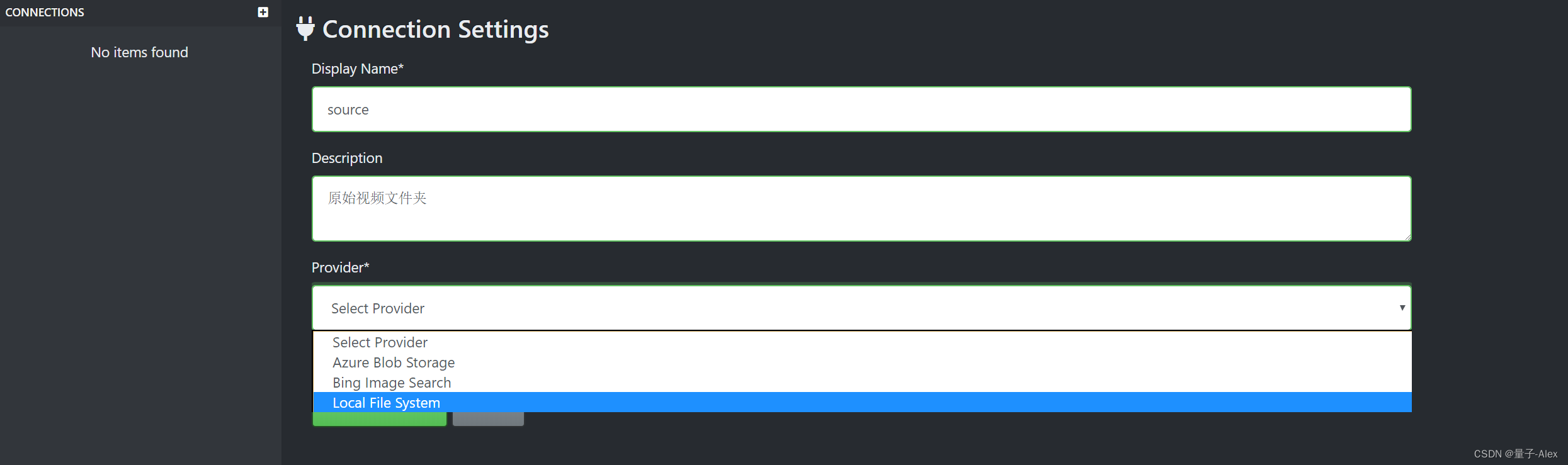
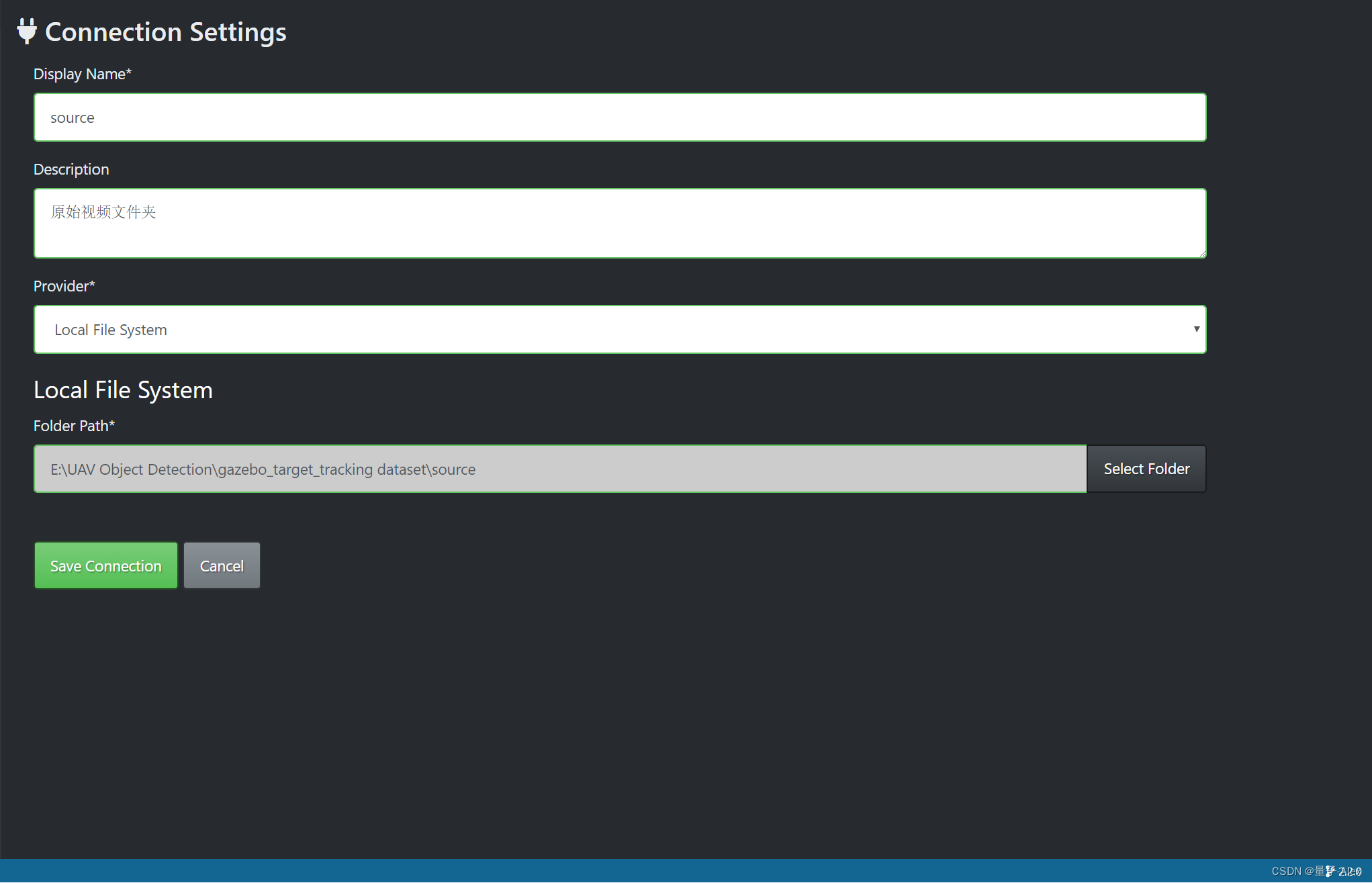
点击 Save Connection
配置target Connection
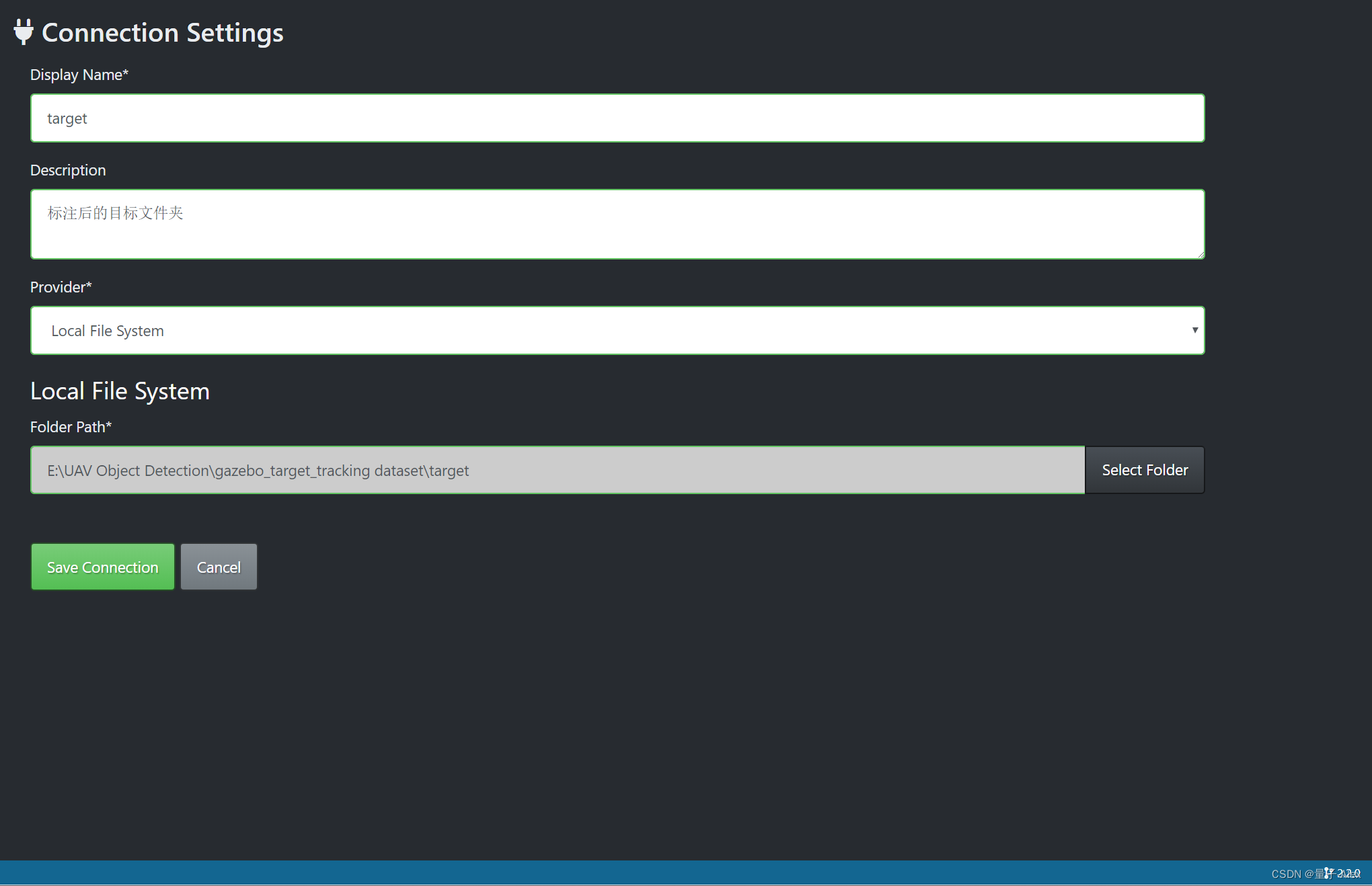
配置好了以后别忘了在下拉框中选择

下面的Video settings是设置视频的FPS,即1秒钟多少帧,一般为了保证视频的流程,最低要30帧,也就是它把视频1秒钟切出30张图像,然后我们挨个去标注,如果是这样的话,一旦视频时长比较长的话,我们的标注工作量会非常大。这里我们先采用默认的设置15.
下面的tags标签,我们可以现在添加,也可以稍后添加,我们稍后再添加。
点击Save project
下面就进入了我们的项目,但是这里出现了问题
提示Unable to load assets就是无法加载资源
我查了一下,不少的说是视频格式,不是mp4格式的视频它没法读取,但是我这几个视频明明是.mp4,我抱着试试看的心态下载了格式转换工厂软件。

