







Towards Large-Scale Small Object Detection:Survey and Benchmarks
面向大规模小目标检测:综述和基准

0.论文摘要和作者信息
摘要
摘要——随着深度卷积神经网络的兴起,目标检测在过去几年中取得了显著的进展。然而,这种繁荣并不能掩盖小目标检测(SOD)的不令人满意的情况,SOD是计算机视觉中众所周知的具有挑战性的任务之一,由于小目标的内在结构导致的不良视觉外观和噪声表示。此外,用于对小目标检测方法进行基准测试的大规模数据集仍然是一个瓶颈。在本文中,我们首先对小目标检测进行了全面的回顾。然后,为了促进SOD的发展,我们构建了两个大规模小目标检测数据集(SODA),SODA-D和SODAA,分别关注驾驶和空中场景。SODA-D包括24828张高质量交通图像和九个类别的278433个目标。对于SODA-A,我们收集了2513幅高分辨率航空图像,并在九个类别中注释了872069个目标。正如我们所知,提议的数据集是有史以来第一次尝试大规模基准测试,收集了大量为多类别SOD量身定制的详尽注释目标。最后,我们评估了主流方法在SODA上的性能。我们期望发布的基准可以促进SOD的发展,并在该领域产生更多突破。
索引术语-基准,卷积神经网络,深度学习,目标检测,小目标检测。
作者信息
作者来自西北工业大学自动化学院, 西安710021(电子邮件:gcheng@nwpu.edu.cn;shaunyuan@mail.nwpu.edu.cn;yaoxiwen@nwpu.edu.cn;2021202443@mail.nwpu.edu.cn;zengqinghua@mail.nwpu.edu.cn;xiexing@mail.nwpu.edu.cn;junweihan2010@gmail.com)。
代码地址
1.研究背景
目标检测是一项基本任务,旨在对图像/视频中感兴趣的目标进行分类和定位。由于深度卷积神经网络(CNN)庞大的数据量和强大的学习能力,目标检测近年来取得了显著的成就[1], [2], [3], [4], [5]。小目标检测(SOD)作为通用目标检测的一个子领域,主要检测小尺寸的目标,在监控、无人机场景分析、行人检测、自动驾驶中的交通标志检测等多种场景下具有重要的理论和实践意义。
尽管在一般目标检测方面已经取得了实质性的进展,但SOD的研究进展相对缓慢。更具体地说,即使对于领先的检测器来说,在检测小型和正常尺寸的目标方面仍然存在巨大的性能差距。以最先进的检测器之一DyHead[9]为例,DyHead获得的COCO[6]test-dev集上小目标的平均精度(mAP)度量仅为28.3%,明显落后于中型和大型目标的平均精度(分别为50.3%和57.5%)。我们假设这种性能下降源于以下两个方面:1)从小目标的有限和扭曲的信息中学习适当表示的内在困难;2)小目标检测大规模数据集的稀缺性。
小目标的低质量特征表示可归因于它们有限的大小和通用的特征提取范例。具体来说,当前流行的特征提取器[10], [11], [12]通常对特征图进行下采样以减少空间冗余并学习高维特征,这不可避免地消除了微小目标的表示。此外,小目标的特征在卷积过程后往往会被背景和其他目标污染,使得网络很难捕捉到对后续任务至关重要的判别信息。为了解决这个问题,研究人员提出了一系列的工作,这些工作可以分为六组:面向样本的方法、尺度感知的方法、基于注意力的方法、特征模仿的方法、上下文建模的方法和聚焦和检测的方法。我们将在综述部分详细讨论这些方法。
为了缓解数据稀缺,已经提出了一些为小目标检测定制的数据集,例如SOD[28]和TinyPerson[7]。然而,这些小规模数据集无法满足训练基于监督CNN的算法的需求,这些算法“渴望”大量的标记数据。此外,几个公共数据集包含相当数量的小目标,如WiderFace[8]、SeaPerson[29]和DOTA2[30]等。不幸的是,这些数据集要么被设计用于通常遵循相对确定的模式的单类别检测任务(人脸检测或行人检测),要么其中微小目标仅分布在少数类别(DOTA数据集中的小型车辆)。简而言之,目前可用的数据集不能支持为小目标检测定制的基于深度学习的模型的训练,也不能作为评估多类别SOD算法的公正基准。同时,作为构建数据驱动的深度CNN模型的基础,PASCAL VOC[31]、ImageNet[32]、COCO[6]和DOTA[30]等大规模数据集的可访问性对于学术界和工业界都具有重要意义,每一个都显著促进了相关领域目标检测的发展。这启发我们思考:我们能否建立一个大规模的数据集,其中多个类别的目标具有非常有限的大小,作为一个基准,可以用来验证小目标检测框架的设计,并促进SOD的进一步研究?