发现我的原始视频文件是mpeg4编码格式,然后我尝试着转换成h264编码的,结果就好了!
当然还有别的要注意的地方,就是source和target的文件夹路径里面不要有空格和中文
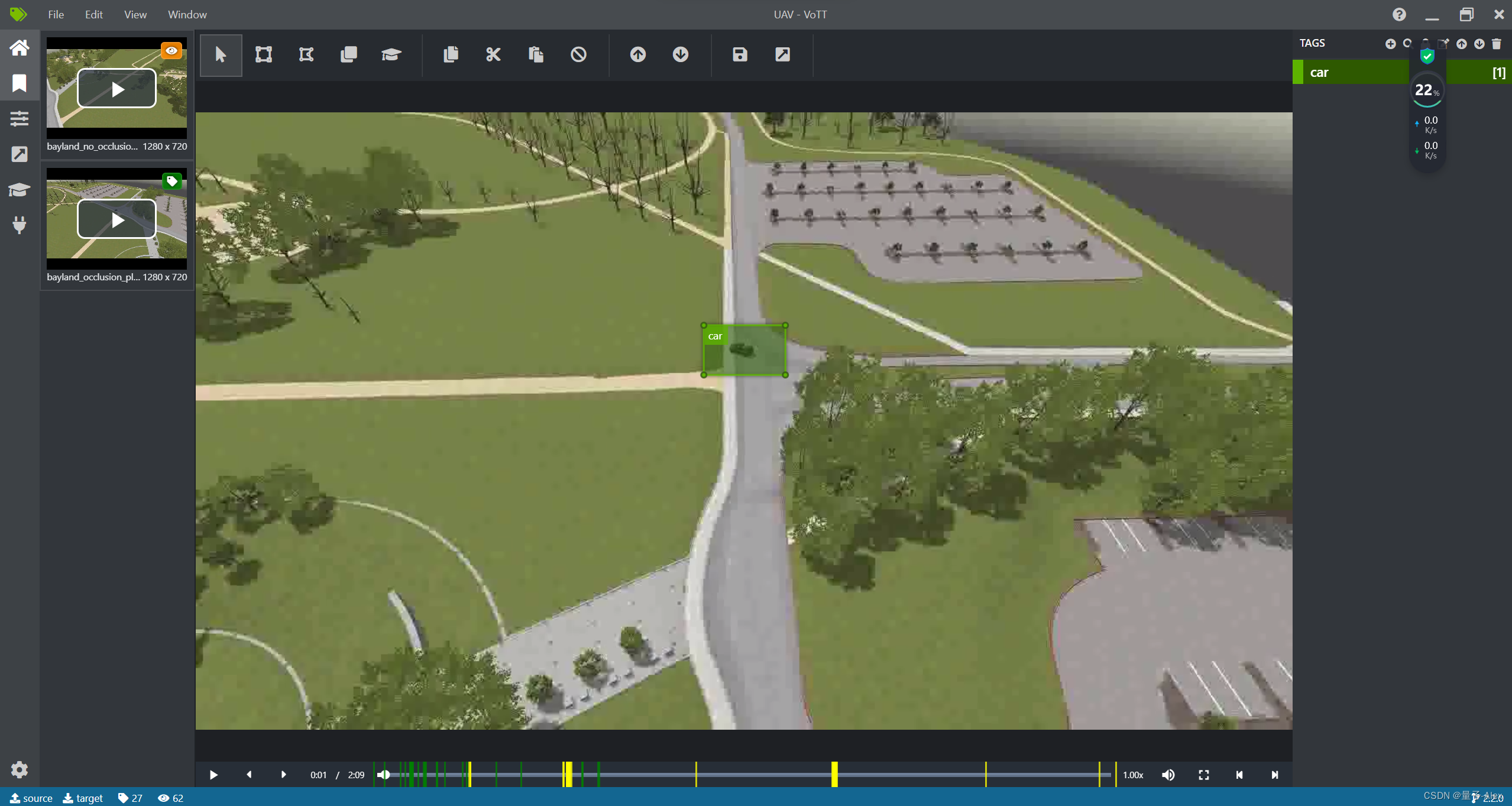
可以看到我们现在左上角有两个视频,有橘黄色标志的表示正在访问和播放的视频,有绿色标签的表示已经标注过的视频,可见我们的第一个视频还没有标注,我们首先在左上角点击,进入对它的标注。
点开是这样的,
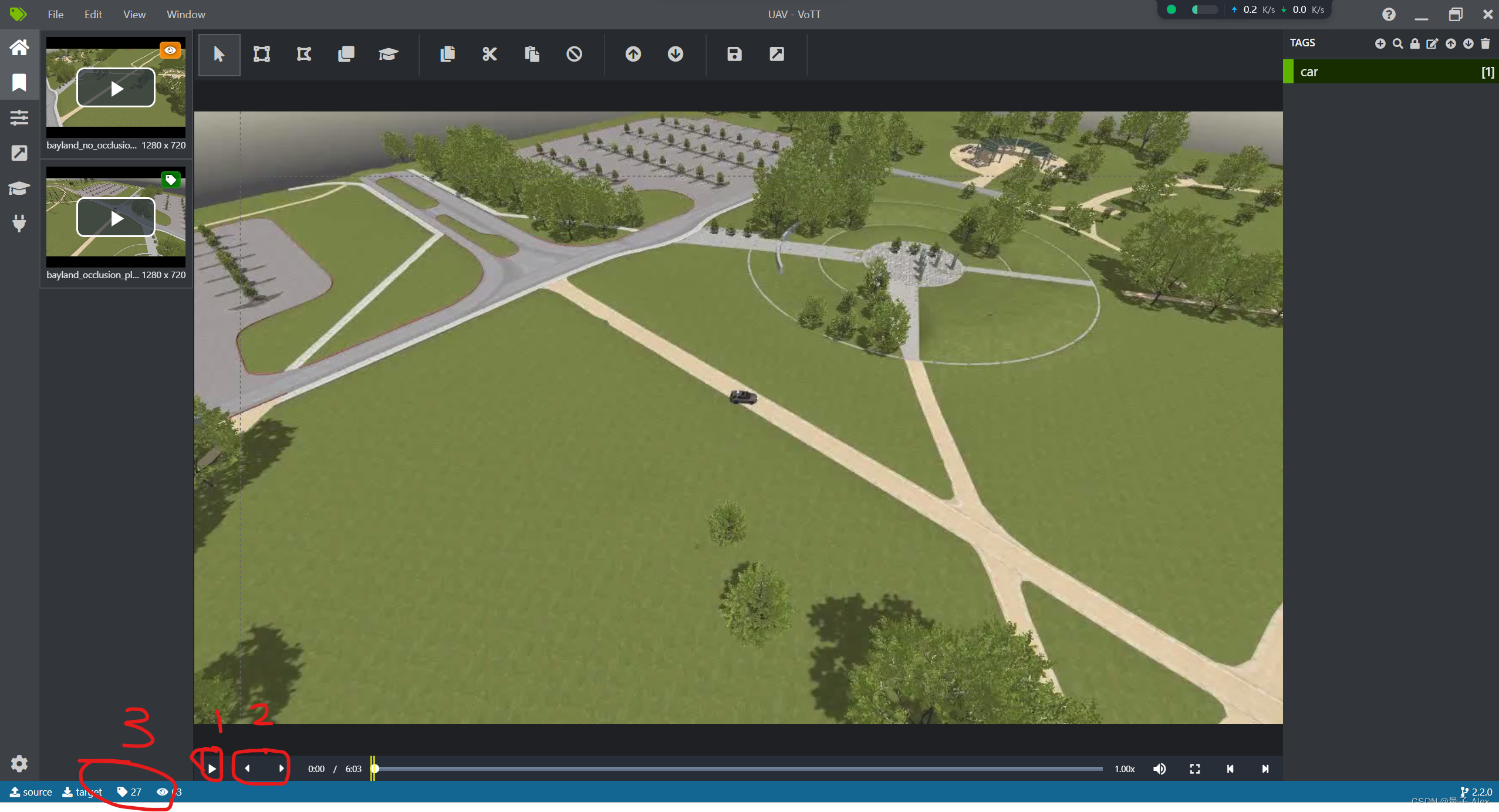
大家可以首先看我勾选的1,点击播放图标,则视频开始播放
2有两个箭头,然后看到后面的进度条有黄色的竖线标志,还记得我们在开始创建项目里面设置的FPS吗,这里就是按我们设置的FPS将视频每一秒钟分隔成多少个帧,总视频有多少秒时长*我们设置的FPS就是我们这个视频要标注的帧数。是一帧一帧的逐个标注的。
然后再看3,左边的Tags标签显示了当前视频我们已经标注了多少帧,右边的像眼睛一样的Visited标签显示我们已经访问(播放到了)多少帧。

点击右上角的这个加号,即可添加标签的名字。
我们添加了car

点击上方的这个矩形框标志,就可以在视频的每一帧中标注了
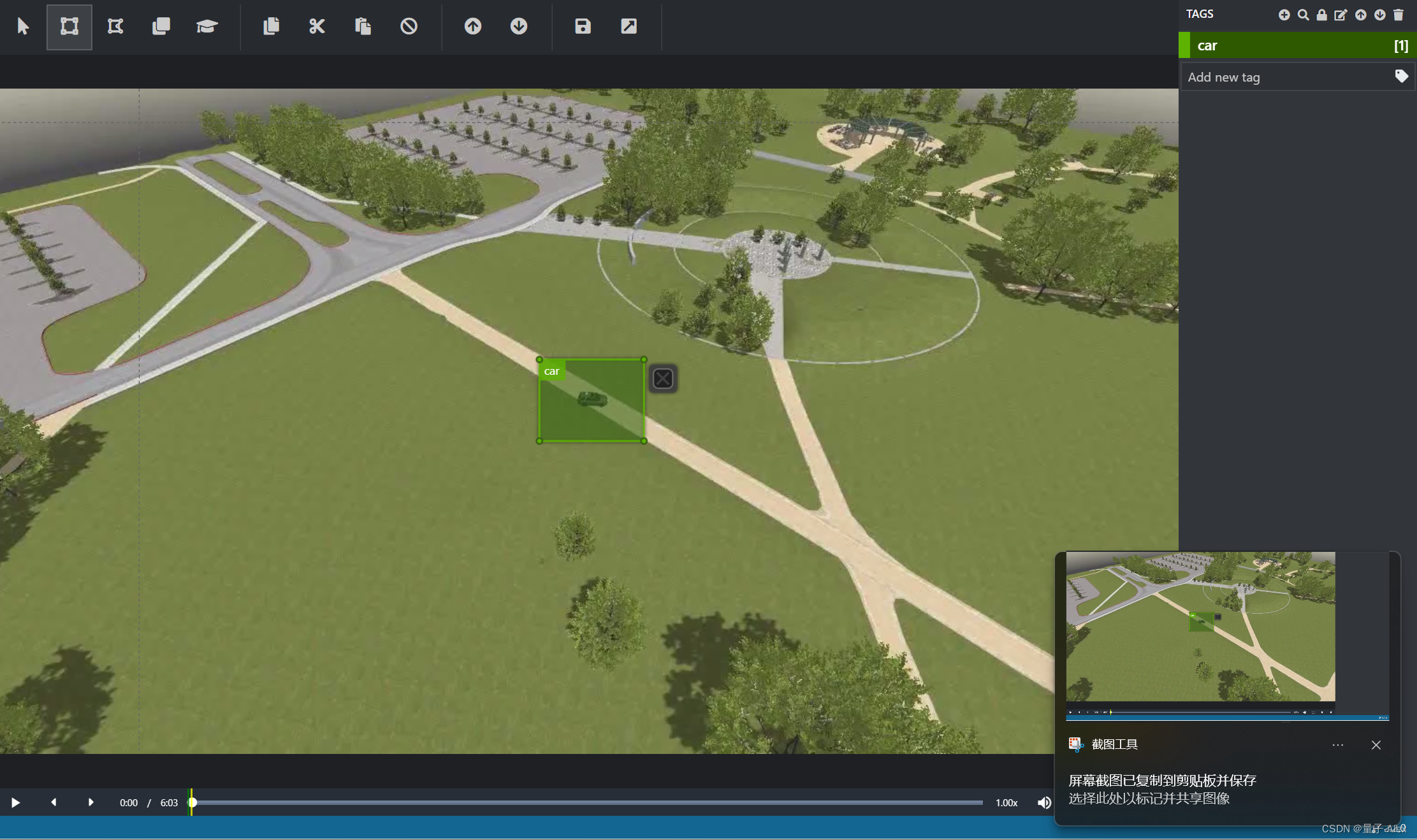
我们在中间选择我们要标注的物体,拖动标注框将其覆盖上,然后到右边点击car,就标注上了,然后我们点击下面的向右的箭头,就可以选择下一帧,快捷键是我们选中目标后,Ctrl+1,比如我们选择的标签car是第1个标签,那么Ctrl+1就表示给我们选中的目标打上了car的标签。键盘的左右方向可以选择上一帧和下一帧。
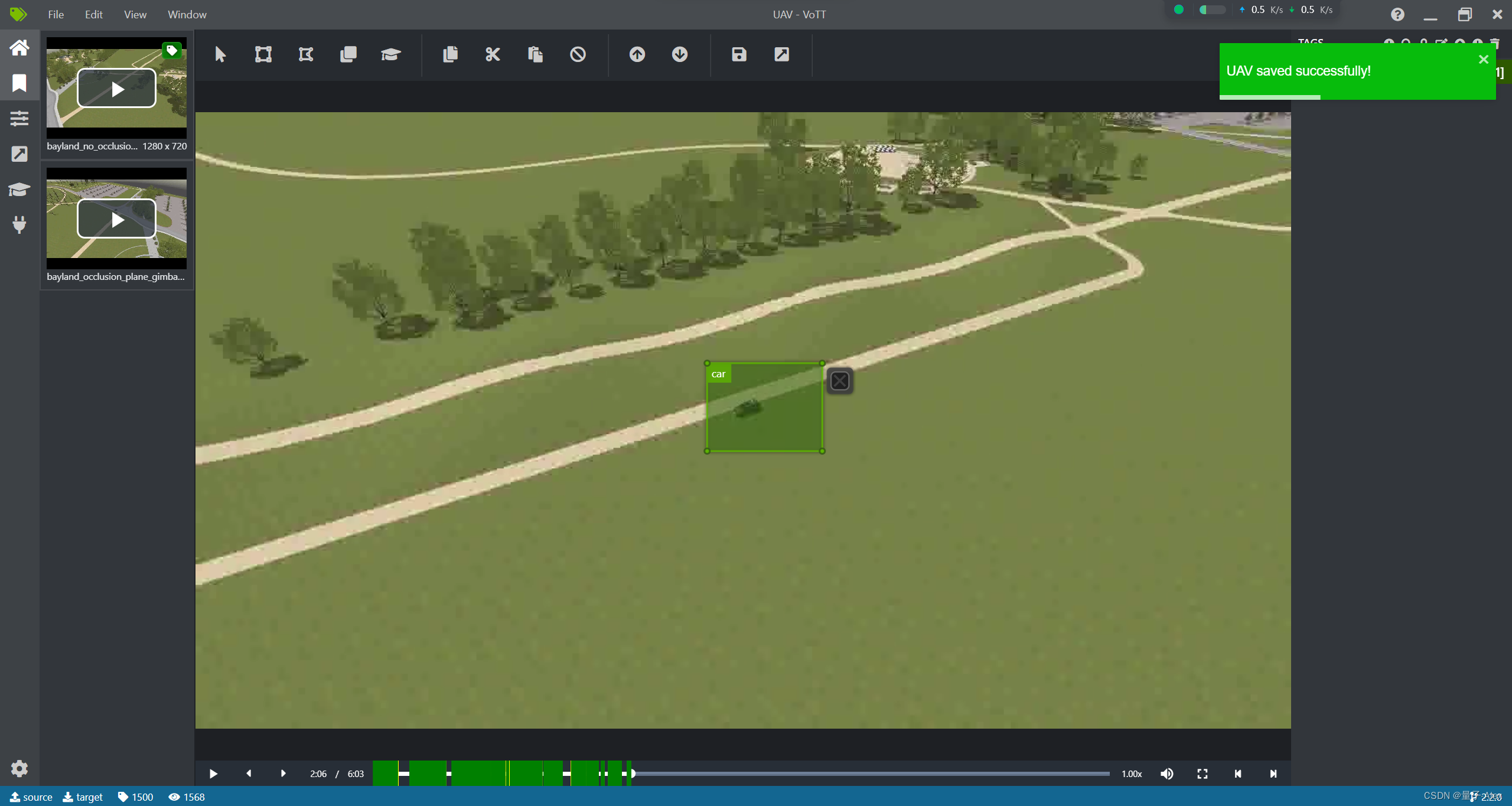
我们已经标注了1500帧
下面就将标注数据导出
导出项目前,首先设置导出选项

首先就是导出的选项是啥。
一般是选择Json,但是这里因为我接下来要用YOLOX 的模型训练,因此我选择导出成为VOC 的格式

然后导出的资源,我们选择我们标注过的 Only tagged assets
下面自动生成了训练数据集和测试数据集的划分比例
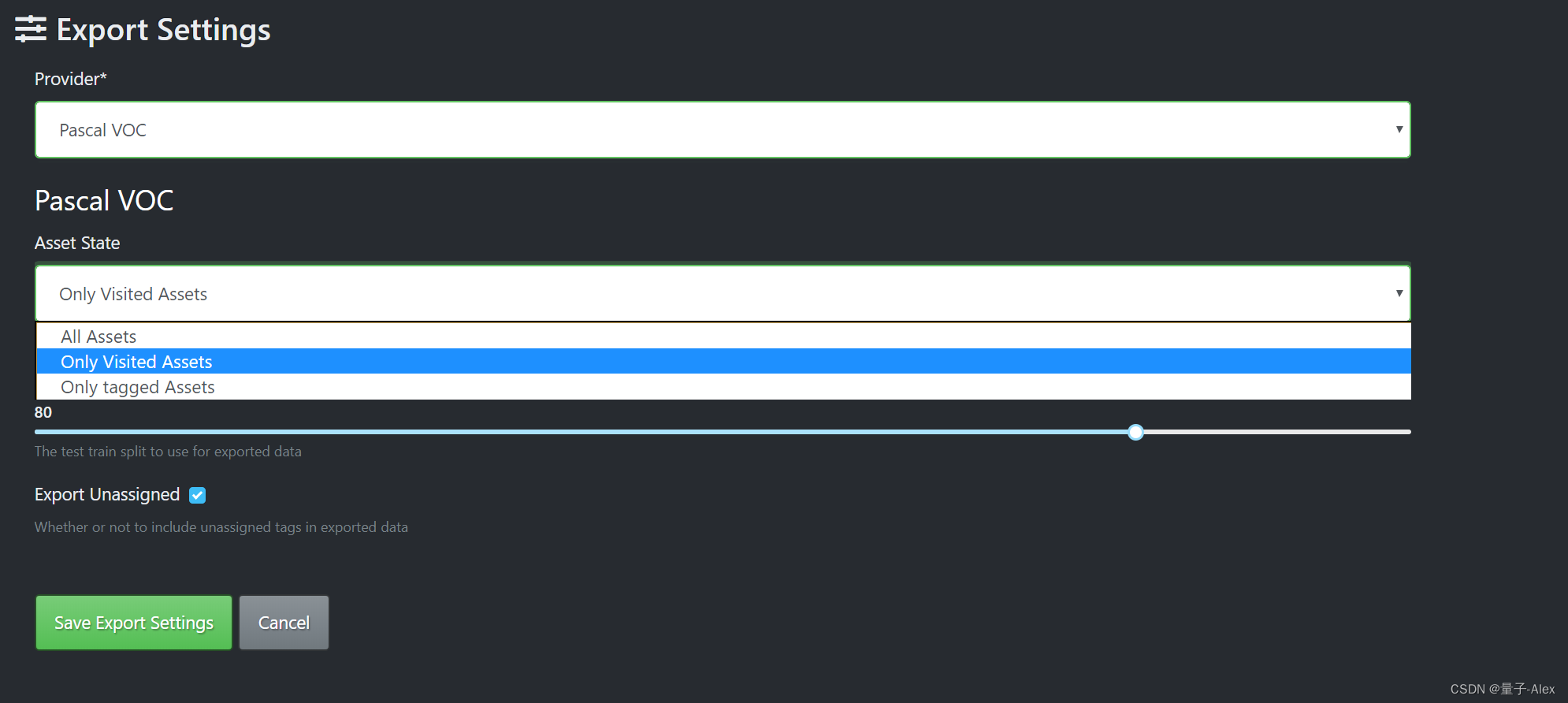
然后我们点击这个导出我们标注的数据集

提示正在导出了,我们去target文件夹去看看

可以看到产生了一个“VoTT项目名称”+PascalVOC-export的文件夹

然后我们进入文件夹看看
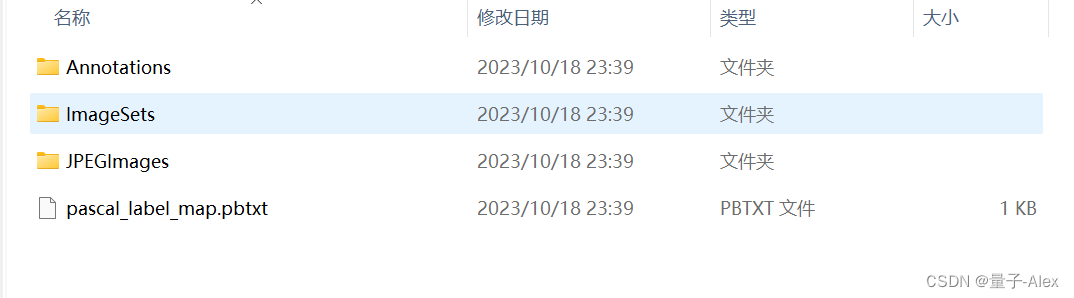
用过Pascal VOC数据集的朋友们一定对这个文件夹目录无比熟悉。
导出过程比较长,咱们可以干别的事等一等。
OK,全部导出完了 咱们挨个文件夹看看
Annotations 与图片对应的xml文件
这个就是用XML文件保存的标注数据
IMageSet文件夹 将数据集分为训练集和验证集,因此产生的train.txt和val.txt

然后是 JPEGImages文件夹 数据集图片

用YOLOX模型训练
下载和配置YOLOX模型
在github上搜索YOLOX,点击下面这个最多star的项目
我们点进去下载项目
然后将项目文件夹放到pycharm的工程路径
新建一个虚拟环境
conda create --prefix=D:\Anaconda3\envs\YOLOX python=3.8
然后激活这个环境
conda activate D:\Anaconda3\envs\YOLOX
在vscode中打开requirement.txt,看看它对于环境的要求
pip install -r requirements.txt -i https://pypi.douban.com/simple
下载完成
然后给项目配置这个环境
python tools/demo.py image -f exps/default/yolox_s.py -c ./weights/yolox_s.pth --path assets/dog.jpg --conf 0.3 --nms 0.65 --tsize 640 --save_result --device gpu
import sys
import os
oscurPath = os.path.abspath(os.path.dirname(__file__))
rootPath = os.path.split(curPath)[0]
sys.path.append(rootPath)
>python demo.py image -f exps/default/yolox_s.py -c ./weights/yolox_s.pth --path assets/dog.jpg --conf 0.3 --nms 0.65 --tsize 640 --save_result --device gpu
报错,
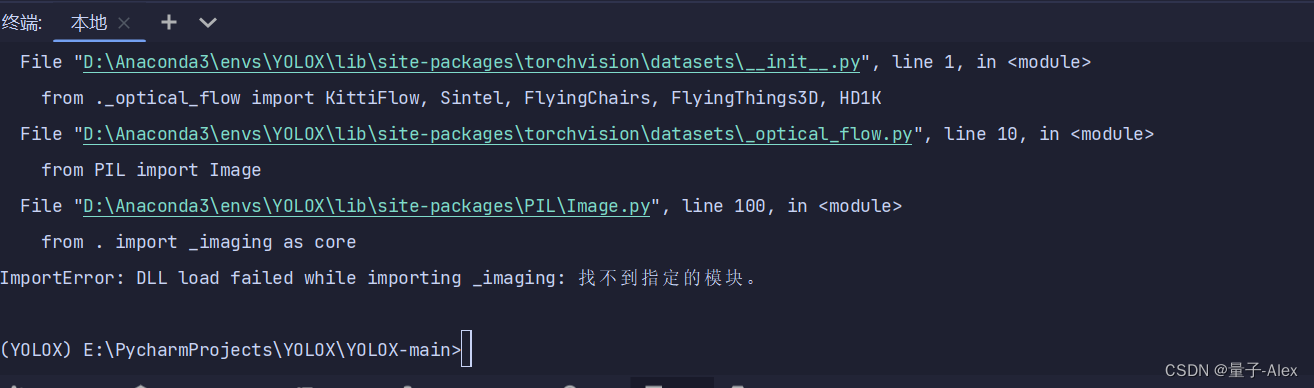
pip show Pillow

突然想到是不是因为没有装matplotlib
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
装了,还是不行
关闭pycharm,重启
重装Pillow
>pip install Pillow==9.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
再输入
python demo.py image -f exps/default/yolox_s.py -c ./weights/yolox_s.pth --path assets/dog.jpg --conf 0.3 --nms 0.65 --tsize 640 --save_result --device gpu
这次可以了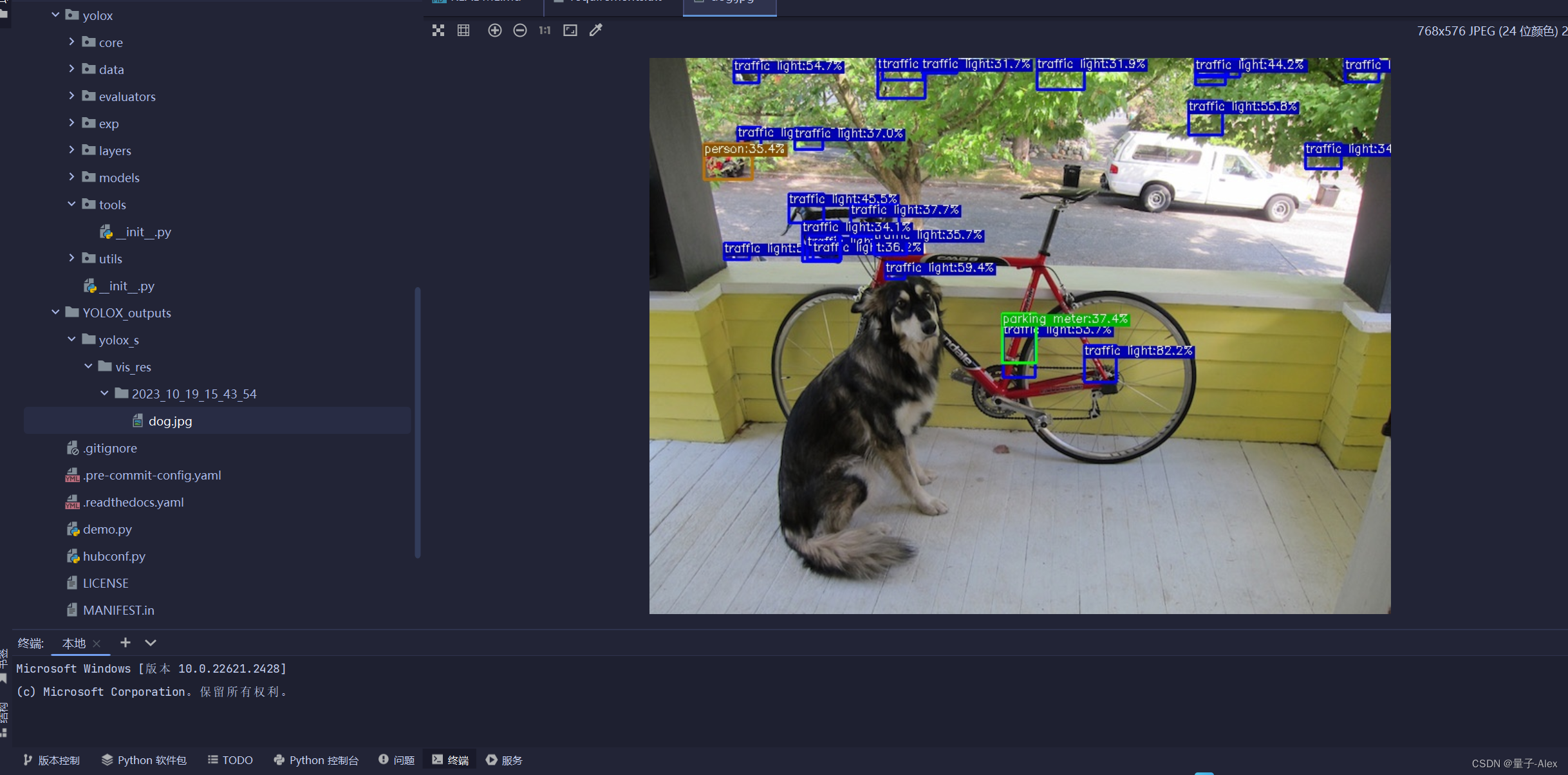
在YOLOX_output下面生成了对实例图像的预测
用自己的数据集进行训练与测试
将VoTT生成的target文件夹里面的文件放yolo项目里面