考虑到上述问题,我们构建了两个大规模小目标检测数据集(SODA),SODA-D和SODA-A,分别关注驾驶和空中场景。提出的SODA-D建立在MVD[33]和我们的数据之上,其中前者是致力于像素级街景理解的数据集,后者主要由车载摄像头和手机捕捉。利用24828张精心挑选的高质量驾驶场景图像,我们用水平边界框注释了九个类别的278433个目标。SODA-A是专门针对空中场景下SOD的基准,它有872069个目标,具有跨越九个类的定向框注释。它包含从谷歌地球中提取的2513张高分辨率图像。
A.问题定义
目标检测旨在对目标进行分类和定位。小目标检测或微小目标检测,顾名思义,仅仅专注于检测那些尺寸有限的目标。在这项任务中,术语微小和小通常由面积阈值[6]或长度阈值[7], [8]来定义。以coco[6]为例,面积小于等于1024像素的目标属于小类。
B.与以往综述的比较
近年来发表了相当多关于目标检测的调查[13]、[14]、[15]、[16]、[17]、[18]、[19]、[20]、[21]、[22]、[23]、[24],我们的综述主要在两个方面与现有的综述不同。
1.致力于跨多个领域的小目标检测任务的全面和及时的综述:大多数先前的综述(如表I所示)集中于通用目标检测[13], [14], [15]或特定目标检测任务,如行人检测[16], [17]、文本检测[18]、遥感图像中的检测[19], [20]以及交通场景下的检测[21], [22]等。此外,已经有几篇综述关注小目标检测[25], [26], [27],然而,它们要么未能进行全面和深入的分析,因为只对有限的区域进行了部分综述,要么将属于通用检测的相当多的算法归类为小目标检测方法,这对于面向SOD的调查来说确实不严格。通过将我们的视线狭隘地投射到小/微小目标上,我们广泛地回顾了数百篇与SOD任务相关的文献,这些文献涵盖了广泛的研究领域,包括人脸检测、行人检测、交通标志检测、车辆检测、航空图像中的目标检测等。因此,我们提供了一个小目标检测的系统调查和一个可理解的和高度结构化的分类法,它根据所涉及的技术将SOD方法组织成六个主要类别,并且与以前的方法完全不同。
2.提出了两个为小目标检测定制的大规模基准,在此基础上对几种有代表性的检测算法进行了深入的评估和分析:以前的综述主要求助于PASCAL VOC[31]和COCO[6]等通用检测数据集进行评估,这些数据集以中型和大型目标为主,因此无法体现相关方法在小目标时的真实性能。相反,我们提出了大规模的基准SODA,并在此基础上,对几个代表性的工作进行了彻底的评估,提供了目标检测方法和新发表的SOD方法。
C.范围
早期的目标检测通常集成手工特征[34], [35], [36]和机器学习方法[37], [38]来识别感兴趣的目标。由于尺度变化能力有限,遵循这种复杂原理的方法在小目标中表现极差。2012年之后,深度卷积网络的强大学习能力[39]给整个检测界带来了一线希望,尤其是考虑到2010年之后目标检测已经达到了平台期[40]。开创性的工作[40]打破了僵局,从那时起,越来越多的基于深度神经网络的检测方法被提出,此后,目标检测进入了深度学习时代[15]。由于深度网络对尺度变化的出色建模能力和强大的信息抽象,小目标检测获得了前所未有的改进。因此,我们的综述集中在基于深度学习的SOD方法的主要发展。综上所述,本文的主要贡献有三个方面:
1.回顾了深度学习时代小目标检测的发展,并对该领域的最新进展进行了系统的综述,可分为六类:面向样本的方法、尺度感知的方法、基于注意力的方法、特征模仿的方法、上下文建模的方法和聚焦和检测的方法。除了分类法,还提供了关于这些方法的利弊的深入分析。同时,我们回顾了几十个数据集,这些数据集跨越了与小目标检测相关的多个领域。
2.发布了两个大型小目标检测基准,其中第一个专用于驾驶场景,另一个专用于空中场景。提议的数据集是首次尝试为SOD量身定制大规模基准。我们希望这两个详尽注释的基准可以帮助研究人员开发和验证SOD的有效框架,并促进该领域的更多突破。
3.研究了几种有代表性的目标检测方法在我们的数据集上的性能,并根据定量和定性结果提供了深入的分析,这将有利于后续小目标检测的算法设计。
本文的其余部分组织如下。在第二节中,我们对小目标检测进行了全面的调查。第三节对与小目标检测相关的几个公开可用的基准进行了彻底的回顾。在第四节中,我们详细阐述了收集和注释,以及关于所提出的基准的数据特征。在第五节中,提供了几种代表性方法在我们的基准上的结果和分析。最后,我们总结了我们的工作,并讨论了小目标检测的未来研究方向。
2.小目标检测研究综述
A.主要挑战
除了通用目标检测中的一些常见挑战,如类内变化、不准确定位、遮挡目标检测等。,当涉及到SOD任务时,存在典型的问题,主要包括目标信息丢失、噪声特征表示、对检测框扰动的低容忍度和不充分的样本。
信息损失:当前流行的目标检测器[1]、[2]、[3]、[4]、[5]、[9]通常包括主干网络和检测头,其中后者根据前者输出的表示做出决策。这种范式被证明是有效的,并产生了前所未有的成功。然而,通用特征提取器[10], [11], [12]通常利用子采样操作来过滤噪声激活[41]并降低特征图的空间分辨率,从而不可避免地丢失目标的信息。考虑到最终特征仍然保留了它们的足够信息,这种信息丢失几乎不会在一定程度上损害大型或中型目标的性能。不幸的是,这对于小目标来说是致命的,因为检测头很难在高度结构化的表示之上给出准确的预测,其中小目标的微弱信号几乎被抹去。
噪声特征表示:判别特征对于分类和定位任务都至关重要[42],[43]。小目标通常具有低质量的外观,因此很难从它们扭曲的结构中学习具有辨别能力的表示。同时,小目标的区域特征倾向于被背景和其他目标污染,进一步将噪声引入学习的表示。综上所述,小目标的特征表示容易受到噪声的影响,阻碍后续的检测。
对检测框扰动的低容忍度:定位作为检测的主要任务之一,在大多数检测范例中被公式化为回归问题[1], [3], [4], [44], [45], [46], [47],并且通常采用并集交(IoU)度量来评估准确性。然而,定位小目标比大目标更困难。如图1所示,与中型和大型目标(56.6%和71.8%)相比,小型目标的预测框的轻微偏差(沿对角线方向6个像素)导致IoU的显著下降(从100%到32.5%)。同时,更大的方差(比如12个像素)进一步加剧了这种情况,对于小目标,IoU下降到可怜的8.7%。也就是说,小目标与大目标相比,对检测框扰动的容忍度较低,加剧了回归分支的学习。
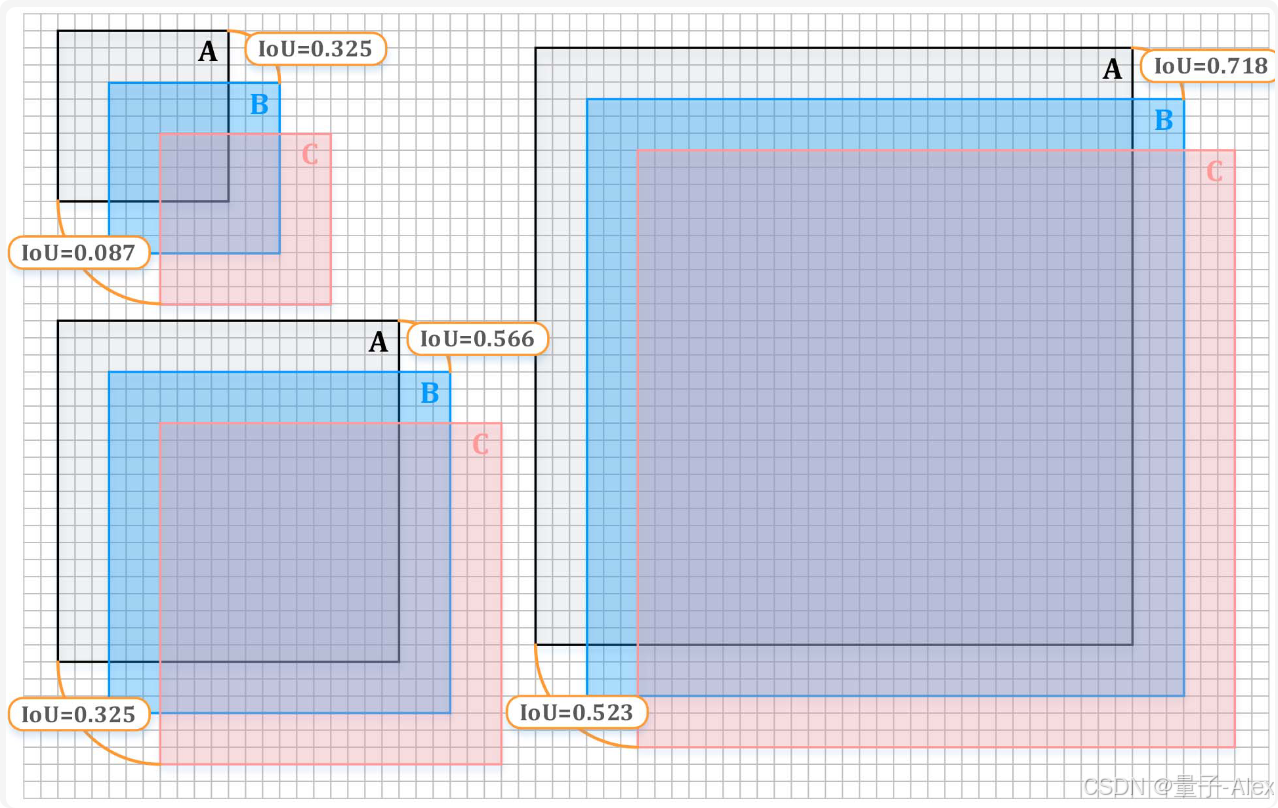
图1。小目标对检测框扰动的低容限。左上、左下和右分别表示小目标(20 × 20像素,网格表示两个像素)、中目标(40 × 40像素)和大目标(70 × 70像素)。A表示真实(GT)框,B和C是沿着对角线方向(6像素和12像素)具有轻微偏差的预测框。IoU表示GT框和相关预测框之间的交集。
训练样本不足:选择正和负样本是训练高性能检测器不可或缺的一步。然而,当涉及到小目标时,事情会变得更加困难。具体来说,小目标占据相当小的区域,并且与先验(锚点或点)的重叠有限。这极大地挑战了传统的标签分配策略[1]、[3]、[4]、[47]、[48],这些策略基于框或中心区域的重叠收集pos/neg样本,导致训练期间为小目标分配的阳性样本不足。
B.小目标检测算法综述
基于深度学习的一般目标检测方法可以分为两组:两阶段检测和一阶段检测,其中前者以从粗到细的例程检测目标,而后者一次性执行检测。两阶段检测方法[1]、[46]、[49]首先使用精心设计的架构(如区域建议网络(RPN)[1])产生高质量的建议,然后检测头将区域特征作为输入,分别执行后续分类和定位。与两阶段算法相比,一阶段方法[3], [44], [50]在特征图上平铺密集锚点,并直接预测分类分数和坐标。受益于无建议设置,单级检测器享有高计算效率,但精度往往落后。除上述两类外,近年来还出现了几种无锚方法[4]、[47]、[48]、[51],它们抛弃了锚范式。此外,基于查询的检测器[5], [52]将检测公式化为一组预测任务,已经显示出巨大的潜力。由于篇幅所限,我们无法详细阐述相关框架。更多详情请参考相应的综述[13]、[14]、[15]和原始论文。
为了解决上述挑战性问题,现有的小目标检测方法通常将深思熟虑的设计引入在通用目标检测中工作良好的强大范例。接下来,我们将简要介绍这些方法,并且所提出的解决方案的概述如图2所示。此外,附录A.1节展示了每种分类中代表性方法的比较,可在线获取。
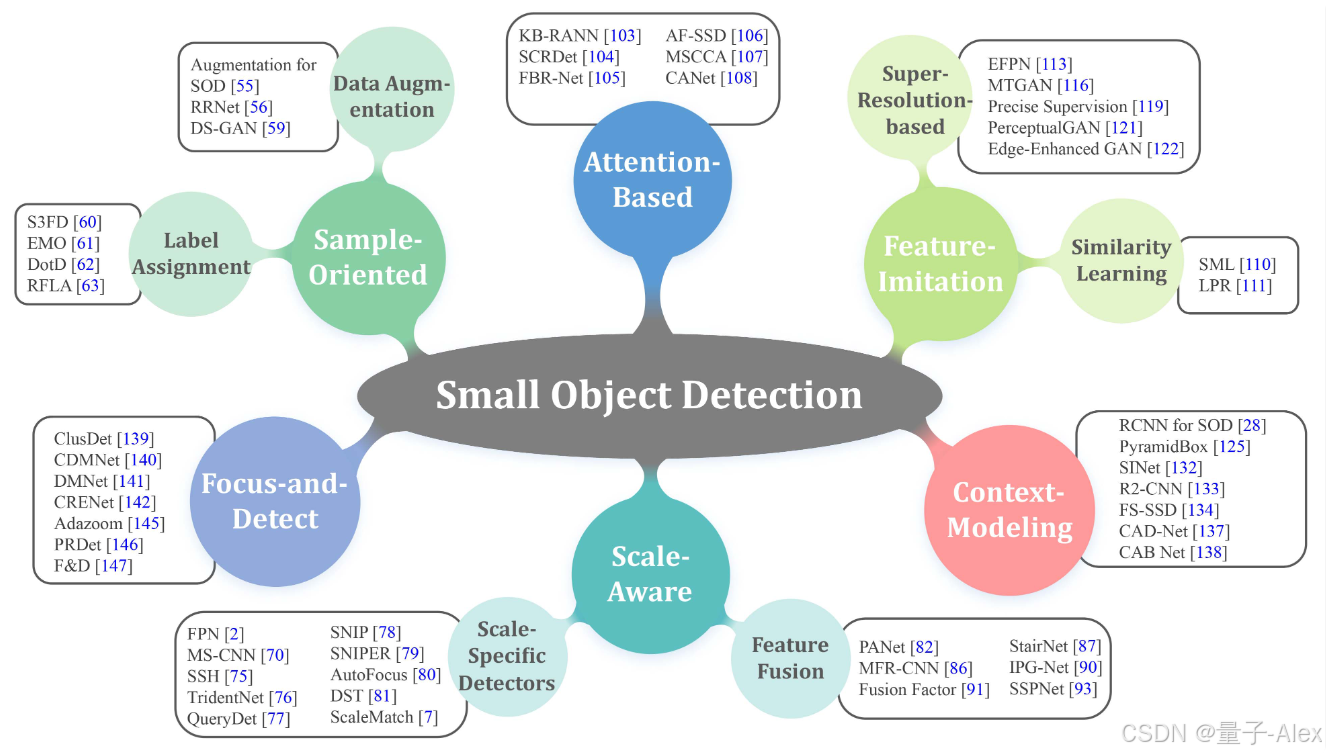
图2。现有基于深度学习的小目标检测方法的结构化分类,包括六种类型。仅演示了每个类别的几种代表性方法。
面向样本的方法