训练准备:把我们自己的数据集放进去
训练准备:修改训练配置参数
1.修改类的标签与数量
注意路径
我的路径是:YOLOX-main/yolox/data/datasets/voc_classes.py
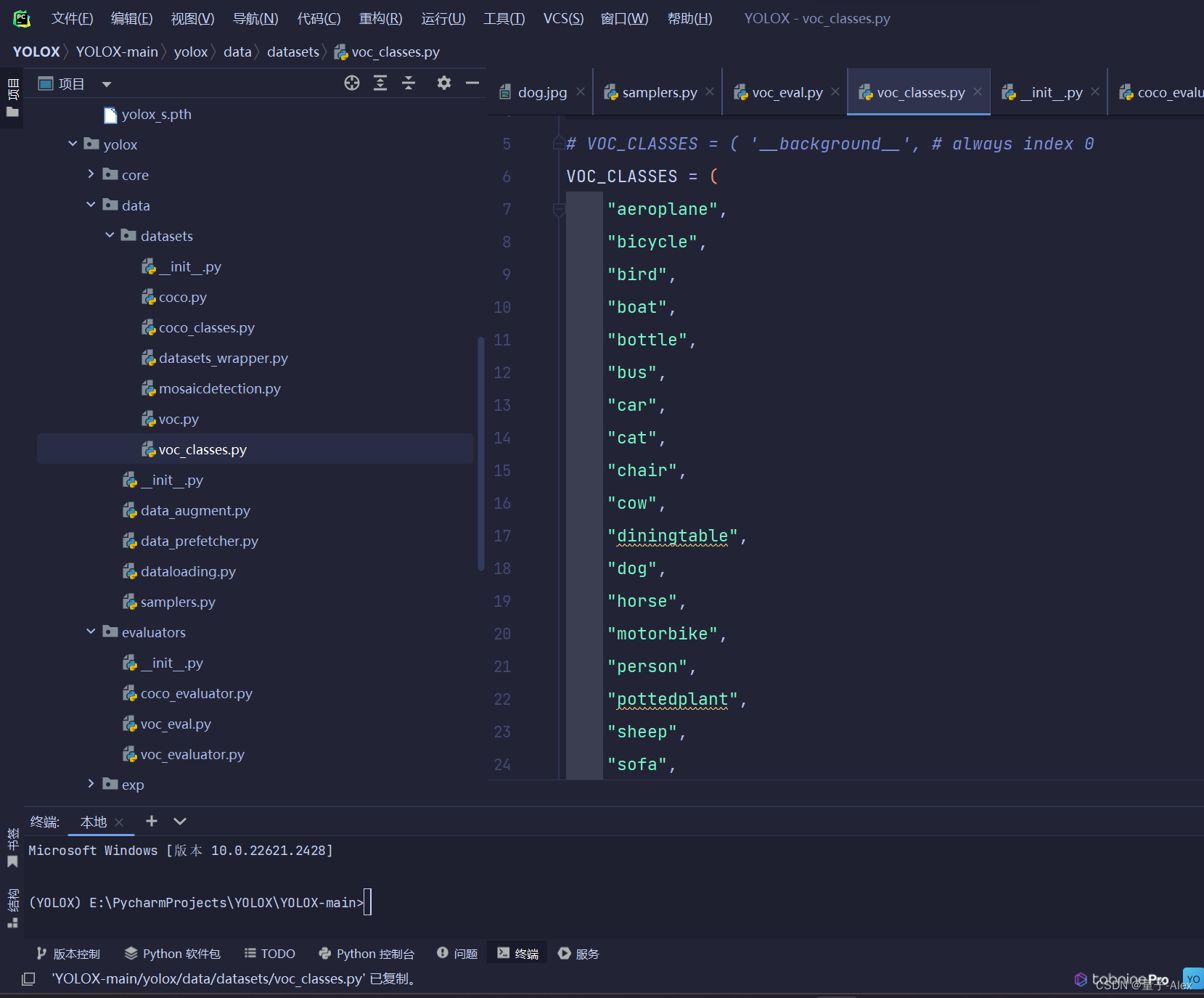
在这里修改类的标签
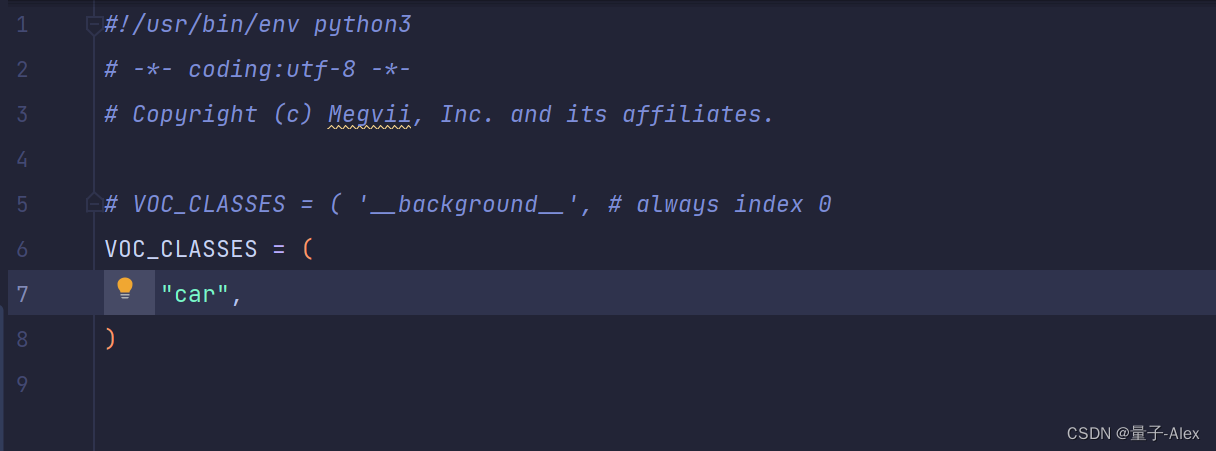
我们只有一个类,car
所以改成如下形式,注意别忘了car后面的逗号
再去这个路径:YOLOX-main/exps/example/yolox_voc/yolox_voc_s.py

改Exp类下面的self.num_classes 改成1
然后再去改 YOLOX-main/yolox/exp/yolox_base.py

还是将self.num_classed=80改成=1
2.修改训练集的信息
YOLOX-main/exps/example/yolox_voc/yolox_voc_s.py中
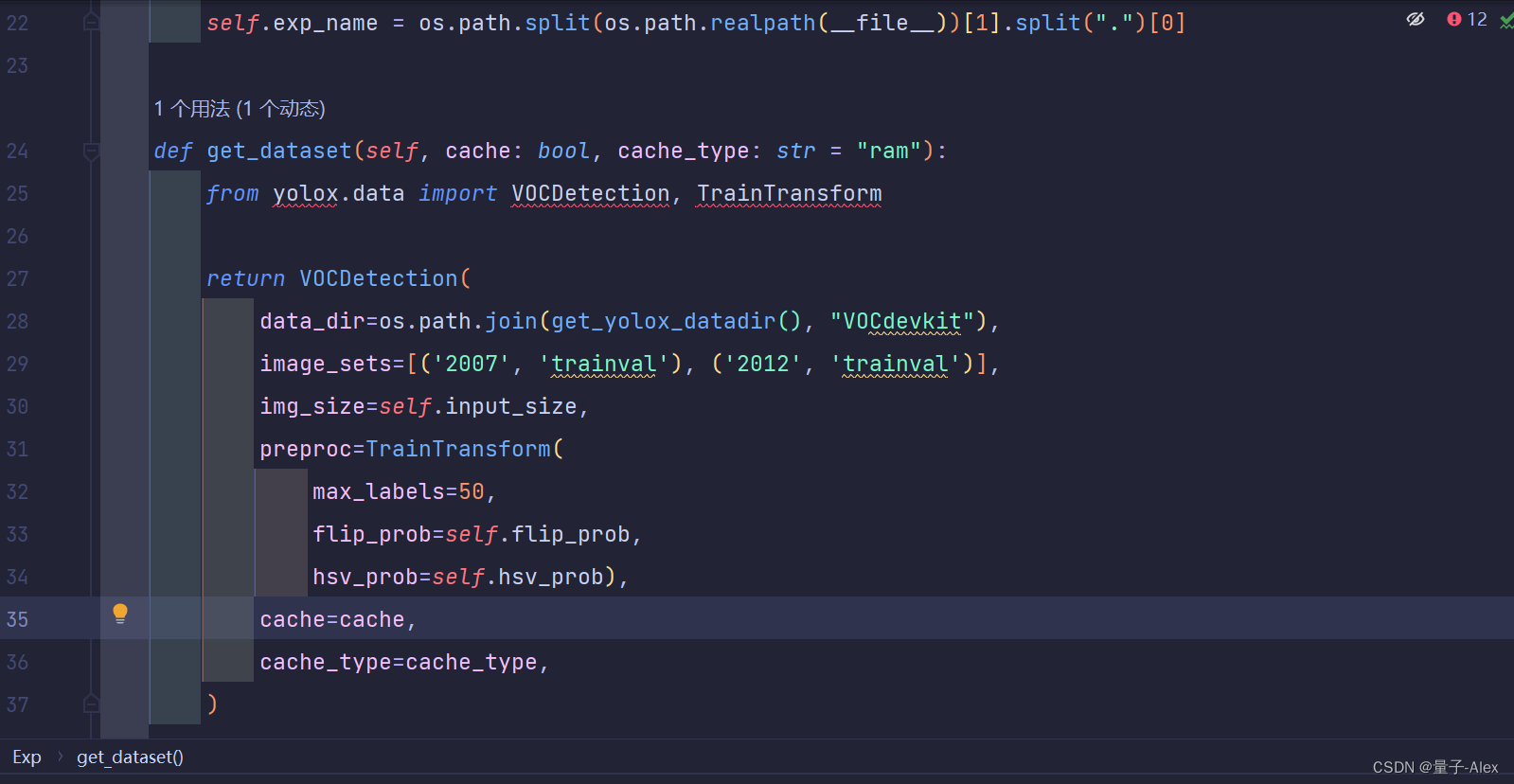
data_dir改成数据集放的路径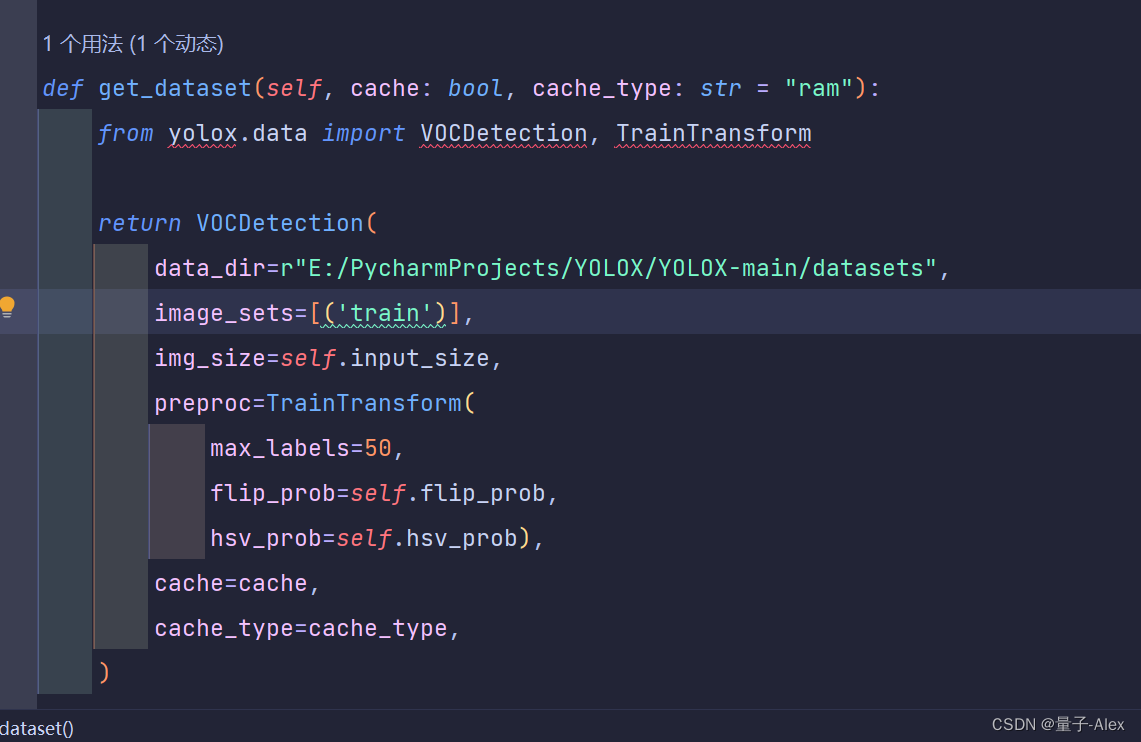
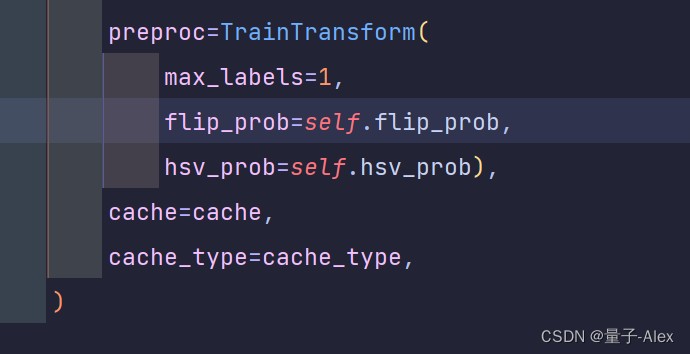
下面的max_labels改成1
另外就是在读取txt的YOLOX-main/yolox/data/datasets/voc.py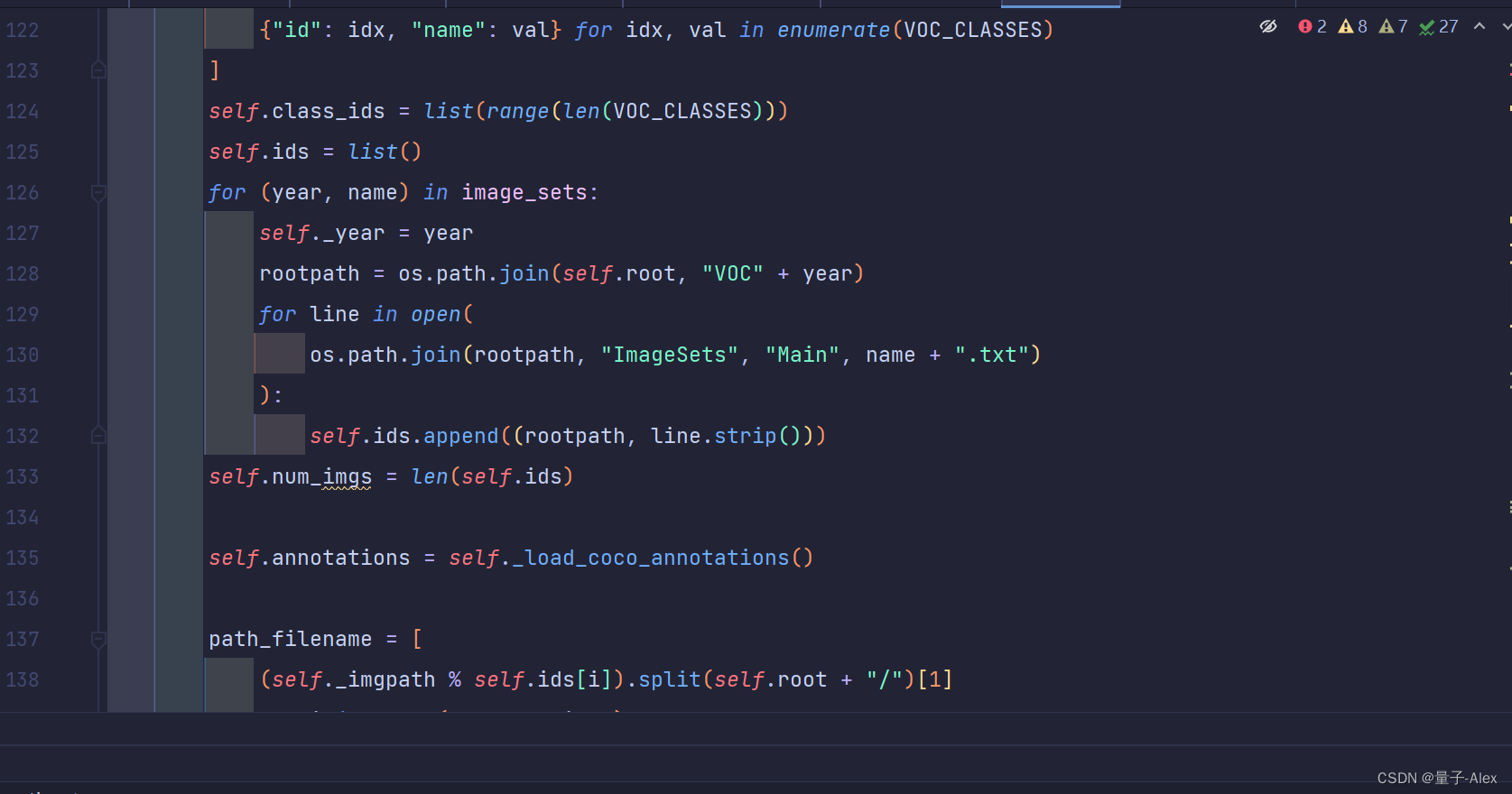
找到127行
改成如下