1)面向样本的方法:训练基于学习的检测器的最关键的过程之一是采样(通常与赋值共存),这导致了通用目标检测的重大进展[53],[54]。然而,对于SOD任务,通用采样策略通常无法提供足够的阳性样本,从而损害最终性能。这种困境源于两个方面:大小有限的目标在当前数据集中仅占据一小部分[6]、[30]、[31];由于先验和小目标区域之间的有限重叠,当前基于重叠的匹配方案[1], [3], [4], [47], [48]过于严格,无法采样足够的正锚或点。鉴于这两个观察结果,已经做出了一系列努力来缓解样本稀缺问题,并且可以分为两派:通过数据扩充来增加小目标的数量或设计最佳分配策略以使足够的样本用于网络学习。
数据增强策略:Kisantal等人[55]通过复制一个小目标并通过随机变换将其粘贴到同一图像中的不同位置来增强小目标。RRNet[56]引入了一种名为AdaResampling的自适应增强策略,它遵循与[55]相同的原理,主要区别在于使用先前的分割图来指导要粘贴的有效位置的采样过程,并且对粘贴目标的比例变换进一步减少了比例差异。张等人[57]和王等人[58]两者都采用了基于功能的划分和调整大小的操作来获得更多的小目标训练样本。在目标分割、图像修复和图像混合的基础上,DS-GAN[59]设计了一种新颖的数据增强管道来生成小目标的高质量合成数据。
优化的标签分配:遵循这一理念的方法旨在减轻由于基于重叠或距离的匹配策略而导致的次优采样结果,并减少回归期间的扰动。在设计的尺度补偿锚点匹配策略的帮助下,S3 FD[60]增加了微小人脸的匹配锚点,从而提高了召回率。朱等人[61]提出了预期最大重叠(EMO)分数,该分数在计算重叠时考虑了锚步幅,并为小面提供了更好的锚设置。徐等人。[62]采用提出的DotD(定义为两个边界框中心点之间的归一化欧几里得距离)来代替常用的IoU。类似地,RFLA[63]在标签分配中测量每个特征点的高斯感受野和真实之间的相似性,这提高了主流检测器在微小目标上的性能。
样本在目标检测中很重要,尤其是对于SOD任务。如果没有足够的阳性样本,小目标的区域在训练期间优化不足,从而阻碍后续的分类和回归。基于增强的方法或设计的匹配策略和适当的先验设置旨在提供足够的阳性样本。然而,前一种方法总是存在性能改进不一致和可移植性差的问题。同时,当前优化的标签分配方案倾向于引入低质量的样本,并且仍然难以处理尺寸极其有限的目标。
尺度感知方法
2)尺度感知方法:图像中的目标通常在尺度上变化,并且这种变化在交通场景和遥感图像中可能特别严重,导致单个检测器的不同检测困难。以前的方法[64], [65]通常采用带有滑动窗口方案的图像金字塔[66]来处理尺度方差问题。然而,受有限表示能力的限制,手工制作的基于特征的方法在小目标上表现极差。基于深度模型的早期检测方法在检测微小目标方面仍然很困难,因为只有高级特征用于识别。为了弥补这一范式的弱点,并受到其他视野中跨多层次推理成功的启发[67],[68],以下工作主要遵循两条路径。一种是通过设计多分支架构或定制的训练方案来构建特定于尺度的检测器,另一种是融合层次特征以实现小目标的强大表示。这两种方法实际上都在一定程度上最小化了特征提取过程中的信息损失。
特定于尺度的检测器:这条线背后的性质很简单:不同深度或级别的特征只负责检测相应尺度的目标。杨等人[69]利用尺度相关池化(SDP)为小目标的后续池化操作选择合适的特征层。MS-CNN[70]在不同的中间层生成目标建议,每个中间层都关注特定比例范围内的目标,从而实现小目标的最佳感受野。按照这个路线图,DSFD[71]采用由特征增强模块连接的双镜头检测器来检测各种比例的人脸。YOLOv3[45]通过添加并行分支来进行多尺度预测,其中高分辨率特征负责小目标。Lin等[2]提出了特征金字塔网络(FPN),其中不同尺度的目标根据其大小被分配到不同的金字塔级别。同时,不同深度特征的交互进一步保证了多尺度目标的正确表示。这种简单而有效的设计已经成为特征提取器的重要组成部分,并激发了一系列显著的变体,例如NAS-FPN[72]和递归-FPN[73]。此外,组合用于多尺度检测的按尺度检测器已经被广泛探索。李等人[74]建立了并行子网络,其中小尺寸子网络被专门学习以检测小行人。SSH[75]结合了尺度变化的人脸检测器,每个检测器都经过特定尺度范围的训练,以形成一个强大的多尺度检测器,以处理尺度变化极大的人脸。TridentNet[76]构建了一个并行的多分支架构,其中每个分支都拥有不同尺度目标的最佳感受野。QueryDet[77]设计了级联查询策略,避免了对低级特征的冗余计算,使得在高分辨率特征图上高效检测小目标成为可能。