3.修改验证集的信息
在YOLOX-main/exps/example/yolox_voc/yolox_voc_s.py
第44行开始
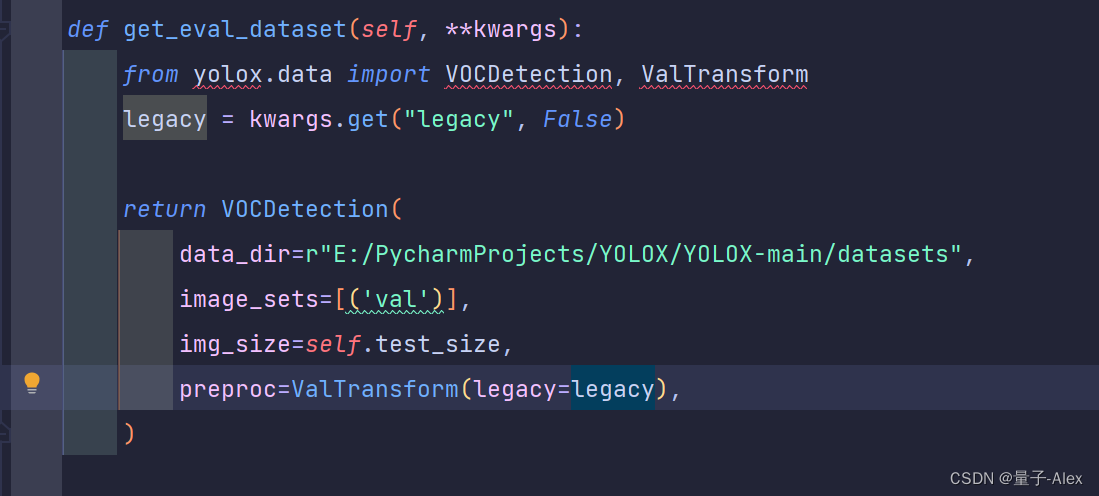
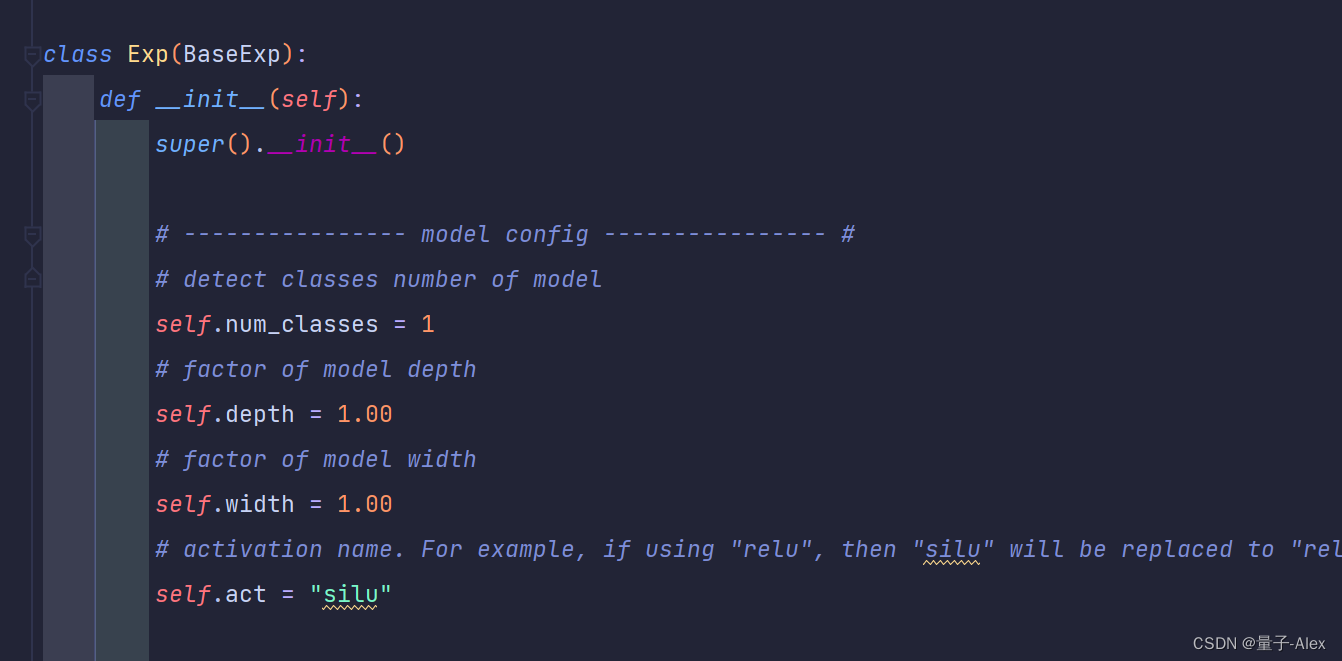
4.修改网络参数
YOLOX-main/yolox/exp/yolox_base.py
第24行

self.depth=0.33
self.width=0.50
5.修改其他参数
YOLOX-main/yolox/data/datasets/voc.py文件
第244行
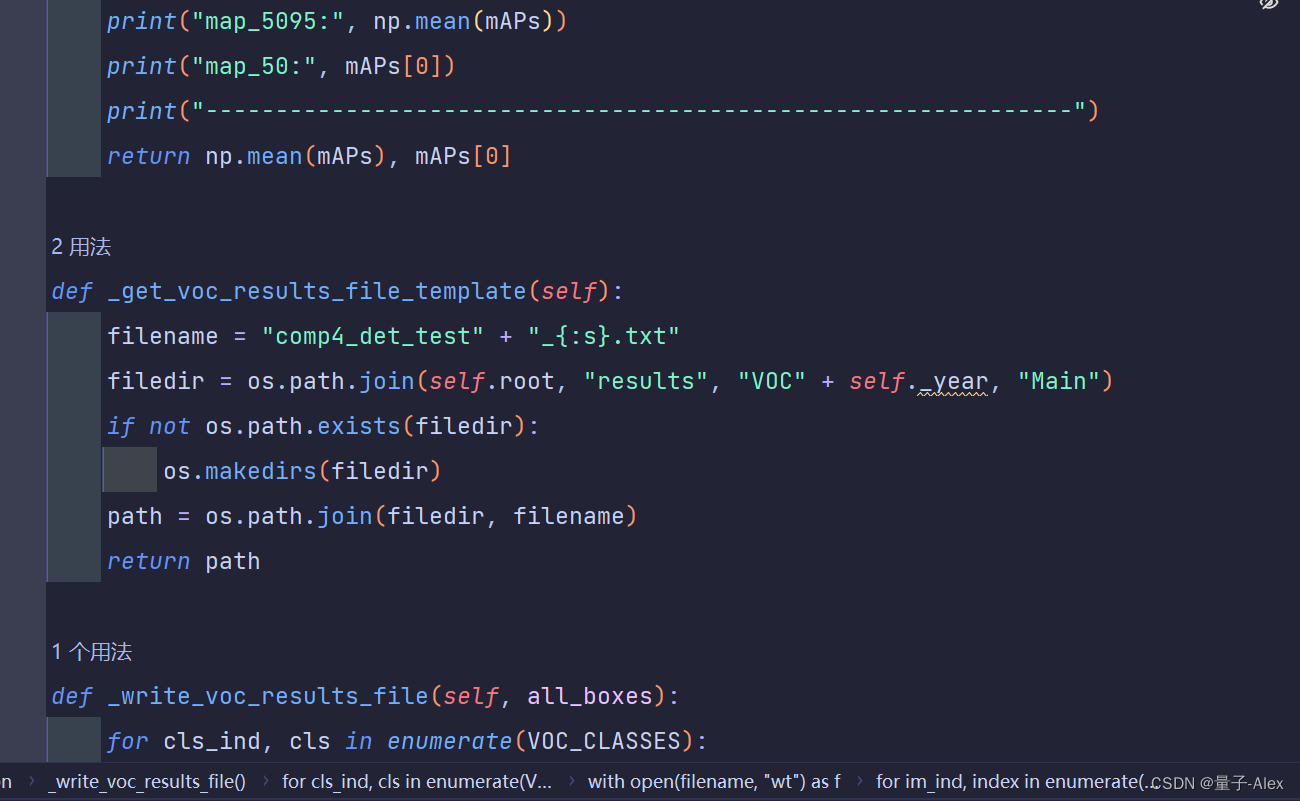
改成下面