几种方法旨在开发定制的数据准备策略,以迫使检测器在训练期间专注于具有特定规模的目标。在通用多尺度训练方案的基础上,Singh等人[78]设计了一种新的训练范式,图像金字塔的尺度归一化(SNIP),它只接受分辨率落在期望尺度范围内的目标进行训练,其余的目标被简单地忽略。通过此设置,小目标可以在最合理的比例,而不会影响对中型到大型目标的检测性能。后来,Sniper[79]建议从多尺度图像金字塔中采样芯片以进行有效训练。Najibi等[80]提出了一种用于检测小目标的粗到细流水线。考虑到数据准备和模型优化之间的协作在以前的方法中探索不足[2]、[66]、[76],Chen等人[81]设计了一种反馈驱动的训练范式来动态指导数据准备,并进一步平衡小目标的训练损失。Yu等[7]介绍了一种基于统计的尺度一致性匹配策略。
分层特征融合:深度CNN架构产生不同空间分辨率的分层特征图,其中低级特征描述更精细的细节以及更多的定位线索,而高级特征捕获更丰富的语义信息[13]、[43]、[76]、[82]、[83]、[84]。对于SOD任务,深层特征可能会与小目标的消失响应作斗争,并且早期阶段的特征图容易受到光照、变形和目标姿态等变化的影响,使得分类任务更具挑战性。为了克服这一困境,广泛的方法利用特征融合,它集成了不同深度的特征,以获得小目标的更好的特征表示。受FPN[2]中简单而有效的交互设计的启发,PANet[82]通过双向路径丰富了特征层次,通过精确的定位信号增强了更深层次的特征。为了以更直观和有原则的方式优化多尺度特征融合,Tan等人[85]提出了双向特征金字塔网络(BiFPN),以保证小目标的正确表示以及更好的准确性和效率权衡。张等人[86]将多个深度的RoI的池化特征与全局特征连接起来,以获得小交通目标的更鲁棒和更具区分性的表示。Woo等人[87]提出了StairNet,其中利用去卷积来放大特征图,这种基于学习的上采样函数可以实现比基于朴素核的上采样更精细的特征,并允许不同金字塔级别的信息更有效地传播[88]。M2Det[89]构建并行分支,以级联方式从浅到深描述特征,其中利用精简的Ushape模块来捕获小目标的更详细信息。Liu等[90]引入了IPG-Net,其中将图像金字塔[66]获得的一组不同分辨率的图像输入到设计的IPG变换模块中,以提取浅层特征来补充空间信息和细节。龚等人[91]设计了一种基于统计的融合因子来控制相邻层的信息流。注意到在基于FPN的方法中遇到的梯度不一致性恶化了低级特征的表示能力[92],SSPNet[93]突出了不同层的特定尺度的特征,并利用FPN中相邻层的关系来实现适当的特征共享。
特定于规模的架构致力于以最合理的规模处理小目标,而基于融合的方法旨在弥合较低金字塔级别和较高金字塔级别之间的空间和语义差距。然而,前者以启发式的方式将不同大小的目标映射到相应的尺度水平,这可能会混淆检测器,因为单层的信息不足以做出准确的预测。另一方面,网络内信息流并不总是有利于小目标的表示。我们的目标是不仅要赋予低层次特征更多的语义,还要防止小目标的原始响应被更深层的信号淹没。不幸的是,鱼与熊掌不可兼得,因此这一困境需要谨慎解决。
基于注意力的方法
3)基于注意力的方法:人类可以通过对整个场景的一系列局部一瞥来快速聚焦和区分目标,同时忽略那些不必要的部分[94],我们感知系统中的这种惊人能力通常被称为视觉注意力机制,它在我们的视觉系统中起着至关重要的作用[95]。毫不奇怪,这种强大的机制已经在以前的文献[96]、[97]、[98]、[99]、[100]中得到了广泛的研究,并在许多视野[5]、[9]、[101]、[102]中显示出巨大的潜力。通过给特征图的不同部分分配不同的权重,注意力建模确实强调了有价值的区域,同时抑制了那些可有可无的区域。自然地,人们可以部署这种优越的方案来突出显示倾向于由图像中的背景和噪声图案支配的小目标,从而部分地最小化特征表示中的污染。
受人类认知的启发,KB-RANN[103]利用长期和短期注意力神经网络来关注图像特征的特定部分,增强小目标的检测。SCRDet[104]设计了一种定向目标检测器,其中像素注意力和通道注意力以监督的方式进行训练,以突出小目标区域,同时消除噪声的干扰。FBR-Net[105]用提出的基于级别的注意力扩展了无锚检测器FCOS[4],平衡了不同金字塔级别的特征,并增强了复杂情况下小目标的学习。Lu等人[106]设计了一个双路径模块来突出小目标的关键特征,抑制非目标信息。通过用所提出的增强信道注意力(ECA)块替换复杂的卷积分量,MSCCA[107]构造了一个具有平衡信道特征和更少参数的轻量级检测器。Li等[108]设计了跨层注意模块,以获得更强的小目标响应。
借鉴人类的认知机制,视觉注意力在当今的视野中发挥着重要作用,它通过筛选关键部分同时抑制嘈杂部分来实现高质量的表征。注意力系列方法因其灵活的嵌入设计而备受推崇,并且可以插入几乎所有的SOD架构中,然而,由于相关操作,性能的提高是以沉重的计算开销为代价的,此外,当前的注意力范例缺乏监督信号和隐式优化。
特征模仿方法
4)特征模仿方法:SOD最重要的挑战之一是由小实例的少量信息引起的低质量表示。对于那些尺寸极其有限的目标来说,这种情况可能会变得更糟[109]。同时,较大的实例通常体现清晰的视觉结构和更好的辨别能力。因此,缓解这一低质量问题的一个直接方法是通过模仿较大目标的区域特征来丰富小目标的区域特征[110]。为此,已经提出了几种方法,可以分为两类:通过相似性学习的特征模仿和基于超分辨率的框架。通过挖掘不同尺度目标之间的内在关系,该分类方法在很大程度上改善了信息丢失和特征表示噪声问题。
基于相似性学习的方法:这条线的原理很简单:对通用检测器施加额外的相似性约束,从而弥合小目标和大目标之间的表示差距。吴等人[110]提出了自模仿学习方法,其中小规模行人的表示被强制接近大规模行人的局部平均RoI特征。受人类视觉理解机制记忆过程的启发,Kim等人。[111]设计了一种具有大规模行人回忆记忆(LPR记忆)的大规模嵌入学习,并在回忆损失下优化了整体架构,旨在引导小规模和大规模行人特征相似。
基于超分辨率的框架:遵循该路线图的方法旨在恢复小目标的扭曲结构,而不是简单地放大它们模糊的外观。借助反卷积和亚像素卷积[112],Zhou等人[83]和Deng等人[113]获得了专门用于小目标检测的高分辨率特征。利用自监督学习范式,Pan等人[114]提出了一种引导特征上采样模块,用于学习具有详细信息的升级特征表示。生成对抗网络(GAN)[115]具有通过遵循生成器和鉴别器之间的双人极小极大博弈来生成视觉上真实的数据的非凡能力,这不出所料,启发研究人员探索这种生成小目标高质量表示的强大范式。考虑到直接操作整个图像在特征提取阶段会产生不可忽略的计算成本[113],MTGAN[116] 用生成器网络超解析ROI的斑块。白等人[117]将该范例扩展到人脸检测任务,Na等人[118]将超分辨率方法应用于小的候选区域以获得更好的性能。尽管超分辨率目标斑块可以部分重建小目标的模糊外观,但该方案忽略了在网络预测中起重要作用的上下文线索[119],[120]。为了解决这个问题,李等人[121]设计了PerceptualGAN来挖掘和利用小规模和大规模目标之间的内在相关性,其中生成器学习将小目标的弱表示映射到超分辨率表示,以欺骗鉴别器。更进一步,Noh等人[119]将直接监督引入超分辨率程序。Rabbi等人[122]和Courtrai等人[123]都使用GAN来超分辨低分辨率遥感图像,其中前者筛选边缘细节以避免重建过程中的高频信息丢失,后者结合循环GAN和残差特征聚合来捕捉复杂特征。
通过向主流检测器添加额外的相似性损失或超分辨率架构,特征模仿方法使模型能够挖掘小尺度目标和大尺度目标之间的内在相关性,从而增强小尺度目标的语义表示。然而,无论是基于相似性学习的方法还是基于超分辨率的方法都必须避免崩溃问题并保持特征多样性。此外,基于GAN的方法倾向于制造虚假纹理和伪影,对检测施加负面影响。更糟糕的是,超分辨率架构的存在使端到端优化变得复杂。
上下文建模方法
5)上下文建模方法:我们人类可以有效地利用环境和目标之间的关系或目标之间的关系来促进目标和场景的识别[124],[125]。这种捕捉语义或空间关联的先验知识被称为上下文,它传达了目标区域之外的证据或线索。上下文信息不仅在人类视觉系统中至关重要[120]、[124],而且在场景理解任务中也至关重要,如目标识别[126]、语义分割[127]和实例分割[128]等。有趣的是,信息上下文有时可以提供比目标本身更多的决策支持,尤其是在识别观看质量差的目标时[124]。为此,几种方法利用上下文线索来增强小目标的检测,从而克服决策中的损失问题。