到时候结果会输出在datasets文件夹中的results文件夹
YOLOX-main/yolox/exp/yolox_base.py文件
第92行和第95行
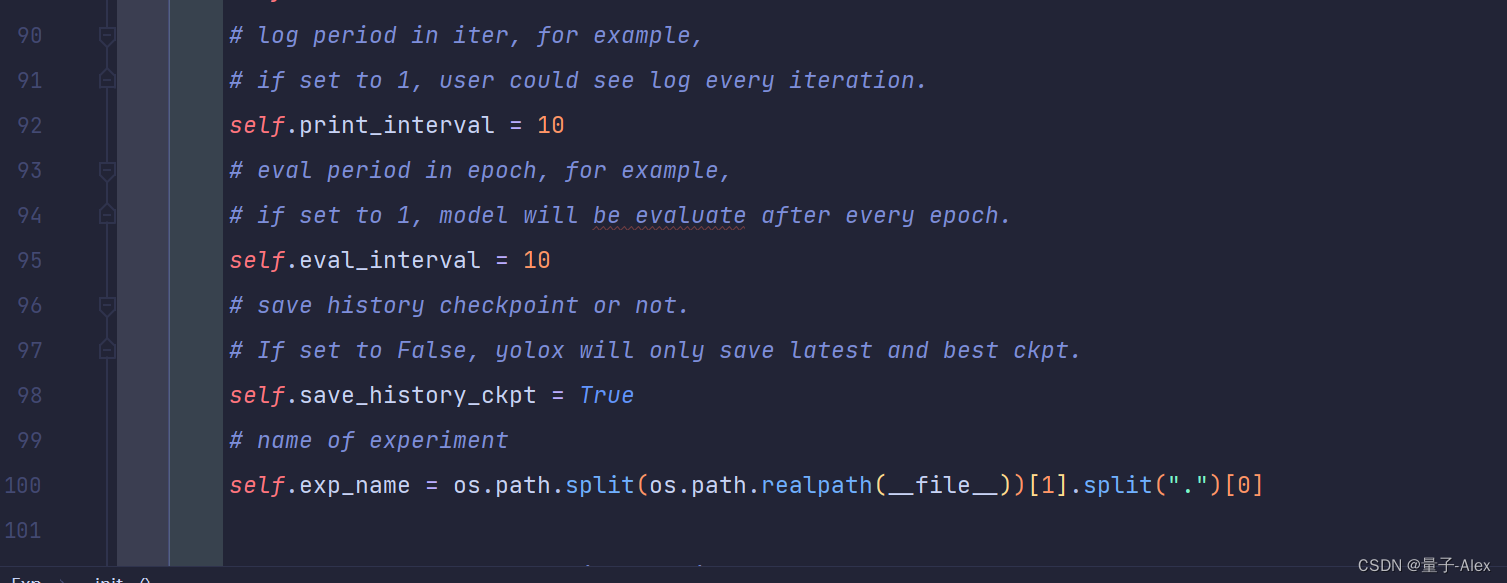
改成下面的
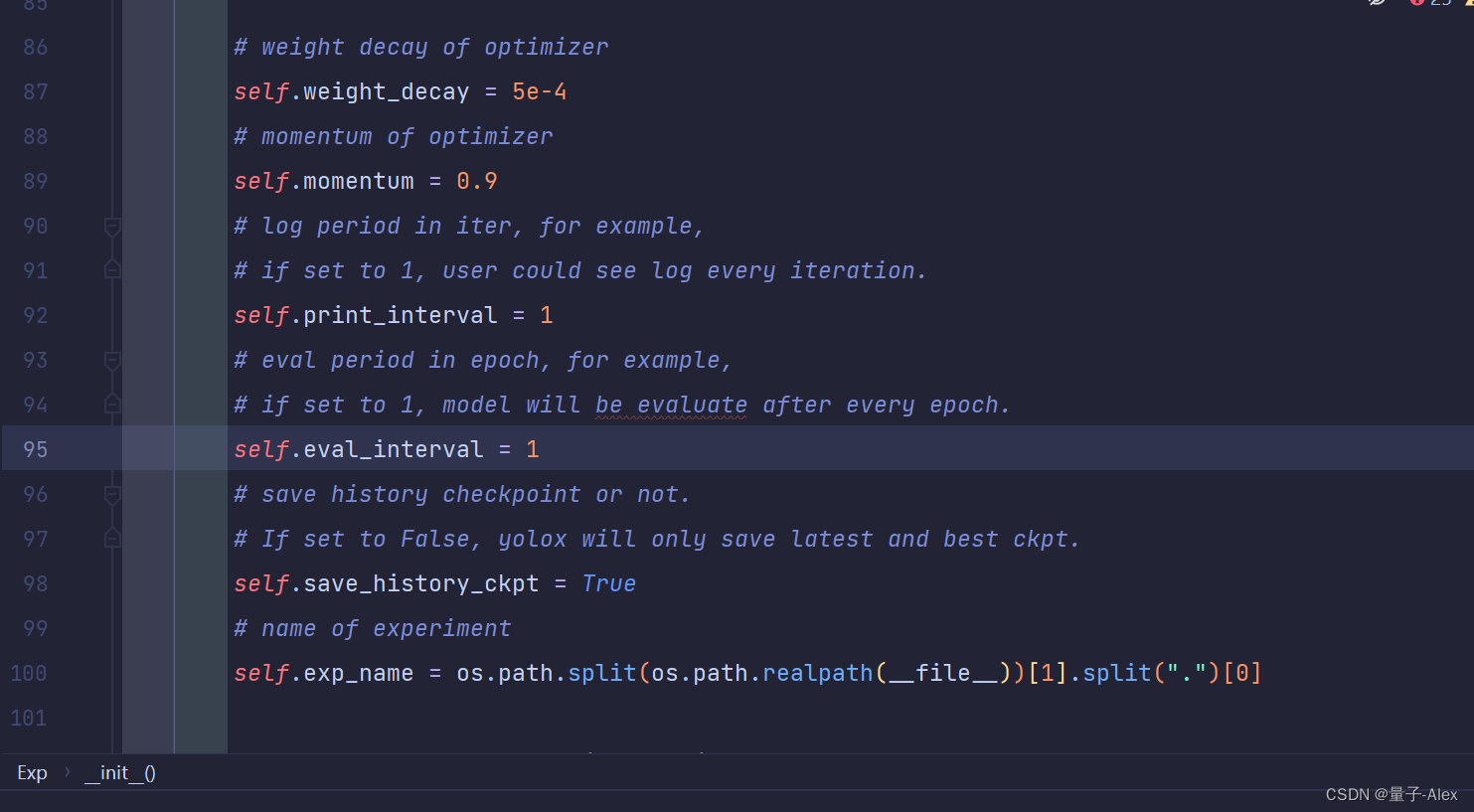
设置为每迭代一个epoch,即使用验证集验证一次
6.修改验证时的相关信息
YOLOX-main/yolox/data/datasets/voc.py中
第278、279 283行
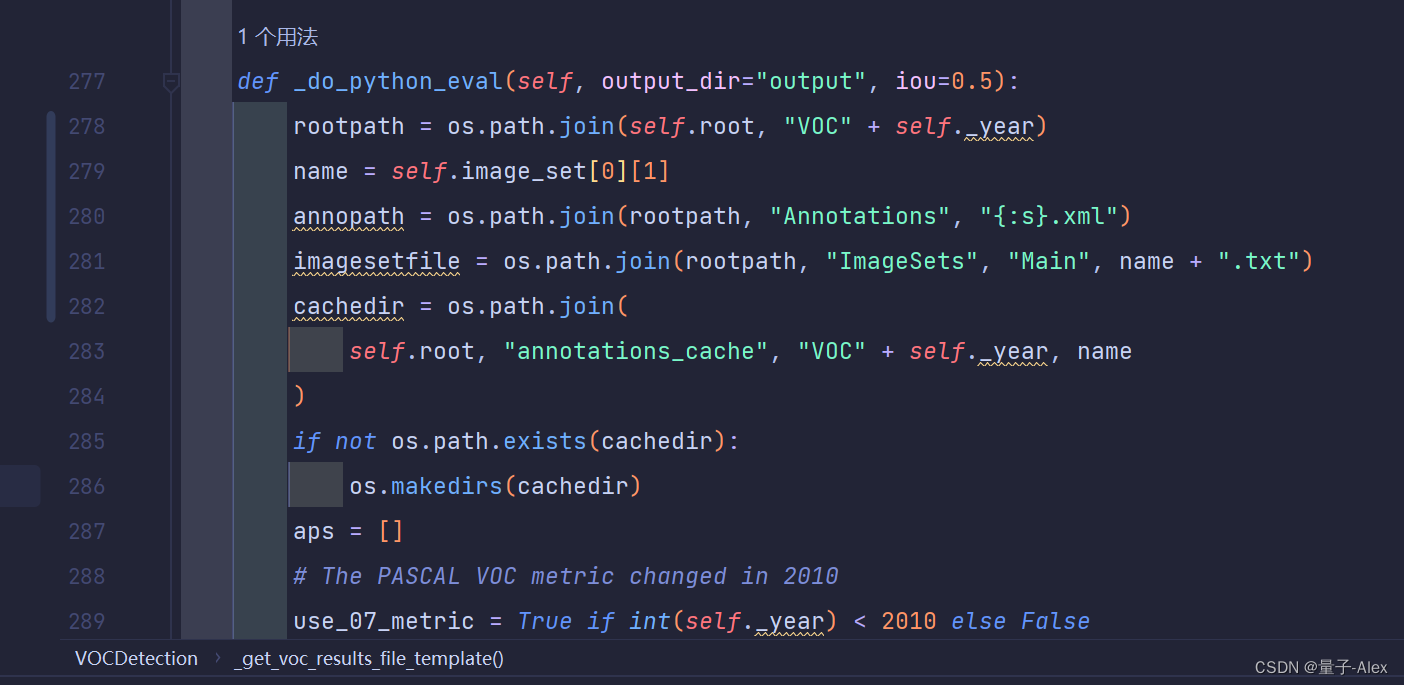
改成下面:
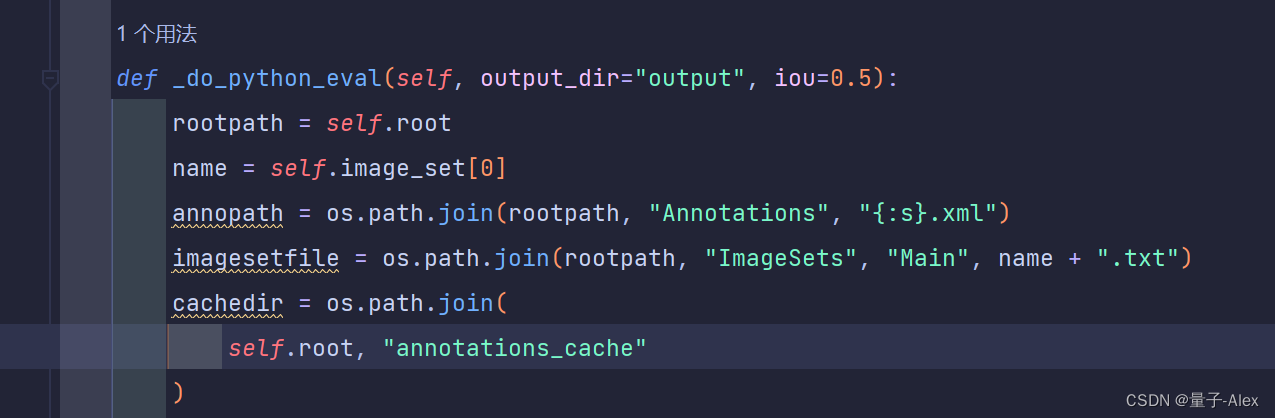
第289行

改成

修改完后执行python setup.py install重载代码。
python setup.py install
开始训练
下面就是关键的一步,在终端中输入命令开始训练
python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 1 -b
8 -c weights/yolox_s.pth
下面一个个说
tools/train.py 是训练的程序
-f exps/example/yolox_voc/yolox_voc_s.py 是voc的模型
-d 1 是device 设备 有几块GPU 我有一块就写1
-b 8 是batchsize
-c weights/yolox_s.pth是预训练模型
报错了
AttributeError: ‘VOCDetection’ object has no attribute ‘cache’

重新配置环境和项目文件
报了两个错
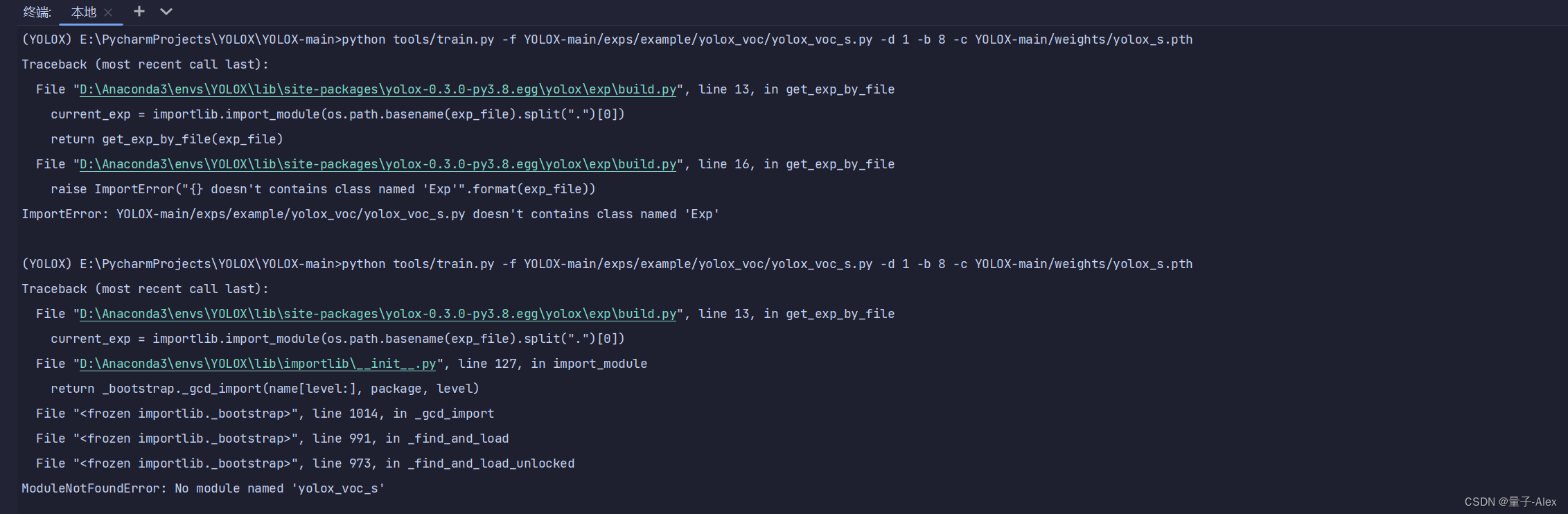

上网搜,参考这个链接
添加链接描述
把命令行改成
python train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 1 -b 8 -c weights/yolox_s.pth
解决问题 ,-f -c我之前是直接复制的路径
又报了两个错