IONet[129]通过两个四向IRNN结构[130]计算全局上下文特征,以便更好地检测小的和严重遮挡的目标。陈等人[28]采用上下文区域的表示,其包含用于后续识别的建议补丁。胡等人[131]研究了如何有效地编码目标范围之外的区域,并以尺度不变的方式对局部上下文信息进行建模,以检测微小人脸。PyramidBox[125]充分利用上下文线索来找到与背景无法区分的小而模糊的脸。假设原始RoI池操作会分解小目标的结构,SINet[132]引入了上下文感知RoI池化层来维护上下文信息。R2-CNN[133]采用全局注意力块来抑制虚警,并有效地检测大规模遥感图像中的小目标。图像中目标的内在相关性同样可以被视为上下文。FS-SSD[134]利用隐式空间上下文信息,即类内和类间实例之间的距离,来重新检测具有低置信度的目标。类似地,Fu等人[135]引入了上下文推理模块,以捕捉内在关系并传播不同区域之间的语义和空间相关性。帕托等人[136]利用来自预测的上下文信息来恢复置信度并提高最终精度。张等人[137]捕捉小目标与全局场景(全局上下文)及其相邻实例(局部上下文)之间的相关性,以提高性能。崔等人[138]设计了一个上下文感知块将多尺度上下文线索与金字塔扩张卷积集成,赋予高分辨率特征有利于小实例的强语义。
从信息论的角度来看,考虑的特征类型越多,越有可能获得更高的检测精度[86]。受共识的启发,上下文启动已被广泛研究以生成更具区分性的特征,特别是对于线索不足的小目标,从而实现精确识别。不幸的是,整体上下文建模或局部上下文启动都混淆了哪些区域应该被编码为上下文。换句话说,当前的上下文建模机制以启发式和经验的方式确定上下文区域,这不能保证所构建的表示对于检测是足够可解释的。
聚焦和检测方法
6)聚焦和检测方法:高分辨率图像中的小目标往往分布不均匀[139],一般的分割和检测方案在这些空斑块上消耗了太多的计算,导致推理过程中的低效率。我们能否过滤掉那些没有目标的区域,从而减少无用的操作来增强检测?答案是肯定的!这方面的努力打破了处理高分辨率图像的通用管道链。它们首先提取包含目标的区域,随后对其执行检测。这种范例保证了可以以更高的分辨率处理小目标,从而缓解信息损失并提高表示质量。
Yang等人[139]提出了一种聚类检测网络(ClusDet),该网络充分利用目标之间的语义和空间信息来生成聚类芯片,然后执行检测。遵循这一范式,段等人[140]和李等人[141]都利用像素监督进行密度估计,实现了更精确的密度图,很好地表征了目标的分布。CRENet[142]设计了一种聚类算法来自适应地搜索聚类区域。
考虑到固定大小的输入处理管道会导致小目标的漏检,[143]利用tilling方法实时检测高分辨率航空图像中的行人和车辆。分享相似的理念,邓等人[144]和徐等人[145]设计了一个超分辨率网络和一个强化学习框架,分别提高局部斑块的空间分辨率以进行更精细的检测和自适应缩放焦点区域。除了传统的区域挖掘程序,Leng等人[146]采用特定于区域的上下文学习模块来增强挑战性区域中大小受限实例的感知。F&D[147]引入了一个聚焦和检测框架,其中聚焦网络检测候选区域,然后将这些区域裁剪并调整到更高的分辨率,从而能够准确检测小目标。
与一般的滑动窗口机制相比,聚焦和检测方法支持自适应裁剪和灵活的缩放操作,即可以以更高的分辨率处理较小的目标,而可以以相对较低的分辨率检测较大的目标,这大大节省了推理时的内存占用,并减少了背景的干扰。遵循这个路线图的方法必须回答一个关键问题:关注哪里?当前的方法求助于手动附加注释或辅助架构,如分割网络或高斯混合模型,然而前者需要费力的标记,而后者使端到端优化复杂化。
3.小目标检测数据集综述
A.用于小目标检测的数据集
数据集是基于学习的目标检测方法的基石,尤其是对于数据驱动的深度学习方法。在过去的几十年里,各种研究机构推出了大量高质量的数据集[6]、[30]、[31]、[32],这些公开的基准显著推动了相关领域的发展。不幸的是,很少有基准是为小目标检测而设计的。为了完整性,我们仍然回顾了十几个包含大量小目标的数据集,并期望提供数据集的全面回顾。我们没有将我们的范围限制在特定的任务上,而是研究了涵盖广泛研究领域的相关数据集,包括人脸检测[8]、行人检测[7]、[148]、[149]、航空图像中的目标检测[20]、[30]、[160]、[162]等。这些基准的统计数据见表二,由于篇幅限制,下面只详细介绍其中最具代表性的。更多详情请参阅附录A.2节,可在线获取。
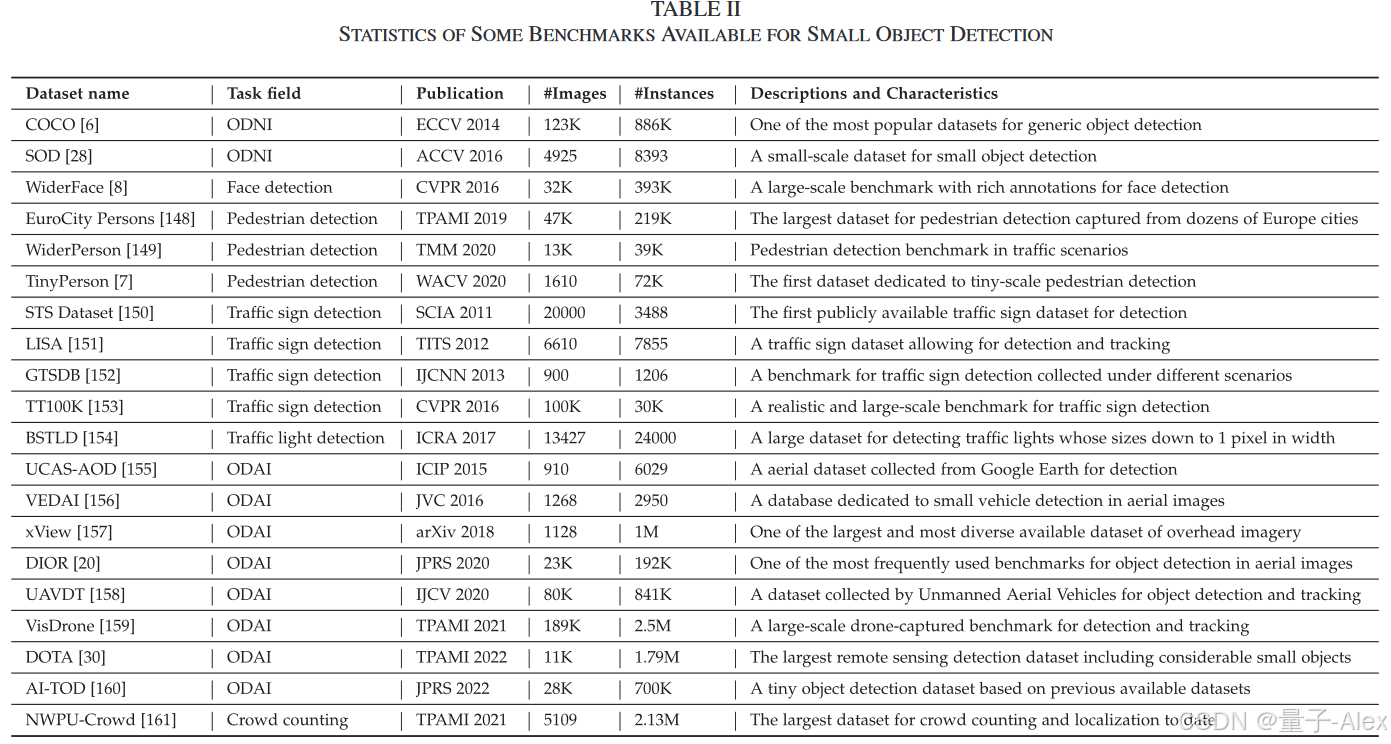 COCO:开创性的工作[31],[32],虽然推动了视觉识别任务的发展,但因其理想条件而受到批评,在理想条件下,目标通常具有较大的尺寸并以图像为中心,与现实世界的场景几乎没有相似之处。为了弥合这一差距并促进精细级别的图像理解,COCO[6]于2014年推出,其trainval集用实例级掩码注释了分布在123 K图像中的886 K个目标,涵盖了复杂日常场景下的80个常见类别。与以前的目标检测数据集相比,COCO包含更多的小目标(COCO训练集中约30%的实例具有小于1024像素的面积)和更密集的实例,这两者都对检测器提出了挑战。此外,完全分割的注释和合理的评估度量鼓励更准确的定位。所有这些特征有助于COCO成为过去几年中验证目标检测方法有效性的事实上的标准。
COCO:开创性的工作[31],[32],虽然推动了视觉识别任务的发展,但因其理想条件而受到批评,在理想条件下,目标通常具有较大的尺寸并以图像为中心,与现实世界的场景几乎没有相似之处。为了弥合这一差距并促进精细级别的图像理解,COCO[6]于2014年推出,其trainval集用实例级掩码注释了分布在123 K图像中的886 K个目标,涵盖了复杂日常场景下的80个常见类别。与以前的目标检测数据集相比,COCO包含更多的小目标(COCO训练集中约30%的实例具有小于1024像素的面积)和更密集的实例,这两者都对检测器提出了挑战。此外,完全分割的注释和合理的评估度量鼓励更准确的定位。所有这些特征有助于COCO成为过去几年中验证目标检测方法有效性的事实上的标准。
WiderFace:WiderFace[8]是一个面向精确人脸检测的大规模基准,其中人脸在比例、姿势、遮挡、表情、外观和照明方面差异很大。它包含32203个图像,总共393703个实例。除了常见的边界框注释之外,还提供了包括遮挡、姿态和事件类别在内的属性,这允许对现有方法进行彻底的研究。WiderFace中的人脸分为三个子集,即小(在10-50像素之间)、中(在50-300像素之间)和大(大于300像素),其中小子集占所有实例的一半。
TinyPerson:TinyPerson[7]专注于海边行人检测。TinyPerson在1610张图像中注释了72561人,根据它们的长度,它们被分为两个子集:微小和小。由于尺寸极小,忽略标签被分配给那些不能确定识别的区域。作为第一个致力于小规模行人检测的数据集,TinyPerson是朝着微小目标检测迈出的具体一步。然而,其有限的实例数量和单一的模式限制了其作为SOD基准的能力。
TT100 K:TT100K[153]是一个用于真实交通标志检测的数据集,包括100000张图像中的30000个交通标志实例,涵盖45个常见的中国交通标志类别。TT100 K中的每个符号都用精确的边界框和实例级掩码进行注释。TT100 K中的图像是从腾讯街景中捕获的,在天气条件和照明方面具有很高的可变性。此外,TT100 K包含相当多的小实例(80%的实例在整个图像区域中占据不到0.1%),并且整个数据集遵循长尾分布。
VisDrone:VisDrone[159]是一个大规模的无人机捕获数据集,收集于中国14个不同城市的各个城市/郊区。VisDrone专注于计算机视觉中的两项基本任务,支持四个轨道:图像目标检测、视频目标检测、单目标跟踪和多目标跟踪。对于图像目标检测跟踪,有10209张分辨率为2000 × 1500像素的图像和542K个实例,涵盖了交通场景中10个常见的目标类别。VisDrone中的图像是用无人机从各种城市场景捕捉的,因此由于视点变化和严重遮挡而包含大量小目标。
DOTA:DOTA[30]是为了方便地球视觉中的目标检测而提出的。它包含11268张图像中的18个常见类别和1793658个实例。每个目标都用水平/定向边界框进行了注释。由于俯视图图像中方向的高度多样性和实例之间的大规模变化,DOTA数据集具有许多小目标,但它们仅分布在少数类别(小型车辆)中。
B.评价指标
在深入探讨小目标检测的评价标准之前,我们首先介绍相关的初步概念。给定检测器输出的真实边界框 b g b_g bg和预测框 b p b_p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3255
3255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