第一个错误
重写数据集的txt文件 我的代码如下,供大家参考
import os
import random
trainval_percent = 0.5
train_percent = 0.9
xmlfilepath = 'VOCdevkit/VOC2007/Annotations'
txtsavepath = 'VOCdevkit/VOC2007/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('VOCdevkit/VOC2007/ImageSets/Main/trainval.txt', 'w')
ftest = open('VOCdevkit/VOC2007/ImageSets/Main/test.txt', 'w')
ftrain = open('VOCdevkit/VOC2007/ImageSets/Main/train.txt', 'w')
fval = open('VOCdevkit/VOC2007/ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
第二个错误 !!!很多人都遇到过,去这个dataset_wrapper里面把定位到的那三行函数给 注释掉就行了
后面又报 eps的错误
在YOLOX-main/yolox/data/datasets/voc.py
第138行
# path_filename = [(self._imgpath % self.ids[i]).split(self.root + "/")[1] for i in range(self.num_imgs)]
注释掉
改成
path_filename = []
for i in range(self.num_imgs):
path_filename.append((self._imgpath % self.ids[i]).split(self.root + "/")[0])
然后再运行train.py
就ok了
我们可以看最后这个代码是什么问题
(self._imgpath % self.ids[i])
这是一个Python代码片段,用于拼接字符串和对象属性值。
代码中使用了字符串格式化(也称为字符串插值)的语法,将一个字符串中的占位符替换为对象属性值。在Python中,字符串格式化使用百分号(%)作为占位符,后面跟着一个冒号(:)来指定要替换的属性名称。
在这个例子中,self._imgpath是一个字符串,它包含了需要用对象属性值替换的占位符。self.ids[i]是一个整数或字符串类型的对象属性值,它将被插入到self._imgpath字符串的相应位置。
因此,整个代码片段的意思是,将self._imgpath字符串中的占位符(例如%s)用self.ids[i]替换,然后得到一个新的字符串。
举个例子,假设有一个名为MyClass的类,其中有一个名为ids的列表和一个名为_imgpath的字符串属性。如果MyClass的实例名为my_instance,并且my_instance.ids[0]等于’image1.jpg’,那么执行(self._imgpath % self.ids[i])会返回’image1.jpg’。
然后训练到第十轮开始验证的时候又报错如下
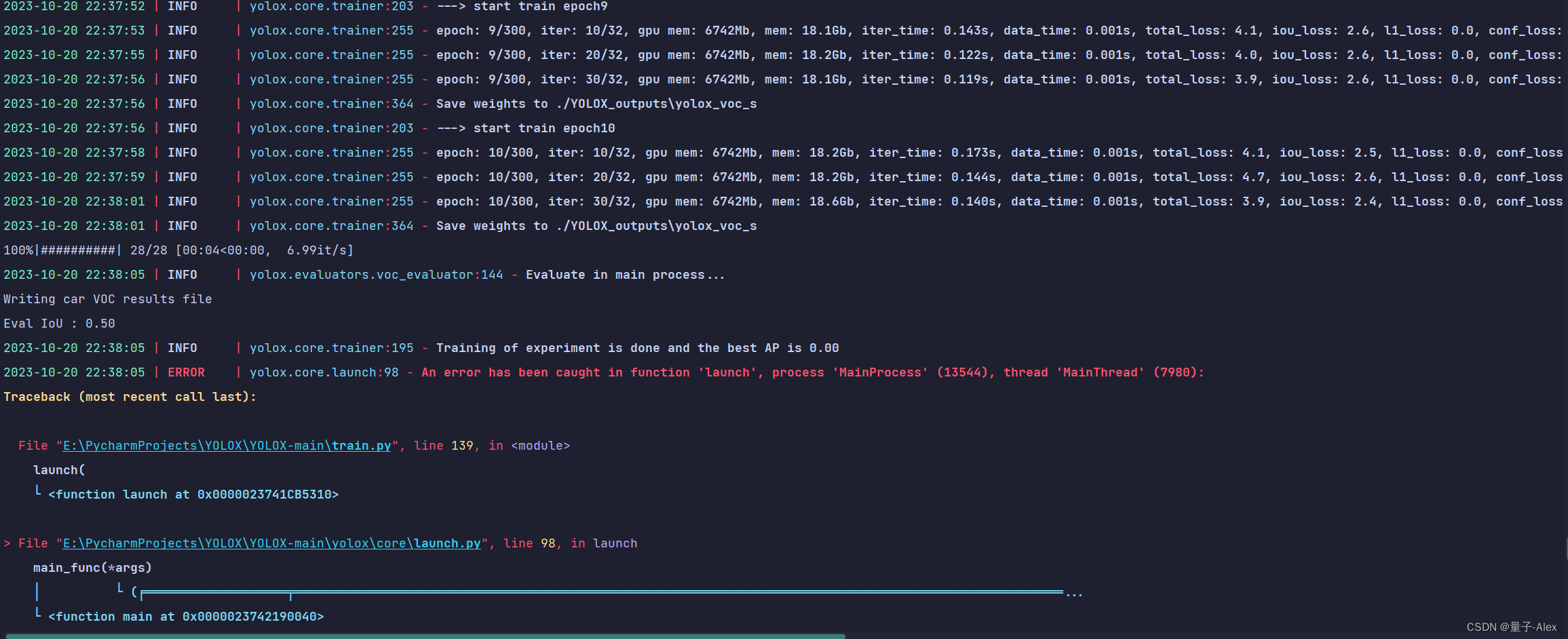
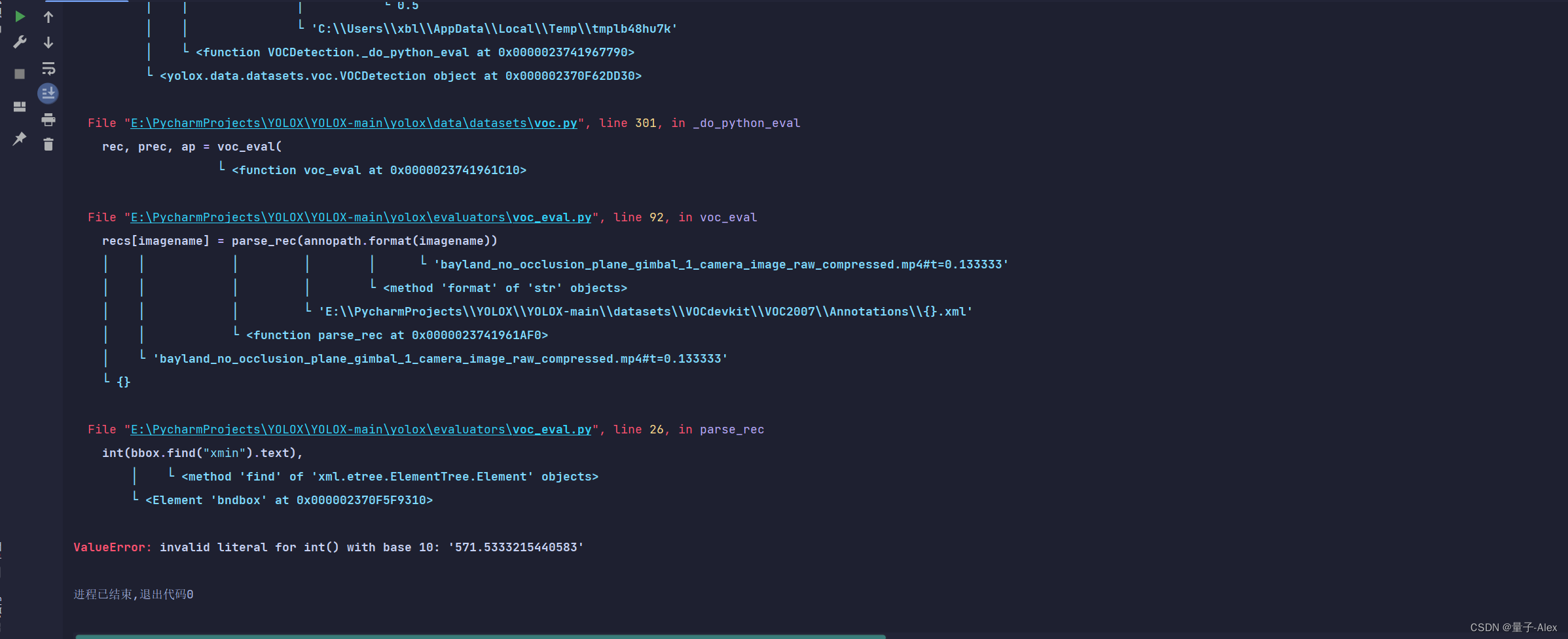
一个是AP=0 另一个是ValueError: invalid literal for int() with base 10: ‘571.5333215440583’
在网上查了下 发现不少人都遇到这个问题,比如这篇博客
ValueError: invalid literal for int() with base 10:解决方法
原因:由于python不能直接将包含小数点的字符串转化为整数,而原始数据的格式经常是不一致的,故类型转化时造成ValueError异常。
解决方法:先将字符串转换为浮点数float,在将浮点数转化为整数int
我们定位到程序YOLOX-main/yolox/evaluators/voc_eval.py
obj_struct["bbox"] = [
int(bbox.find("xmin").text),
int(bbox.find("ymin").text),
int(bbox.find("xmax").text),
int(bbox.find("ymax").text),
]
这明显是标注框bounding box的四个参数
我们改成
obj_struct["bbox"] = [
int(float(bbox.find("xmin").text)),
int(float(bbox.find("ymin").text)),
int(float(bbox.find("xmax").text)),
int(float(bbox.find("ymax").text)),
]
至于AP=0的问题,很多人也遇到了,这篇文章非常全面,值得参考
https://blog.csdn.net/weixin_42166222/article/details/119637797
明显问题是出现在我们的数据集上
我们逐个检查
1.dataset文件夹下面的VOC2007是否是按照VOC的格式部署的,ImageSet文件的Main文件下面是否有train.txt和test.txt文件,我们有的
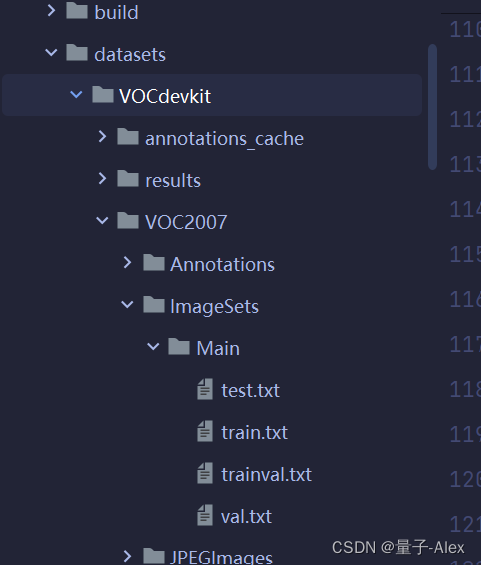
2.yolox/data/datasets/voc_classes.py文件下是我们自己定的类的名字,我们也有,car

3.yolox/exp/yolox_base.py self.num_classes=1,这里也是对的
4.对yolox/data/datasets/voc.py 下的 _do_python_eval 方法进行修改
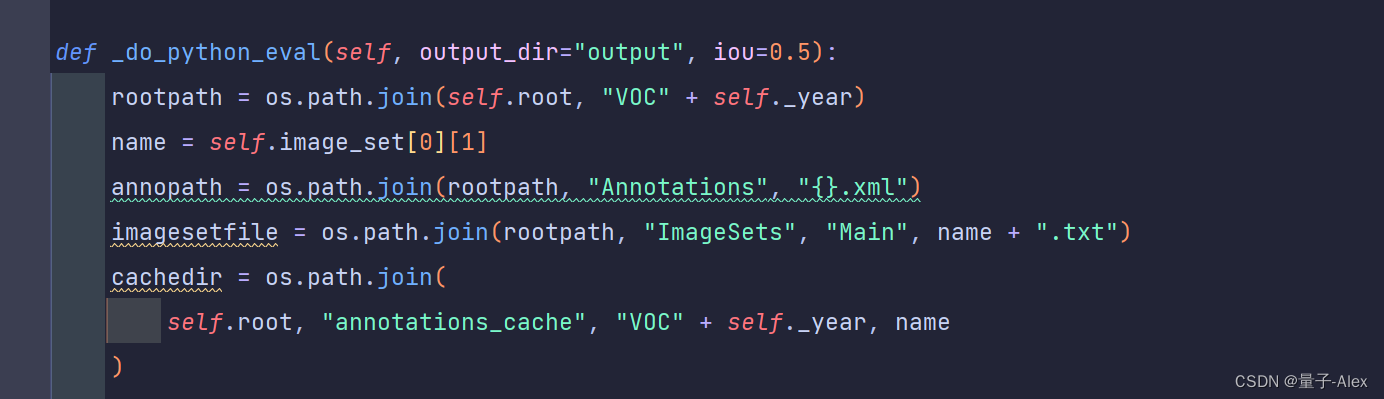
这里我也是对的
5.exps/example/yolox_voc/yolox_voc_s.py
首先是 self.num_classes=1,

然后get_data_loder 下的 VOCDetection 下的 image_sets
image_sets=[(‘2007’, ‘trainval’)],

最后发现问题在这里!!!
get_eval_loader 下的 VOCDetection 下的 image_sets
不能是test!!!!可以看到我的是错的

应该改为

一定要修改为 image_sets=[(‘2007’, ‘val’)],因为我们验证的数据在val.txt,而不是test.txt,这应该也是为什么 AP 一直为0的原因
然后我们再试,果然就成功了
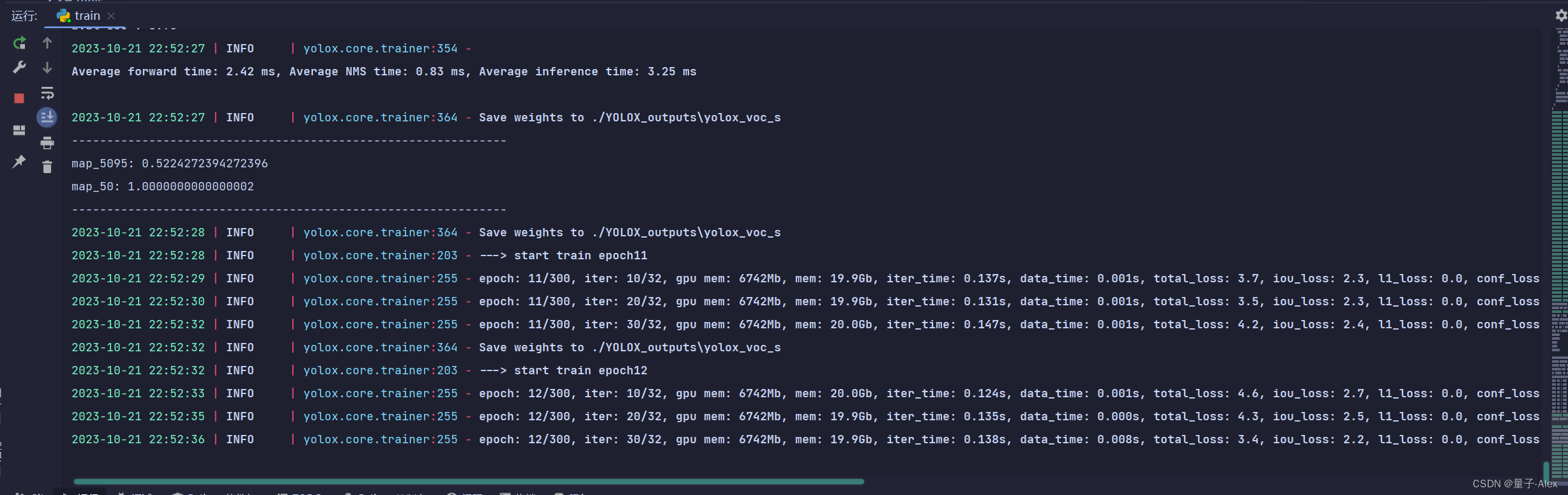
在pycharm终端输入
tensorboard --logdir=YOLOX-main/YOLOX_outputs/yolox_voc_s/train_log.txt
可视化过程

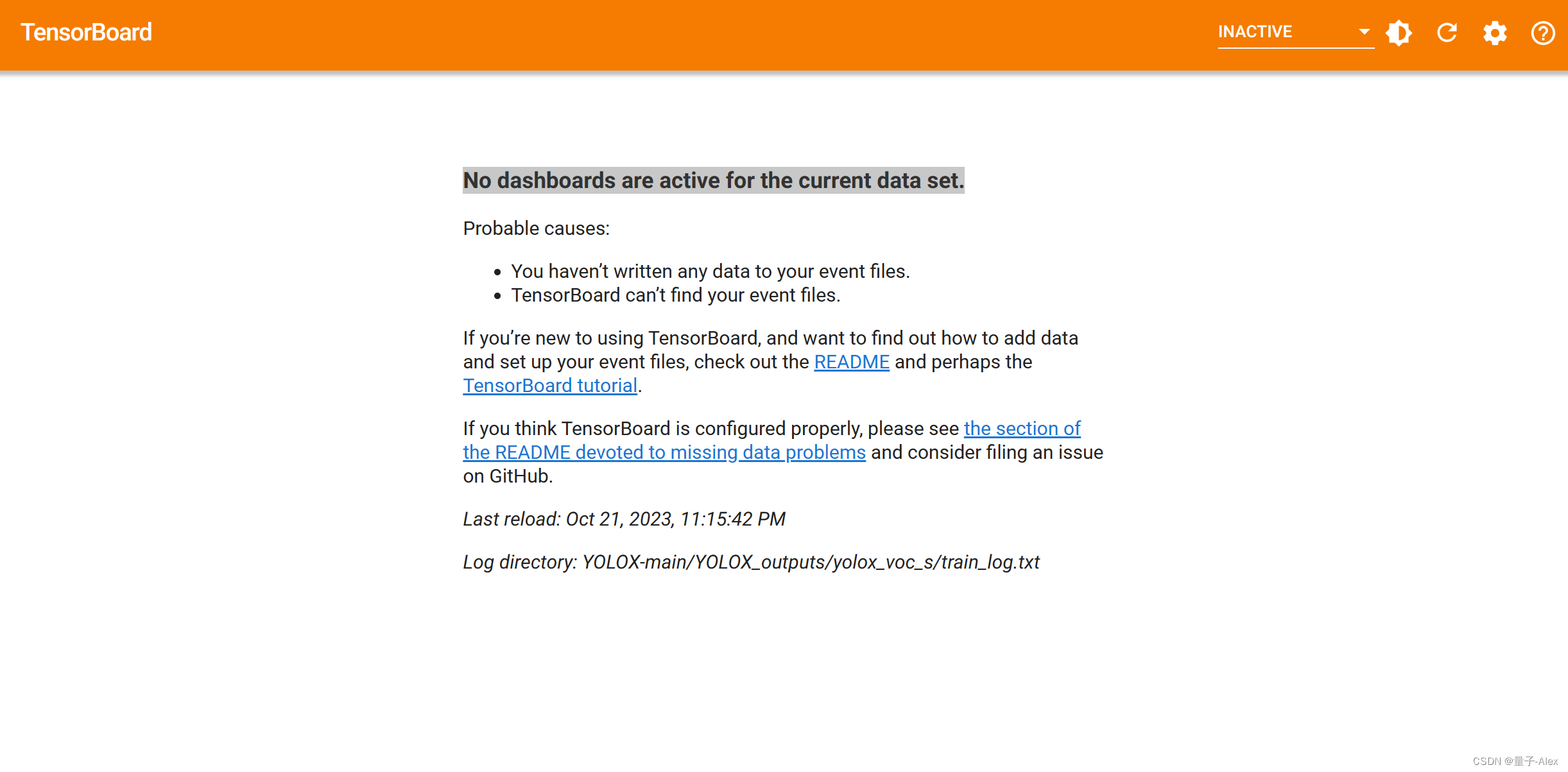
报错
首先试着改一下绝对路径
>tensorboard --logdir=E:\PycharmProjects\YOLOX\YOLOX-main\YOLOX_outputs\yolox_voc_s\train_log.txt
还是不行

改成
tensorboard --logdir=E:\PycharmProjects\YOLOX\YOLOX-main\YOLOX_outputs\yolox_voc_s\
OK了

然后就等它训练完就行了
可以看到在YOLOX_outputs路径下有
进行测试
首先找到YOLOX-main/tools/demo.py
第15行
from yolox.data.datasets import COCO_CLASSES

改成:
from yolox.data.datasets import voc_classes
第105行
class Predictor(object):
def __init__(
self,
model,
exp,
cls_names=COCO_CLASSES,
trt_file=None,
decoder=None,
device="cpu",
fp16=False,
legacy=False,
):
改成:
cls_names=voc_classes.VOC_CLASSES,
还有第306行
predictor = Predictor(
model, exp, COCO_CLASSES, trt_file, decoder,
args.device, args.fp16, args.legacy,
)
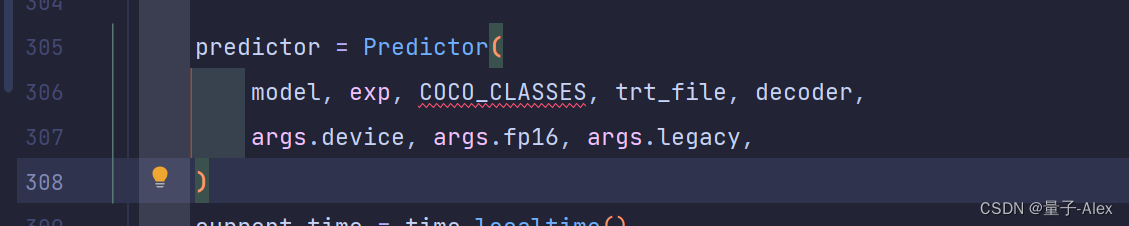
把COCO_CLASSES改成
voc_classes.VOC_CLASSES
改完以后如下:
predictor = Predictor(
model, exp, voc_classes.VOC_CLASSES, trt_file, decoder,
args.device, args.fp16, args.legacy,
)
然后我们去YOLOX_outputs路径下找到:
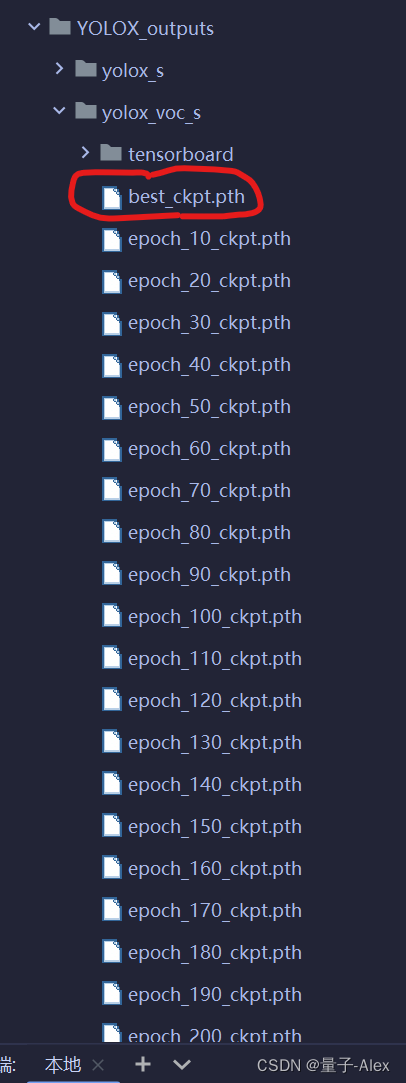
然后把它复制到weights文件夹下面
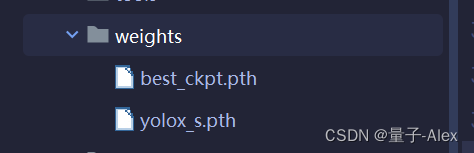
然后把demo.py文件复制到YOLOX项目的根目录,这样可以避免一些路径报错
再检查一下:
YOLOX-main/exps/example/yolox_voc/yolox_voc_s.py
第28行是否有VOCDetection

第43行

第54行

都没问题
然后检查
YOLOX-main/yolox/data/datasets/init.py
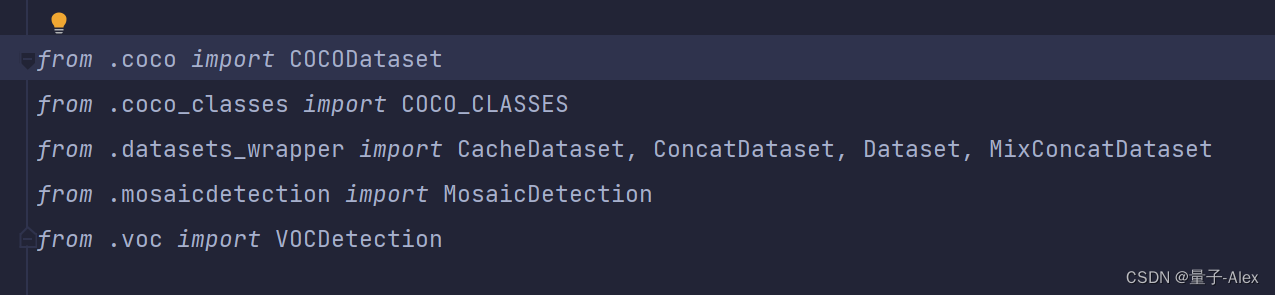
有
from .voc import VOCDetection
没问题
然后YOLOX-main/yolox/evaluators/init.py

有
from .voc_evaluator import VOCEvaluator
没问题
加入
from .voc_class import VOC_CLASSES
最后!!!准备开始测试了。三种方法
1.通过命令行
之前说了把demo.py放在项目根目录了
demo.py video -f exps/example/yolox_voc/yolox_voc_s.py -c weights/best_ckpt.pth --path assets/bayland_occlusion_plane_gimbal_1_camera_image_raw_compressed_Cut01.mp4 --conf 0.3 --nms 0.65 --tsize 640 --save_result --device gpu
报错
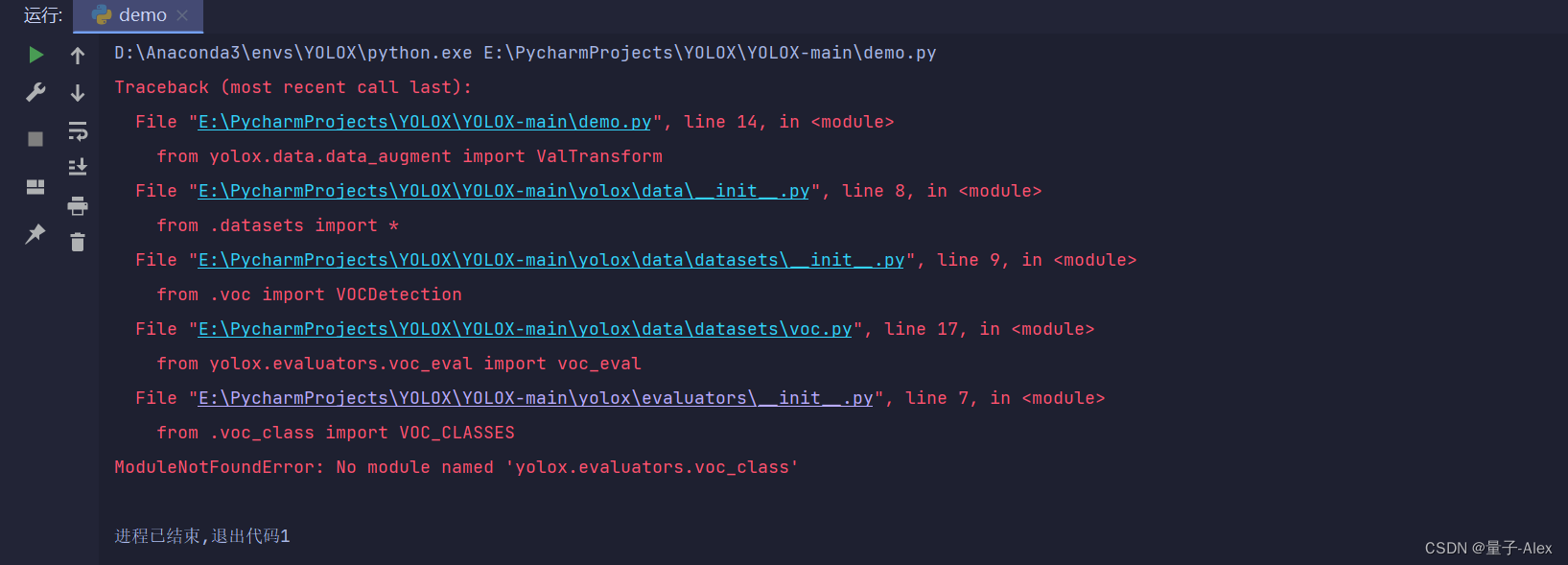
去YOLOX-main/yolox/evaluators/init.py
改成
from yolox.data.datasets.voc_classes import VOC_CLASSES
















 1703
1703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











